Hive使用Calcite CBO优化流程及SQL优化实战
上一篇主要对Calcite的背景,技术特点,SQL的RBO和CBO等做了一个初步的介绍。深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
这一篇会从Hive入手,介绍Hive如何使用Calcite来优化自己的SQL,主要从源码的角度进行介绍。文末附有一篇其他博主的文章,从其他角度阐述Hive CBO的,可供参考。
另外,上一篇中有提到我整理了Calcite的各种样例,Calcite的一些使用样例整理成到github,https://github.com/shezhiming/calcite-demo。其中自定义rule,Relnode等内容有部分参照自Hive。在介绍的时候可能也会稍微讲到。
最后会从Hive这个例子延伸,看看自己可以怎么借助Calcite来优化SQL。
Hive SQL执行流程
Hive debug简单介绍
在开始介绍之前,本着授人以渔的精深,先说下如何使用Hive debug查看源码执行流程。具体流程可以参照这篇:
简单说就是搭建个hive环境,通过 hive --debug -hiveconf hive.root.logger=DEBUG,console语句开启 debug 模式,开启后 hive 会监听 8000 端口并等待输入,此时从本地的 hive 源码项目中配置远程 debug 就可以通过 debug 的方式追踪 hive 执行流程。
debug过程中,执行SQL的入口是在CliDriver.executeDriver()这个方法,可以在这个地方打一个断点,然后就可以调试跟踪了。如下图:

搭建hive服务的话,建议使用docker,搭建起来会比较方便一些。
PS:这里介绍用的Hive的版本是2.3.x。
Hive SQL执行流程
前面说到,debug输入语句的入口的类是org.apache.hadoop.hive.cli.CliDriver。而实际执行SQL语句逻辑的主要模块是ql(Query Language) 模块的Driver类(org.apache.hadoop.hive.ql.Driver)。Driver主要逻辑,是先调用compile(String command, boolean resetTaskIds, boolean deferClose)方法,对 SQL 进行编译,然后Driver调用execute()方法,执行对应的MR任务。我们的关注点主要放在compile()方法的执行过程。
在compile()方法中,整个SQL执行流程如下图:

即先将SQL解析成AST Node,然后转换成QB,再转换成Operator tree,最后进行逻辑优化和物理优化后,就编程一个可执行的MR任务了。对应阶段的入口,我也在上面的图中标注出来了。
其中较为核心的,从AST Node到Phsical Optimize这几个阶段,都是在SemanticAnalyzer.analyzeInternal()方法中进行的。这个方法中的注释已经跟我们说明了SQL执行的主要流程,我这里贴一下:
- Generate Resolved Parse tree from syntax tree
- Gen OP Tree from resolved Parse Tree
- Deduce Resultset Schema
- Generate Parse Context for Optimizer & Physical compiler
- Take care of view creation
- Generate table access stats if required
- Perform Logical optimization
- Generate column access stats if required - wait until column pruning takes place during optimization
- Optimize Physical op tree & Translate to target execution engine (MR, TEZ..)
- put accessed columns to readEntity
- if desired check we're not going over partition scan limits
大致的流程和图里面介绍的差不多,不过会多一些细节上的补充,感兴趣的童鞋可以实际执行一下看看执行流程。我这里简单介绍下,前几个步骤就是根据AST Node生成QB,然后再转换成Operator Tree,然后处理视图和生成统计信息。最后执行逻辑优化和物理优化并生成MapReduce Task。
上述流程有一个比较容易让人疑惑的点,无论是AST Node,Operator Tree都比较好理解,后面的逻辑优化和物理优化也都是SQL解析的常规套路,但为什么中间会插入一个QB的阶段?
