结对第二次—文献摘要热词统计及进阶需求
班级:软件工程1916|W(福州大学)
作业:结对第二次—文献摘要热词统计及进阶需求
结对学号:221600315 黎焕明 221600319 李彦文
GitHub基础需求项目地址:基础需求
GitHub进阶需求项目地址:进阶需求
作业目标: 实现一个能够对文本文件中的单词的词频进行统计的控制台程序。在基本需求实现的基础上,编码实现顶会热词统计器。
具体分工:两个人一起负责分析需求,然后主要分析需求和文档编写主要是221600319,221600315主要负责部分代码的实现。
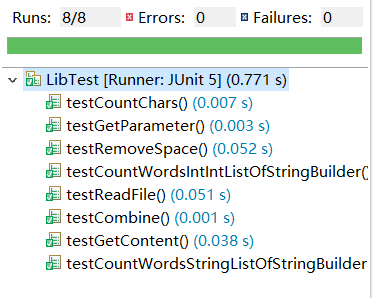
一、github代码签入记录
- 基本需求
![]()
- 进阶需求
![]()

二、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 660 | 1010 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 180 | 60 |
| • Design Spec | • 生成设计文档 | 60 | 180 |
| • Design Review | • 设计复审 | 60 | 120 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 无 | 无 |
| • Design | • 具体设计 | 120 | 180 |
| • Coding | • 具体编码 | 240 | 300 |
| • Code Review | • 代码复审 | 0 | 200 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 60 | 90 |
| Reporting | 报告 | ||
| • Test Report | • 测试报告 | 无 | 无 |
| • Size Measurement | • 计算工作量 | 无 | 无 |
| • Postmortem & Process Improvement Plan | • 事后总结并提出过程改进计划 | 60 | 60 |
| 合计 | 660 | 1010 |
三、解题思路
1. 基本需求:拿到题目后,看到基本需求时感觉并不难,因为之前写过类似的程序。要求满足三个功能,第一个是字符统计,第二个是单词统计,第三个是词频统计。基本想法是将这三个功能分别写到三个函数中,然后通过主函数调用返回相应的结果并且打印输出。
2. 进阶需求:是在基本需求的基础上添加了参数判断要求,新增的功能是加入词组统计、单词或词组加入权重来计算最终的频数。参数判断单独封装,程序执行开始前就要将所有参数全部处理,方便之后使用,所以将参数判断结果利用类属性记录。首先是加入权重这个问题,我们的想法是直接在词频统计函数中加入判断功能,如果开启权重功能,那么属于TITLE的词出现一次词频加10,其他情况都一样。词组统计功能,将这个功能单独分装成一个函数,利用正则来匹配词组。
3. 资料查找:经过初步分析之后,上网看了一些介绍单词统计,词组统计的博客。大致了解了一下他们的思路,基本有两种,一种是循环读取判断,再一种就是正则表达式匹配。我们更倾向于后一种,这种方法比较直观,体现再代码上就是比较简洁。
四、基本需求设计实现过程:
- 代码如何组织:
一共用两个类,一个类是主程序入口Main,另外一个是文本处理类Lib。Main类调用Lib类的静态函数countChars、countWords、countLines分别统计字符数单词数和行数,然后直接输出,整体结构较为简单。
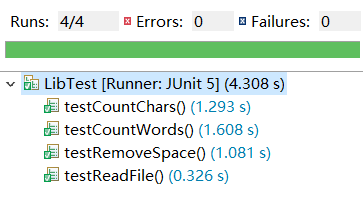
-
单元测试:
![]()
![]()
-
类图:
![]()
-
程序改进思路:

在基本功能完成后,进行测试时发现,如果测试文件比较大,程序读取文件非常缓慢。通过debug发现是因为在读取文件时使用了节点流,当文件读取采用处理流方式时文件读取会快很多。
