
面经
1.七层网络结构
应用层、表示层、会话层、传输层、网络层、数据链路层、物理层。
2.TCP与UDP的区别
a.数据可靠与不可靠,基于连接和无连接。
b.TCP会有三次握手、确认、窗口、重传、拥塞控制等。UDP无
c.TCP需要建立连接,慢,占用系统资源,效率较低,且容易受到攻击。UDP快、但网络拥堵时容易丢包。
d.TCP适用于保证数据安全的场景:http、ssh、pop、telnet、ftp、smtp。UDP适用的场景:语音、视频、TFTP等。
e.TCP点对点连接。UDP可以一对一,一对多,多对多。
TCP有的一些特性:
。ARQ(自动重复请求):出错时尝试简单的 重新发送。
。窗口:如果你把在一个通信对话中发送的所有分组排成长长的一行,但只能通过一个小孔来观察他们,你就只能看到他们的一个子集——像通过一个窗口观看一样。
。流量控制:接收方跟不上发送方的速率时,会强迫发送方慢下来。拥塞控制属于流量控制的一种形式。
3.红黑树
红黑树:是平衡搜索树中的一种,可以保证在最坏情况下基本动态集合操作的时间复杂度为O(lgn);
树中每个结点包含5个属性:color、key、left、right、和p。
性质:
1.每个结点或是红色的或是黑色的。
2.根节点是黑色的。
3.每个叶节点是黑色的。
4.如果一个节点是红色的,则它的两个子节点都是黑色的。
5.对每个节点,从该结点到其所有后代叶结点的简单路径上,均包含相同数目的黑色结点。
4.平衡二叉树
它是一 棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树
5.HashMap原理
待完善。
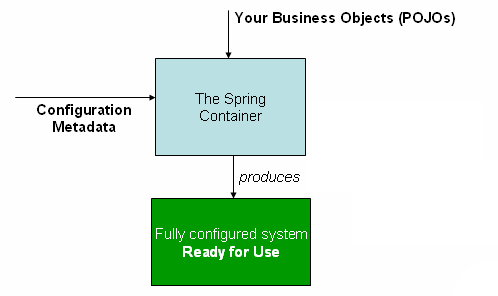
6.Spring IoC原理
IoC(控制反转)也称为依赖注入(DI)。在传统的开发模式中,通常在一个类中使用new Object来创建其他类的对象,这样,我们程序的耦合度会变得很高。而Spring通过容器来管理对象之间的依赖关系,通俗来讲,如果对象需要依赖其他对象,那么就向Spring容器来提交自己的需求对象,Spring容器将提供给对象请求的需求对象。对象的生命周期以及相互之间的协调不由自己掌握,而是由Spring容器来掌握,这个过程和传统相比是相反的,因此称为控制反转。
两个包:org.springframework.beans和org.springframework.context;
两个主要接口:BeanFactory,ApplicationContext
7.Redis回收策略
-
volatile-lru:从已设置过期时间的数据集中挑选最近最少使用的数据淘汰
-
volatile-ttl:从已设置过期时间的数据集中挑选将要过期的数据淘汰
-
volatile-random:从已设置过期时间的数据集中任意选择数据淘汰
-
allkeys-lru:从数据集中挑选最近最少使用的数据淘汰
-
allkeys-random:从数据集中任意选择数据淘汰
-
no-enviction:禁止回收数据
8.大文件查找指定条件的行(太大,无法加载到内存,在磁盘中)
一种不太好的方式:拆分大文件为小文件。
另一种大概可能是加索引排序??
