
OS之内存管理 --- 虚拟内存管理(一)
虚拟内存的背景
在基本的内存管理策略中,所有的策略的相同点都是:每个进程在执行之前需要完全处于内存中。那有没有一种方法可以不需要将进程所有页面加载到内存中就可以开始运行进程呢?有没有可能在进程需要某些页面时再将其调入进内存中呢?于是就有了虚拟内存技术。
而虚拟内存将用户逻辑内存和物理内存分开,使得编程人员不在担心有限的物理内存空间。
除此之外,虚拟内存允许文件和内存通过共享页而为多个进程共享,这将会有很多好处:
- 通过将共享进程映射到虚拟地址空间中,系统库可以为多个进程所共享。
- 虚拟内存允许一个进程创建一个内存区域,以便与其他进程共享,共享这个内存区域的进程认为:它是其虚拟地址空间的一部分,而事实这部分是共享的。
- 当通过系统调用fork()创建进程时,可以共享页面,从而加快进程创建。
请求调页
在程序执行时,仅在程序需要时才加载页面,这种技术称为请求调页。对于请求调页的虚拟内存,页面只有在程序执行期间被请求时才被加载,那些从未访问的页面从不加载到物理内存中。
当程序执行时,他被交换到内存中,但是不是将整个进程交换到内存中,而是采用惰性交换器。惰性交换器除非需要某个页面,否则从不将他交换到内存中。
基本概念
当换入进程时,调页程序会猜测该进程被再次换出之前会用到哪些页,调页程序不是调入整个进程,而是把那些要使用的页调入内存,这样调页程序就避免读入那些不使用的页,也减少了交换时间和所需的物理内存空间。这中方法需要硬件的支持,以区分内存的页面和磁盘的页面。可以采用有效-无效位方案用于这一目的。当该位被设置为有效的时候,相关联的页面是合法的,并且存在于内存中;当该位被设置为无效时,页面无效(即不在进程的逻辑地址空间中),或有效但只在磁盘上。
如果进程试图访问标记为无效的页面时,对标记为无效的页面访问会产生缺页错误。分页硬件在通过页表转换地址时会注意到无效位被设置,从而陷入操作系统,处理缺页错误的流程大致如下:
- 检查这个进程的内部表,通常和PCB一起保存,以确定该引用是有效的还是无效的内存访问。
- 如果引用无效,那么终止进程,如果引用有效但是尚未调入内存,那么现在就应该调用。
- 找到一个空闲帧
- 调入一个磁盘操作,以将所需页面读到刚分配的帧。
- 当磁盘读取完成时,修改进程的内部表和页表,以指示该页现在处于内存中。
- 重新启动被陷阱中断的指令。该进程现在能访问所需的页面。
极端情况下,直接执行一个没有内存页面的进程,这种方案称为纯请求调页。
请求调页的性能
我们需要计算请求调页内存的有效访问时间。对于没有出现缺页错误,有效访问时间就等于内存访问时间,如果出现缺页错误,那么就应该先从磁盘中读入相关的页面,在进行访问所需要的字。
设p为缺页错误的概率(0 p 1),内存访问时间为m,则有效访问时间为:
有效访问时间=(1-p) * m + p * 缺页错误时间
如果发生缺页错误,那么大致流程如下:
- 陷入操作系统
- 保存用户寄存器和进程状态
- 确定中断是否为缺页错误
- 检查页面引用是否合法,并确定页面的磁盘位置
- 从磁盘读入页面到空闲帧
a. 在该磁盘队列中等待,直到读请求被处理
b. 等待磁盘的寻道或延迟时间
c. 开始传世磁盘页面到空闲帧 - 在等待时,将CPU分配给其他用户(CPU调度,可选)
- 收到来自I/O子系统的中断(I/O完成)
- 保存其他用户的寄存器和进程状态(如果执行了第6步)
- 确认中断是来自上述磁盘的
- 修正页表和其他表,以表示所需的页面现在已经在内存中。
- 等待CPU再次分配到本进程
- 恢复用户寄存器、进程状态和新页表,再次中心执行中断的指令。
总结下来,缺页错误的处理时间有三个主要组成部分:
- 处理缺页错误中断
- 读入页面
- 重新启动进程
写时复制
当一个父进程通过fork()创建一个子进程的时候,fork()方法将会为子进程创建一个父进程地址空间的副本,并且复制属于父进程的页面。但是通常子进程在创建之后会立即调用exec(),父进程地址空间的复制没有必要。这时候我们可以通过写时复制的技术,允许父进程和子进程最初共享相同的页面来工作,这些共享页面标记为写时复制,如果任何一个进程写入共享页面,那么就创建共享页面的副本。
这里需要注意:只有可以修改的页面才需要标记为写时复制,不能修改的页面可以由父进程和子进程共享。