其实这里插入一个QB,一个主要的目的,是为了让Calcite来进行优化。
Hive 使用Calcite优化
Hive Calcite优化流程
在Hive中,使用Calcite来进行核心优化,它将AST Node转换成QB,又将QB转换成Calcite的RelNode,在Calcite优化完成后,又会将RelNode转换成Operator Tree,说起来很简单,但这又是一条很长的调用链。
Calcite优化的主要类是CalcitePlanner,更加细节点,是在CalcitePlannerAction.apply()这个方法,CalcitePlannerAction是一个内部类,包括将QB转换成RelNode,优化具体操作都是在这个方法中进行的。
这个方法的注释也给出了主要操作步骤,这里也贴一下流程:
- Gen Calcite Plan
- Apply pre-join order optimizations
- Apply join order optimizations: reordering MST algorithm
If join optimizations failed because of missing stats, we continue with the rest of optimizations - Run other optimizations that do not need stats
- Materialized view based rewriting
We disable it for CTAS and MV creation queries (trying to avoid any problem due to data freshness) - Run aggregate-join transpose (cost based)
If it failed because of missing stats, we continue with the rest of optimizations
7.convert Join + GBy to semijoin - Run rule to fix windowing issue when it is done over aggregation columns
- Apply Druid transformation rules
- Run rules to aid in translation from Calcite tree to Hive tree
10.1. Merge join into multijoin operators (if possible)
10.2. Introduce exchange operators below join/multijoin operators
简单说下,就是先生成RelNode(根据QB),然后进行一系列的优化。这里的优化最主要的还是跟join有关的优化,上面流程步骤中的2~7步都是join相关的优化。然后才是根据各个rule进行优化。最后再转换成Operator Tree,这就是最上面图片中QB->Operator Tree的流程。
接下来我们就深入这个流程,看看Hive是如何使用Calcite做SQL优化的。
Hive Calcite使用细则
要介绍Hive如何利用Calcite做优化,我们还是先转头看看Calcite优化需要哪些东西。先贴一下上一篇中介绍到的,Calcite的架构图:

从图中可以明显发现,跟QUery Optimizer(优化器)有关的模块有三个,Operator Expressions,Metadata Providers和Pluggable Rules,三者分别是关系表达树(由RelNode节点组成),元数据提供器,还有Rule。
其中关系表达树是Calcite将SQL解析校验后产生的一种关系树,树的节点即是RelNode(关系代数节点),RelNode又有多种类型,比如TableScan代表最底层的表输入,Filter表示Where(关系代数的过滤),Project表示select(关系代数的投影),即大部分的RelNode都会和关系代数中的操作对应。以一条SQL为例,一条简单的SQL编程RelNode就会是下面这个样子:
select * from TEST_CSV.TEST01 where TEST01.NAME1='hello';
//RelNode关系树
Project(ID=[$0], NAME1=[$1], NAME2=[$2])
Filter(condition=[=($1, 'hello')])
TableScan(table=[[TEST_CSV, TEST01]])
再来说说元数据提供器,所谓元数据,就是跟表有关的那些信息,rowcount,表字段等信息。其中rowcount这类信息跟计算cost有关,Calcite有自己的默认的元数据提供器,但做的比较粗糙,如果有需要应该自己提供一个元数据提供器提供自己的元数据信息。
最后就是Rules,这块Calcite默认已经有非常多的Rules,当然我们也可以定义自己的Rule再添加进去。不过通常基本的SQL优化使用Calcite的Rule就足够。这里说下怎么在idea里面查看Calcite提供的Rule,先找到RelOptRule这个类,然后按下查看类继承关系的快捷键(Mac上是Ctrl+h),就能看到多条Rule,如果要自己实现也可以照着其中实现。