9.如何同步。如何解决并发。
a.synchronized关键字
b.锁
c.Java集合框架中的一些类需要了解。
10.乐观锁和悲观锁
乐观锁:每次拿数据的时候认为别人不会修改,所以不会上锁,但是在更新时会判断在此期间别人有没有更新操作的数据,可以使用版本号version等机制作为更新依据。乐观锁适应于多读的情况。可以使用CAS实现。
悲观锁:总是假设最坏的情况,每次操作数据之前都会上锁,比如行锁、表锁、读写锁等。使用synchronized实现。
使用的时机:当访问冲突概率小于20%的时候,使用乐观锁,否则使用悲观锁,且乐观锁的重试次数不少于3次。
11.GC
四种算法:标记清理、复制、标记整理、分代收集。
a.Serial收集器:单线程收集器,采用复制算法,STW(stop the world),在进行垃圾收集时,必须暂停其他所有的工作线程,直到它收集结束。优点:在单线程内存较小环境下,无线程交互,效率较高。
b.ParNew收集器:Serial的多线程版本。与Serial几乎一模一样,除了是多线程外。优点:在新生代中只有此和Serial能够配合CMS收集器工作。
c.Parallel Scavenge收集器:并行清除收集器。使用复制算法,也是并行的多线程收集器。优点:达到一个可控制的吞吐量。参数MaxGCPauseMillis可以尽可能的保证内存回收花费的时间不超过设定值。GCTimeRatio参数能设置吞吐量大小。UseAdaptiveSizePolicy:GC自动调节策略,虚拟机会根据当前系统的运行情况收集性能监控信息。动态调整参数以提供合适的停顿时间和最大的吞吐量。
d.Serial Old收集器:Serial 收集器的老年代版本。也是单线程的。使用标记整理算法。也是Client模式下的虚拟机使用。
e.Parallel Old收集器:Parallel Scavenge的老年代版本。使用标记整理算法。优点:在注重吞吐量和CPU资源敏感的场合可以优先考虑这两种收集器。
f.CMS收集器:Concurrent Mark Sweep 标记清除算法实现。以获取最短回收停顿时间为目标的收集器,重视服务器的响应速度。整个过程分四步:初始标记、并发标记、重新标记、并发清除。1、 3需要STW。并发收集,低停顿。缺点:对CPU资源敏感,耗费cpu资源;无法处理浮动垃圾,在并发清理时产生的垃圾;空间碎片过多。
g.G1收集器:1.7商用。优点:并行和并发:充分利用多cpu、多核环境来缩短STW时间。分代收集。空间整合:整体是标记整理,局部是复制。可预测的停顿:建立可预测的停顿时间模型。将整个Java堆划分为多个大小相等的独立区域(Region)。虚拟机使用Remembered Set来避免全堆扫描。四个步骤:初始标记、并发标记、最终标记、筛选回收。
12.TCP三次握手和四次挥手
TCP头部:标准长度是20字节。
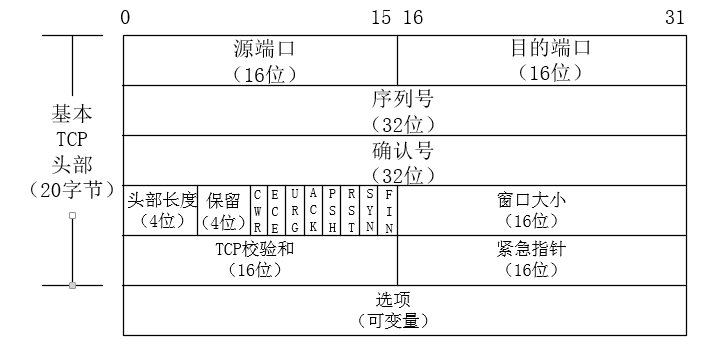
序列号:标识了TCP发送端到TCP接收端的数据流的一个字节,该字节代表着包含该序列号的报文段的数据中的第一个字节。
确认号:该确认号的发送方期待接收的下一个序列号。
CWR:拥塞窗口标示。发送方降低它的发送速率。
ECE:ECN回显。发送方接收到了一个更早的拥塞控制。
URG:紧急。紧急指针有效。
ACK:确认。确认好字段有效。
PSH:推送。接收方应尽快给应用程序传送这个数据。
RST:重置连接。经常是因为错误。
SYN:用于初始化一个连接的同步序列号。
FIN:该报文段的发送方已经结束向对方发送数据。

建立连接步骤:
步骤一:主动开启者(客户端)发送一个SYN报文段,并指明自己想要连接的端口号和它的客户端初始序列号(记为ISN(c))。
步骤二:服务器发送自己的SYN报文段作为响应,并包含了它的初始序列号(记为ISN(s)),此外,为了确认客户端的SYN,服务器将包含的ISN(c)数值+1后作为返回的ACK数值。因此,每发送一个SYN,序列号就会自动+1.如果出现丢失的情况,该SYN将会重传。
步骤三:为了确认服务器的SYN,客户端将ISN(s)的数值+1后作为返回的ACK数值。
断开连接步骤:
步骤一:连接的主动关闭者发送一个FIN段指明接收者希望看到自己当前的序列号K和一个ACK段用于确认对方最近一次发来的数据L。
步骤二:连接的被动关闭者将K的数值+1作为响应的ACK值,以表明它已经成功接收到主动关闭者发送的FIN。
步骤三:上层的应用程序会被告知连接的另一端已经提出了关闭的请求。这将导致应用程序发起自己的关闭操作,即发送自己的FIN和序列号L。
步骤四:为完成连接的关闭,最后发送的报文段还包含一个ACK用于确认上一个FIN。如果出现FIN丢失的情况,那么发送方将重新传输知道接收到一个ACK确认标识。
13. 公平锁非公平锁
公平锁:如果一个锁是公平的,那么锁的获取顺序就应该符合请求的绝对时间顺序,也就是FIFO。
非公平锁:不会按照FIFO顺序来执行同步,而是使用抢占式,只要CAS设置同步状态成功,则表示当前线程获取了锁。
公平锁往往没有非公平锁效率高。但不是所有的场景都是TPS作为唯一指标。
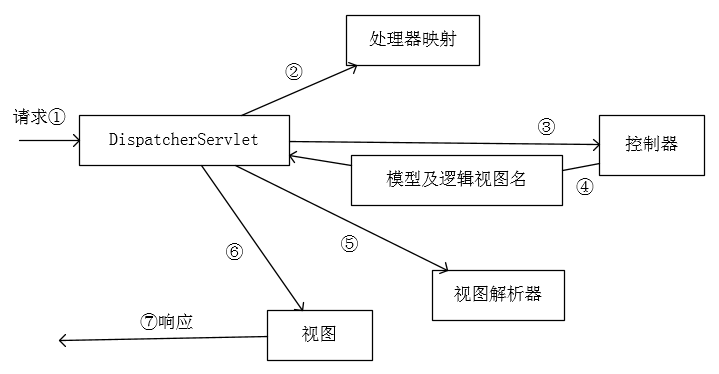
14.Spring MVC的请求流程
Spring MVC的所有请求都会通过一个前端控制器Servlet。名称为DispatcherServlet①。然后DispatcherServlet查询一个或者多个处理器映射(Handler Mapping)②来确定处理请求的控制器(Controller)③,是根据请求携带的URL信息确定的。之后控制器根据请求的数据,委托给一个或多个服务对象处理相关业务逻辑,完成后将返回的信息(称为Model)返回到用户并在浏览器中显示。大部分时候需要将Model格式化输出,比如HTML,所以控制器会将Model数据打包,并且标识出用于渲染输出的视图名,返回给DispatcherServlet④。之后DispacherServlet将使用视图解析器(View Resolver)⑤来将逻辑视图名匹配为一个特定的视图实现。可能是JSP。这个特定的视图将使用模型数据渲染输出⑥,通过响应对象传递给客户端⑦。
15.进程的状态
-
进程是资源分配的最小单位,线程是程序执行的最小单位。
-
进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
-
线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。不过如何处理好同步与互斥是编写多线程程序的难点。
-
但是多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间
17.git和svn的区别
- git是分布式的,svn是集中式的
- git 只关心文件数据的整体是否发生变化,而SVN这类版本控制系统则只关心文件内容的具体差异。
- git大部分操作无需联网,若无网络,可以先提交的本地,等到有网络后,提交的服务器。而svn只能依赖于网络查看和更新。(git的commit一定要频繁)
- git的克隆很快,但是svn很慢。
- svn有bug,可能造成提交丢失,git使用 SHA-1哈希值进行校验。
18.Spring Bean的生命周期
- 实例化
- 设置其属性值
- BeanNameAware的setBeanName方法
- BeanFactoryAware的setBeanFactory方法
- BeanPostProcessors的postProcessorBeforeInitailiztion方法
- InitializingBean的afterPropertiesSet方法
- Bean标签中init-method属性中的方法
- 使用bean
- DisposableBean中的destory方法
- Bean标签中destory-method方法
19.事务
事务的四个特性:
A:原子性,一组操作要么全部执行,要么全部不执行。
C:一致性,数据库总是从一个一致性状态转换为另外一个一致性状态。
I:隔离性,一个事务所做的操作在提交以前,对于其他的事务是不可见的。
D:持久性,事务一但提交,那么所做的修改会永久保存到数据库中。
事务的四种隔离级别:
read uncommitted,未提交读,事务中的修改,即使没有提交,对其他事务也都是可见的。事务可以读取未提交的数据,称为脏读。
read committed,提交读(也叫不可重复读),大部分数据库是这种隔离级别,一个事务从开始直到提交之前,所做的任何修改对其他事务都是不可见的。两次执行同样的查询,可能得到不一样的结果。如果一个事务在提交数据之前,另一个事务可以修改和删除这些数据,就会发生不可重读。
