
03-深入类和对象
一、深入类和对象
1.1、鸭子类型和多态
维基百科中的解释为:
鸭子类型(英语:duck typing)在程序设计中是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由"当前方法和属性的集合"决定。这个概念的名字来源于由詹姆斯·惠特科姆·莱利提出的鸭子测试,“鸭子测试”可以这样表述:
“当看到一只鸟走起来像鸭子、游泳起来像鸭子、叫起来也像鸭子,那么这只鸟就可以被称为鸭子。”在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。
class Cat(): def say(self): print("I am a cat") class Dog(): def say(self): print("I am a dog") class Duck(): def say(self): print("I am a duck") animal_list = [Cat,Dog,Duck] for animal in animal_list: animal().say()#实例化对象,在调用say方法 三个类实现同一个方法名,这就是多态。然后可以将这些类归为一种类型(鸭子类型) #python中的魔法函数充分也利用了鸭子类型的特性,可以在任一类中定义 name_list = ["list1","list2"] name_list1 = ["love","python"] name_tuple = (3,4) name_set = set() name_set.add(5) name_set.add(6) name_list.extend(name_set) #参数name_set:['list1', 'list2', 5, 6]参数name_tuple:['list1', 'list2', 3, 4] print(name_list) # 参数:name_list1:['list1', 'list2', 'love', 'python'] """ 这里说的是只要传入的参数是一个可迭代的类型就可以, 就连我们自定义的类将类的魔法函数__getitem__(返回 )、__iter__就可以变成可迭代的,都可以传入 def extend(self, *args, **kwargs): # real signature unknown Extend list by appending elements from the iterable. pass """ #首先这三个类里面都包含了这个say()方法,如果在JAVA里边,要实现多态的话,需要继承父类在覆盖父类的方法实现多态。 # 例如:一般情况先定义一个父类Animal,然后这个Animal有一个say()方法。 # 然后在写其他类例如上面的Cat类,Cat类继承Animal类,然后重写say()方法。 # 然后指定类型实例化这个Cat对象,在python中不需要指定类型,在JAVA中(静态语言)必须指定类型, #这是动态语言和静态语言最大的区别。在python中都要做的一件事就是每个对象下都要写这个say()方法
1.2、抽象基类(abc)
python里边的抽象基类,是不能够实例化的。python是动态语言,动态语言是没有变量的类型的。在python中变量只是一个符号而已,这个符号可以指向任何类型的对象。动态语言缺少编译时检查错误的环境,在python中编写代码是很难发现错误的,只有要运行解释器才能找到错误。这也是动态语言共有的一个缺陷。python信奉的是鸭子类型,鸭子类型贯穿于整个面向对象之中。抽象基类是什么意思?在这个基础的类当中,设定好一些方法,然后所有的继承这个基类的类,都必须覆盖这个抽象基类里面的方法。抽象基类是无法实例化的。
##################去检查某个类是否有某种方法############################# class Students(object): def __init__(self,student_list): self.student = student_list def __len__(self): return len(self.student) students = Students(["lishuntao","test","python"]) # print(hasattr(students,"__len__"))#True # print(hasattr(students,"__getitem__"))#False ##############################判定某个对象的类型##################################### from collections.abc import Sized print(isinstance(students,Sized))#True ######################利用抽象基类实现接口的 强制规定########################## #强制某些子类必须实现某些方法 #实现了一个web框架,集成cache(redis,cache,memorychache) #需要设计一个抽象基类,指定子类必须实现某些方法 #如何去模拟一个抽象基类呢? class CacheBase(): def get(self,key): raise NotImplementedError def set(self,key,value): raise NotImplementedError #用户在实现这个抽象基类的子类时候,必须实现这里面的两个方法 class RedisCache(CacheBase): pass redis = RedisCache() #redis.get("key")#抛出异常raise NotImplementedError NotImplementedError #但这样做不好,我们需要刚初始化的时候就抛出异常,接下来就换成abc实现个人基类 import abc class Cache1Base(metaclass=abc.ABCMeta): @abc.abstractmethod def get(self,key): pass @abc.abstractmethod def set(self,key,value): pass class RedisCache1(Cache1Base): pass redis_cache1 = RedisCache1() #TypeError: Can't instantiate abstract class RedisCache1 with abstract methods get, set #利用抽象基类直接初始化抛出异常 #在python当中已经实现了一些通用的抽象基类,放在 from collections.abc import *
抽象基类不是用来继承的,它只是利用抽象基类来理解继承之间的关系,以及接口的定义,我们去使用的时候一定要用我们的鸭子类型,如果一定要用接口的话,那么推荐使用mixin多继承的方式去实现它。抽象基类使用的时候设计过度,反而不容易理解它。
1.3、isinstance和type的区别
class A: pass class B(A): pass b = B() print(isinstance(b,B)) #True print(isinstance(b,A)) #True print(type(b) is B) #True is与==的区别,==判断值是否相等,is判断是不是同一个对象(id(b)地址是否一样) print(type(b),A) #False ###########判断类型:为什么更推荐用isinstance而不是type?############## #因为如果判断某个对象的类型的话,用isinstance会根据树的形状去搜索,从叶子搜索到跟就可以判断是否是相同类型, #就算是不同对象可能是相同类型,然而type是同种类型,但不同对象。
1.4、类变量和实例变量
class A: a = 1 #a是类变量 def __init__(self,x,y):#self是类的实例 x与y已经绑定到实例上的属性上了 self.x = x self.y = y num = A(2,3) # A.a = 11 #如果修改类属性,那么实例的值也会跟着变 # num.a = 100 #如果修改实例属性,那么类属性的值不变, # 会在对象中新建一个实例属性的值,寻找的时候直接对象属性中寻找。 print(num.x,num.y,num.a) #2 3 1 为什么实例num能够找到A的类属性呢, # 首先实例num先在实例属性种寻找,如果没有找到的话就会向上寻找,找到类属性 print(A.a) # 1 类属性 print(A.x)#AttributeError: type object 'A' has no attribute 'x' #类找实例属性找不到是因为类首先到自己的属性中找,如果没有找到的话,就不会向下寻找
1.5、类和实例属性的查找顺序----mro查找
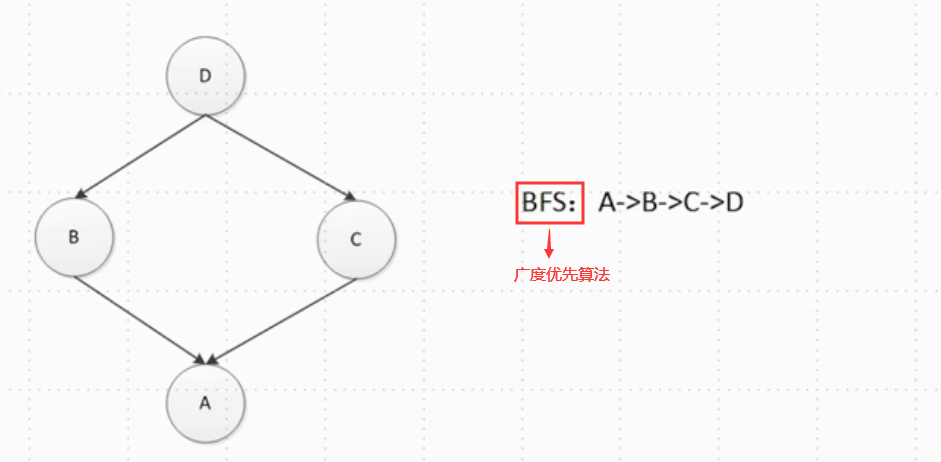
类查找属性的查找顺序有深度优先查找和广度优先查找。
广度优先查找:
#python3以后称为新式类,全部都继承object class D: pass class C(D): pass class B(D): pass class A(B,C): pass print(A.__mro__) #(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.D'>, <class 'object'>) #__mro__魔法方法直接显示出类查找属性的顺序
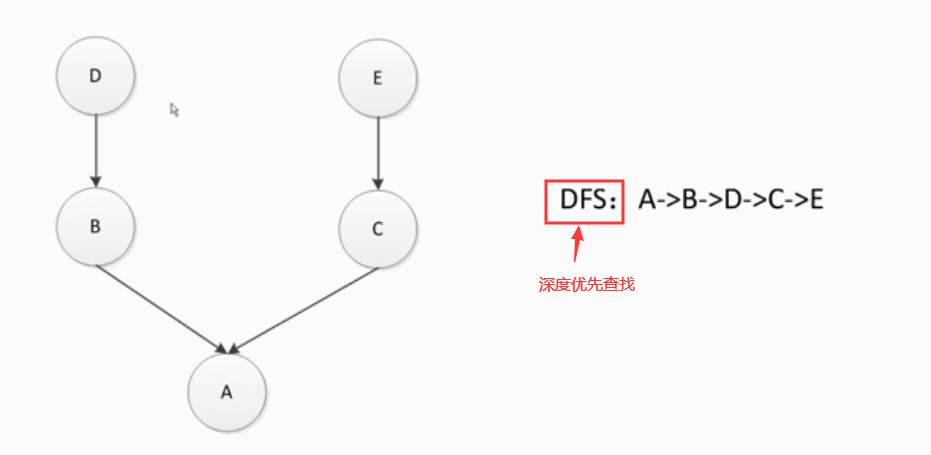
深度优先查找:
#python3以后称为新式类,全部都继承object class E: pass class D: pass class C(E): pass class B(D): pass class A(B,C): pass print(A.__mro__) #(<class '__main__.A'>, <class '__main__.B'>, <class '__main__.D'>, <class '__main__.C'>, <class '__main__.E'>, <class 'object'>)
但在python3中为了避免深度优先算法与广度优先算法混乱,出现了C3算法避免了两种算法出现的问题,例如菱形搜索应用深度优先算法,从A找B再到D找到方法,可能C中重写了D的方法,因此深度优先算法不能解决菱形搜索的情况,然而C3算法解决了以上出现的两种情况。
1.6、类方法、静态方法和实例方法