稍微总结一下,Calcite已经基本提供了所需要的Rule,所以要使用Calcite优化SQL,我们需要的,是提供SQL对应的RelNode,以及通过元数据提供器提供自身的元数据。
Hive要使用Calcite优化,也无外乎就是提供上述的两部分内容。
用过Hive的童鞋应该知道,Hive可以通过外部存储组件存储数据库和表元数据信息,包括rowcount,input size等(需要执行Analyze语句或DML才会计算并元数据到Mysql)。Hive要做的就是将这些信息,提供给Calcite。
Hive向Calcite提供元数据
需要先明确的一点是,元数据提供器需要提供的一个比较重要的数据,是rowcount,在进行CBO计算Cost的过程中,CPU,IO等信息也基本都是从rowcount加工而来的。且元数据重要的一个用途,也是进行CBO优化,输入的元数据可以等价于CBO要用到的Cost数据。
继续深入CBO的Cost,通过前面的例子,可以知道SQL在Calcite会被解析成RelNode树,RelNode树上层节点(Project等)的Cost信息,是由下层的信息计算而得到的。我们的目标是要自定义Cost信息,那么就需要将Hive的元数据注入最底层的TableScan的Cost信息,同时要能够自定义每个节点的Cost计算方式。
还记得前面说到Calcite默认的元数据提供器比较粗糙吗,就是体现在它的TableScan的rowcount默认是100,而每个节点的计算逻辑也比较简单。
所以重点有两个,一个是最底层TableScan的cost信息注入方式,另一个是如何每种RelNode类型定义计算逻辑的方式。
办法有两种,一种是比较上层的,通过自定义RelNode,修改其中的computeSelfCost()方法和estimateRowCount方法,这两个方法,一个是计算Cost信息,另一个是计算行数。这种办法可以直接解决TableScan的cost注入,和自定义每种RelNode类型的计算逻辑。但这种办法忽了元数据提供器,算是比较简单粗暴的方法。
就像这样:
代码见:https://github.com/shezhiming/calcite-demo/blob/master/src/main/java/pers/shezm/calcite/optimizer/reloperators/CSVTableScan.java
public class CSVTableScan extends TableScan implements CSVRel {
private RelOptCost cost;
public CSVTableScan(RelOptCluster cluster, RelTraitSet traitSet, RelOptTable table) {
super(cluster, traitSet, table);
}
@Override public double estimateRowCount(RelMetadataQuery mq) {
return 50;
}
@Override
public RelOptCost computeSelfCost(RelOptPlanner planner, RelMetadataQuery mq) {
//return super.computeSelfCo(planner, mq);
if (cost != null) {
return cost;
}
//通过工厂生成 RelOptCost ,注入自定义 cost 值并返回
cost = planner.getCostFactory().makeCost(1, 1, 0);
return cost;
}
}
另一种方法则更加底层一些,TableScan的元数据信息,是通过内部变量RelOptTable获取,那么就自定义RelOptTable实现元数据注入。然后通过实现MetadataDef<BuiltInMetadata.RowCount>系列的接口,在其中添加自己的计算逻辑,将这些自定义的类都加载到RelMetadataProvider中(元数据提供器,可以在其中提供自定义的元数据和计算逻辑),再注入到Calcite中就可以实现自己的Cost计算逻辑。这也是Hive的实现方式。
我们从TableScan注入,和RelMetadataProvider这两方面看看Hive是怎么做。
TableScan的注入元数据
首先,Hive自定义了Calcite的TableScan,在org.apache.hadoop.hive.ql.optimizer.calcite.reloperators.HiveTableScan。但这里并不涉及元数据,我们观察下TableScan的源码,
public abstract class TableScan extends AbstractRelNode {
//~ Instance fields --------------------------------------------------------
/**
* The table definition.
*/
protected final RelOptTable table;
//生成 cost 信息
@Override public RelOptCost computeSelfCost(RelOptPlanner planner,
RelMetadataQuery mq) {
double dRows = table.getRowCount();