repeatable read,可重复读,保证两次读取的数据结果是一致的。但是会产生幻行,当某个事务在读取某个范围内的记录时,另外一个事务又会在该范围内插入新的记录,再次读取时会产生幻行。MySql的默认隔离级别。
serializable,可串行化,强制事务串行,读取的每一行加锁。
MVCC:保存数据在某个时间点的快照。每行记录后面有两个隐藏列,一个保存了行的创建时间,一个保存了删除时间。
20.索引
索引是什么以及他的作用,一定要弄明白。如果可以的话,建议查看《高性能MySQL》这本书的第五章。
索引(MySQL中也称为“键(key)”):是一种数据结构,存储引擎用来快速找到记录的一种数据结构,这是索引的基本功能。我觉得不只是存储引擎,平常中的文件也是可以应用索引的,因为本质上都是存储在磁盘上的文件。不知道理解的对不对。
索引可以包含一个或多个列的值。如果有多个列,那么列的顺序也十分重要。
MySQL的常用的索引类型有4种:BTree、哈希索引、空间数据索引(R-Tree)、全文索引
对于BTree类型的索引,一般来说使用B-Tree,但是Innodb使用的是B+Tree,NDB集群使用的为T-Tree(虽然他也叫BTree)。B-Tree适用于全键值、键值范围、最左前缀查找。
B-Tree的缺点:
-
-
- 如果不是按照索引的最左列则无法使用索引。
- 不能跳过索引中的列。如果有3个列为一个索引,若不指定第二个列,则无法使用第三个列只能使用第一个列。
- 如果查询中有某个列的范围查询,则其右边的所有列都无法使用索引优化查找。例如若指定3个列last_name、first_name、create为索引,若有查询where last_name='bob' and first_name like 'J%' and create='2000-01-01',则只能使用last_name、first_name,在范围查询first_name右边的create列是无法应用索引的。
-
哈希索引:它基于哈希表实现,只有Memory引擎显示支持哈希索引(NDB也支持)。当然,Memory也支持B-Tree,当发生冲突时,使用链表方式存放。其查找速度非常快。
哈希索引的缺点:
-
-
- 只包含哈希值和行指针,不存储字段值,所以不能使用索引中的值来避免读取行。
- 不是按照索引值顺序存储,所以无法用于排序。
- 不支持部分索引列匹配查找。例如,在列A和B上建立哈希索引,如果查询中只有A,那么不能使用该索引。
- 最主要的缺点是只支持等值比较查询,即=、IN()、<=>(完全等于),不支持范围查找,如where price > 100
- 虽说访问哈希索引的数据非常快但当有许多哈希冲突时,会遍历链表的所有行指针,稍慢。
- 当哈希冲突很多时,索引的维护代价较高。
-
适应场景:适用于星型Schema(需要关联很多查找表)。其实还可以和InnoDB引擎的B-Tree结合,即在B-Tree树的基础上创建一个伪哈希索引。它使用哈希值而不是键本身进行索引查找。只需要很小的索引就可以为超长的键创建索引。例如当存储大量URL,并根据URL进行搜索查找时,如果使用B-Tree存储URL,那么内容将会很大,这时我们可以新增一个被索引的列url_crc,可以使用CRC32做哈希。查找时Select id from url where url_crc=CRC32("http://www.mysql.com") and url="http://www.mysql.com",这样将很快找到相应的数据。如果对完整的URL字符串做索引,那么将非常非常慢。 但是这样需要维护索引,可以使用触发器。(不能使用SHA1和MD5作为哈希函数)
21.分布式一致性理论
CAP理论:
Consistency:一致性,数据在多个副本之间能否保持一致的特性。一个系统在数据一致的状态下执行更新操作后,应该保证系统的数据仍然处于一致的状态。
Availability:可用性,系统提供的服务一致处于可用的状态。
Partition Tolerance:分区容错性,遇到故障时,仍然需要能够保证对外提供满足一致性和可用性的服务。
考虑ca和ap。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号