
回归——线性回归,Logistic回归,范数,最大似然,梯度,最小二乘……
写在前面:在本篇博客中,旨在对线性回归从新的角度考虑,然后引入解决线性回归中会用到的最大似然近似(Maximum Likelihood Appropriation-MLA)
求解模型中的参数,以及梯度下降法解决MLA。然后分析加入不同范数(L0, L1, L2)对线性回归的影响。其次,另外一个重点是Logistic回归,他们分别用来
做回归和分类。线性回归与Logistic回归的区别,以及由Logistic回归引出的SoftMax回归及其用途。
一。线性回归
(1)残差
对于线性回归模型,我们一般使用二次损失函数,其形式为:

有时我们会直接使用它,然后用梯度下降的方法直接解决,但是它是怎么推导出来的呢?
这里使用一种新的思路:
假设对于一个房屋的数据集,一幢房子的价格可能会受其面积,几居室,交通因素,楼层等因素的影响,假设最终价格与这些因素都是线性的关系。我们的目标
是拟合出一条直线(超平面),可以由这些feature得出预测的房屋价格。图示如下:
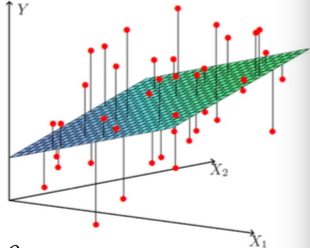

这样实际的数据点与拟合出的直线之间会有一定的距离,我们称之为残差。而且可以证明(通过中心极限定理),残差ε(i)(0<=i<=m)是独立同分布的
(independently and identically distribution -IID),服从均值为0,方差为某定值σ2的高斯分布。即:


(2)最大似然估计
因为数据点也是独立同分布的,因此我们可以用联合概率分布来计算似然概率:

然后,下面都是套路啊。。。连乘计算太困难,所以取对数。。。
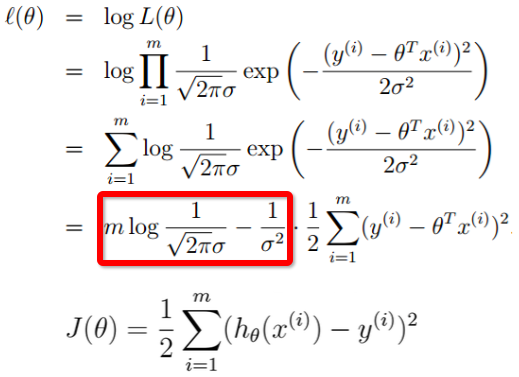
红框中的都是常数,因此可以省略不考虑,所有就得到了我们的lost function。加上1/2是因为方便后面求导。
(3)用最小二乘法解MLA的参数θ
假设我们的数据是由M个N维样本组成的矩阵X,注意另外还有一维常数项,全为1.
则目标函数为:
![]()
可以看到,J(θ)是关于θ的二次函数,且二次项系数大于0,则我们可以直接求导然后求其导数的驻点就可以得到整个函数的最小值了。

则 θ = (xTx)-1 XTy
为防止xTx不可逆,我们有时需要加入一个扰动项:
θ = (xTx + λI)-1 XTy
在最小二乘法的线性回归中,我们的目标方程是:
![]()
但是,有时候训练出来的模型会太复杂而导致过拟合,因此需要加入一定的惩罚项(正则项Regularization):
L0: θ(i) (0 <= i <= M)中非零的个数;
L1: ∑i=0M = |θ(i)| 即θ绝对值的和;
L2: ∑i=0M = (θ(i))2 即θ的平方和。
在实际的应用中,因为平方项比较好求导,所以L2用的最广泛。
加入正则项的目标函数为:
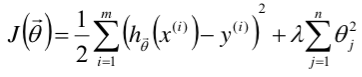
则,θ = (xTx + λI)-1 XTy
以上就是用最小二乘法解决MLA参数问题的解法。
(4)用梯度下降法解MLA的参数θ
目标函数为:
![]()
- 初始化θ(随机初始化);
- 沿着负梯度方向迭代,更新后的θ使J(θ)更小:θj = θj - α (∂J(θ) / ∂θ)

批量梯度下降:
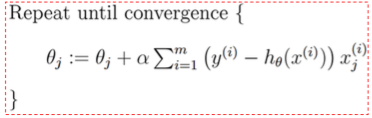
随机梯度下降:
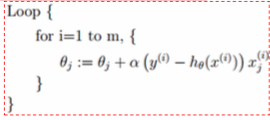
批量 VS 随机:
每次迭代都要用所有的数据 VS 随机选择一个数据就可以来做更新

一个非常非常需要注意的地方:
线性回归中的线性指的是:这里的线性是指参数是线性的,与数据x无关!!!
二。Logistic回归
(1)引出
一个大胆的想法:用线性回归来做分类如何?比如既然都是找一条超平面,我们何不用训练出来的回归直线来做分类。如下图中右上角的图片所示,如果函数值小于0.5为A类,如果大于0.5为B类。
然而,理想很丰满,现实很骨感。实际是不可以的!
如下图中右下角的图片,如果有一个非常严重的离群点,则会导致我们的回归线网离群点方向偏移,这样会导致很多错误分类,从而完全无法分类。

虽然线性回归无法解决分类问题,但是我们可以使用它的变种——Logistic回归来解决!!
引入sigmoid函数:
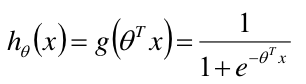
则最大似然(联合概率分布)为:注意 y = 0 / 1, 所以![]() 中,只会有一项存在。
中,只会有一项存在。

接下来依然是套路。。取对数,求偏导。

所以,Logistic回归的参数学习规则为:
![]()
批量梯度上升 VS 随机梯度上升

(与线性回归模型非常相像,只不过一个是梯度下降,一个梯度上升)
三。SoftMax回归
既然Logistic回归可以解决二分类的问题,那么我们可能又会问:对于多分类问题,除了OVA 及 OVO外是否有一种方法可以直接实现多分类呢?
Of course!!一种基于Logistic回归的soft Max回归可以实现多分类。
基本的思路是:对于每个样本,我们不认为它仅仅属于一个类,而是将它属于每个类的概率大小纪录下来,最终将其分入概率最大的一个类中。

这样,参数θ由一维向量变成了一个矩阵,我们仍然可以使用批量梯度下降和随机梯度下降的方法来估计参数。
另外,除了分类,Logistic也是推荐系统中一个强有力的工具。
[总结]
我们分类了线性回归通过线性模型中残差的概念引出来,然后通过最大似然估计得出了它的目标函数。
在求解目标函数时,我们可以使用最小二乘的方法来直接估计,也可以使用梯度下降的方法来迭代估计。同时,为了防止过拟合,我们又介绍了范数/正则项(L0,L1,L2)及他们的区别。
求解完线性回归的问题,我们有考虑能否用回归来解决分类问题。这样,便引入了Logistic回归。他的求解过程与线性回归非常相似,只是加了一个sigmoid函数,而且解参数时使用的是梯度上升。
解决完二分类问题后希望可以直接解决多分类问题,所以引入了softMax回归,它仅仅是Logistic回归的矩阵版本,求解过程几乎一样。
最后需要注意的一点是:线性模型指的是对参数θ/w是线性的,而不是说数据x必须是线性的!!!切记切记。
最后给出手写版的Linear Regression 和 Logistic Regression的直观对比:


