Mysql增量写入Hdfs(一) --将Mysql数据写入Kafka Topic
一. 概述
在大数据的静态数据处理中,目前普遍采用的是用Spark+Hdfs(Hive/Hbase)的技术架构来对数据进行处理。
但有时候有其他的需求,需要从其他不同数据源不间断得采集数据,然后存储到Hdfs中进行处理。而追加(append)这种操作在Hdfs里面明显是比较麻烦的一件事。所幸有了Storm这么个流数据处理这样的东西问世,可以帮我们解决这些问题。
不过光有Storm还不够,我们还需要其他中间件来协助我们,让所有其他数据源都归于一个通道。这样就能实现不同数据源以及Hhdfs之间的解耦。而这个中间件Kafka无疑是一个很好的选择。
这样我们就可以让Mysql的增量数据不停得抛出到Kafka,而后再让storm不停得从Kafka对应的Topic读取数据并写入到Hdfs中。
二.binlog和maxwell介绍
2.1Mysql binlog介绍
binlog即Mysql的二进制日志。它可以说是Mysql最重要的日志了,它记录了所有的DDL和DML(除了数据查询语句)语句,以事件形式记录,还包含语句所执行的消耗的时间,MySQL的二进制日志是事务安全型的。
上面所说的提到了DDL和DML,可能有些同学不了解,这里顺便说一下:
- DDL:数据定义语言DDL用来创建数据库中的各种对象-----表、视图、索引、同义词、聚簇等如:CREATETABLE/VIEW/INDEX/SYN/CLUSTER...
- DML:数据操纵语言DML主要有三种形式:插入(INSERT),更新(UPDATE),以及删除(DELETE)。
在Mysql中,binlog默认是不开启的,因为有大约1%(官方说法)的性能损耗,如果要手动开启,流程如下:
- vi编辑打开mysql配置文件:
vi /usr/local/mysql/etc/my.cnf
在[mysqld]区块设置/添加如下,
log-bin=mysql-bin
注意一定要在[mysqld]下。
2. 重启Mysql
pkill mysqld
/usr/local/mysql/bin/mysqld_safe --user=mysql &
2.2kafka
这里只对Kafka做一个基本的介绍,更多的内容可以度娘一波。
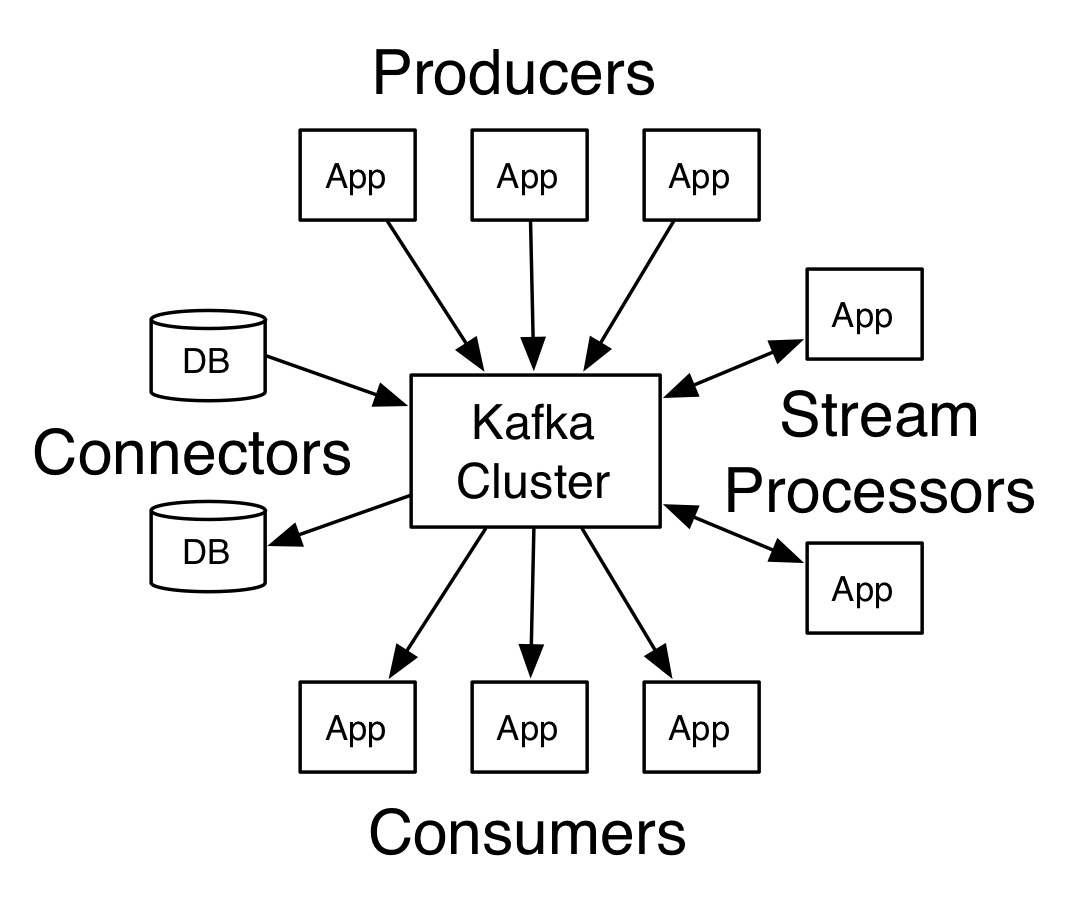
