最全面最详细的字符集讲解来了!
1.字符集
-
编码与解码
在计算机科学中,信息的存储和处理都是基于二进制数的,这是因为二进制数在计算机硬件层面上实现起来最为简单和高效。二进制数由两个基本元素组成:0和1,这两个元素可以通过电子器件(如晶体管)的开关状态来轻松表示。而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码。反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码。 -
字符编码(Character Encoding) : 就是一套自然语言的字符与二进制数之间的对应规则。
-
字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
2.常见的字符编码
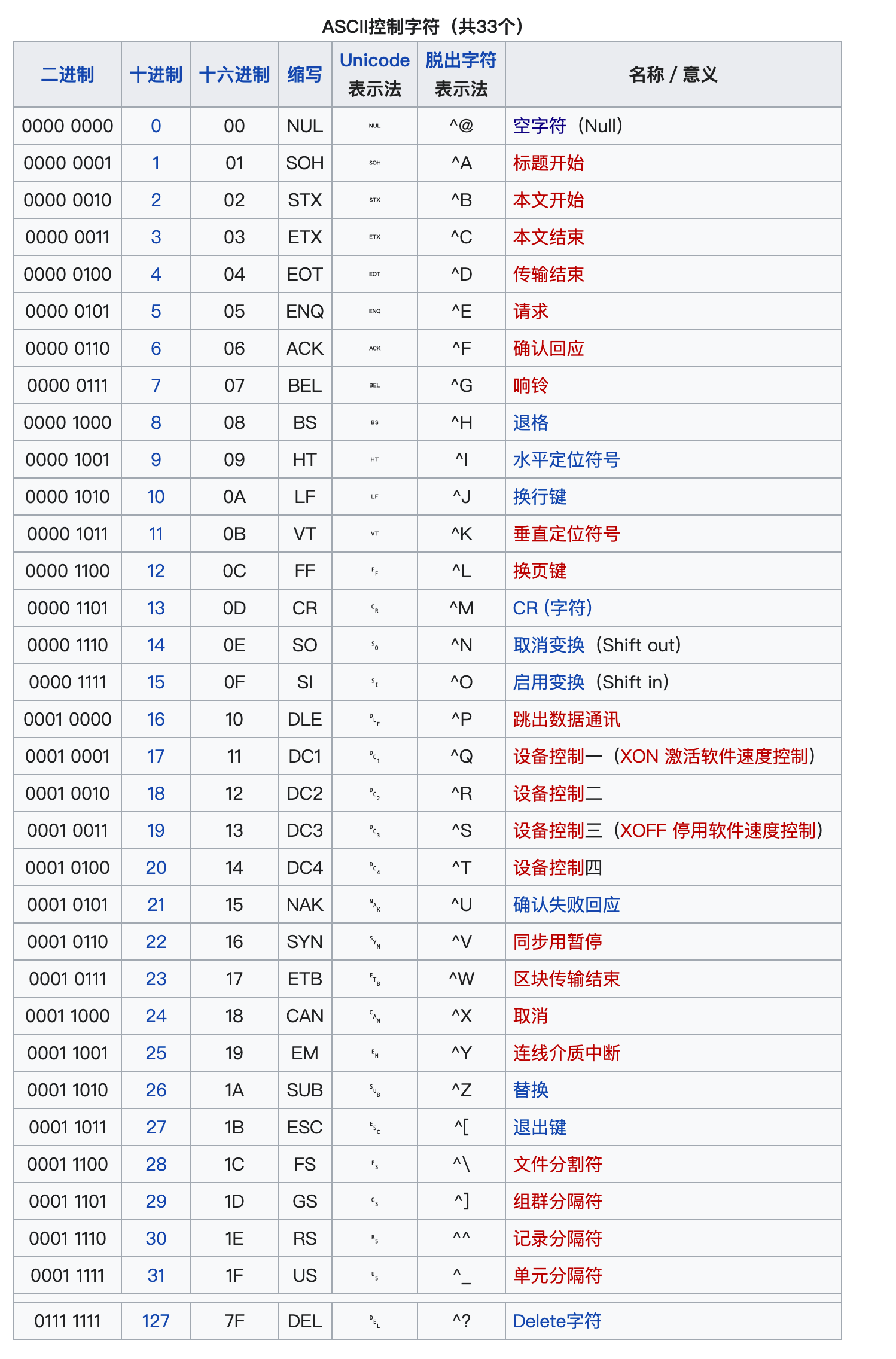
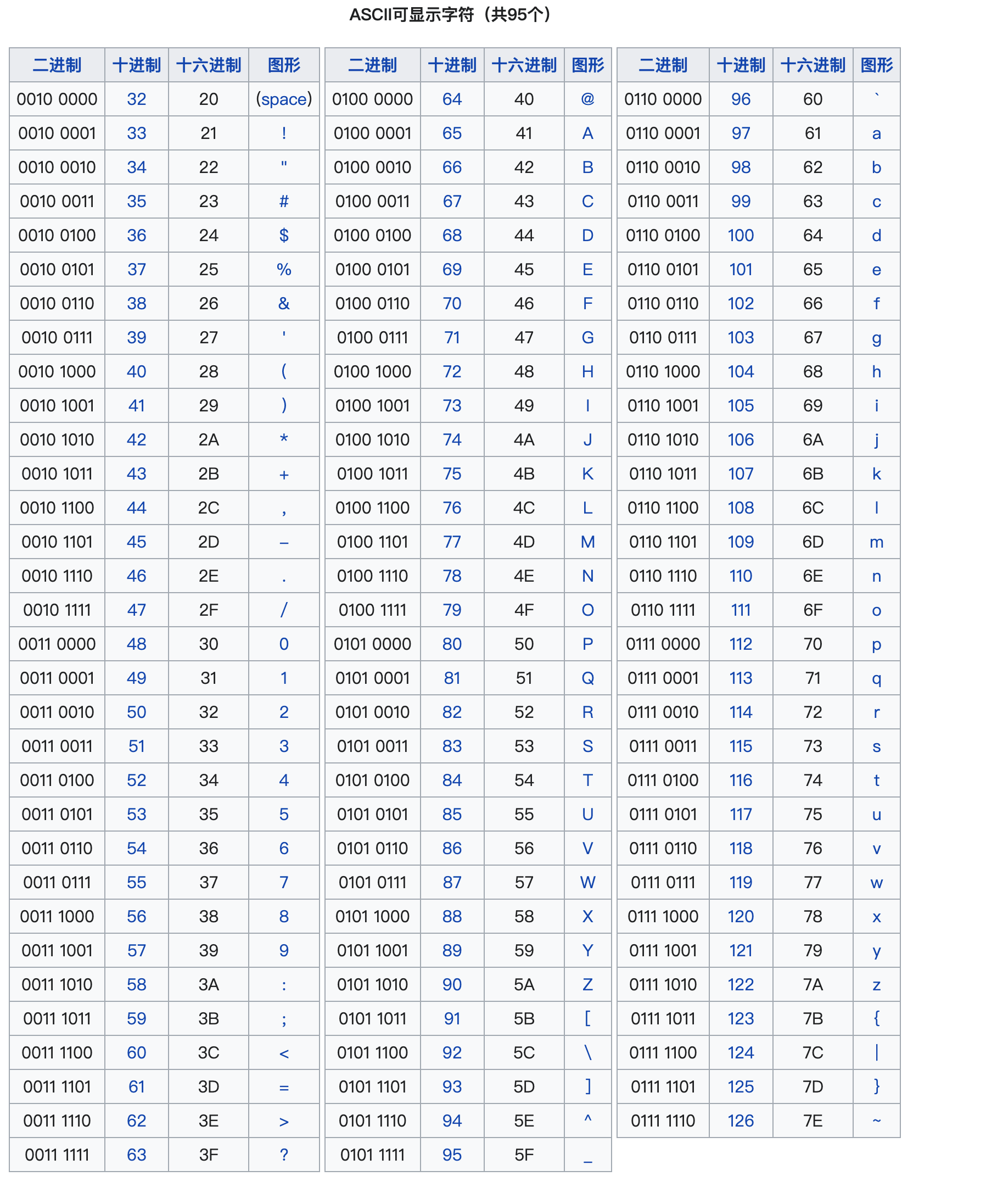
2.1 ASCII码(American Standard Code for Information Interchange,美国信息交换标准代码)
-
1961年,美国制定了一套字符编码,对
英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码。 -
ASCII码用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
-
基本的ASCII字符集,使用7位(bits)表示一个字符(最前面的1位统一规定为0),共
128个字符。比如:空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。 -
缺点:不能表示所有字符。
![ASCII-1]()
![ASCII-2]()
2.2 ISO-8859-1字符集
ISO-8859-1字符集,正式编号为ISO/IEC 8859-1:1998,又称Latin-1或“西欧语言”,是国际标准化组织内ISO/IEC 8859系列字符集的第一个8位字符集,兼容ASCII编码。以下是对ISO-8859-1字符集的详细概述:
一、基本介绍
- 名称:ISO-8859-1,又称Latin-1或“西欧语言”。
- 正式编号:ISO/IEC 8859-1:1998。
- 基础:以ASCII为基础,扩展了ASCII字符集。
二、特点
-
字符范围:ISO-8859-1字符集总共包含256个字符(即8位二进制数所能表示的范围)。
-
字符分类:
-
较低部分(从1到127之间的代码):这部分是最初的ASCII字符集,包括0-9的数字、大写和小写英文字母表(A-Z, a-z),以及一些特殊字符(如标点符号、控制字符等)。
-
较高部分(从160到255之间的代码):这部分包含了西欧国家使用的字符和一些被广泛使用的特殊字符,它们全都有实体名称。这些字符主要是为了支持使用附加符号的拉丁字母语言。
-
三、支持的语言
ISO-8859-1字符集支持多种西欧语言,包括但不限于:
阿尔巴尼亚语
巴斯克语
布列塔尼语
加泰罗尼亚语
丹麦语
荷兰语
法罗语
弗里西语
加利西亚语
德语
格陵兰语
冰岛语
爱尔兰盖尔语
意大利语
拉丁语
卢森堡语
挪威语
葡萄牙语
里托罗曼斯语
苏格兰盖尔语
西班牙语
瑞典语
此外,虽然英语没有重音字母,但仍会标明为ISO/IEC 8859-1编码。同时,欧洲以外的部分语言,如南非荷兰语、斯瓦希里语、印尼语及马来语、菲律宾他加洛语等,也可使用ISO/IEC 8859-1编码。
四、历史与替代
-
历史版本:ISO-8859-1字符集曾推出过ISO 8859-1:1987版,后更新为ISO/IEC 8859-1:1998版。
-
替代情况:尽管ISO-8859-1广泛用于西欧语言,但由于其字符集的限制(如不支持法语中的œ、Œ、Ÿ和芬兰语中的Š、š、Ž、ž等字符),它于1998年被ISO/IEC 8859-15所取代。ISO/IEC 8859-15在ISO-8859-1的基础上增加了这些字符,并同时加入了欧元符号。
五、应用与影响
- 浏览器默认字符集:ISO-8859-1是大多数浏览器默认的字符集之一,用于在网页上正确显示西欧语言的文本。
- 兼容性:由于其广泛的应用和历史地位,ISO-8859-1字符集在许多系统和应用程序中仍然保持着良好的兼容性。
2.3 GBxx的字符集
GBxx字符集是中国为了显示和处理中文字符而制定的一系列字符集标准,其中“GB”代表“国家标准”(Guobiao)的缩写。这些字符集涵盖了从基本的汉字编码到更广泛字符支持的多个版本。
以下是对GBxx字符集的一些主要版本的详细概述:
-
GB2312
-
全称:《信息交换用汉字编码字符集·基本集》,又称GB0,由中国国家标准总局发布,1981年5月1日实施。
-
GB2312是中华人民共和国国家标准简体中文字符集(简体中文表),一个小于127的字符的意义与原来相同,即向下兼容ASCII码。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含
7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,这就是常说的"全角"字符,而原来在127号以下的那些符号就叫"半角"字符了。 -
采用双字节编码,每个汉字或符号由两个字节表示。第一个字节称为“高位字节”,第二个字节称为“低位字节”。
-
-
GBK
最常用的中文编码-
全称:《汉字内码扩展规范(GBK)》1.0版,由中华人民共和国全国信息技术标准化技术委员会1995年制定。
-
GBK是对GB 2312的扩展,增加了对更多汉字和符号的支持,包括部分GB 2312未收录的汉字、繁体字、日文假名等。GBK总计拥有23940个码位,共收入21886个汉字和图形符号。
-
同样采用
双字节编码,但编码范围更广,总体编码范围为8140-FEFE。
-
-
GB18030
-
全称:国家标准GB 18030-2005《信息技术 中文编码字符集》,是中华人民共和国现时最新的内码字集。
-
GB 18030是对GBK的进一步扩展,支持更多的字符,包括中国国内少数民族的文字、繁体汉字以及日韩汉字等。共收录汉字70,244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。
-
与GB 2312-1980完全兼容,与GBK基本兼容,并支持GB 13000及Unicode的全部统一汉字。
-
2.4 UniCode字符集
Unicode编码,全称Unicode标准(The Unicode Standard),也被称为统一码、标准万国码、单一码等,是一种用于表示文本字符的标准编码系统。Unicode将世界上所有的文字用2个字节统一进行编码,为每个字符设定唯一的二进制编码,以满足跨语言、跨平台进行文本处理的要求。以下是Unicode编码的详细概述:
一、背景与目的
-
背景:传统的字符编码方案,如ASCII码,只能表示一种语言的字符,无法同时支持多种语言的字符,导致不同语言的字符无法混合出现在一个文本中。此外,不同国家和地区的字符编码标准各异,也造成了字符显示和处理的混乱。
-
目的:Unicode编码的目的是为每种语言中的每个字符设定一个统一且唯一的二进制编码,以满足跨语言、跨平台进行文本转换和处理的需求。
二、编码特点
-
唯一性:Unicode为每个字符分配了一个唯一的标识符,称为“码点”(Code Point),通常以十六进制数表示,前缀为“U+”。
-
广泛性:Unicode字符集包含了几乎所有语言的字符,包括汉字、拉丁字母、数字、标点符号、符号等,以及特殊的控制字符。
-
扩展性:Unicode字符集还在不断扩展,每个新版本都会加入更多新的字符。截至当前时间(2024年),Unicode已经收录了超过14万个字符。
三、Unicode的局限性
-
第一,英文字母只用一个字节表示就够了,如果用更多的字节存储是
极大的浪费。 -
第二,如何才能
区别Unicode和ASCII?计算机怎么知道两个字节表示一个符号,而不是分别表示两个符号呢? -
第三,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,
不够表示所有字符。
所以Unicode在很长一段时间内无法推广,直到互联网的出现,为解决Unicode如何在网络上传输的问题,于是面向传输的众多
UTF(UCS Transfer Format)标准出现。
具体来说,有三种编码方案:UTF-8、UTF-16和UTF-32。
四、编码方式
-
Unicode是字符集,UTF-8、UTF-16、UTF-32是三种
