Spark SQL源码解析(二)Antlr4解析Sql并生成树
Spark SQL原理解析前言:
Spark SQL源码剖析(一)SQL解析框架Catalyst流程概述
这一次要开始真正介绍Spark解析SQL的流程,首先是从Sql Parse阶段开始,简单点说,这个阶段就是使用Antlr4,将一条Sql语句解析成语法树。
可能有童鞋没接触过antlr4这个内容,推荐看看《antlr4权威指南》前四章,看完起码知道antlr4能干嘛。我这里就不多介绍了。
这篇首先先介绍调用spark.sql()时候的流程,再看看antlr4在这个其中的主要功能,最后再将探究Logical Plan究竟是什么东西。
初始流程
当你调用spark.sql的时候,会调用下面的方法:
def sql(sqlText: String): DataFrame = {
Dataset.ofRows(self, sessionState.sqlParser.parsePlan(sqlText))
}
parse sql阶段主要是parsePlan(sqlText)这一部分。而这里又会辗转去org.apache.spark.sql.catalyst.parser.AbstractSqlParser调用parse方法。这里贴下关键代码。
protected def parse[T](command: String)(toResult: SqlBaseParser => T): T = {
logDebug(s"Parsing command: $command")
val lexer = new SqlBaseLexer(new UpperCaseCharStream(CharStreams.fromString(command)))
lexer.removeErrorListeners()
lexer.addErrorListener(ParseErrorListener)
lexer.legacy_setops_precedence_enbled = SQLConf.get.setOpsPrecedenceEnforced
val tokenStream = new CommonTokenStream(lexer)
val parser = new SqlBaseParser(tokenStream)
parser.addParseListener(PostProcessor)
parser.removeErrorListeners()
parser.addErrorListener(ParseErrorListener)
parser.legacy_setops_precedence_enbled = SQLConf.get.setOpsPrecedenceEnforced
try {
try {
// first, try parsing with potentially faster SLL mode
parser.getInterpreter.setPredictionMode(PredictionMode.SLL)
toResult(parser)
}
catch {
case e: ParseCancellationException =>
// if we fail, parse with LL mode
tokenStream.seek(0) // rewind input stream
parser.reset()
// Try Again.
parser.getInterpreter.setPredictionMode(PredictionMode.LL)
toResult(parser)
}
}
catch {
case e: ParseException if e.command.isDefined =>
throw e
case e: ParseException =>
throw e.withCommand(command)
case e: AnalysisException =>
val position = Origin(e.line, e.startPosition)
throw new ParseException(Option(command), e.message, position, position)
}
}
可以发现,这里面的处理逻辑,无论是SqlBaseLexer还是SqlBaseParser都是Antlr4的东西,包括最后的toResult(parser)也是调用访问者模式的类去遍历语法树来生成Logical Plan。如果对antlr4有一定了解,那么对这里这些东西一定不会陌生。那我们接下来看看Antlr4在这其中的角色。
Antlr4生成语法树
Spark提供了一个.g4文件,编译的时候会使用Antlr根据这个.g4生成对应的词法分析类和语法分析类,同时还使用了访问者模式,用以构建Logical Plan(语法树)。
访问者模式简单说就是会去遍历生成的语法树(针对语法树中每个节点生成一个visit方法),以及返回相应的值。我们接下来看看一条简单的select语句生成的树是什么样子。
这个sqlBase.g4文件我们也可以直接拿出来玩,直接复制出来,用antlr相关工具就可以生成一个生成一个解析SQL的图了。
这里antlr4和grun都已经存储成bat文件,所以可以直接调用,实际命令在《antlr4权威指南》说得很详细了就不介绍了。调用完后就会生成这样的语法树。
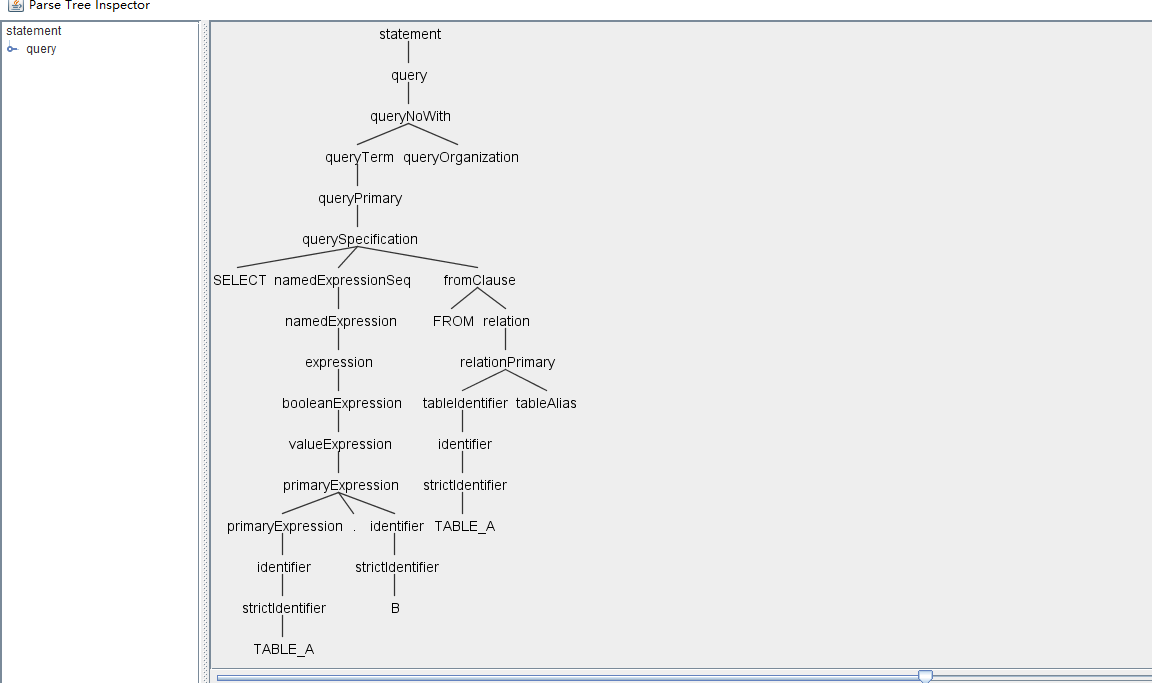
