只有一百行的xss扫描工具——DSXS源码分析
0x00 废话
DSXS是一个只有一百行代码的xss扫描器,其作者刚好就是写sqlmap的那位,下面来看一下其扫描逻辑。0x01部分文字较多,感觉写的有点啰嗦,如果看不下去的话就直接看最后的0x02的总结部分。
0x01 扫描逻辑
程序有两个非并行的逻辑,第一个逻辑是检测dom型xss,第二个逻辑是检测经过后端的xss。在执行两个逻辑之前,程序会先判断目标路径上是否有参数值为空的情况,有则赋为1,比如:baidu.com/?id=99&name=&age=转换成baidu.com/?id=99&name=1&age=1。转换完成后,进入xss检测逻辑部分。
第一个逻辑:dom型xss
首先根据dom_filter_regex去掉响应包中的内容,然后在响应中查找dom_patterns,如果存在,则提示可能存在dom-xss
第二个逻辑:经过后端的xss
首先要知道这里有一个核心的正则表达式list,一共有九个元组,每个元组都代表输出点在dom结点中的一个确定的位置,比如:script标签内、单引号内、注释内。。然后对应每个位置,还有对应的攻击方法,比如在单引号内就需要用单引号逃逸,即单引号在响应中不能被转义,如果被转义就完了。其中每个元组有四个元素,详细看下面:
REGULAR_PATTERNS = ( # each (regular pattern) item consists of (r"context regex", (prerequisite unfiltered characters), "info text", r"content removal regex") # 格式(匹配有可能存在xss的字符串的正则,攻击成功需要哪些字符未经过滤,说明(简易表达匹配格式),获取响应包后首先筛掉的字符的regexp)
(r"\A[^<>]*%(chars)s[^<>]*\Z", ('<', '>'), "\".xss.\", pure text response, %(filtering)s filtering", None),
(r"<!--[^>]*%(chars)s|%(chars)s[^<]*-->", ('<', '>'), "\"<!--.'.xss.'.-->\", inside the comment, %(filtering)s filtering", None),