double dCpu = dRows + 1; // ensure non-zero cost
double dIo = 0;
return planner.getCostFactory().makeCost(dRows, dCpu, dIo);
}
//生成 rowcount 信息
@Override public double estimateRowCount(RelMetadataQuery mq) {
return table.getRowCount();
}
}
顺便说下,上面说过,Cost信息和rowcount息息相关,这里就可以看出来了,Cpu直接就用rowcount加一。并且这里也可以看出默认的元数据提供器比较粗糙。
不过我们重点不在这,通过代码可以发现它主要是通过table这个变量获取表元数据信息。而hive也自定义了相关的类,就是继承自RelOptTable的RelOptHiveTable。这个类在HiveTableScan初始化的时候,会作为参数传递进去。而它的元数据则是通过QB获取,这个过程也是在CalcitePlannerAction.apply()中完成的,至于QB的元数据,则是在初始化的时候通过Mysql获取到的。听起来挺绕,稍微按顺序整理下:
- QB初始化的时候,通过Mysql获取元数据信息并注入
- QB转成RelNode的时候,将元数据传递到
RelOptHiveTable RelOptHiveTable作为参数新建HiveTableScan
以上就是Hive完成TableScan元数据注入的过程。
自定义RelMetadataProvider
再来说说如何提供RelMetadataProvider。这个主要是通过继承MetadataHandler实现的,这里贴一下就能清楚metadata有哪些类型,以及Hive实现了哪些:
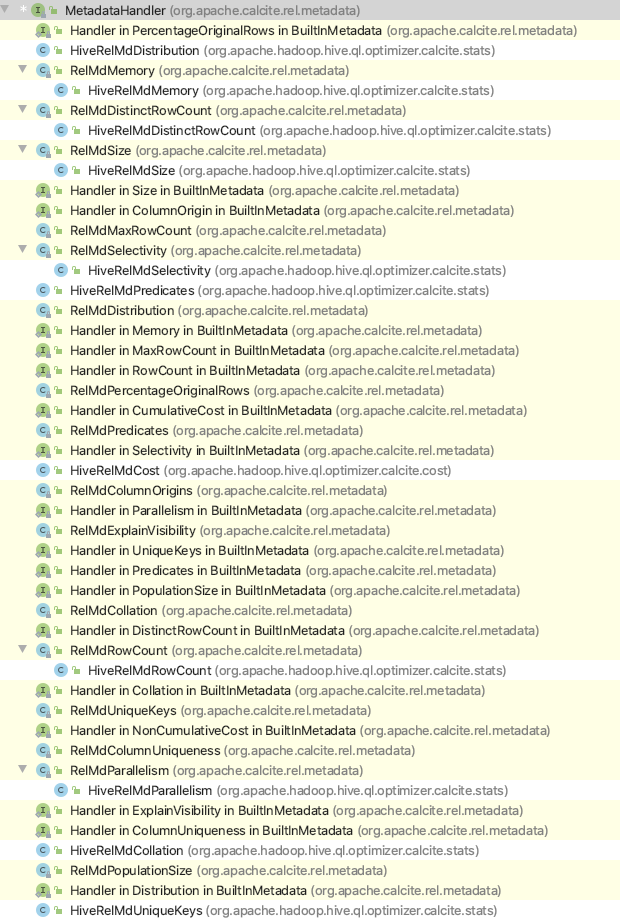
这里可以清楚看到,metadata除了之前提到的rowcount,cost,还有size,Distribution等等,其中白色的就是Hive实现的。
而之前一直提到的rowcount和cost,对应的就是HiveRelMdRowCount和HiveRelMdCost(这个真正的cost模型实现,是在HiveCostModel)。这里贴一下HiveCostModel中Join的Cost自定义计算逻辑,因为join优化是一个重点,所以这里会根据不同实现类去计算cost,相比Calcite默认实现,精细很多了。
public abstract class HiveCostModel {
......其他代码
public RelOptCost getJoinCost(HiveJoin join) {
// Select algorithm with min cost
JoinAlgorithm joinAlgorithm = null;
RelOptCost minJoinCost = null;
if (LOG.isTraceEnabled()) {
LOG.trace("Join algorithm selection for:\n" + RelOptUtil.toString(join));
}
for (JoinAlgorithm possibleAlgorithm : this.joinAlgorithms) {
if (!possibleAlgorithm.isExecutable(join)) {
continue;
}
RelOptCost joinCost = possibleAlgorithm.getCost(join);
if (LOG.isTraceEnabled()) {
LOG.trace(possibleAlgorithm + " cost: " + joinCost);
}
if (minJoinCost == null || joinCost.isLt(minJoinCost) ) {
joinAlgorithm = possibleAlgorithm;
minJoinCost = joinCost;
}
}
if (LOG.isTraceEnabled()) {
LOG.trace(joinAlgorithm + " selected");
}
join.setJoinAlgorithm(joinAlgorithm);
join.setJoinCost(minJoinCost);
return minJoinCost;
}
......其他代码
}
其他的也和这个差不多,就是更加精细的自定义Cost计算,就不多展示了。
OK,说完上面这些,Hive的优化也就差不多介绍完了,这里重点还是介绍了Hive如何向Calcite中注入元数据信息以及实现自定义的RelNode计算逻辑。至于Calcite进行RBO和CBO优化的更多细节,我上一篇有提到,也有给出相关资料,这里就不多介绍。
深入浅出Calcite与SQL CBO(Cost-Based Optimizer)优化
还有另一个点是编写自定义的rule实现自定义优化,这一点以后与机会再说。
另外我最上方的github中,也有简单照着hive,实现了自己注入元数据和自定义RelNode的计算方式,基本都是从最简单的CSV的例子延伸而言,方便理解,有兴趣的朋友可以看看,如果有帮助不妨点个star。
以上~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号