
MapReduce程序(一)——wordCount
写在前面:WordCount的功能是统计输入文件中每个单词出现的次数。基本解决思路就是将文本内容切分成单词,将其中相同的单词聚集在一起,统计其数量作为该单词的出现次数输出。
1.MapReduce之wordcount的计算模型
1.1 WordCount的Map过程
假设有两个输入文本文件,输入数据经过默认的LineRecordReader被分割成一行行数据,再经由map()方法得到<key, value>对,Map过程如下:
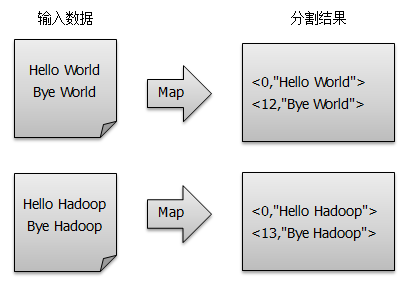

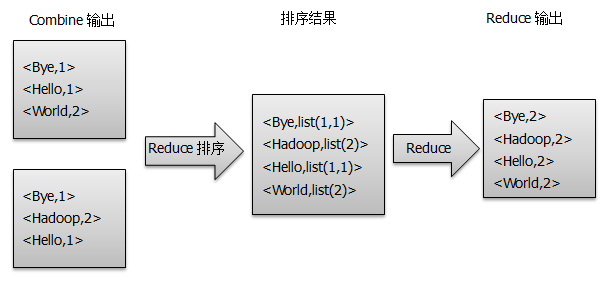
得到map方法输出的< key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key值相同的value值累加,得到Mapper的最终输出结果,如图所示:

1.2 WordCount的Reduce过程
Reducer对从Mapper端接收的数据进行排序,之后由reduce()方法进行处理,将相同主键下的所有值相加,得到新的<key, value>对作为最终的输出结果,如图所示:
2. 打包运行WordCount程序
通过Eclipse来编译打包运行自己写的MapReduce程序(基于Hadoop 2.6.0)。
2.1 下载所需的驱动包
下载地址Group: org.apache.hadoop下载对应版本的驱动包:
- hadoop-common-2.6.0.jar
- hadoop-mapreduce-client-core-2.6.0.jar
- hadoop-test-1.2.1.jar
2.2 创建新的工程
- 使用Eclipse创建名为WordCount的Java Project;
- 在
Project Properties -> Java Build Path -> Libraries -> Add External Jars添加第一步所下载Jar包, 点击OK; - 创建WordCount.java源文件:
-
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); /* * LongWritable 为输入的key的类型 * Text 为输入value的类型 * Text-IntWritable 为输出key-value键值对的类型 */ public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); // 将TextInputFormat生成的键值对转换成字符串类型 while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); /* * Text-IntWritable 来自map的输入key-value键值对的类型 * Text-IntWritable 输出key-value 单词-词频键值对 */ public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); // job的配置 Job job = Job.getInstance(conf, "word count"); // 初始化Job job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); // 设置输入路径 FileOutputFormat.setOutputPath(job, new Path(args[1])); // 设置输出路径 System.exit(job.waitForCompletion(true) ? 0 : 1); } }
2.3 打包源文件
- 在Eclipse -> File ->Export -> Java ->JAR file ->next
- 选中新建的WordCount工程,设置相应的输出路径和文件名(这里的输出路径一定要记下来,后面会用到),FInish
- 在设置的输出路径处生成了WordCount.jar,至此,打包完毕。
2.4 启动HDFS服务
打开Terminal,进入目录/usr/local/Cellar/hadoop/2.6.0/sbin
$ start-dfs.sh #启动HDFS
$ jps #验证是否启动成功
1666
2503 SecondaryNameNode
2920 Jps
2317 NameNode
2399 DataNode
成功启动服务后, 可以直接在浏览器中输入http://localhost:50070/访问Hadoop页面
2.5 将文件上传到HDFS
进入目录/usr/local/Cellar/hadoop/2.6.0/bin
#在HDFS上创建输入/输出文件夹 $ hdfs dfs -mkdir /user $ hdfs dfs -mkdir /user/input $ hdfs dfs -ls /user #上传本地file中文件到集群的input目录下 $ hdfs dfs -put /Users/&&&&&&&&/Downloads/test* /user/input
#查看上传到HDFS输入文件夹中到文件
$ hadoop fs -ls /user/input
#输出结果
-rw-r--r-- 1 &&&&&& supergroup 666 2015-04-06 10:49 /user/input/test01.html
-rw-r--r-- 1 &&&&&& supergroup 9708 2015-04-06 14:25 /user/input/test02.html
2.6 运行JAR文件
#在当前文件夹创建一个工作目录 $ mkdir WorkSpace
#下面这句可以不用,只要运行程序时,正确写入jar所在的完整路径即可 #将打包好的Jar复制到当前工作目录下(复制前路径就是你打包Jar时的存储路径) $ cp /Users/&&&&&/Desktop/WorkCount.jar ./WorkSpace #运行Jar文件,各字段含义:hadoop是运行命令命令,jar WorkSpace/WordCount.jar指定Jar文件,WordCount指定Jar文件入口类,/user/input指定job的HDFS上得输入文件目录,output指定job的HDFS输出文件目录 $ hadoop jar WorkSpace/WordCount.jar WordCount /user/input /user/output
#这里input和output在同一user目录中,方便管理
显示如下结果,则说明运行成功:
……省略大量代码
2.7 查看运行结果
$ hdfs dfs -ls /user/output
Found 2 items -rw-r--r-- 1 xumengting supergroup 0 2015-04-06 15:40 output/_SUCCESS -rw-r--r-- 1 xumengting supergroup 824 2015-04-06 15:40 output/part-r-00000
#查看结果输出文件中的内容
$ hdfs dfs -cat /user/output/part-r-00000
结果文件一般由2部分组成:
- _SUCCESS文件:表示MapReduce运行成功。
- part-r-00000文件:存放结果,也是默认生成的结果文件
参考文献:
[1]. 【Hadoop基础教程】5、Hadoop之单词计数——http://blog.csdn.net/andie_guo/article/details/44055863
[2]. MapReduce之Wordcount——http://andrewliu.tk/2015/03/29/MapReduce%E4%B9%8BWordCount/#more
[3]. Mac下Hadoop的配置及在Eclipse上编程

