Scala函数式编程(四)函数式的数据结构 上
这次来说说函数式的数据结构是什么样子的,本章会先用一个list来举例子说明,最后给出一个Tree数据结构的练习,放在公众号里面,练习里面给出了基本的结构,但代码是空缺的需要补上,此外还有预留的testcase可以验证。
关注公众号:哈尔的数据城堡,回复“函数式数据结构”可以获得。(写文章不容易,大哥大姐关注下吧[哭笑])
然后是这系列的索引:
1.什么是函数式的数据结构
还记得前面说过,函数式编程最大的特点是什么吗?就是没有副作用。那么函数式的数据结构自然也是如此。
无副作用的关键是:
- 一个函数无论调用多少次,只要输入参数相同,则结果也必然相同。
- 且这个函数执行过程中不会改变程序的任何外部状态,如全局变量,对象的属性等。
- 函数的结果也不依赖外部状态。
在java中,最经典的数据结构ArrayList,是通过一个全局的size变量,来控制ArrayList的大小的,这就说明ArrayList并非无副作用。
在scala中,集合(List,Map等)默认是不可变的,以链表List为例,是无法通过push等操作,往一个链表里面添加内容的。只能通过两个链表相加的方式,生成一个新链表(Map也是一样,通过两个Map相加,Key相同的会覆盖,以达到更新的目的)。这点倒是和String有点像。
不过其实这样有一个问题,那就是很耗费内存。但这个问题可以用懒加载来解决,限于篇幅,后面再介绍吧。
总结一下,函数式的数据结构,最大的特点,就是没有副作用。那么如何实现无副作用的数据结构呢,我们下面用链表的例子来展示。
不过在这之前,需要先回顾下一些语法知识。
2.scala知识回顾
我的一个观点是,语言的语法知识如果只是看,背,而没有实际用到,那是比较难记住的。这里就把这次会用到的语法知识做个简单介绍,如果有需要,可以查阅前面写的前两章。
我这里也有演示如果运用前面介绍的语法知识实现一个函数式的List()。
PS:如果不想看语法知识可以直接跳到第三节。
前面的语法索引:
2.1 scala的模式匹配
模式匹配类似于swtch语法,不过它能匹配的不止是值,还有数据类型。同时,它是一个匿名函数,在scala里,函数不用return,能直接返回值。
val times = 1
//使用模式匹配来匹配值
times match {
case 1 => "one"
case 2 => "two"
case _ => "some other number"
}
//使用模式匹配,匹配类型,再判断值
times match {
case i:Int if i == 1 => "one"
case i:Int if i == 2 => "two"
case _ => "some other number"
}
如果有小伙伴想了解更多,可以看看我这篇,scala模式匹配详细解析。
2.2 object和apply
前面介绍到,object是一个类的伴生对象,而且相当于static类,内存里只能有一个对象。apply方法则是说,可以在使用object对象的时候,直接默认使用。别说了,看代码:
scala> class Foo {}
defined class Foo
//有一个apply方法
scala> object FooMaker {
| def apply() = new Foo
| }
defined module FooMaker
//新建object,自动得就调用了apply
scala> val newFoo = FooMaker() //赋值的对象是Foo,因为调用了FooMaker()的apply
newFoo: Foo = Foo@5b83f762
上面的代码,FooMaker相当于一个工厂。
2.3 scala的泛型
scala中的泛型,叫做型变或变性,英文叫variance。主要有三种情况:
假设Dog是Animal的子类。那么有如下关系:
- 协变(covariant):List[Dog]是List[Animal]的子类,形态用一个+号表示,即List[+A](这里的A是泛指,类似java中的泛型,可以随便指定一个字母)。
- 逆变(contravariant):与协变相反,List[Animal]是List[Dog]的子类,形态用一个-号表示,即List[-A]。
- 不变(invariant):List[Dog]是List[Animal]的无关,不用任何表示,List[A]。
协变是比较符合正常逻辑思考的,一群狗确实也可以说是一群动物。逆变就比较反直觉了,不过这里先不讨论这点,后面有机会再讨论。
3.构建函数式的List
OK,有了上面的基础,就能够来构建一个函数式的数据结构了,不过在此之前,先让我们回顾下传统的List数据结构。
3.1 传统的List
还记得以前数据结构是怎样设计的吗?
