
快速排序和冒泡排序
前言:
并不能一文就解释清楚排序到底是怎么一回事,我所有几乎文章都需要和别的材料配合才比较容易产生理解。
推荐书目:
- 《算法精解》
- 《啊哈,算法》
主要内容:
- 冒泡排序
冒泡排序是一种比较简单的排序算法,容易用C语言写成也非常好理解, 但是它的时间效率不高。 - 快速排序
快速排序是常用的排序算法,时间效率高,而且算法简单,但是乍一看上去,是没有冒泡排序那么“粗浅”的, 我不是说冒泡排序粗浅。冒泡两个字已经非常有意思了。
冒泡排序(Bubble sort)
算法过程
如果说你现在有一组数据需要排序:
1,5,2,3,0,7
如果是升序,冒牌排序做的就是:
- 比较第一个元素和第二个元素,判断第一个元素是否小于第二个元素。如果第一个元素大于第二个元素,那么这种情况是违背要求的序列规则的,就交换两个变量。使得第一个元素小于第二个元素。
1,5,2,3,0,7 // 在这里我们没有交换第一个元素和第二个元素 - 我们完成了第一个元素和第二个元素,让较大的那个元素成为第二个元素。
- 现在比较第二个元素和第三个元素,同理,我们就可以让第三个元素成为前三个数中最大的那个元素。
1,2,5,3,0,7 // 应该注意到,这一轮仅能够最后一个位置成为最大的值,而不能把顺序就此排好 - 我们这样做下去,我们就可以让这堆数据中最大的数到达最后一个位置。
1,2,3,0,5,7 // 这一轮结束,最大的数字7,到达了最后的位置(尽管它并没有移动,但是它在我们的算法中是“移动”的)
所以我们让这个比较(比较第一位置和第二位置的大小关系,不满足要求就交换,比较第二位置和第三位置的大小关系,不满足要求就交换)执行到结束的那个位置,就可以让那个位置得到包括那个位置以内前面所有数据的最大值(最小值)。
那我们第二轮也像第一轮那样做,只是我们不处理最后一个位置了,因为它就在它应该在的位置。我们让倒数第二个位置上获得它应有的数据:
1,2,0,3,5
让倒数第三个位置获得应有数据:
1,0,2,3
让倒数第四个位置获得应有的数据:
0,1,2 // 在这样的原始数据下,此时排序已经完成了, 0,1,2,3,5,7
// 但是我们先让它干下去
让正数第三: …
让正数第二: …
如果正数第二也拥有,那么此时正数第一个位置也应该拥有应有的数据了,也就是拥有最小的数据 :-)
代码
#include <stdio.h> int main(void) { int a[8] = {1, 3, 2, 0, 123, 12, 11, 4}; int size = 8; int i = 0; int j = 0; for (i = 0; i < size-1; ++i) // i表示着倒数第几个位置成为最大(小)值, { for(j = 0; j < size-i; ++j) // 因为i这个计数是从0开始的,i的最大值小于数据长度-1,j就能走到倒数数据长度-1个位置, 也就是j能走到正数第二个位置 // 随着i的值的变大,j走的范围在减小 { if (a[j] > a[j+1]) // 这里我们想要一个升序的结果,如果前面的比后面的大,就交换数据 { int tmp = a[j]; a[j] = a[j+1]; a[j+1] = tmp; } } } // 输出结果 for (i = 0; i < size; ++i) { printf("%4d", a[i]); } }
也许有人会注意到我的条件写的不漂亮,我也没办法,我总是对这个东西感到棘手,脑子里会是一团浆糊。:0
执行结果:
PS C:\Users\Jack\devproject> .项目1.exe 0 1 2 3 4 11 12 123
问题
我们注意到在前面的例子里面,在步骤没有完全结束的时候,就已经排好序了,后面的执行是多余的,请思考一下如何避开这些多余的执行?
