从分治算法到 Hadoop MapReduce
从分治算法说起
要说 Hadoop MapReduce 就不得不说分治算法,而分治算法其实说白了,就是四个字 分而治之 。其实就是将一个复杂的问题分解成多组相同或类似的子问题,对这些子问题再分,然后再分。直到最后的子问题可以简单得求解。
要具体介绍分治算法,那就不得不说一个很经典的排序算法 -- 归并排序。这里不说它的具体算法代码,只说明它的主要思想。而归并排序的思想正是分治思想。
归并排序采用递归的方式,每次都将一个数组分解成更小的两个数组,再对这两个数组进行排序,不断递归下去。直到分解成最简单形式的两个数组的时候,再将这一个个分解后的数组进行合并。这就是归并排序。
下面有一个取自百度百科的具体例子可以看看:
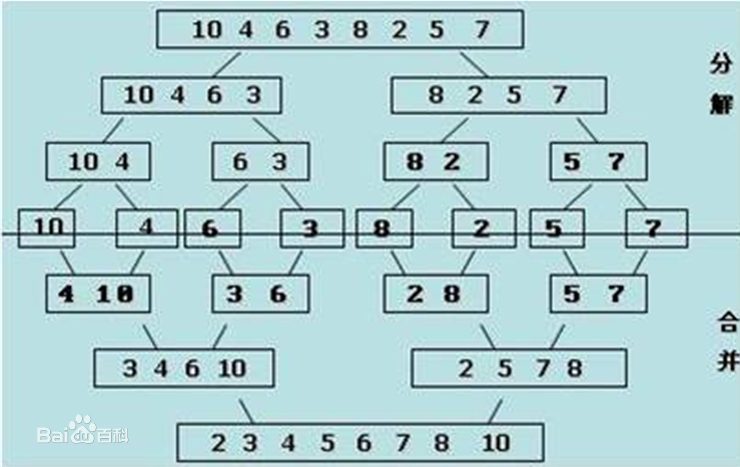
我们可以看到,初始的数组是:{10,4,6,3,8,2,5,7}
第一次分解后,变成两个数组:{10,4,6,3},{8,2,5,7}
分解到最后为 5 个数组:{10},{4,6},{3,8},{2,5},{7}
然后分别合并并排序,最后排序完成:{2,3,4,5,6,7,8,10}
上述的例子这是比较简单的情况,那么我们想想看,当这个数组很大的时候又该怎么办呢?比如这个数组达到 100 GB大小,那么在一台机器上肯定是无法实现或是效率较为低下的。
那一台机器不行,那我们可以拆分到多台机器中去嘛。刚好使用分治算法将一个任务可以拆分成多个小任务,并且这多个小任务间不会相互干扰,可以独立计算。那么我们可以拆分这个数组,将这个数组拆分成 20 个块,每个的大小为 5 GB。然后将这每个 5 GB的块分散到各个不同的机器中去运行,最后再将处理的结果返回,让中央机器再进行一次完整的排序,这样无疑速度上会提升很多。
上述这个过程就是 Hadoop MapReduce 的大致原理了。
函数式的 MapReduce
Map 和 Reduce 其实是函数式编程中的两个语义。Map 和循环 for 类似,只不过它有返回值。比如对一个 List 进行 Map 操作,它就会遍历 List 中的所有元素,然后根据每个元素处理后的结果返回一个新的值。下面这个例子就是利用 map 函数,将 List 中每个元素从 Int 类型 转换为 String 类型。
val a:List[Int] = List(1,2,3,4)
val b:List[String] = a.map(num => (num.toString))
而 Reduce 在函数式编程的作用则是进行数据归约。Reduce 方法需要传入两个参数,然后会递归得对每一个参数执行运算。还是用一个例子来说明:
val list:List[Int] = List(1,2,3,4,5)
//运算顺序是:1-2 = -1; -1-3 = -4; -4-4 = -8; -8-5 = -13;
//所以结果等于 -13
list.reduce(_ - _)
谈谈 Hadoop 的 MapReduce
Hadoop MapReduce 和函数式中的 Map Reduce 还是比较类似的,只是它是一种编程模型。我们来看看 WordCount 的例子就明白了。