class Date: def __init__(self,year,month,day): self.year = year self.month = month self.day = day #静态方法的缺点就是硬编码,如果换类名又要重新改返回的类名 @staticmethod def parse_from_string(date_str): year,month,day = tuple(date_str.split("-")) return Date(int(year),int(month),int(day)) #为啥不用classmethod替换staticmethod呢? #检查时间格式是否正确,不需要对象返回回来,因此这个时候它就有用了,而其余都是要将对象返回回来 @staticmethod def valid_str(date_str): year, month, day = tuple(date_str.split("-")) if int(year)>0 and (int(month)>0 and int(month)<=12) and int(day)<=31: return True else: return False #类方法就解决掉刚才的硬编码问题 @classmethod def from_string(cls,date_str): year, month, day = tuple(date_str.split("-")) return cls(int(year), int(month), int(day)) def __str__(self): return "{year}/{month}/{day}".format(year=self.year,month=self.month,day=self.day)
if __name__ == '__main__': days = Date(2019,12,1) print(days) #2019/12/1 #方法中传入self这个参数叫实例方法, #用staticmethod完成初始化 date_str = "2019-12-01" new_day = Date.parse_from_string(date_str) print(new_day) #2019/12/1 # 用classmethod完成初始化 new_day = Date.from_string(date_str) print(new_day) #2019/12/1 print(Date.valid_str("2019-12-01")) #True
1.7、数据封装和私有属性
导入的Date是上面写的类:
from chapter04.class_method import Date class User: def __init__(self,birthday): self.__birthday = birthday#在属性前面加上双下划线, # 就变成了私有属性,外面实例化对象不能直接访问 def get_age(self): """ 希望用户看不见出生日期(我们提供计算年龄的接口)在这里只能用公共方法调用,子类都不能使用私有属性 :return:返回用户年龄, """ return 2019 - self.__birthday.year if __name__ == '__main__': user = User(Date(1999,9,9)) print(user._User__birthday) #1999/9/9 如果想要访问那么对象名._classname__attr就可以获取python的私有属性 print(user.get_age())#20 #从语言的角度来讲,没有绝对的私有属性的安全性的,都是可以突破的,
1.8、python对象的自省机制
自省:就是通过一定的机制查询到对象的内部结构。
from chapter04.class_method import Date class Person: name = "user" class Student(Person): def __init__(self,school_name): self.school_name = school_name if __name__ == '__main__': student = Student("清华大学")#实例 #通过__dict__查询属性 print(student.__dict__) #{'school_name': '清华大学'} #上面打印的是实例的属性,为啥name属性没有进入__dict__呢?因为name属于Person类, # 实例查询到name的值,但并不是说name属性属于实例 print(student.name) #user print(Person.__dict__)#结果如下:类的__dict__比对象也就是实例更加丰富 #{'__module__': '__main__', 'name': 'user', '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None} #给实例添加属性 student.__dict__["school_addr"] = "四川市" print(student.school_addr)#四川市 #会列出我们对象的所有属性 print(dir(student)) #['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', 'name', 'school_addr', 'school_name'] list1 = [1,2,3,4] print(dir(list1))#列表不可以用__dict__,列表没有这个属性 #['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
1.9、super真的是调用父类吗?
