
记一次svg反爬学习
网址:http://www.porters.vip/confusion/food.html
打开开发者工具后

页面源码并不是真实的数字,随便点一个d标签查看其样式
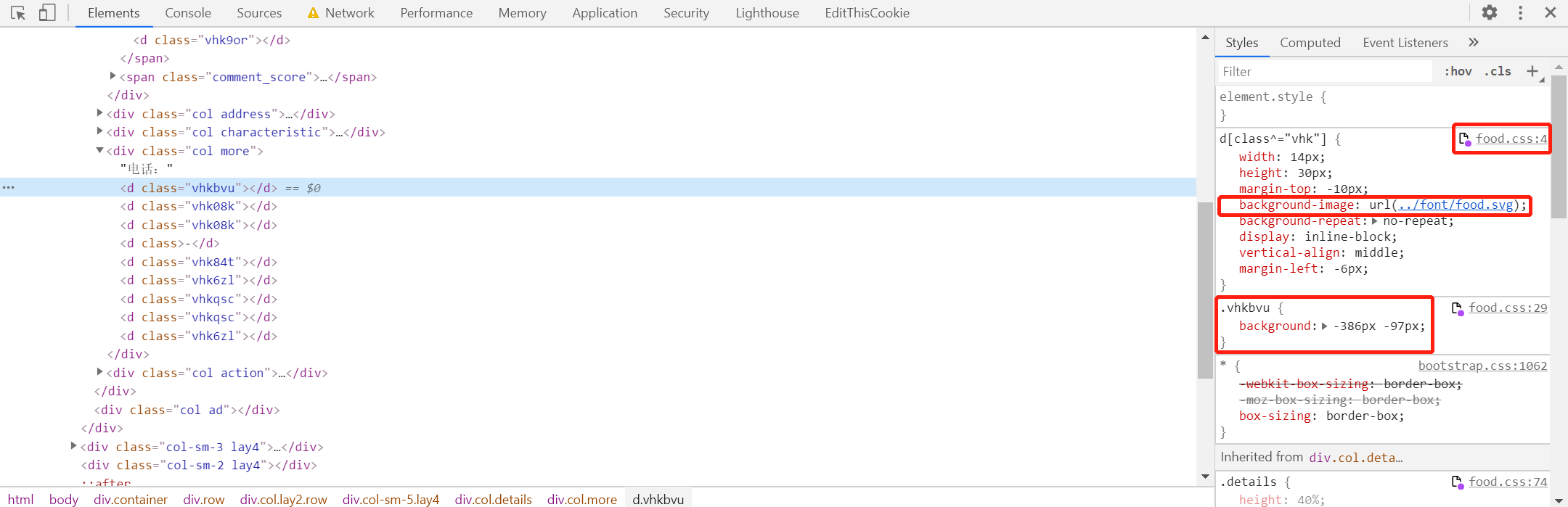
我们需要找到两个文件,food.css和food.svg文件,点开第一个红框会在Sources面板打开该文件,鼠标放到food.css文件名上,显示的就是food.css的地址
鼠标放到第二个红框的url上面,得到的就是food.svg的地址,也可以右键Copy link address获取地址
svg_url = 'http://www.porters.vip/confusion/font/food.svg' css_url = 'http://www.porters.vip/confusion/css/food.css'
这里我们打开svg的地址后是这样的

我们会看到四行毫无规律的数字,查看源码发现又是一堆看着像加密的代码(其实不是,这里是svg-font的坐标)
然后打开css文件
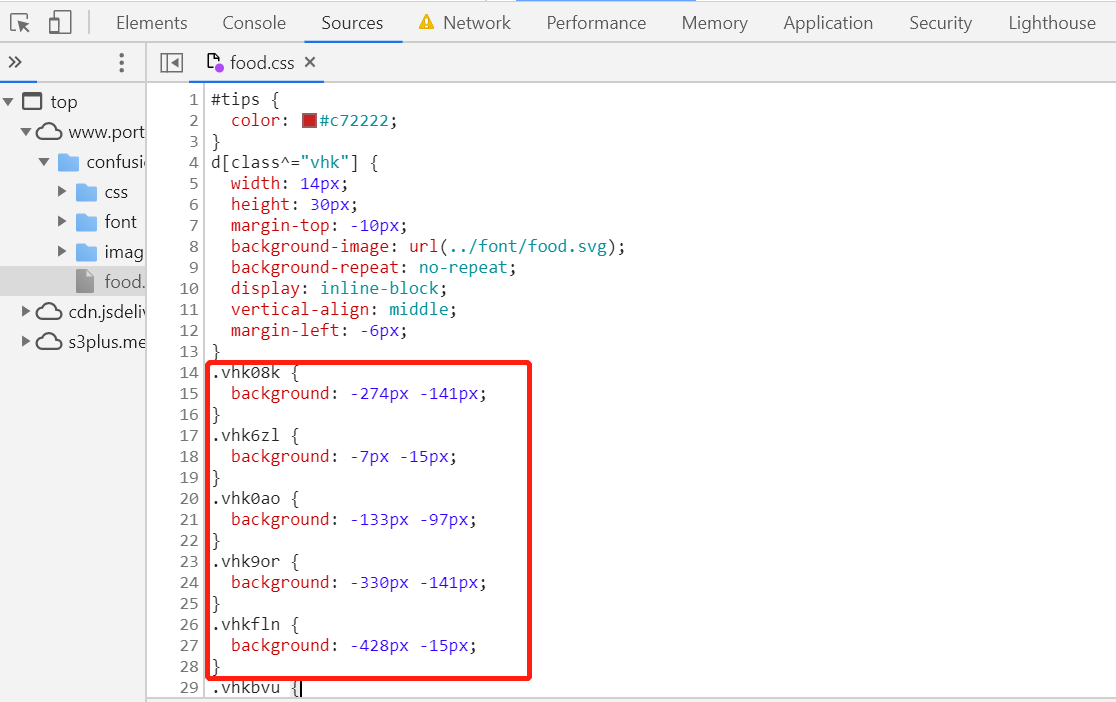
这里的background的css渲染数字的坐标
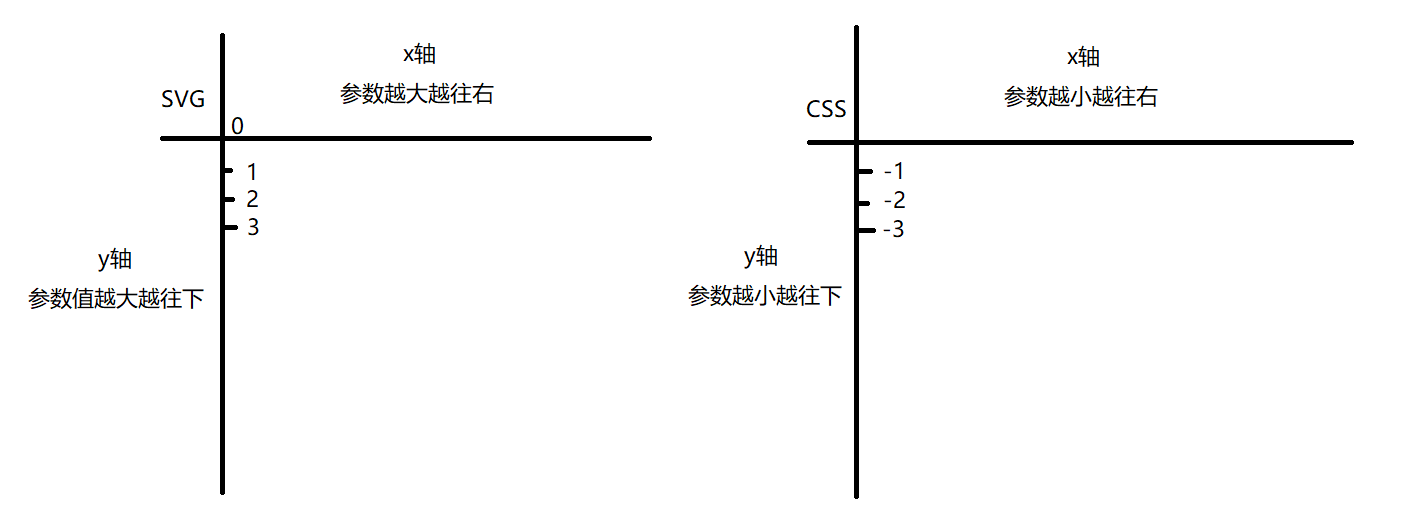
到此,需要解释一下为什么会有两个坐标,及字符定位的问题:
浏览器根据css样式中设定的坐标和元素宽高来确定svg中对应的数字。
接下来我们就只获取下面图中的电话号码
因为获取d标签的class属性比较容易,这里就简单构造一个电话号SVG列表
获取svg文件和css文件,以及构造电话号svg列表(这里比较简单,没什么解释的)
def get_file(url): resp = requests.get(url=url) content = resp.text return content svg_url = 'http://www.porters.vip/confusion/font/food.svg' css_url = 'http://www.porters.vip/confusion/css/food.css' css_content = get_file(css_url) svg_content = get_file(svg_url) # 获取源码中电话号的SVG列表 svg_list = ['vhkbvu', 'vhk08k', 'vhk08k', 'vhk84t', 'vhk6zl', 'vhkqsc', 'vhkqsc', 'vhk6zl']
for svg_name in svg_list:
print(svg_name)
...