这里,将SELECT TABLE_A.B FROM TABLE_A,转换成一棵语法树。我们可以看到这颗语法树非常复杂,这是因为SQL解析中,要适配这种SELECT语句之外,还有很多其他类型的语句,比如INSERT,ALERT等等。Spark SQL这个模块的最终目标,就是将这样的一棵语法树转换成一个可执行的Dataframe(RDD)。
我们现阶段的目标则是要先生成Logical Plan,Spark使用Antlr4的访问者模式,生成Logical Plan。这里顺便说下怎么实现访问者模式吧,在使用antlr4命令的时候,加上-visit参数就会生成SqlBaseBaseVisitor,里面提供了默认的访问各个节点的触发方法。我们可以通过继承这个类,重写对应节点的visit方法,实现自己的访问逻辑,而这个继承的类就是org.apache.spark.sql.catalyst.parser.AstBuilder。
通过观察这棵树,我们可以发现针对我们的SELECT语句,比较重要的一个节点,是querySpecification节点,实际上,在AstBuilder类中,visitQuerySpecification也是比较重要的一个方法(访问对应节点时触发),正是在这个方法中生成主要的Logical Plan的。
接下来重点看这个方法,以及探究Logical Plan。
生成Logical Plan
我们先看看AstBuilder中的代码:
class AstBuilder(conf: SQLConf) extends SqlBaseBaseVisitor[AnyRef] with Logging {
......其他代码
override def visitQuerySpecification(
ctx: QuerySpecificationContext): LogicalPlan = withOrigin(ctx) {
val from = OneRowRelation().optional(ctx.fromClause) { //如果有FROM语句,生成对应的Logical Plan
visitFromClause(ctx.fromClause)
}
withQuerySpecification(ctx, from)
}
......其他代码
代码中会先判断是否有FROM子语句,有的话会去生成对应的Logical Plan,再调用withQuerySpecification()方法,而withQuerySpecification()方法是比较核心的一个方法。它会处理包括SELECT,FILTER,GROUP BY,HAVING等子语句的逻辑。
代码比较长就不贴了,有兴趣的童鞋可以去看看,大意就是使用scala的模式匹配,匹配不同的子语句生成不同的Logical Plan。
然后再来说说最终生成的LogicalPlan,LogicalPlan其实是继承自TreeNode,所以本质上LogicalPlan就是一棵树。
而实际上,LogicalPlan还有多个子类,分别表示不同的SQL子语句。
- LeafNode,叶子节点,一般用来表示用户命令
- UnaryNode,一元节点,表示FILTER等操作
- BinaryNode,二元节点,表示JOIN,GROUP BY等操作
这里一元二元这些都是对应关系代数方面的知识,在学数据库理论的时候肯定有接触过,不过估计都还给老师了吧(/偷笑)。不过一元二元基本上也就是用来区分具体的操作,如上面说的FILTER,或是JOIN等,也不是很复杂。这三个类都位于org.apache.spark.sql.catalyst.plans.logical.LogicalPlan中,有兴趣的童鞋可以看看。而后,这三个类又会有多个子类,用以表示不同的情况,这里就不再赘述。
最后看看用一个测试案例,看看会生成什么吧。示例中简单生成一个临时的view,然后直接select查询这个view。代码如下:
//生成DataFrame
val df = Seq((1, 1)).toDF("key", "value")
df.createOrReplaceTempView("src")
//调用spark.sql
val queryCaseWhen = sql("select key from src ")
补充下,这里的sql()方法是做了一些封装的方法,可以直接看成spark.sql(...)。最终经过parse SQL后会变成如下的内容:
'Project ['key]
+- 'UnresolvedRelation `src`
这个Project是UnaryNode的一个子类(SELECT自然是一元节点),表明我们要查询的字段是key。
UnresolvedRelation是一个新的概念,这里顺便说下,我们通过SQL parse生成的这棵树,其实叫Unresolved LogicalPlan,这里的Unresolved的意思说,还不知道src是否存在,或它的元数据是什么样,只有通过Analysis阶段后,才会把Unresolved变成Resolved LogicalPlan。这里的意思可以理解为,读取名为src的表,但这张表的情况未知,有待验证。
总的来说,我们的示例足够简单直接,所以内容会比较少,不过拿来学习是足够了。
下一个阶段是要使用这棵树进行分析验证了,也就是Analysis阶段,这一块留到下篇介绍吧。
以上~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号