class A: def __init__(self): print("A") class B(A): def __init__(self): print("B") super(B,self).__init__() # 想让他初始化B之后,运行A的初始化,这是python2的用法 super().__init__() #python3的用法 #既然重写了A的构造函数,为什么还要调用super? #super函数到底执行顺序是什么?(遵循__mro__算法逻辑顺序) from threading import Thread class MyThread(Thread): def __init__(self,name,user): self.user = user # self.name = name #实际上父类Thread的参数有了name这个参数,我们直接可以调用父类 super().__init__(name=name)#这样我们就不用写具体的name相关的逻辑了 if __name__ == '__main__': b = B() #运行结果:B,A,A
2.0、mixin继承案例----django-rest-framework
mixin模式特点:
1、Mixin类功能单一
2、不和基类关联(mixin只是定义一个方法(接口)),可以和任一基类组合、基类可以不和mixin组合就能初始化成功
3、在mixin中不要使用super的用法
4、设置mixin的时候尽量以Mixin结尾,这样别人就可以读懂代码(规范)
接下来展示的代码就是Django-REST-Framework的Mixins的设计模式(Mixin源代码):
""" Basic building blocks for generic class based views. We don't bind behaviour to http method handlers yet, which allows mixin classes to be composed in interesting ways. """ from rest_framework import status from rest_framework.response import Response from rest_framework.settings import api_settings class CreateModelMixin: """ Create a model instance. """ def create(self, request, *args, **kwargs): serializer = self.get_serializer(data=request.data) serializer.is_valid(raise_exception=True) self.perform_create(serializer) headers = self.get_success_headers(serializer.data) return Response(serializer.data, status=status.HTTP_201_CREATED, headers=headers) def perform_create(self, serializer): serializer.save() def get_success_headers(self, data): try: return {'Location': str(data[api_settings.URL_FIELD_NAME])} except (TypeError, KeyError): return {} class ListModelMixin: """ List a queryset. """ def list(self, request, *args, **kwargs): queryset = self.filter_queryset(self.get_queryset()) page = self.paginate_queryset(queryset) if page is not None: serializer = self.get_serializer(page, many=True) return self.get_paginated_response(serializer.data) serializer = self.get_serializer(queryset, many=True) return Response(serializer.data) class RetrieveModelMixin: """ Retrieve a model instance. """ def retrieve(self, request, *args, **kwargs): instance = self.get_object() serializer = self.get_serializer(instance) return Response(serializer.data) class UpdateModelMixin: """ Update a model instance. """ def update(self, request, *args, **kwargs): partial = kwargs.pop('partial', False) instance = self.get_object() serializer = self.get_serializer(instance, data=request.data, partial=partial) serializer.is_valid(raise_exception=True) self.perform_update(serializer) if getattr(instance, '_prefetched_objects_cache', None): # If 'prefetch_related' has been applied to a queryset, we need to # forcibly invalidate the prefetch cache on the instance. instance._prefetched_objects_cache = {} return Response(serializer.data) def perform_update(self, serializer): serializer.save() def partial_update(self, request, *args, **kwargs): kwargs['partial'] = True return self.update(request, *args, **kwargs) class DestroyModelMixin: """ Destroy a model instance. """ def destroy(self, request, *args, **kwargs): instance = self.get_object() self.perform_destroy(instance) return Response(status=status.HTTP_204_NO_CONTENT) def perform_destroy(self, instance): instance.delete()
看这些源代码是不是和上面的规范要求都是符合的呢?好接下来看我项目中的实战代码:
class GoodsListViewSet(mixins.ListModelMixin,mixins.RetrieveModelMixin,viewsets.GenericViewSet): """ 商品列表页 分页 搜索 过滤 排序 """ queryset = Goods.objects.all() serializer_class = GoodsSerializer pagination_class = GoodsSetPagination filter_backends = [DjangoFilterBackend,filters.SearchFilter,filters.OrderingFilter] #这是精确搜索过滤,我们需要的是模糊搜索 # filterset_fields = ['name', 'shop_price'] filter_class = GoodsFilter search_fields = ("name","goods_brief","goods_desc") ordering_fields = ("shop_price","sold_num","add_time")
基类和Mixin组合成新类,实现想要的功能。
2.1、python中的with语句
#try except else finally def exe_try(): try: print("coding is started") raise KeyError except KeyError as e: print("key error") return 2 else: #要程序没有出异常就会运行else print("other coding") return 3 finally: print("finally") return 4 #python会自动识别自己的协议 #上下文管理器协议(with调用)(简化try-finally用法的) class Sample(): def __enter__(self): #获取资源 print("enter") return self def __exit__(self, exc_type, exc_val, exc_tb): #释放资源 print("exit") def do_something(self): print("do something") with Sample() as sample: sample.do_something() """ 当我们离开with语句的时候,就会调用__exit__方法 运行结果: enter do something exit """ # if __name__ == '__main__': # result = exe_try() # print(result) """ 运行结果:为什么会出现这样的结果?程序运行,直接抛出异常KeyError先返回2进入栈底(栈的知识), 然后执行finally中的返回4,4进入栈顶,栈的规则是后进先出,则返回的是4 coding is started key error finally 4 """
2.2、contextlib简化上下文管理器
import contextlib @contextlib.contextmanager#装饰器将函数变为上下文管理器(上下文管理器都可以用with用) def file_open(filename): print("file open") #yield之前的相当于__enter__函数的操作 yield {} print("file end")#之后相当于__exit__函数的操作 with file_open("test.txt") as fp: print("file open processing") """ 运行结果: file open file open processing file end """
这样就大大简化我们的上下文管理器啦。