(r"(?s)<script[^>]*>[^<]*?'[^<']*%(chars)s|%(chars)s[^<']*'[^<]*</script>", ('\'', ';'), "\"<script>.'.xss.'.</script>\", enclosed by <script> tags, inside single-quotes, %(filtering)s filtering", r"\\'"),
(r'(?s)<script[^>]*>[^<]*?"[^<"]*%(chars)s|%(chars)s[^<"]*"[^<]*</script>', ('"', ';'), "'<script>.\".xss.\".</script>', enclosed by <script> tags, inside double-quotes, %(filtering)s filtering", r'\\"'),
(r"(?s)<script[^>]*>[^<]*?%(chars)s|%(chars)s[^<]*</script>", (';',), "\"<script>.xss.</script>\", enclosed by <script> tags, %(filtering)s filtering", None),
(r">[^<]*%(chars)s[^<]*(<|\Z)", ('<', '>'), "\">.xss.<\", outside of tags, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->"),
(r"<[^>]*=\s*'[^>']*%(chars)s[^>']*'[^>]*>", ('\'',), "\"<.'.xss.'.>\", inside the tag, inside single-quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|\\"),
(r'<[^>]*=\s*"[^>"]*%(chars)s[^>"]*"[^>]*>', ('"',), "'<.\".xss.\".>', inside the tag, inside double-quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|\\"),