在这个 wordcount 程序中,Hadoop MapReduce 会对输入先进行切分,这一步其实就是分治中分的过程。切分后不同部分就会让不同的机器去执行 Map 操作。而后便是 Shuffle,这一阶段会将不相同的单词加到一起,最后再进行 Reduce 。
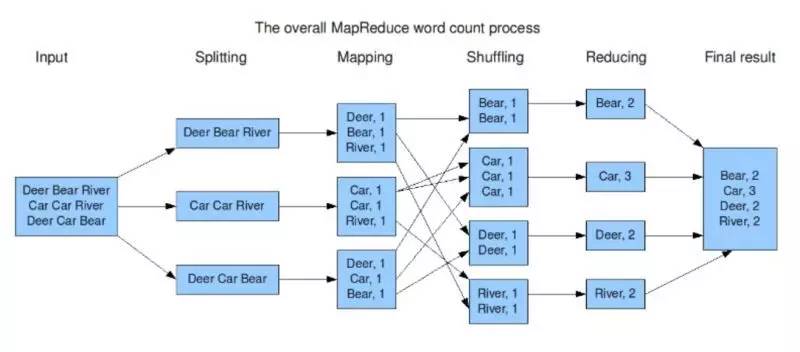
这个 WordCount 程序是官方提供的一个简易的 Demo,更复杂的任务需要自己分解成 Hadoop MapReduce 模型的代码然后执行。
所谓 MapReduce 的意思是任何的事情只要都严格遵循 Map Shuffle Reduce 三个阶段就好。其中Shuffle是系统自己提供的而Map和Reduce则用户需要写代码。
当碰到一个任务的时候,我们需要将它解析成 Map Reduce 的处理方式然后编写 Hadoop MapReduce 代码来实现。我看过一个比喻很贴切,Hadoop MapReduce 这个东西这就像是说我们有一把大砍刀,一个锤子。世界上的万事万物都可以先砍几刀再锤几下,就能搞定。至于刀怎么砍,锤子怎么锤,那就算个人的手艺了。
从模型的角度来看,Hadoop MapReduce 是比较粗糙的,无论什么方法都只能用 Map Reduce 的方式来运行,而这种方式无疑不是万能的,很多应用场景都很难解决。而从做数据库的角度来看,这无非也就是一个 select + groupBy() 。这也就是为什么有了后面 Spark 基于 DAG 的 RDD 概念的崛起。
这里不得不多说一句,Hadoop 的文件系统 Hadoop Hdfs 才是 Hadoop MapReduce 的基础,因为 Map Reduce 最实质的支撑其实就是这个 Hadoop Hdfs 。没有它, Map Reduce 不过是空中阁楼。你看,在 Hadoop MapReduce 式微的今天,Hadoop Hdfs 还不是活得好好的,Spark 或是 Hive 这些工具也都是以它为基础。不得不说,Hadoop Hdfs 才牛逼啊。
为什么会出现 Hadoop MapReduce
好了,接下来我们来探究一下为什么会出现 Hadoop MapReduce 这个东西。
MapReduce 在 Google 最大的应用是做网页的索引。大家都知道 Google 是做搜索引擎起家的,而搜索引擎的基本原理就是索引,就是爬去互联网上的网页,然后对建立 单词->文档 的索引。这样什么搜索关键字,才能找出对应网页。这也是为什么 Google 会以 WordCount 作为 MapReduce 的例子。
既然明白搜索引擎的原理,那应该就明白自 2000 年来互联网爆发的年代,单台机器肯定是不够存储大量的索引的,所以就有了分布式存储,Google 内部用的叫 Gfs,Hadoop Hdfs 其实可以说是山寨 Gfs 来的。而在 Gfs 的基础上,Hadoop MapReduce 的出现也就自然而然了。
推荐阅读:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号