
httprunner3.X 参数化实现数据驱动
环境:httprunner==3.1.4 python==3.7.7
数据源指定支持三种方式:
在 YAML/JSON/py 中直接指定参数列表:该种方式最为简单易用,适合参数列表比较小的情况
通过内置的 parameterize(可简写为P)函数引用 CSV 文件:该种方式需要准备 CSV 数据文件,适合数据量比较大的情况
调用 debugtalk.py 中自定义的函数生成参数列表:该种方式最为灵活,可通过自定义 Python 函数实现任意场景的数据驱动机制,当需要动态生成参数列表时也需要选择该种方式
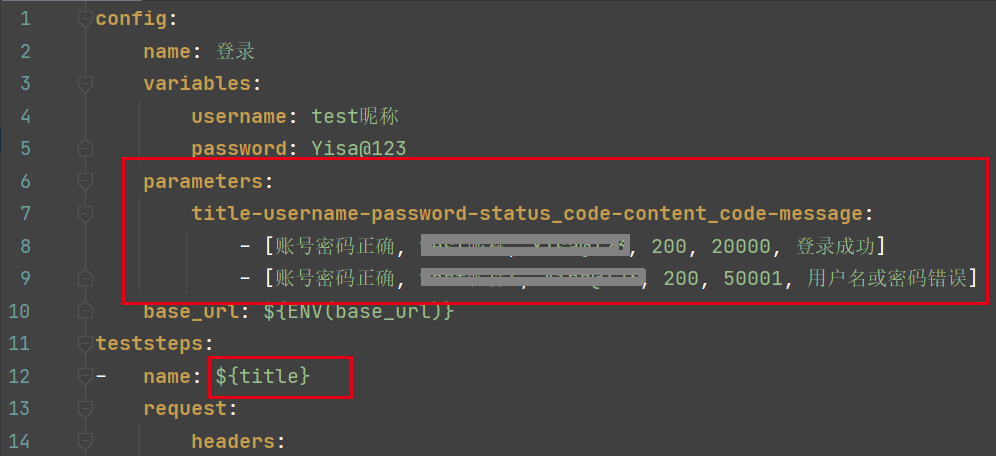
1. 在YML中直接指定参数列表
如:针对一个账号对应一个密码,对应一种预期结果
在config-parameters中设置对应参数列表,步骤中用${}进行引用,variables 和 parameters 设置相同名称变量时,parameters 优先级大于variables
遇到的坑:
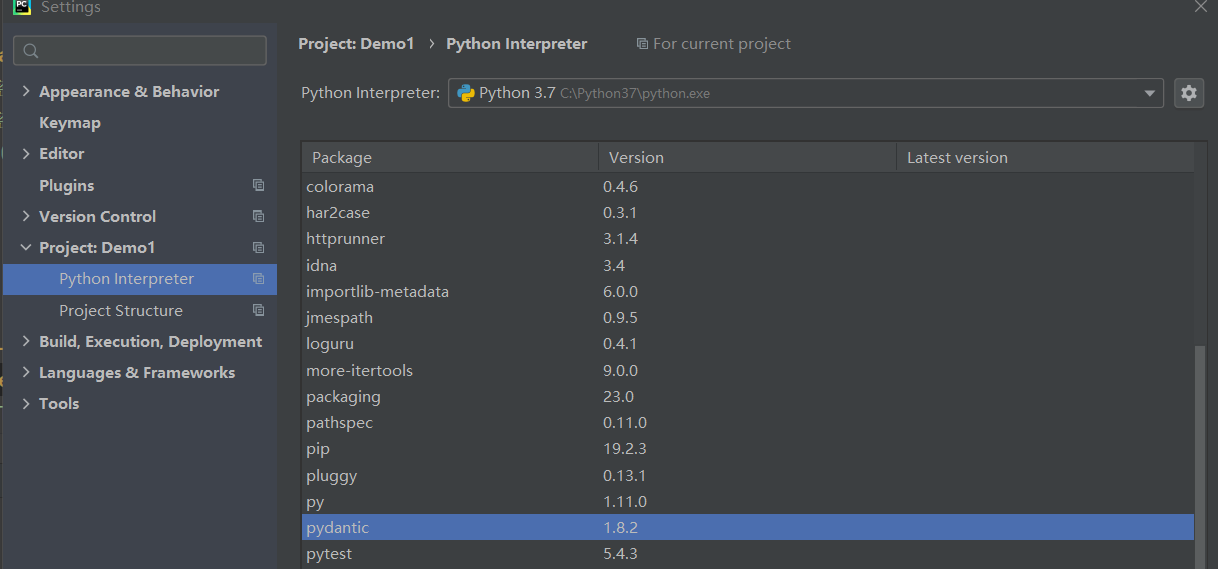
parameters的参数化数据 每次只运行第一组的参数化数据
解决方案:
检查下依赖包:pydantic 的版本是不是1.8.2,如果不是可以卸载后重新下载1.8.2解决
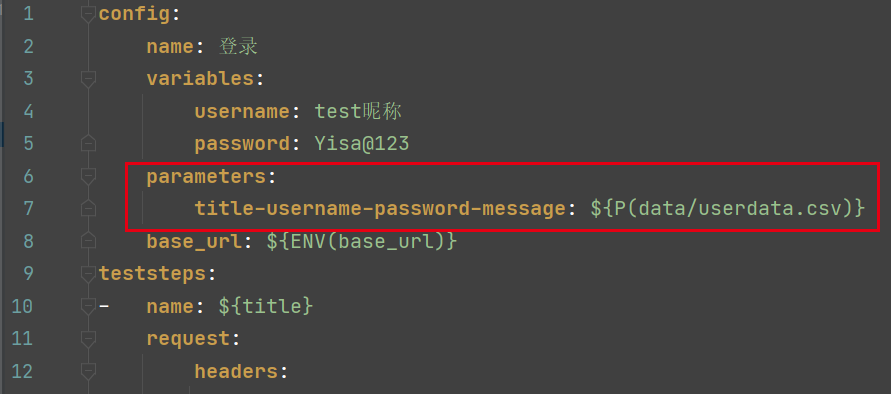
2. 通过内置的 parameterize(可简写为P)函数引用 CSV 文件
创建csv文件,命名未userdata.csv,存放在项目的data文件夹下