当采用写时复制复制来复制页面时,重要的是注意空闲页面的分配位置。通常情况下,OS为这类请求提供了一个空闲的页面池。操作系统分配这些页面通常采用按需填零的技术,按需填零页面在分配之前先填零,因此清除了以前的内容。
UNIX的多个版本提供了fork()的变种,即vfork()(虚拟内存fork),vfork()不同于写时复制的fork()。父进程被挂起,子进程使用父进程的地址空间,所以vfork()不采用写时复制。
页面置换
为了实现请求调页,需要解决两个问题:帧分配算法和页面置换算法。如果有多个进程在内存中,则必须决定要为每个进程分配多少帧;并且当需要页面置换时,必须要选择置换的帧。
基本的页面置换
如果没有空闲帧,那么就查找当前不在使用的一个帧,并释放它:将其内容写到交换空间,并修改页表,以表示该页不在内存中。现在可以使用空闲帧,来保存进程出错的页面,大致的流程如下:
- 找到所需页面的磁盘位置
- 找到一个空闲帧
a. 如果有空闲帧,那么使用它
b. 如果没有空闲帧,那么就使用页面置换算法来选择一个牺牲帧
c. 将牺牲帧的内容写到磁盘上,修改对应的页表和帧表 - 将所需页面读入(新的)空闲帧,修改页表和帧表
- 将发生缺页错误位置,继续用户进程
如果没有空闲帧,那么需要两个页面传输(一个调入,一个调出)。增加了缺页错误的处理时间和有效访问时间,可以采用修改位(或脏位)减少这种开销。当使用这种方法时,需要为每个页面或帧设置一个修改位,每当页面的任何字节被写入时,它的页面修改位会由硬件来设置,以表示该页面已被修改过。当选择一个页面进行置换时,检查它的修改位,如果该位已被设置,应将页面写入磁盘。如果修改为没有被设置,那么就不需要将内存页面写到磁盘。
FIFO页面置换
FIFO页面置换算法为每个页面记录了调到内存的时间,当必须置换页面时,选择最旧的页面。可以创建一个FIFO队列,来管理所有的内存页面。置换的是队列的首个页面,当需要调入页面到内存时,就将它加到队列的尾部。
| 引用串 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 帧一 | 7 | 0 | 7 | 2 | 2 | 2 | 4 | 4 | 4 | 0 | 0 | 0 | 7 | 7 | 7 | |||||
| 帧二 | 0 | 0 | 0 | 3 | 3 | 3 | 2 | 2 | 2 | 1 | 1 | 1 | 0 | 0 | ||||||
| 帧三 | 1 | 1 | 1 | 0 | 0 | 0 | 3 | 3 | 3 | 2 | 2 | 2 | 1 |
注意:FIFO置换算可能导致Belady异常。
最优页面置换
该算法具有所有算法的最低的缺页错误率,并且不会遭受到belady异常。该算法在进行置换页面时会置换最长时间不会使用的页面。
| 引用串 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 帧一 | 7 | 0 | 7 | 2 | 2 | 2 | 2 | 2 | 7 | |||||||||||
| 帧二 | 0 | 0 | 0 | 0 | 4 | 0 | 0 | 0 | ||||||||||||
| 帧三 | 1 | 1 | 3 | 3 | 3 | 1 | 1 |
但是最优置换算法需要引用串的未来进行判定,所以难以实现。
LRU页面置换
使用最近的过去作为不远将来的近似,那么可以将置换时间最长没有使用的页。这种方法称为最近最少使用算法。LRU置换将每个页面与它上次使用的时间关联起来,当需要置换页面的时候,LRU选择最长时间没有使用的页面。
| 引用串 | 7 | 0 | 1 | 2 | 0 | 3 | 0 | 4 | 2 | 3 | 0 | 3 | 2 | 1 | 2 | 0 | 1 | 7 | 0 | 1 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 帧一 | 7 | 0 | 7 | 2 | 2 | 4 | 4 | 4 | 0 | 1 | 1 | 1 | ||||||||
| 帧二 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 3 | 3 | 0 | 0 | |||||||||
| 帧三 | 1 | 1 | 3 | 3 | 2 | 2 | 2 | 2 | 2 | 7 |
LRU置换算法的一个主要问题是:如何确定由上次使用时间定义的帧的顺序?