因为刚开始写时需求分析时间很少就开始写代码,导致我们直接用了比较“土”的方法来实现,在进阶需求写爬虫才想起来用正则表达式实现可以简单地非常多。同时因为List<StringBuilder>的deleteChar方法效率非常低,我们直接重新分配了内存,这部分处理时间复杂度缩短了非常多。
- 代码说明及流程图:
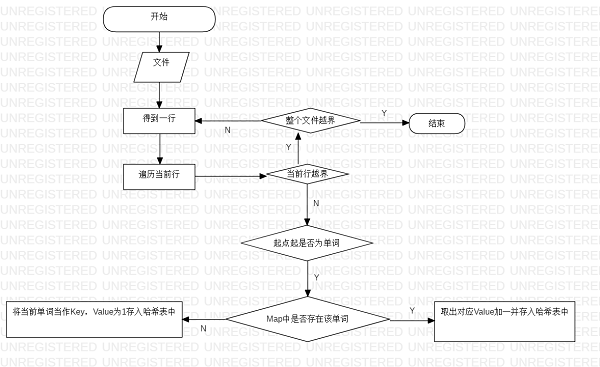
基础需求实现比较简单,但是countWords有一定的难度,刚开始并没有想到用正则,而是直接遍历。该方法接收StringBuilder的List并返回一个哈希表,该方法遍历List的每一行,然后遍历该行,如果找到单词就检查哈希表是否存在,如果哈希表存在该单词就取出哈希表里面的值+1并put进哈希表,如果哈希表不存在该单词,则将该单词直接put进哈希表,key为单词,value为1。最后对哈希表进行按值排序并返回哈希表。
/**
* 统计单词数
* @param stringList
* @return
*/
public static Map<String,Integer> countWords(List<StringBuilder> stringList){
Map<String,Integer> hashTable=new LinkedHashMap<>();
/* 计数器 */
int count;
/* 是否为单词的标志*/
boolean flag;
/* 统计单词数,如果存在单词就放进哈希表 */
for(StringBuilder line:stringList){
count=0;
flag=true;
for(int i=0;i<line.length();++i){
if(line.charAt(i)<='z'&&line.charAt(i)>='a'){
++count;
}else if(line.charAt(i)<='9'&&line.charAt(i)>='0'){
if(count<4){
flag=false;
}
++count;
}else if(count>3&&flag){
String key=line.substring(i-count,i);
/* 将单词存入哈希表 */
hashTable.merge(key, 1, (a, b) -> a + b);
count=0;
}else{
count=0;
flag=true;
}
}
}
/* 对哈希表进行排序 */
List<Map.Entry<String, Integer>> keyList = new LinkedList<Map.Entry<String, Integer>>(hashTable.entrySet());
keyList.sort( new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1,
Map.Entry<String, Integer> o2) {
return Integer.compare(o2.getValue().compareTo(o1.getValue()), 0);
}
});
hashTable.clear();
for(Map.Entry<String, Integer> entry:keyList){
hashTable.put(entry.getKey(),entry.getValue());
}
return hashTable;
}
- 流程图:
![]()
五、进阶需求设计实现过程
-
代码如何组织 :
同样是两个类,一个类是主程序入口Main,另外一个是文本处理类Lib。Main类调用Lib类的静态函数getParameter获得参数,然后根据参数调用readFile读取文件,以及打开输出文件流,调用Lib类静态函数getContent获得result.txt中的内容,然后Main类调用Lib类的静态函数countChars、countWords、countLines分别统计字符数单词数和行数,然后直接输出。 -
