详细解析kafka之 kafka消费者组与重平衡机制
消费组组(Consumer group)可以说是kafka很有亮点的一个设计。传统的消息引擎处理模型主要有两种,队列模型,和发布-订阅模型。
队列模型:早期消息处理引擎就是按照队列模型设计的,所谓队列模型,跟队列数据结构类似,生产者产生消息,就是入队,消费者接收消息就是出队,并删除队列中数据,消息只能被消费一次。但这种模型有一个问题,那就是只能由一个消费者消费,无法直接让多个消费者消费数据。基于这个缺陷,后面又演化出发布-订阅模型。
发布-订阅模型:发布订阅模型中,多了一个主题。消费者会预先订阅主题,生产者写入消息到主题中,只有订阅了该主题的消费者才能获取到消息。这样一来就可以让多个消费者消费数据。
以往的消息处理引擎大多只支持其中一种模型,但借助kafka的消费者组机制,可以同时实现这两种模型。同时还能够对消费组进行动态扩容,让消费变得易于伸缩。
这篇我们先介绍下消费者组,然后主要讨论kafka著名的重平衡机制。
kafka消费者组
所谓消费者组,那自然是由消费者组成的,组内可以有一个或多个消费者实例,而这些消费者实例共享一个id,称为group id。对了,默认创建消费者的group id是在KAFKA_HOME/conf/consumer.properties文件中定义的,打开就能看到。默认的group id值是test-consumer-group。
消费者组内的所有成员一起订阅某个主题的所有分区,注意一个消费者组中,每一个分区只能由组内的一消费者订阅。
看看下面这张图,这是kakfa官网上给出的说明图。
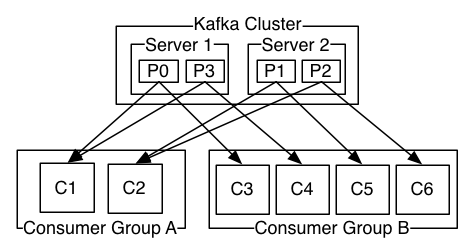
这张图应该很好的说明了消费者组,我们从上到下解释一下,kafka cluster中有两台broker服务器,每一台都有两个分区,这四个分区都是同一个topic下的。下左的消费者组A,组内有两个消费者,每个消费者负责两个分区的消费,而右边的消费者组B有四个消费者,每个负责消费一个分区。
当消费者组中只有一个消费者的时候,就是消息队列模型,不然就是发布-订阅模型,并且易于伸缩。
消费者组内消费者数量
上面那张图,仔细推敲一下就会发现,图中其实已经有一些既定的事实,比如消费者组内消费者小于或等于分区数,以及topic分区数刚好是消费者组内成员数的倍数。
那么如果消费者组内成员数超过分区数会怎样呢?比如有4个分区,但消费者组内有6个消费者,这时候有2个消费者不会分配分区,它会一直空闲。
而如果消费者不是分区的倍数,比如topic内有4个分区,而消费者组内有三个消费者,那怎么办呢?这时候只会有两个消费者分别被分配两个分区,第三个消费者同样空闲。
所以,消费者组内的消费者数量最好是与分区数持平,再不济,最好也是要是分区数的数量成比例。
查看集群中的消费者组
这里顺便说下如何查看消费者组及组内消费情况,可以使用ConsumerGroupCommand命令工具,来查看具体的kafka消费者组。注意,这里都是以最新版的kafka版本,也就是2.+版本。
可以使用如下命令列出当前集群中的kafka组信息。
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --list
test-consumer-group
具体到某个组的消费者情况,可以使用下面这条命令工具:
> bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group my-group
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
topic3 0 241019 395308 154289 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic2 1 520678 803288 282610 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic3 1 241018 398817 157799 consumer2-e76ea8c3-5d30-4299-9005-47eb41f3d3c4 /127.0.0.1 consumer2
