HDFS详细分析一
1. Hadoop启动中遇到的问题以及解决办法:
(1)搭建HDFS集群的时候,NameNode和DataNode这两个进程会挂掉?
查看logs,查看相关的异常信息
a.如果是namenode没有正常启动,原因在启动之前没有格式化,我们需要format
b.如果data没有启动,原因是namespaceID不一样
正确的步骤是:
1.rm -rf 本地的存储目录(/tmp/hadoop-<user_name>)
2.hadoop namenode -format
3.执行脚本 start-dfs.sh
(2)dfsadmin -setQuota的问题
dfsadmin -setQuota 限制文件数量
dfsadmin -setSpaceQuota 限制磁盘空间
(3)什么样的文件算是小文件?在哪里配置?
数据块的默认大小是64M,如果一个文件大小小雨64M,那么它也要占据一个数据块,使用Archive的方式归并小文件。
数据块大小可以使用dfs.block.size这个属性进行配置。
(4)start-dfs.sh的告警信息
Unable to load native-hadoop library for your platform...
using built-in java classes
没有找到native库,使用内置的java code
(5)重复运行wordcount,提示output目录存在
可以使用命令行或者hdfs API 直接删除
修改源代码,增加强制目录替换功能
(6)默认的hadoop conf路径变成了etc/hadoop
start-dfs.sh之前它会source一下hadoop-config.sh,然后再去执行hadoop-deamon.sh,接下来执行hadoop脚本,执行java程序。
2.HDFS架构
一个组的存储容量是该组机器最小的存储容量决定的。(木桶效应)
一、常见的分布式文件系统

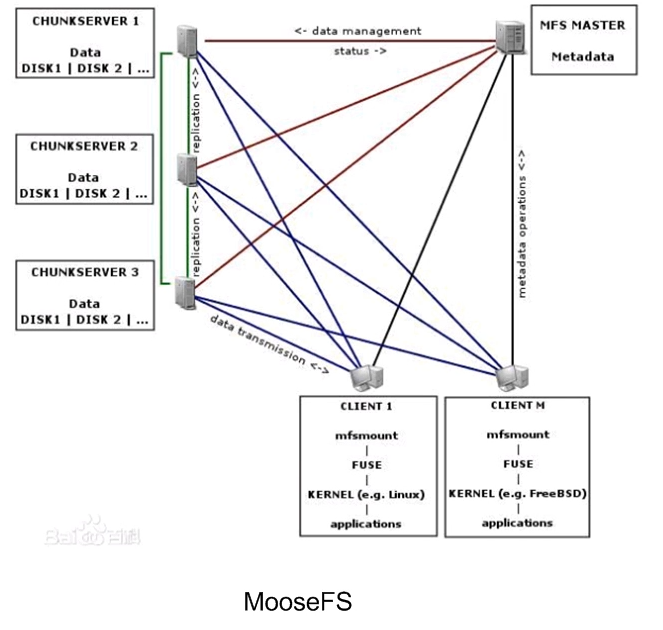
不同的是MooseFS有一个FUSE,可以将分布式文件系统和本地分布式文件系统结合起来
以文件为基本存储单位:
1.难以并行化处理
一个节点只能处理一个文件
无法同时处理一个文件
2.难以实现负载均衡
文件大小不同,无法实现负载均衡
用户需要自己控制文件大小
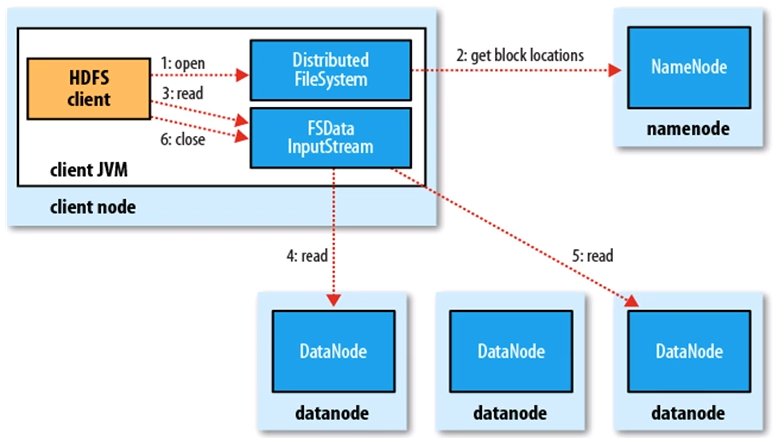
二、HDFS文件系统

HDFS读过程:
HDFS写过程:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号