【数据仓库与数据挖掘 - 决策树分类算法】信息量、无条件熵、条件熵、信息增益
决策树分类算法,针对离散数据来进行预测的。
ID3算法
缺点1:用信息增益来作为选择分支属性标准的话,偏向于取值较多的那个属性
缺点2:只能处理离散型的属性
缺点3:对于比较小的数据集是有效的
缺点4:可能会出现过度拟合的问题
1.信息增益

描述属性(条件属性)
类别属性(分类属性)“也是预测的对象”
信息增益=无条件熵-条件熵
G(C,Ak) = E(C) - E(C,Ak)
例题:
对于如表6.14所示的训练数据集。构造其决策树。有一个客户信息如下:X=(有房=‘否’,婚姻状况=‘已婚’,年收入=‘中’),采用决策树分类法,预测该客户的拖欠贷款类别。


结果:求得的年收入的信息增量最大,所以年收入是根节点(决策属性)




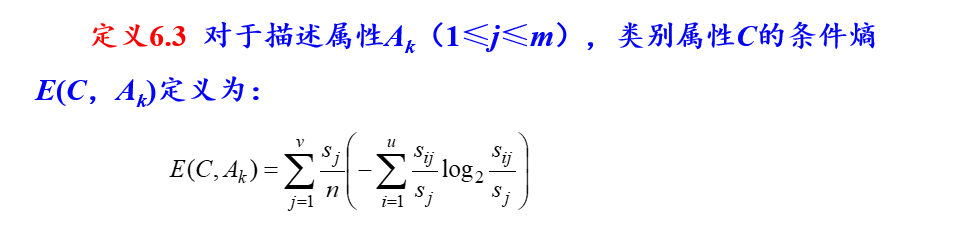


 浙公网安备 33010602011771号
浙公网安备 33010602011771号