parameterize中函数引用csv文件:
title-username-password-message: ${P(data/userdata.csv)}
遇到的坑1:参数化入参和返回值的数据类型不同问题
httprunner.exceptions.ValidationFailure: assert status_code equal 200(str) ==> fail

读取CSV文件,参数化入参 → str 类型
但是接口返回值 → int 类型
使用 -eq 是一直失败的。因为str和int类型比较就是错误了。
解决方案:
直接将比较关键字 eq 改为 str_eq

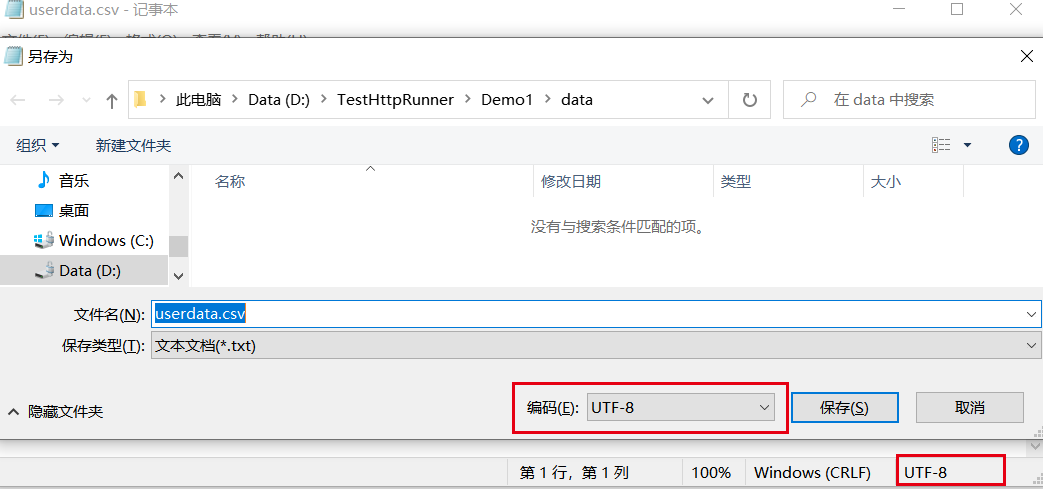
遇到的坑2:编码问题
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd3 in position 33: invalid continuation byte

解决方案:
记事本打开csv文件,查看右下角编码格式,另存为时选择utf-8
3. 调用 debugtalk.py 中自定义的函数生成参数列表
在debugtalk.py中定义一个函数,返回列表
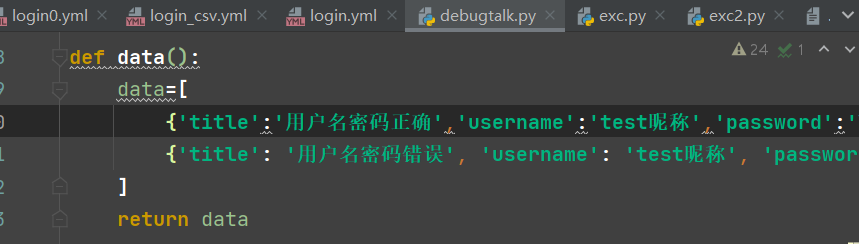
在yml用例文件调用
parameters:
title-username-password-status_code-message: ${data()}