将数字转换到程序数据的编码方案。顾名思义,UTF-8就是每次8个位传输数据,而UTF-16就是每次16个位。其中,UTF-8 是在互联网上使用最广的一种 Unicode 的实现方式。-
UTF-8:一种变长编码方式,可以使用1到4个字节表示Unicode字符集中的任何字符,并且兼容ASCII编码。
-
UTF-16:使用16位或32位(代理对)表示Unicode字符,根据字节序的不同,可以分为UTF-16LE(小端序)和UTF-16BE(大端序)。
-
UTF-32:固定使用32位(4个字节)表示Unicode字符,同样根据字节序的不同,可以分为UTF-32LE和UTF-32BE。
-
-
Unicode码点:Unicode定义了字符集中每个字符的唯一码点,如汉字“中”的Unicode码点是U+4E2D。
-
互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。UTF-8 是一种
变长的编码方式。它可以使用 1-4 个字节表示一个符号它使用一至四个字节为每个字符编码,编码规则:-
128个US-ASCII字符,只需一个字节编码。
-
拉丁文等字符,需要二个字节编码。
-
大部分常用字(含中文),使用三个字节编码。
-
其他极少使用的Unicode辅助字符,使用四字节编码。
-
-
举例:
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
————————————————————|—–—–—–—–—–—–—–—–—–—–—–—–—–—–
0000 0000-0000 007F | 0xxxxxxx(兼容原来的ASCII)
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
注意
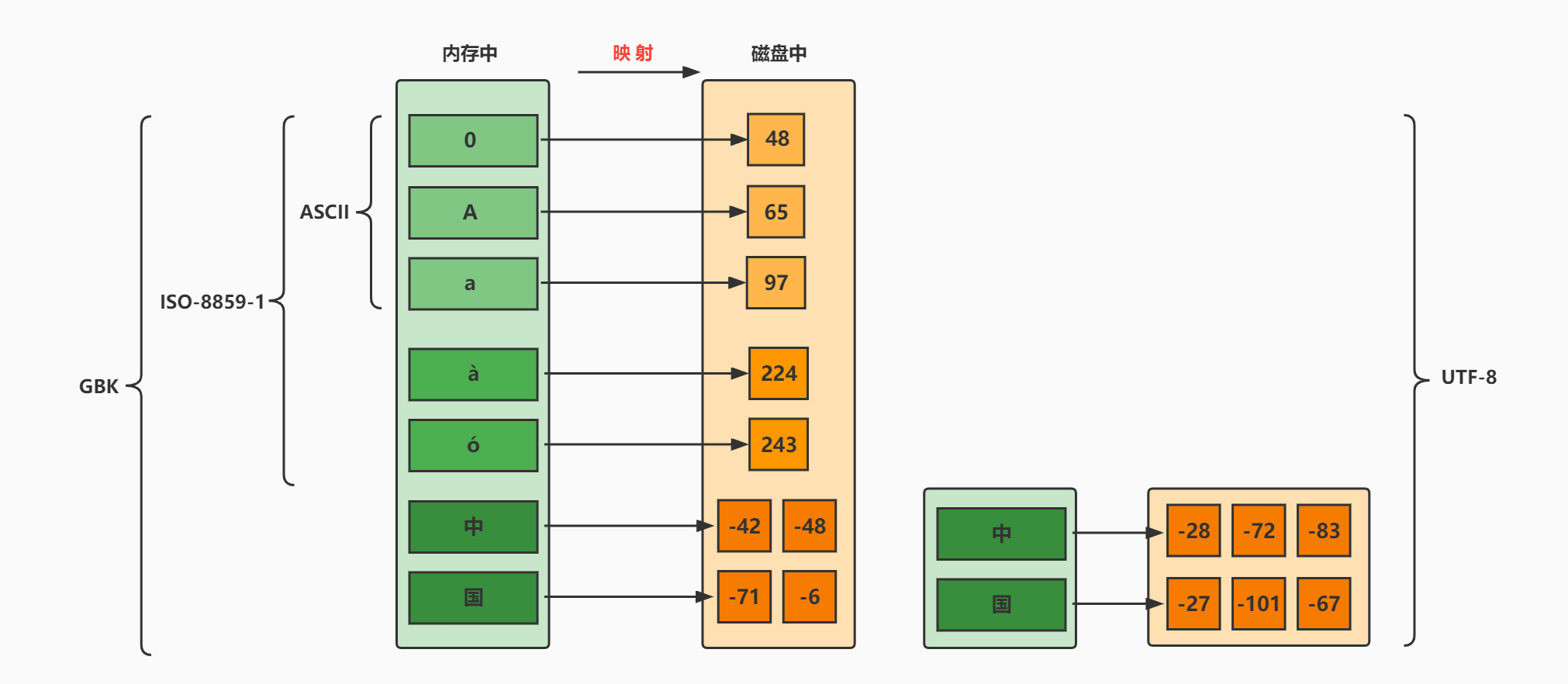
在中文操作系统上,ANSI(美国国家标准学会、AMERICAN NATIONAL STANDARDS INSTITUTE: ANSI)编码即为GBK;在英文操作系统上,ANSI编码即为ISO-8859-1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号