
桶排序和计数排序的理解实现和比较(Java)
比较和非比较的区别
常见的快速排序、归并排序、堆排序、冒泡排序等属于比较排序。在排序的最终结果里,元素之间的次序依赖于它们之间的比较。每个数都必须和其他数进行比较,才能确定自己的位置。比较排序的优势是,适用于各种规模的数据,也不在乎数据的分布,都能进行排序。
计数排序、基数排序、桶排序则属于非比较排序,通过确定每个元素之前,应该有多少个元素来排序。针对数组arr,计算arr[i]之前有多少个元素,则唯一确定了arr[i]在排序后数组中的位置。非比较排序只要确定每个元素之前的已有的元素个数即可,所有一次遍历即可解决。算法时间复杂度O(n)。非比较排序时间复杂度底,但由于非比较排序需要占用空间来确定唯一位置。所以对数据规模和数据分布有一定的要求。
桶排序
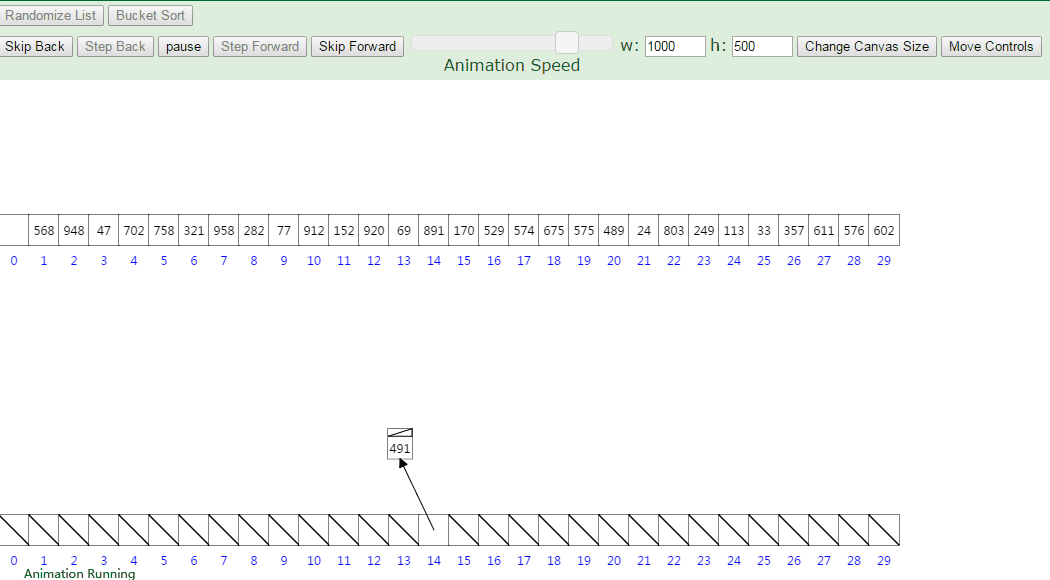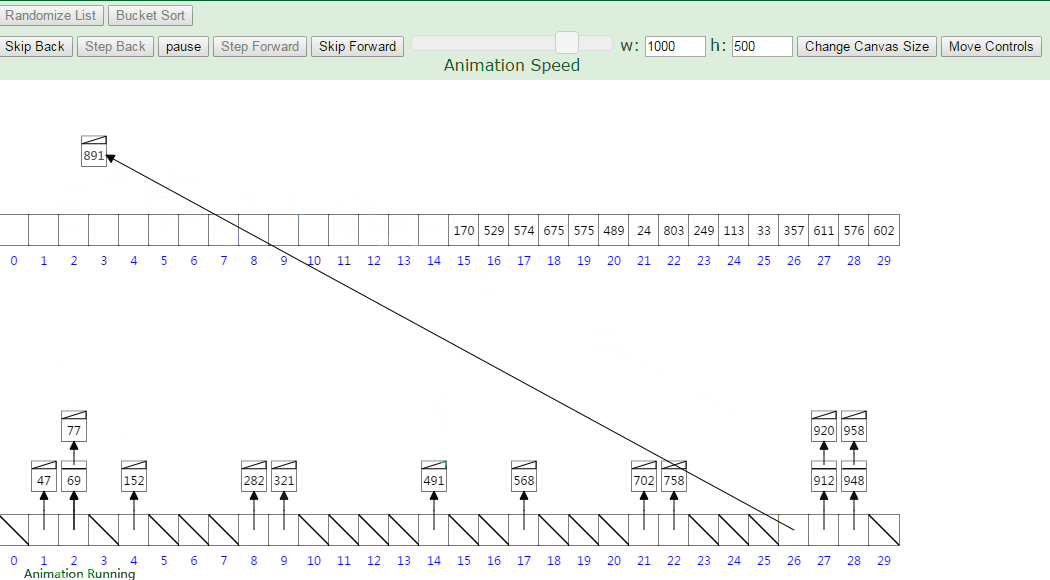