topic1 0 854144 855809 1665 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic2 0 460537 803290 342753 consumer1-3fc8d6f1-581a-4472-bdf3-3515b4aee8c1 /127.0.0.1 consumer1
topic3 2 243655 398812 155157 consumer4-117fe4d3-c6c1-4178-8ee9-eb4a3954bee0 /127.0.0.1 consumer4
重平衡(Rebalance)
说完消费者组,再来说说与消费者组息息相关的重平衡机制。重平衡可以说是kafka为人诟病最多的一个点了。
重平衡其实就是一个协议,它规定了如何让消费者组下的所有消费者来分配topic中的每一个分区。比如一个topic有100个分区,一个消费者组内有20个消费者,在协调者的控制下让组内每一个消费者分配到5个分区,这个分配的过程就是重平衡。
重平衡的触发条件主要有三个:
- 消费者组内成员发生变更,这个变更包括了增加和减少消费者。注意这里的减少有很大的可能是被动的,就是某个消费者崩溃退出了
- 主题的分区数发生变更,kafka目前只支持增加分区,当增加的时候就会触发重平衡
- 订阅的主题发生变化,当消费者组使用正则表达式订阅主题,而恰好又新建了对应的主题,就会触发重平衡
为什么说重平衡为人诟病呢?因为重平衡过程中,消费者无法从kafka消费消息,这对kafka的TPS影响极大,而如果kafka集内节点较多,比如数百个,那重平衡可能会耗时极多。数分钟到数小时都有可能,而这段时间kafka基本处于不可用状态。所以在实际环境中,应该尽量避免重平衡发生。
了解了什么是重平衡,重平衡的缺点和触发条件后,我们先来看看重平衡的三种不同策略,然后说说应该如何避免重平衡发生。
三种重平衡策略
kafka提供了三种重平衡分配策略,这里顺便介绍一下:
Range
具体实现位于,package org.apache.kafka.clients.consumer.RangeAssignor。
这种分配是基于每个主题的分区分配,如果主题的分区分区不能平均分配给组内每个消费者,那么对该主题,某些消费者会被分配到额外的分区。我们来看看具体的例子。
举例:目前有两个消费者C0和C1,两个主题t0和t1,每个主题三个分区,分别是t0p0,t0p1,t0p2,和t1p0,t1p1,t1p2。
那么分配情况会是:
- C0:t0p0, t0p1, t1p0, t1p1
- C1:t0p2, t1p2
我来大概解释一下,range这种模式,消费者被分配的单位是基于主题的,拿上面的例子来说,是主题t0的三个分区分配给2个消费者,t1三个分区分配给消费者。于是便会出现消费者c0分配到主题t0两个分区,以及t1两个分区的情况(一个主题有三个分区,三个分区无法匹配两个消费者,势必有一个消费者分到两个分区),而非每个消费者分配两个主题各三个分区。
RoundRobin
具体实现位于,package org.apache.kafka.clients.consumer.RoundRobinAssignor。
RoundRobin是基于全部主题的分区来进行分配的,同时这种分配也是kafka默认的rebalance分区策略。还是用刚刚的例子来看,
举例:两个消费者C0和C1,两个主题t0和t1,每个主题三个分区,分别是t0p0,t0p1,t0p2,和t1p0,t1p1,t1p2。
由于是基于全部主题的分区,那么分配情况会是:
- C0:t0p0, t0p1, t1p1
- C1:t1p0, t0p2, t1p2
因为是基于全部主题的分区来平均分配给消费者,所以这种分配策略能更加均衡得分配分区给每一个消费者。
上面说的都是同一消费者组内消费组都订阅相同主题的情况。更复杂的情况是,同一组内的消费者订阅不同的主题,那么任然可能会导致分区不均衡的情况。
还是举例说明,有三个消费者C0,C1,C2 。三个主题t0,t1,t2,分别有1,2,3个分区 t0p0,t1p0,t1p1,t2p0,t2p1,t2p2。