(r"<[^>]*%(chars)s[^>]*>", (), "\"<.xss.>\", inside the tag, outside of quotes, %(filtering)s filtering", r"(?s)<script.+?</script>|<!--.*?-->|=\s*'[^']*'|=\s*\"[^\"]*\""),
)
人话版如下:
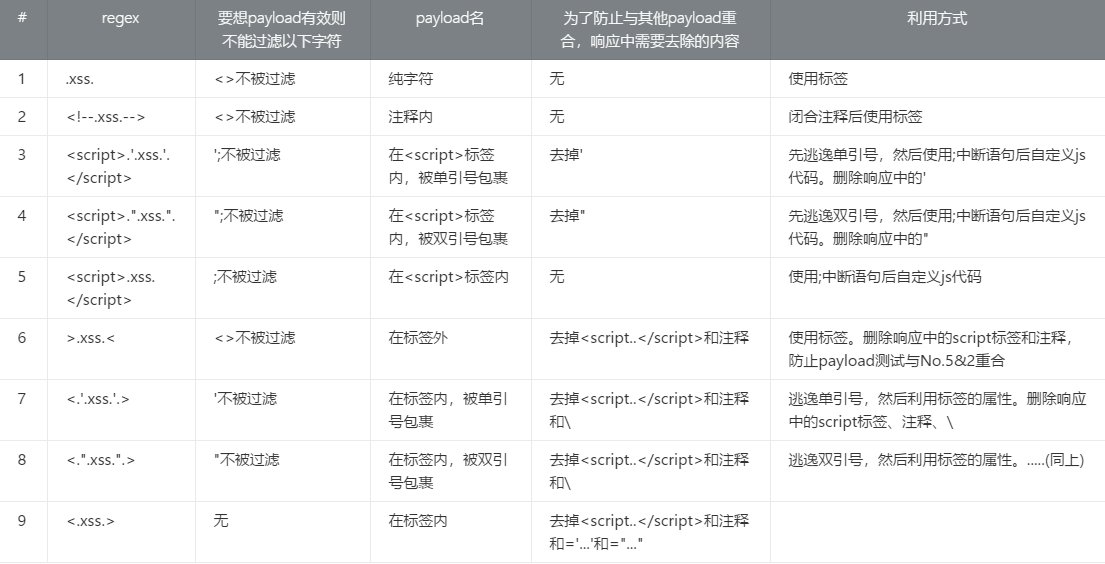
这个表说了,下面说一下检测的大体流程。首先是发送payload,然后查找payload的输出点,接着再看这个输出点对应上边表中的哪个位置。找到对应的位置之后再看如果在这个位置要利用成功需要哪些字符不被转义,然后在响应中查找payload,确定payload中‘不可被转义的特殊字符’前是否被加上了反斜杠\,如果有则认为被转义,并继续往下找,直到每个不可被转义的字符至少在响应中未被转义地出现了一次,才会认为存在漏洞。
下面根据代码说一下。
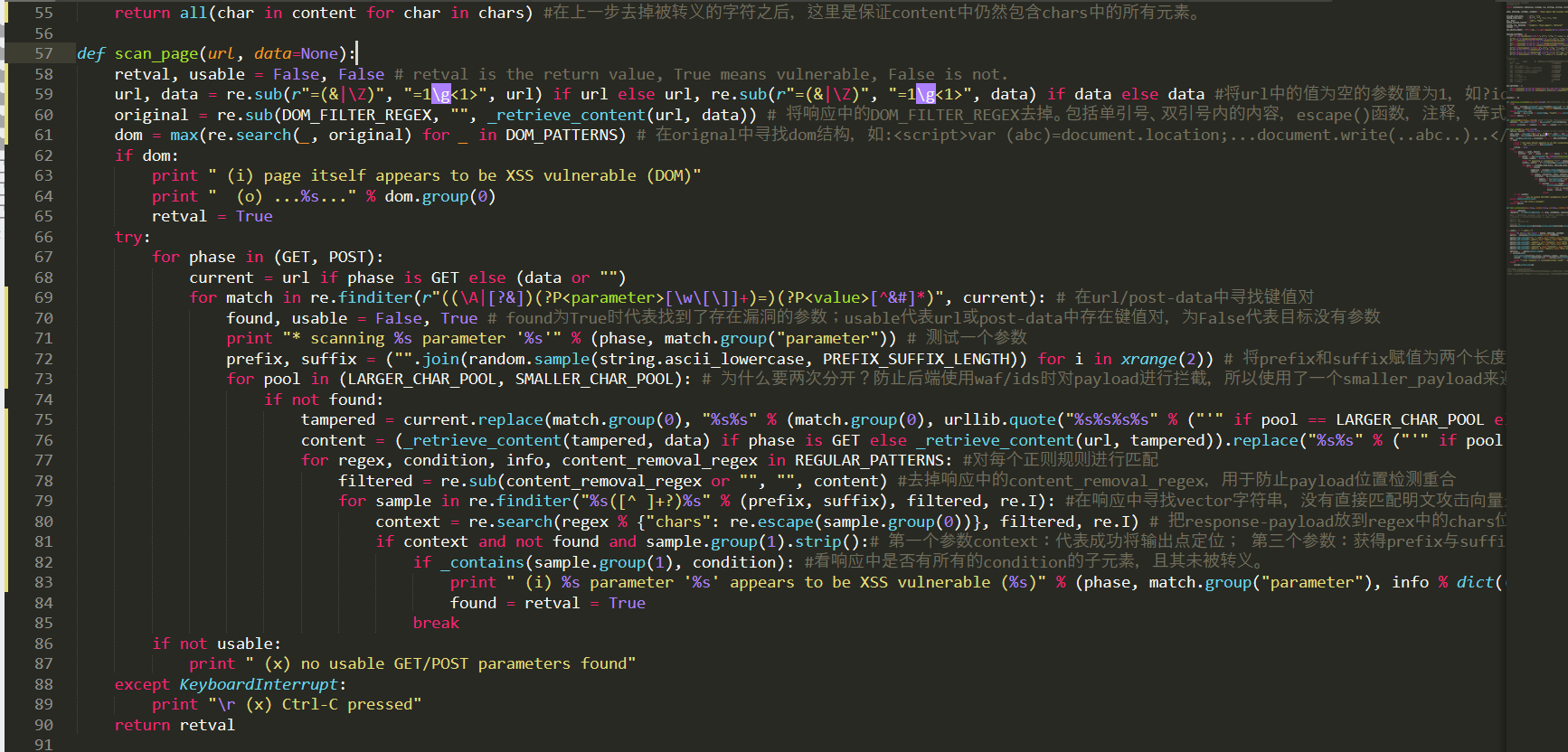
62-65行是dom-xss检测,是属于上面的第一个逻辑,这里就不再展开。从67行往下看,首先是分别进行GET和POST请求,然后到了69行。
这里在url和post-data中查找键值对(参数)的位置,然后对每个参数进行以下的测试。
从72行可以看到,首先赋值两个长度为5的随机字符的字符串:prefix和suffix
然后使用一个for循环,针对larger_char_pool和smaller_char_pool进行单独的测试(这两个list分别是:(''', '"', '>', '<', ';') 和('<', '>')。之所以要用两个list的原因是防止后端使用waf/ids时对payload进行拦截,所以使用了一个smaller_payload来避免过于明显的payload[即有较少的特殊字符]) 。
进入75行,这里先构造payload,payload格式为prefix+pool中所有字符的随机排序+suffix,如果这个pool是larger_char_pool,则这里在payload之前加一个单引号'原因如下:
1) .试图触发xss
2) .故意构造一个错误的sql语句用于报错,试图在报错信息中寻找触发点