上面的图片是kafka官方的一个图片,我们目前只需要关注Producers和Consumers就行了。
Kafka是一个分布式发布-订阅消息系统。分布式方面由Zookeeper进行协同处理。消息订阅其实说白了吧,就是一个队列,分为消费者和生产者,就像上图中的内容,有数据源充当Producer生产数据到kafka中,而有数据充当Consumers,消费kafka中的数据。
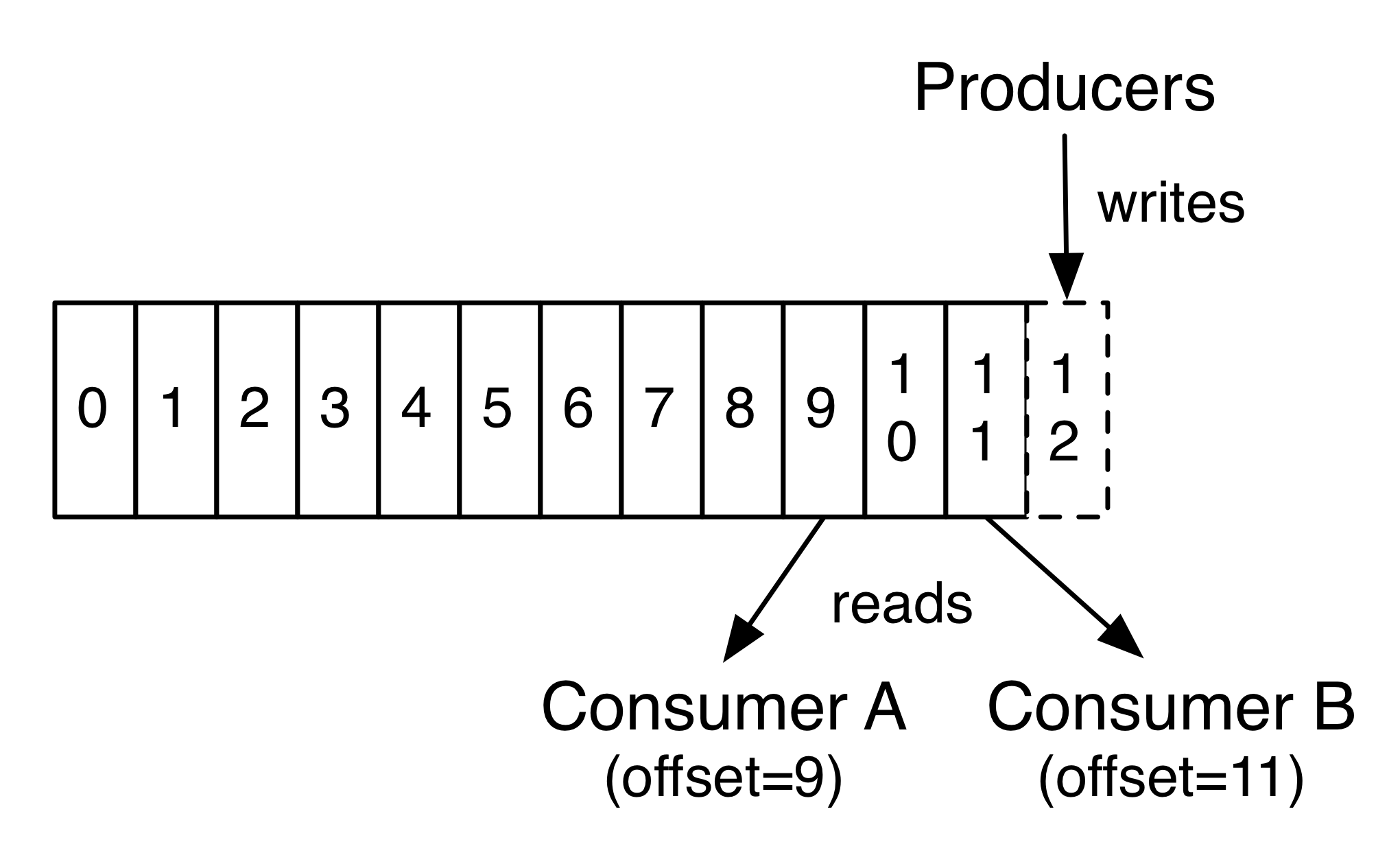
上图中的offset指的是数据的写入以及消费的位置的信息,这是由Zookeeper管理的。也就是说,当Consumers重启或是怎样,需要重新从kafka读取消息时,总不能让它从头开始消费数据吧,这时候就需要有个记录能告诉你从哪里开始重新读取。这就是offset。
kafka中还有一个至关重要的概念,那就是topic。不过这个其实还是很好理解的,比如你要订阅一些消息,你肯定是不会订阅所有消息的吧,你只需要订阅你感兴趣的主题,比如摄影,编程,搞笑这些主题。而这里主题的概念其实和topic是一样的。总之,可以将topic归结为通道,kafka中有很多个通道,不同的Producer向其中一个通道生产数据,也就是抛数据进去这个通道,Comsumers不停得消费通道中的数据。
而我们要做的就是将Mysql binlog产生的数据抛到kafka中充当作生产者,然后由storm充当消费者,不停得消费数据并写入到Hdfs中。
至于怎么将binlog的数据抛到kafka,别急,下面我们就来介绍。
2.3maxwell
maxwell这个工具可以很方便得监听Mysql的binlog,然后每当binlog发生变化时,就会以json格式抛出对应的变化数据到Kafka中。比如当向mysql一张表中插入一条语句的时候,maxwell就会立刻监听到binlog中有对应的记录增加,然后将一些信息包括插入的数据都转化成json格式,然后抛到kafka指定的topic中。
除了Kafka外,其实maxwell还支持写入到其他各种中间件,比如redis。
同时maxwell是比较轻量级的工具,只需要在mysql中新建一个数据库供它记录一些信息,然后就可以直接运行。
三.使用maxwell监听binlog