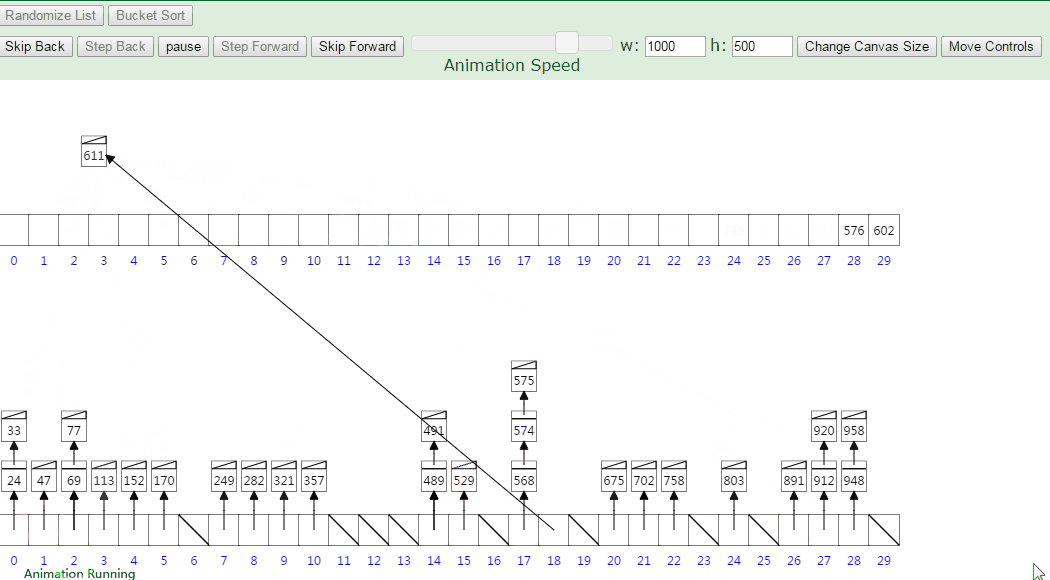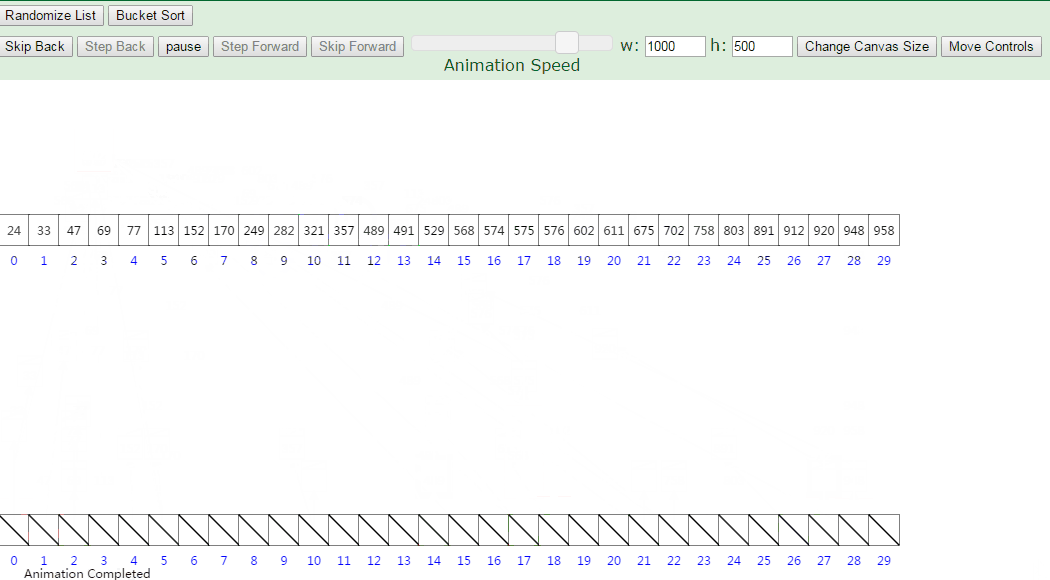
桶排序又称为箱排序,原理是将数组分到有限数量的桶里。每个桶再个别排序,最后依次把各个桶中的记录列出来记得到有序序列。
当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间(O(n))。
基本思想
桶排序假设待排序的一组数均匀独立的分布在一个范围中,并将这一范围划分成几个子范围(桶)。然后基于某种映射函数f ,将待排序列的关键字 k 映射到第i个桶中 (即桶数组B 的下标i) ,那么该关键字k 就作为 B[i]中的元素 (每个桶B[i]都是一组大小为N/M 的序列 )。接着将各个桶中的数据有序的合并起来。
桶排序适用数据范围
桶排序可用于最大最小值相差较大的数据情况。但桶排序要求数据的分布必须均匀,否则可能导致数据都集中到一个桶中。比如[104,150,123,132,20000], 这种数据会导致前4个数都集中到同一个桶中。导致桶排序失效。