这里暂且把prefix与suffix中间的部分称为vector。构造完payload之后直接发送,然后获取返回内容。如果这个pool是larger_char_pool,那么这里就要去掉prefix之前的单引号',这个单引号的作用刚刚已经说了,至此已经完成了它的使命,这里自然要从响应中去掉,防止干扰。
然后到77行,下面开始使用regular_patterns对相应内容进行测试,首先根据content_removal_regex去掉响应中的内容(因为payload有重合部分,所以要通过这种方式来避免重合的检测,即表中每个元组的第四个元素),然后在响应中寻找(prefix+...+suffix) [注:这里的规则大致是prefix.*suffix,不指定中间的部分为vector,因为vector有可能被后端转义掉了],暂时称之为response-payload。
如果可以找到,就说明这个参数的值是会被输出到响应中的(先不管有没有过滤),下面的逻辑就要检测这个参数是否可以利用。首先需要确定response-payload的输出点在哪个位置(script标签内?注释内?引号内?等等,详见REGULAR_PATTERNS),然后再根据输出点来确定在这个位置利用成功需要哪些字符不被过滤。
ok,逻辑大概理清楚了,下面是程序的实现。首先是输出点定位,在第80行,程序将response-payload插入到regular_patterns的regex(每个元组的第一个元素)中的chars位置,如果可以在响应中匹配到regex,就说明定位成功。然后下一步就是检查字符过滤情况,程序通过在82行调用_contains函数来确定“不可被过滤的字符”在响应中是否被过滤(即判断这些字符前是否有反斜杠\),对prefix和suffix中vector位置的字符串进行检测,_contains代码如下:
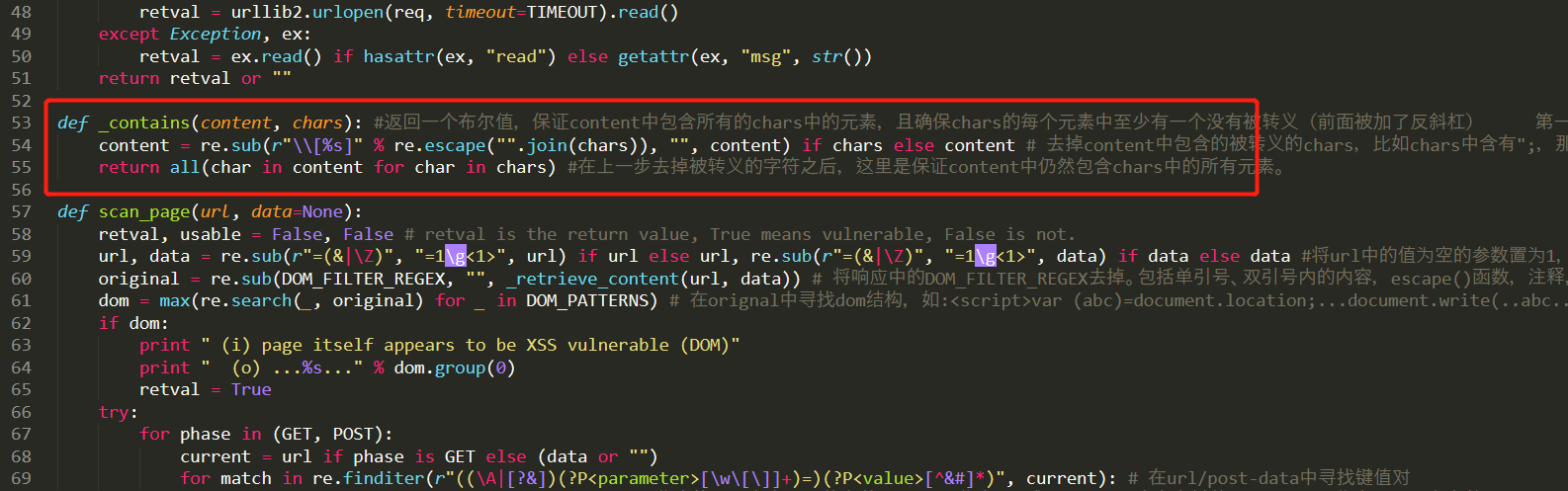
这里如果没有被过滤,这认为可能存在漏洞。
0x02 总结
至此,这个代码分析结束。来个总结,dom xss的检测方法就是通过正则表达式来对一些有可能造成危害的函数进行匹配,并且匹配其参数是否可控。至于经过后端型xss,这里先是通过正则判断输出点在dom树中的位置,然后确定如果想要触发xss需要哪些字符不被过滤,接着再根据响应包中的payload中的特殊字符前是否有反斜杠来确定其是否被过滤从而确定是否满足上面的条件,满足则存在漏洞。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号