其中,C0订阅t0,C1订阅t0,t1。C2订阅t0,t1,t2。最终订阅情况如下:
- C0:t0p0
- C1:t1p0
- C2:t1p1,t2p0,t2p1,t2p2
这个结果乍一看有点迷,其实可以这样理解,按照序号顺序进行循环分配,t0只有一个分区,先碰到C0就分配给它了。t1有两个分区,被C1和C2订阅,那么会循环将两个分区分配出去,最后到t2,有三个分区,却只有C2订阅,那么就将三个分区分配给C2。
Sticky
Sticky分配策略是最新的也是最复杂的策略,其具体实现位于package org.apache.kafka.clients.consumer.StickyAssignor。
这种分配策略是在0.11.0才被提出来的,主要是为了一定程度解决上面提到的重平衡非要重新分配全部分区的问题。称为粘性分配策略。
听名字就知道,主要是为了让目前的分配尽可能保持不变,只挪动尽可能少的分区来实现重平衡。
还是举例说明,有三个消费者C0,C1,C2 。三个主题t0,t1,t2,t3。每个主题各有两个分区, t0p0,t0p1,t1p0,t1p1,t2p0,t2p1,t3p0,t3p1。
现在订阅情况如下:
- C0:t0p0,t1p1,t3p0
- C1:t0p1,t2p0,t3p1
- C2:t1p0,t2p1
假设现在C1挂掉了,如果是RoundRobin分配策略,那么会变成下面这样:
- C0:t0p0,t1p0,t2p0,t3p0
- C2:t0p1,t1p1,t2p1,t3p1
就是说它会全部重新打乱,再分配,而如何使用Sticky分配策略,会变成这样:
- C0:t0p0,t1p1,t3p0,t2p0
- C2:t1p0,t2p1,t0p1,t3p1
也就是说,尽可能保留了原来的分区情况,不去改变它,在这个基础上进行均衡分配,不过这个策略目前似乎还有些bug,所以实际使用也不多。
避免重平衡
要说完全避免重平衡,那是不可能滴,因为你无法完全保证消费者不会故障。而消费者故障其实也是最常见的引发重平衡的地方,所以这里主要介绍如何尽力避免消费者故障。
而其他几种触发重平衡的方式,增加分区,或是增加订阅的主题,抑或是增加消费者,更多的是主动控制,这里也不多讨论。
首先要知道,如果消费者真正挂掉了,那我们是没有什么办法的,但实际中,会有一些情况,会让kafka错误地认为一个正常的消费者已经挂掉了,我们要的就是避免这样的情况出现。
当然要避免,那首先要知道哪些情况会出现错误判断挂掉的情况。在分布式系统中,通常是通过心跳来维持分布式系统的,kafka也不例外。对这部分内容有兴趣可以看看我之前的这篇分布式系统一致性问题与Raft算法(上)。这里要说的是,在分布式系统中,由于网络问题你不清楚没接收到心跳,是因为对方真正挂了还是只是因为负载过重没来得及发生心跳或是网络堵塞。所以一般会约定一个时间,超时即判定对方挂了。而在kafka消费者场景中,session.timout.ms参数就是规定这个超时时间是多少。
还有一个参数,heartbeat.interval.ms,这个参数控制发送心跳的频率,频率越高越不容易被误判,但也会消耗更多资源。
此外,还有最后一个参数,max.poll.interval.ms,我们都知道消费者poll数据后,需要一些处理,再进行拉取。如果两次拉取时间间隔超过这个参数设置的值,那么消费者就会被踢出消费者组。也就是说,拉取,然后处理,这个处理的时间不能超过max.poll.interval.ms这个参数的值。这个参数的默认值是5分钟,而如果消费者接收到数据后会执行耗时的操作,则应该将其设置得大一些。
小结一下,其实主要就是三个参数,session.timout.ms控制心跳超时时间,heartbeat.interval.ms控制心跳发送频率,以及max.poll.interval.ms控制poll的间隔。这里给出一个相对较为合理的配置,如下:
- session.timout.ms:设置为6s
- heartbeat.interval.ms:设置2s
- max.poll.interval.ms:推荐为消费者处理消息最长耗时再加1分钟
以上~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号