在上一步,我们已经可以通过循环拿到每一个svg_name,接下来就是通过正则获取css文本中,对应的svg_name的样式(坐标)
def get_css_coordinates(css_content, svg_name): res = re.findall('\.%s\s{\s+background:\s-(\d+)px\s-(\d+)px;\s}' % svg_name, css_content) if bool(res): x, y = res[0]
return (int(x), int(y))
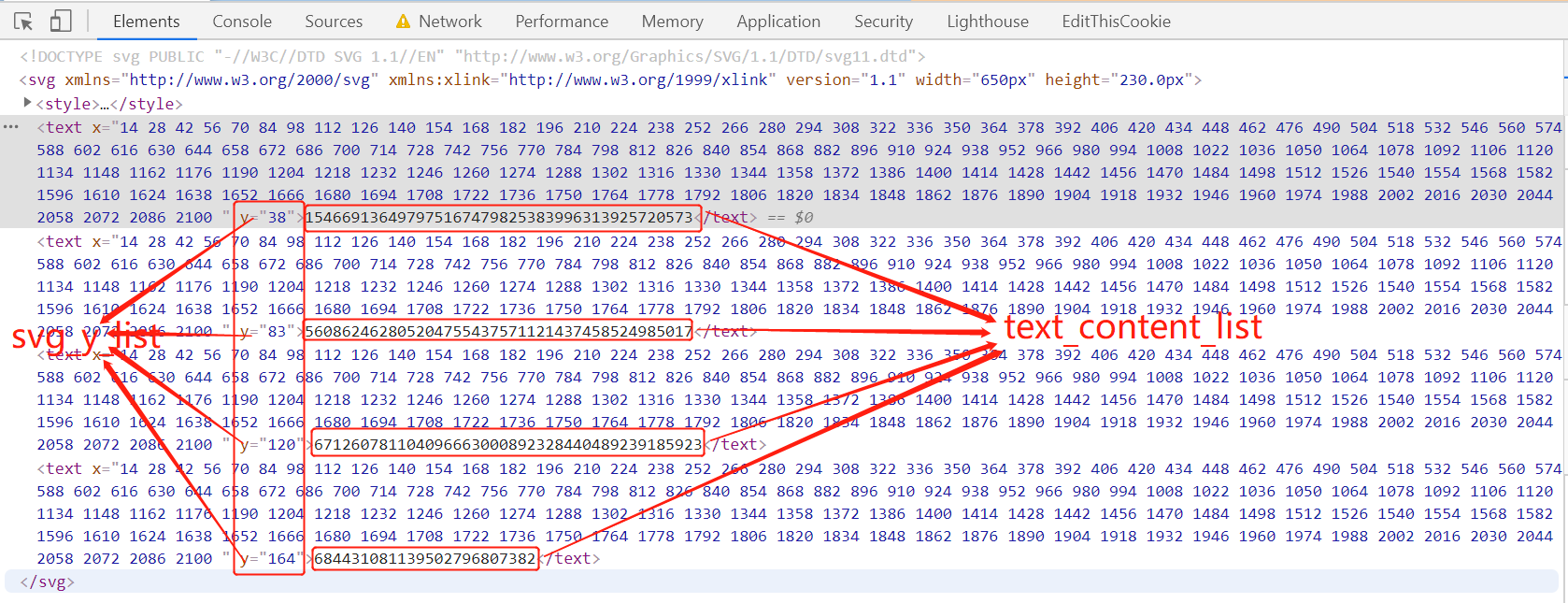
得到css_x和css_y坐标后,拿着css_y坐标去定位上面svg文件中四行数字,获取css_x,css_y坐标对应的数字
from parsel import Selector
def get_svg_text_content(svg_content, css_y): # 获取svg中字符的font-size属性,后面会用到 font_size = svg_content.split('font-size:')[1].split('px;')[0] svg_data = Selector(svg_content) # 获取svg文件 text元素的y属性列表 svg_y_list = svg_data.xpath('//text/@y').getall() # 取到大于css_y且最近的一个 new_svg_y_list = [svg_y for svg_y in svg_y_list if css_y <= int(svg_y)] # print(new_svg_y_list[0]) # 获取目标svg_y在原svg_y_list中的下标 index = svg_y_list.index(new_svg_y_list[0]) # print(svg_data.xpath('//text/text()').getall()) text_content = svg_data.xpath('//text/text()').getall()[index] return text_content, font_size
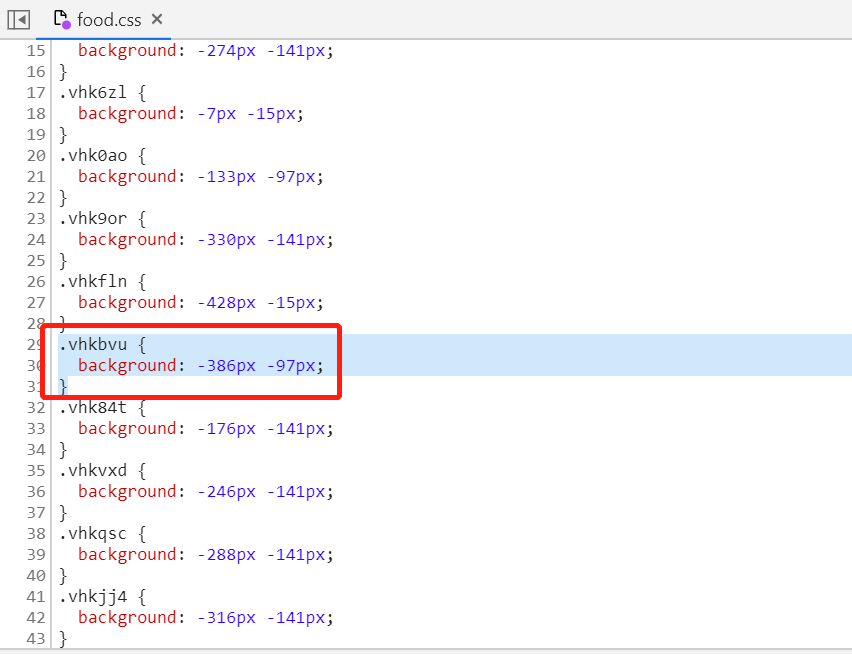
解释一下,在上面所示代码中,在电话号svg列表中第一个元素vhkbvu,对应的css_y的值为97,而我们获得的svg_y_list为 ['38', '83', '120', '164'],在此列表大于97且最近接的就是120,
因此我们确定svg_y的值为120,同时也确定了我们需要的是第三行数据,通过svg_y,也就是纵坐标的值已经确定
现在我们获取到了text_content为:671260781104096663000892328440489239185923,也就是上图中的第三个text标签中的文本,而font-size为14px
font-size也可以打开svg文件后找到style,查看里面font-size的值
下面我们来确定横坐标,横坐标确定后,我们就可以找到具体的数字值,从而完成破解
def get_char(text_content, css_x, font_size): text_chars = list(text_content) # 利用x轴的坐标确定是第几个元素 n = css_x // int(font_size) print(text_chars[n]) return text_chars[n]
至此,我们的svg反爬破解完成,下面是完整代码