单元测试:
![]()
![]()
类图
![]()
-
代码说明及流程图:
进阶需求整体比较难,主要难在词组词频统计,将获取到的文本放在两个List中,行的一行字符串并记录为volatileString,使用正则表达式“[a-z0-9]”+对volatileString进行分割,得到一个数组的单词,然后对数组内所有单词使用"[a-z]{4}[a-z0-9]*" m个一组进行正则匹配,确定该单词是否为单词,如果为词组,通过使用正则表达式“单词1[a-z0-9]+单词2[a-z0-9]+单词m”对volatileString进行匹配得到包含分隔符的完整单词str(①),然后将str同基础需求一样存入map,然后通过volatileString.indexof(单词1)和单词1.length得到单词1初始位置beginindex和结束位置endIndex,然后将line赋值为截取0-beginIndex和endIndex到volatileString.length(),以上操作是为了避免①位置匹配到不相符的结果。


/**
* 统计词组词频
* @param stringList
* @return
*/
static Map<String,Integer> countWords(int delete, int m, List<StringBuilder> stringList){
Map<String,Integer> hashTable=new LinkedHashMap<>();
// 创建 Pattern 对象
String patternString = "^[a-z]{4}[a-z0-9]*";
Pattern pattern = Pattern.compile(patternString);
boolean flag;
for(StringBuilder line:stringList){
String volatileString= "";
if(line.length()>delete) {
volatileString = line.substring(delete);
}
String notAlphaandNumber="[^a-z0-9]+";
String [] strings=volatileString.split(notAlphaandNumber);
for(int i=0;i<strings.length-m+1;i++){
//是否全为单词
flag=true;
for(int j=i;j<i+m&&j<strings.length;++j){
Matcher matcher = pattern.matcher(strings[j]);
if(!matcher.find()){
flag=false;
break;
}
}
//如果全为单词
if(flag){
StringBuilder regEx= new StringBuilder();
for(int k=0;k<m;++k){
regEx.append(strings[i + k]);
if(k!=m-1)regEx.append(notAlphaandNumber);
}
Pattern compile = Pattern.compile(regEx.toString());
Matcher matcher=compile.matcher(volatileString);
if(matcher.find()){
hashTable.merge(matcher.group(), 1, (a, b) -> a + b);
}
}
int beginIndex=volatileString.indexOf(strings[i]);
// int endIndex=volatileString.indexOf(strings[i+m-1])+strings[i+m-1].length();