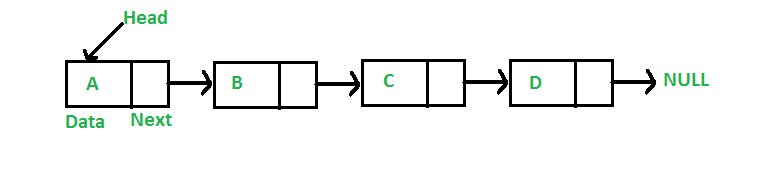
最普通的链表,通常都是由一个又一个的Node组成,一个Node中存储数据和下一个链表的变量。最后通过一个空值结尾,通常是Null。
在Java中,它的链表Linklist,是通过一个全局变量size来控制链表的。
通过for循环实现基础的增删查改等操作。而是,也是传统List的常见写法,但在函数式的List中可不能这样。还记得吗,函数式最大的特点就是无副作用。像java这里用一个全局的size来控制,那可真是万万不可啊,在多线程的情况下还不得崩溃。
关于为什么要写无副作用的代码,这里就不做探讨,详细内容可以看看这个系列的第一章。Scala函数式编程指南(一) 函数式思想介绍。
3.2 scala实现函数式的List
我们要做的是写出无副作用的集合,那要怎么做呢?给5秒钟闭上眼睛好好想一想有没有什么思路。。。
可能有的同学会想得到,这个答案就是递归。通过递归,能够避免副作用的产生。如常用的增删查改,如果使用递归,就可以避免使用一个全局变量,当然递归通常都没有直接使用for循环那么直观,所以充满递归的代码初次看会比较晦涩。但如果用多了,你会发现其实函数式的代码,也是非常好懂的。
下面,我们来看看如果使用递归实现一个List。
3.1 定义基本的类型
首先,我们要定义每个节点Node的类型,以及结尾Nil。由于使用到了递归,我们需要让Node和Nil都有同样的父类,因为递归函数的返回都是一样的。
如果还是不明白为什么要让Node和Nil为啥要有同样的父类,那不妨先放一放,继续看下去吧。
//定义自己的特质(相当于java的接口),泛型使用协变
sealed trait List[+A]
//定义一个case类,作为每一个List的结尾
case object Nil extends List[Nothing]
//定义List子类,也可以说是List中的每个Node,每个List都是由一个又一个的Cons组成,以Nil结尾
case class Cons[+A](head: A, tail: List[A]) extends List[A]
注意第一行定义了List[+A]的特质,和scala集合中的List是区分开来的,只是名字叫一样而已。这个是我们自己的List!!