import requests import re from parsel import Selector def get_file(url): resp = requests.get(url=url) # print(resp.text) content = resp.text return content def get_css_coordinates(css_content, svg_name): res = re.findall('\.%s\s{\s+background:\s-(\d+)px\s-(\d+)px;\s}' % svg_name, css_content) if bool(res): x, y = res[0] return (int(x), int(y)) def get_svg_text_content(svg_content, css_y): # 获取svg中字符的font-size属性,后面会用到 font_size = svg_content.split('font-size:')[1].split('px;')[0] svg_data = Selector(svg_content) # 获取svg文件 text元素的y属性列表 svg_y_list = svg_data.xpath('//text/@y').getall() # 取到大于css_y且最近的一个 new_svg_y_list = [svg_y for svg_y in svg_y_list if css_y <= int(svg_y)] # print(new_svg_y_list[0]) # 获取目标svg_y在原svg_y_list中的下标 index = svg_y_list.index(new_svg_y_list[0]) # print(svg_data.xpath('//text/text()').getall()) text_content = svg_data.xpath('//text/text()').getall()[index] return text_content, font_size def get_char(text_content, css_x, font_size): text_chars = list(text_content) # 利用x轴的坐标确定是第几个元素 n = css_x // int(font_size) print(text_chars[n]) return text_chars[n] def get_phone(): result = '' svg_url = 'http://www.porters.vip/confusion/font/food.svg' css_url = 'http://www.porters.vip/confusion/css/food.css' css_content = get_file(css_url) svg_content = get_file(svg_url) # 获取源码中电话号的SVG列表 svg_list = ['vhkbvu', 'vhk08k', 'vhk08k', 'vhk84t', 'vhk6zl', 'vhkqsc', 'vhkqsc', 'vhk6zl'] for svg_name in svg_list: coordinate = get_css_coordinates(css_content, svg_name) if coordinate is not None: css_x, css_y = coordinate print(css_x, css_y) text_content, font_size = get_svg_text_content(svg_content, css_y) num = get_char(text_content, css_x, font_size) result += num print(result) if __name__ == '__main__': get_phone()
最后说明:此案例只是我在学习《Python3反爬虫原理与绕过实战》里面svg反爬的学习心得以及实践,供参考,不喜勿喷