int endIndex=volatileString.indexOf(strings[i])+strings[i].length();
// volatileString=volatileString.substring(0,beginIndex)+volatileString.substring(endIndex);
volatileString=volatileString.substring(0,beginIndex)+volatileString.substring(endIndex);
}
}
return hashTable;
}
-
改进的思路:
刚开始也是使用基本需求那样一个个比对,但是因为写爬虫的时候突然想起来还有正则表达式,于是直接使用正则表达式进行匹配,然后使用Pattern.compile可以更加快速的进行正则匹配,同时因为String是Immutable的,所以进阶需求和基础需求一样都是使用StringBuilder进行字符串处理。 -
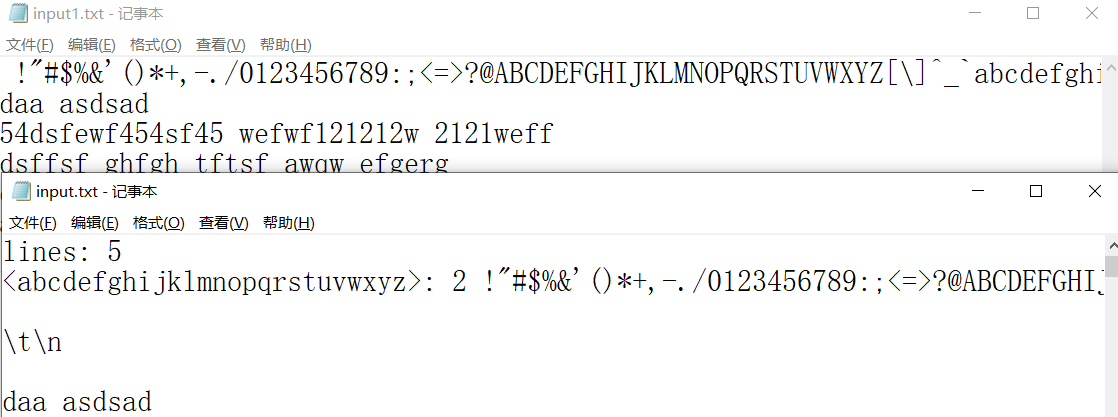
项目测试
- 基本需求
![]()
![]()
![]()
- 进阶需求
![]()
![]()
- 基本需求
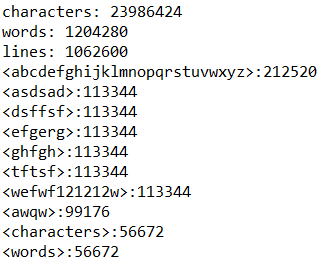
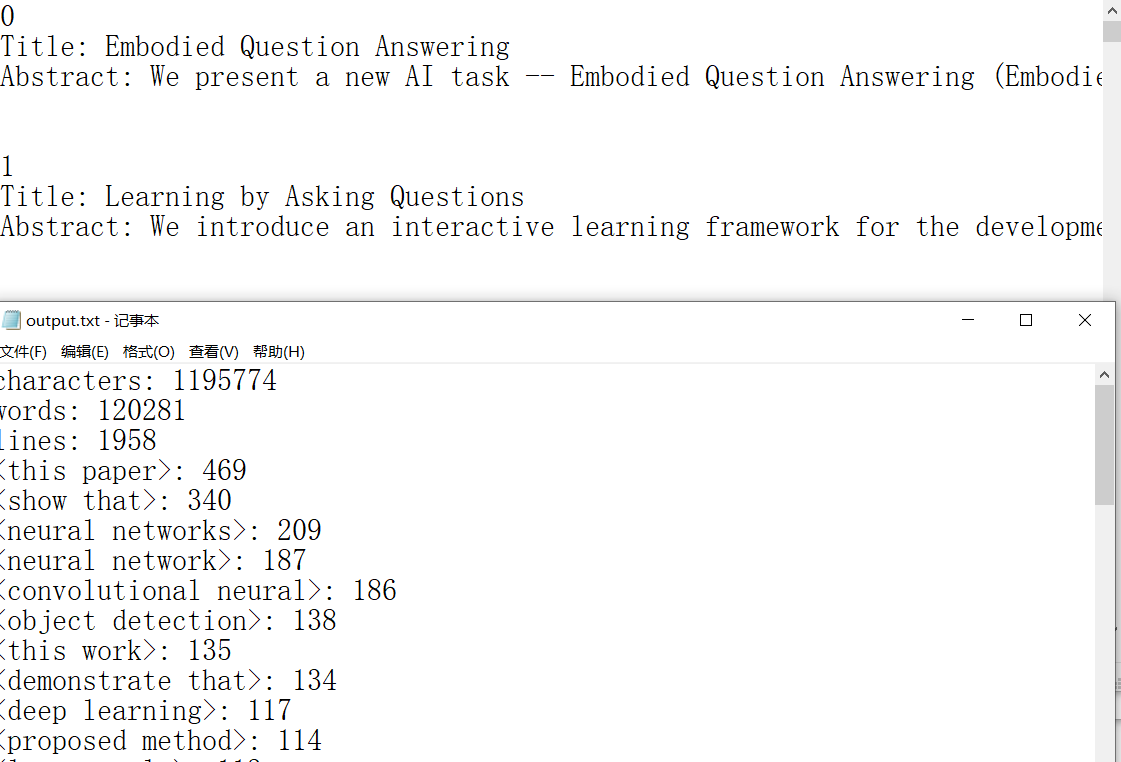
六、爬虫简介
爬虫是自己使用Python实现的,直接用正则匹配所有div为ptitle的节点并获取链接,然后对链接的网页内容进行正则匹配将结果输出到文件中。使用方法:Python main.py
# coding=utf-8
import re
import requests
respose=requests.get('http://openaccess.thecvf.com/CVPR2018.py')
text=respose.text
urls=re.findall(r'class="ptitle".*?href="(.*?)"',text,re.S)
output=open("result.txt","w",encoding='utf-8')
j=0
print(respose.encoding)
for i in urls:
url='http://openaccess.thecvf.com/'+i
respose = requests.get(url)
text = respose.text
paper_title = re.findall('id="papertitle">\n(.*?)<',text, re.S)
abstract = re.findall('id="abstract" >\n(.*?)<', text, re.S)
output.write(str(j)+"\n")
output.write("Title: ")
output.write(paper_title[0])
output.write("\n")
output.write("Abstract: ")
output.write(abstract[0])
output.write('\n\n\n')
j+=1
七、遇到的困难与解决方法
- 需求分析不够
重头开始需求分析,然后重构代码。
- 代码耦合性比较高
通过分离不同的模块和功能降低整体的耦合度。
- 两个人沟通不够及时造成了理解分歧
下次记得及时和多沟通。
八、队友评价
221600315代码能力较强,在需求分析完成后很快就将部分基本代码写了出来,确实很厉害。讨论之后确定要用Java实现,我自己因为Java好久没看了,所以要重新复习一下,怕时间来不及,然后就让队友先写。在写的过程中共同讨论遇到的问题,以及需求方面的一些研究。这次作业队友花费的时间比较多,让我有了时间复习Java,还是非常感谢他的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号