而后定义了Nil和Cons,分别作为List的结尾和Node节点,注意case class也是scala的语法糖,可以理解为java bean。
之所以先定义了一个List的特质(接口),再分别用Nil和Cons继承它,是因为在递归的情况下,要让节点和结尾保持同一类型,而这个就是通过多态实现的。
3.2 实现List工厂
前面说到,通常是用object来作为工厂,这里也是一样的,我们可以定义List工厂。
定义工厂方法如下:
object List {
//使用可变长度,如果传进来的参数是空,就返回Nil,否则使用递归返回Cons,注意,这里的apply方法就是使用了递归
def apply[A](as: A*): List[A] = // Variadic function syntax
if (as.isEmpty) Nil
else Cons(as.head, apply(as.tail: _*))
}
这里的apply[A](as: A),括号里面的A的意思,是多个参数的意思,就是说可以有很多个参数,是scala的一个语法糖。
在最后
else Cons(as.head, apply(as.tail: _*))
看到最后面的 _*了吗,这个的意思,是除了第一个参数以外的其他参数,也是语法糖。
在这一个小小的地方就用到了递归,不断调用apply方法去解析后面的参数,最终生成一个List。初次看可能会比较迷,可能放在编译器里面运行一下,方便理解。而这种操作在scala函数式编程中,是非常普遍的做法。
至此,我们就建立了一个List的数据结构,先来看看我们的成果
//一个递归的List
scala> List(1,2,3)
res0: List[Int] = Cons(1,Cons(2,Cons(3,Nil)))
现在的List数据结构只是初具雏形,我们还得往里面加方法。
3.3 用函数式的方式实现List更多方法
通常来说,数据结构比较重要的是增删查改等操作,但因为是不可变的,同时函数式中通常是不改变对象信息的,所以这些基本操作反而不是首要的。
我们先来看一个简单些的例子吧,让一个List[Int]中的数据累加。
object List {
......
//传入参数是一个Int类型的List,使用模式匹配
def sum(ints: List[Int]): Int = ints match {
case Nil => 0
//使用递归累加
case Cons(x,xs) => x + sum(xs)
}
......
}
这里主要传入的参数是一个Int类型的List,然后使用模式匹配,如果是结尾,则返回0,如果是中间节点,则使用递归累加。
上面那个例子比较简单,明白后可以来看看如何为List构建更加通用的方法。通常比较常用的是前面介绍过的诸如map,filter等操作,下面先用一个map来说明一下吧。
object List {
......
//Map操作,使用模式匹配
def map[A,B](list: List[A],f: A => B): List[B] =list match {
case Nil ⇒ Nil
//使用递归
case Cons(head, tail) ⇒ Cons(f(head), map(tail,f))
}
......
}
map函数,需要传进入一个待处理的list,以及一个函数作为参数,用以对List中每个元素做处理。
比如说想让List中每个元素+1,那就可以传入
val addOne = (num:Int) => num+1
还记得之前说,在scala中,函数也能当作变量嘛。将addOne这个函数作为参数,这样就会让List中每个元素都+1,然后返回一个新的List,当然,这个也是用递归实现的。
实现代码看起来很简洁,也是用模式匹配,匹配每个元素的类型,就是是Node还是结尾。如果是结尾,直接返回,如果是Node,那么处理完当前数据,递归去处理后面的数据,并返回新的处理后的Node。
熟悉以后,会发现这样的处理方式看着很舒服,代码写得也很少,非常简洁。
在我看来,这就是递归的魅力所在。
除了map之外,还有其他操作处理,包括filter,foldLeft,reduce等操作。我把代码放在我的公众号中,限于篇幅这里就不讲太多。关注公众号:哈尔的数据城堡,回复“函数式数据结”可以获得。
代码中使用了隐式转换来扩充List的操作,并演示了如何使用隐式转换,以及如何使用复用来组合功能以实现新的功能。有同学可能不明白为什么简单的List要搞这么复杂,看了代码可能会更加理解。
4.函数式的二叉搜索树
这部分我是作为练习的,连同List代码放在一块,里面有基本的结构,但一些缺失的内容需要你来补充。相信我,做了一遍,肯定能够对函数式的数据结构有更深的理解。
对了,二叉搜索树的练习还有几个test case,做完跑一遍了,如果全过那基本上你写的代码就不会有太大的问题,good luck~
再说一遍我把练习的代码放在了我的公众号中,关注公众号:哈尔的数据城堡,回复“函数式数据结构”就能免费获得啦。
下一篇会再针对List和Tree的代码来讲一讲,有不明白的地方到时候也可以看看。
以上~~
推荐阅读:
通俗得说线性回归算法(一)线性回归初步介绍
通俗得说线性回归算法(二)线性回归初步介绍
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs
C,java,Python,这些名字背后的江湖!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号