计数器
为每个页表条目关联一个使用时间域,并为CP添加一个逻辑时钟或计数器。每次内存引用都会递增时钟。每当进行时间引用时,时钟寄存器的内容会复制到相应的页面的页表条目的使用时间域。这样总是有每个页面的最后引用的时间,在置换时置换具有最小时间的页面。
堆栈
采用页码堆栈,每当页面被引用时,就从堆栈中移除并放在顶部,这样最近使用的页面总是在堆栈的顶部,最近最少使用的页面总是在堆栈的底部。因为需要从堆栈中间删除条目,所以可以采用具有首指针和尾指针的双向链表来实现。
LRU置换和最优置换算法属于同一类算法,称为堆栈算法,绝不可能有Belady异常。证明:帧数为n的内存页面集合是帧数n+1的内存页面集合的子集。对于LRU置换,内存中的页面集合为最近引用的n个页面,如果帧数增加,那么这n个页面依旧是最近被引用的,因此仍然在内存中。
近似LRU页面置换
很少有计算机系统能够提供足够的硬件来支持真正的LRU算法,但是很多系统都通过引用位的形式提供一定的支持。每当引用一个页面时,它的页面引用位就被硬件置位。页表内的每个条目都关联一个引用位
额外引用位算法
为内存中的页表的每个页面保留一个8位的字节,定时器中断定期的将控制传到操作系统,操作系统将每个页面引用位移到其8位字节的高位,将其他位右移一位,并丢弃最低位。这些8位移位寄存器包含着最近8个时间周期内的页面使用情况。将这些8位字节即视为无符号整数,那么具有最小编号的页面是LRU替换页面。
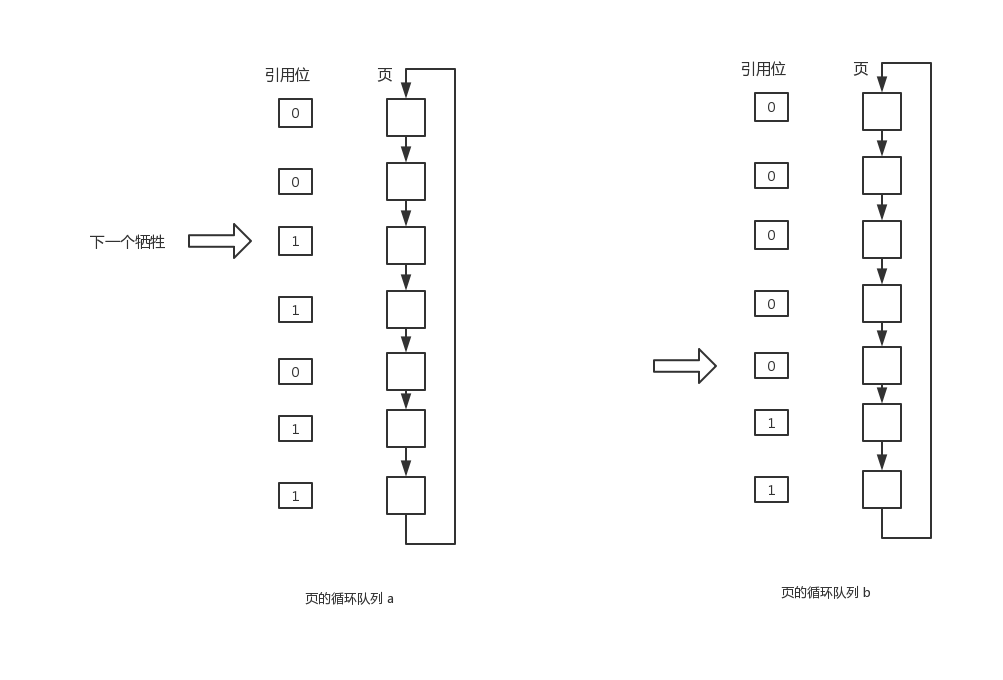
第二次机会算法
在极端情况下,引用位的位数可以降至0,即只有引用位本身,这种算法就是第二次机会算法。是一种FIFO置换算法。
当选择了一个页面时,需要检查其引用位,如果值为0,那么就直接置换该页面;如果引用位为1,那么就给此页面第二次机会,并继续选择下一个页面。当一个页面获得第二次机会时,其引用位被清除,并且到达时间被设为当前时间。因此获得第二次机会的页面在所有其他页面被置换前不会被置换。
实现第二次机会算法的一种方式是采用循环队列:
增强型第二次机会算法
通过将引用位和修改位作为有序对,可改进第二次机会算法,存在四种可能的类型:
- (0, 0)最近没有使用且没有修改的页面,最佳的页面置换
- (0, 1)最近没哟使用但修改过的页面,在置换前需将页面写出
- (1, 0)最近使用过但没有修改的页面,可能很快再次使用
- (1, 1)最近使用过且修改过,可能很快再次使用且在置换前需将页面写出
为已修改的页面赋予更高级别,从而降低了所需的I/O数量。
基于计数的页面置换
可以为每个页面的引用次数保存一个计数器,基于计数的算法如下:
- 最不经常使用(LFU)页面置换算法
要求置换具有最小计数的页面。这种选择的原因是积极使用的页面应当具有大的引用计数。但是当一个页面在进程的初始阶段大量使用但是随后不在使用时会出现问题。由于被大量使用具有一个大的计数,即使不再需要却仍然保存在内存中。一种解决方法是:定期将计数右移1位,以形成指数衰减的平均使用计数。 - 最经常使用(MFU)页面置换算法
基于论点:具有最小计数的页面可能刚刚被引入并且尚未使用。
LFU和MFU置换不常用,这些算法的实现是昂贵的且不能很好的近似OPT(最优置换算法)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号