快速排序(Quick sort)
快速排序是一种比冒泡排序高效的排序算法。它是每次把数据分成两组,保证其中一组的所有数据,肯定小于另外一组的所有数据。所以不管多大的蛋糕,如果是用一刀两半的方式去切的话,很容易就切出来小块蛋糕。这就是它的强大之处,
算法过程。
这个内容《啊哈!算法》这本书里面讲的比较好,我也是从这本书里面学习的
我们需要两个标记来标记位置,还需要一个容器来存放基准。
l标记左边的位置,r标记右边的位置,把第一个数据作为参照
如果说被排序的数据是:
3 1 2 6 5
- 我们可以简单的让l指向第一个数据,让r指向最后一个数据
![]()
- 然后用r来找本应该在参照左边的数据(也就是小于参照的数据),右边的向左移动
![]()
- 用l来找应该在参照右边的数据(也就是大于参照的数据),左边的向右移动,在此期间l应该小于r。
![]() 这里 l 和 r 直接相遇了,应该跳过第四步
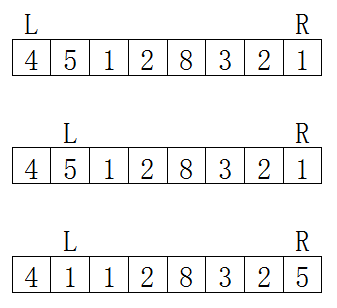
这里 l 和 r 直接相遇了,应该跳过第四步 - 当我们找到一个应该在参照右边的数值和应该在参照左边的数值,但是他们的位置是错的。那我们交换一下双方的位置,就可以让他们在正确的位置了
![]() 这个例子是为了解释第四步而造出来的。在这里L和R上的数据进行了交换
这个例子是为了解释第四步而造出来的。在这里L和R上的数据进行了交换 -
当l和r相遇的时候,我们就应将参照和l(r)的位置进行值交换。这样的话,得到的结果是:参照前面的数都比参照小,后面的都比参照大。
2 1 3 6 5我们能发现,l和r相遇的地方就是参照应该在的位置
-
所以如果我们处理的范围变小。处理 2 1:
1 2 // 结果处理 6 5:
5 6 // 结果 -
最终我们得到了排序之后的结果。
1 2 3 5 6
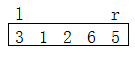

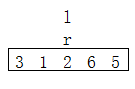
代码:
void qsort(int *p, int left, int right) { if (left > right) // 如果left>right { return; } int base = p[left]; // 设置参照 int l = left; // 两个“指针” int r = right; while (l != r) // 当没有找到参照应在的位置的时候 { while (base <= p[r] && l < r) { --r; } // 从右边开始找位置错了的数据 while (p[l] <= base && l < r) { ++l; } // 从左边开始找位置错了的数据 swap(p + l, p + r); // 交换两个数据的值 } p[left] = p[l]; p[l] = base; // 把参照的值和当前l的位置上的值进行交换 qsort(p, left, l-1); // 处理参照前面的部分 qsort(p, l+1, right); // 处理参照后面的部分 }
这个函数是递归的,简单的看,在函数体的结尾我们分别处理了前段和后段。而这个函数在当left>right的情况下返回(想想为什么是这个条件?)
执行测试:
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void swap(int *a, int *b);
void qsort(int *p, int left, int right);
int main(void)
{
srand((unsigned)time(NULL));
int a[6] = {1,1,-1,4,5,5};
for (int i = 0; i < 6; ++i)
{
a[i] = rand() % 10;
printf("%4d", a[i]);
}
putchar('\n');
qsort(a, 0, 5);
for (int i = 0; i < 6; ++i)
{
printf("%4d", a[i]);
}
system("pause");
return 0;
}
void swap(int *a, int *b)
{
int t = *a;
*a = *b;
*b = t;
}
void qsort(int *p, int left, int right)
{
if (left > right)
{
return;
}
int base = p[left];
int l = left;
int r = right;
while (l != r)
{
while (base <= p[r] && l < r) { --r; }
while (p[l] <= base && l < r) { ++l; }
swap(p + l, p + r);
}
p[left] = p[l]; p[l] = base;
qsort(p, left, l-1);
qsort(p, l+1, right);
}
测试结果:
多次测试
|
1
2
|
6 7 9 0 0 7
0 0 6 7 7 9请按任意键继续. . .
|
|
1
2
|
2 9 2 1 6 5
1 2 2 5 6 9请按任意键继续. . .
|
|
1
2
|
0 0 2 5 1 3
0 0 1 2 3 5请按任意键继续. . .
|
总结
快速排序的学习需要多写代码,不要害怕去学习,去copy,搞懂原理之后要尝试自己裸写,事实上我这篇文章并不是裸写的,但是在写完这篇文章之后,我感觉我快排学的更好了 :)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号