接下来我们将的是如果使用maxwell,让它监听mysql的binlog并抛到kafka中。maxwell主要有两种运行方式。一种是使用配置文件,另一种则是在命令行中添加参数的方式运行。这里追求方便,只使用命令行的方式进行演示。
这里介绍一下简单的将数据抛到kafka的命令行脚本吧。
bin/maxwell --user='maxwell' --password='XXXXXX' --host='127.0.0.1' \
--producer=kafka --kafka.bootstrap.servers=localhost:9092 --kafka_topic=maxwell --port=3306
各项参数说明如下:
- user:mysql用户名
- password:mysql密码
- host:Mysql地址
- producer:指定写入的中间件类型,比如还有redies
- kafka.bootstrap.servers:kafka的地址
- kafka_topic:指明写入到kafka哪个topic
- port:mysql端口
启动之后,maxwell便开始工作了,当然如果你想要让这条命令可以在后台运行的话,可以使用Linux的nohup命令,这里就不多赘述,有需要百度即可。
这样配置的话通常会将整个数据库的增删改都给抛到kafka,但这样的需求显然不常见,更常见的应该是具体监听对某个库的操作,或是某个表的操作。
在升级到1.9.2(最新版本)后,maxwell为我们提供这样一个参数,让我们可以轻松实现上述需求:--filter。
这个参数通常包含两个配置项,exclude和include。意思就是让你指定排除哪些和包含哪些。比如我只想监听Adatabase库下的Atable表的变化。我可以这样。
--filter='exclude: *.*, include: Adatabase.Atable'
这样我们就可以轻松实现监听mysqlbinlog的变化,并可以定制自己的需求。
OK,这一章我们介绍了mysql binlog,kafka以及maxwell的一些内容,下一篇我们将会看到storm如何写入hdfs以及定制一些策略。see you~~
推荐阅读 :
从分治算法到 MapReduce
一个故事告诉你什么才是好的程序员
大数据存储的进化史 --从 RAID 到 Hadoop Hdfs

 浙公网安备 33010602011771号
浙公网安备 33010602011771号