代码实现
public void bucket_sort(int[] elem) {
int min = Integer.MAX_VALUE;
int max = Integer.MIN_VALUE;
for (int i = 0; i < elem.length; i++) {
max = Math.max(max, elem[i]);
min = Math.min(min, elem[i]);
}
int bucketNum = (max - min) / elem.length + 1;
ArrayList<ArrayList<Integer>> buckets = new ArrayList<ArrayList<Integer>>(bucketNum);
for (int i = 0; i < bucketNum; i++) {
buckets.add(new ArrayList<Integer>());
}
for (int i = 0; i < elem.length; i++) {
int num = (elem[i] - min) / elem.length;
buckets.get(num).add(elem[i]);
}
for (int i = 0; i < buckets.size(); i++) {
Collections.sort(buckets.get(i));
}
for (int i = 0, j = 0; i < buckets.size(); i++) {
if(!buckets.get(i).isEmpty()) {
for (int j2 = 0; j2 < buckets.get(i).size(); j2++) {
elem[j++] = buckets.get(i).get(j2);
}
}
}
}
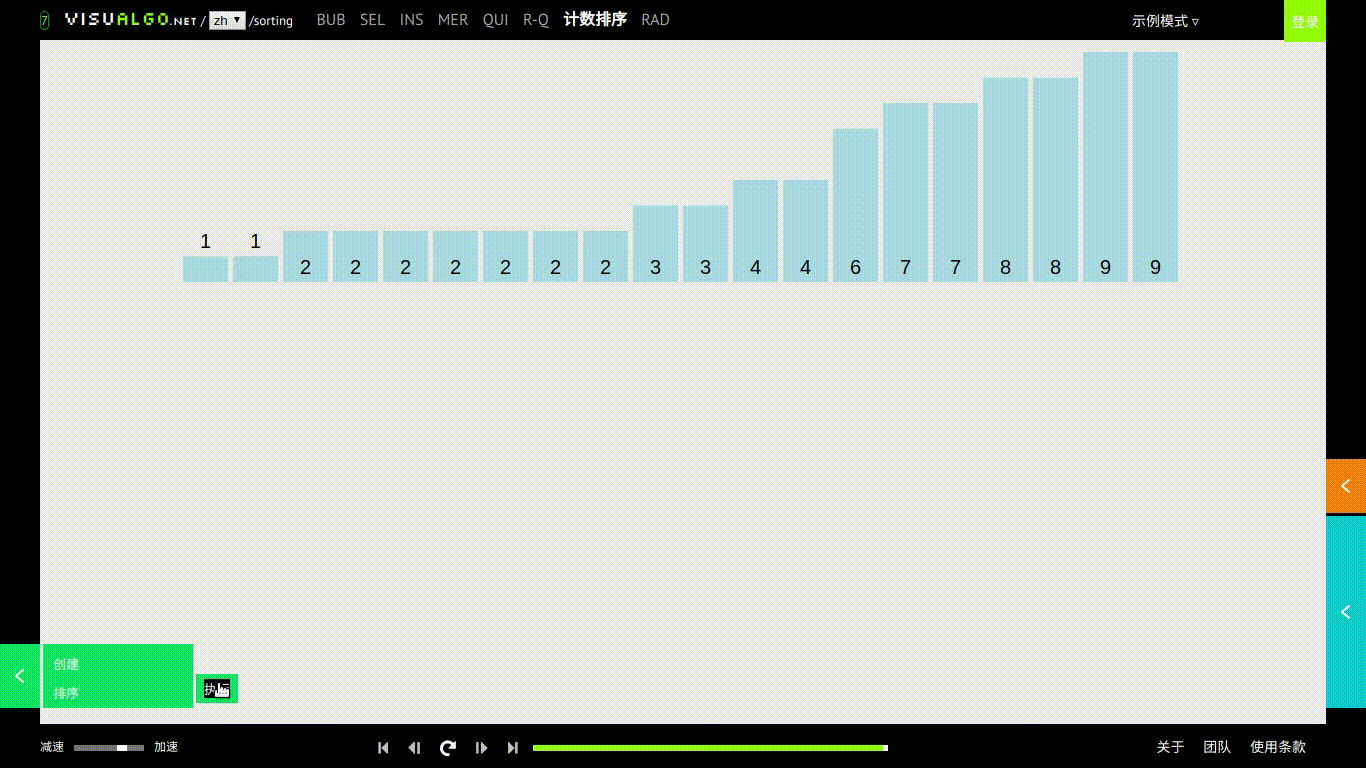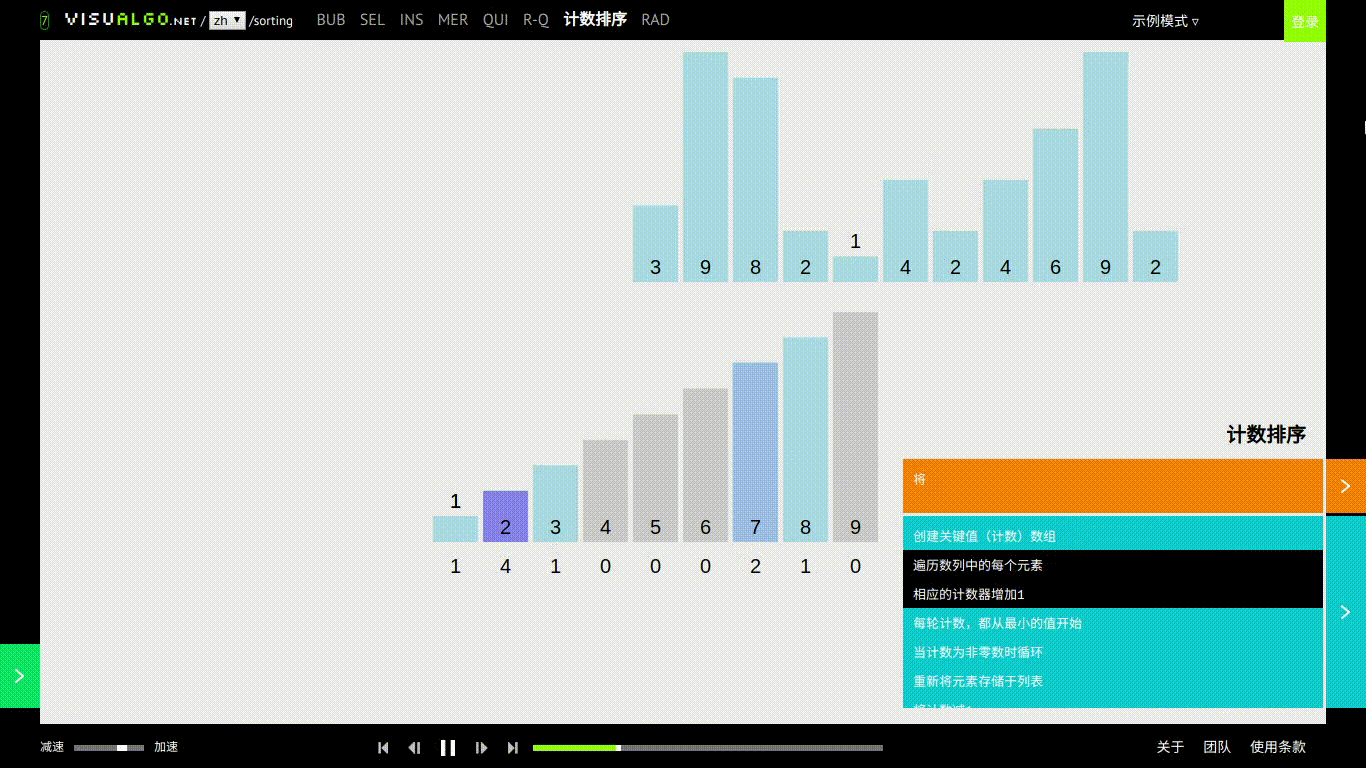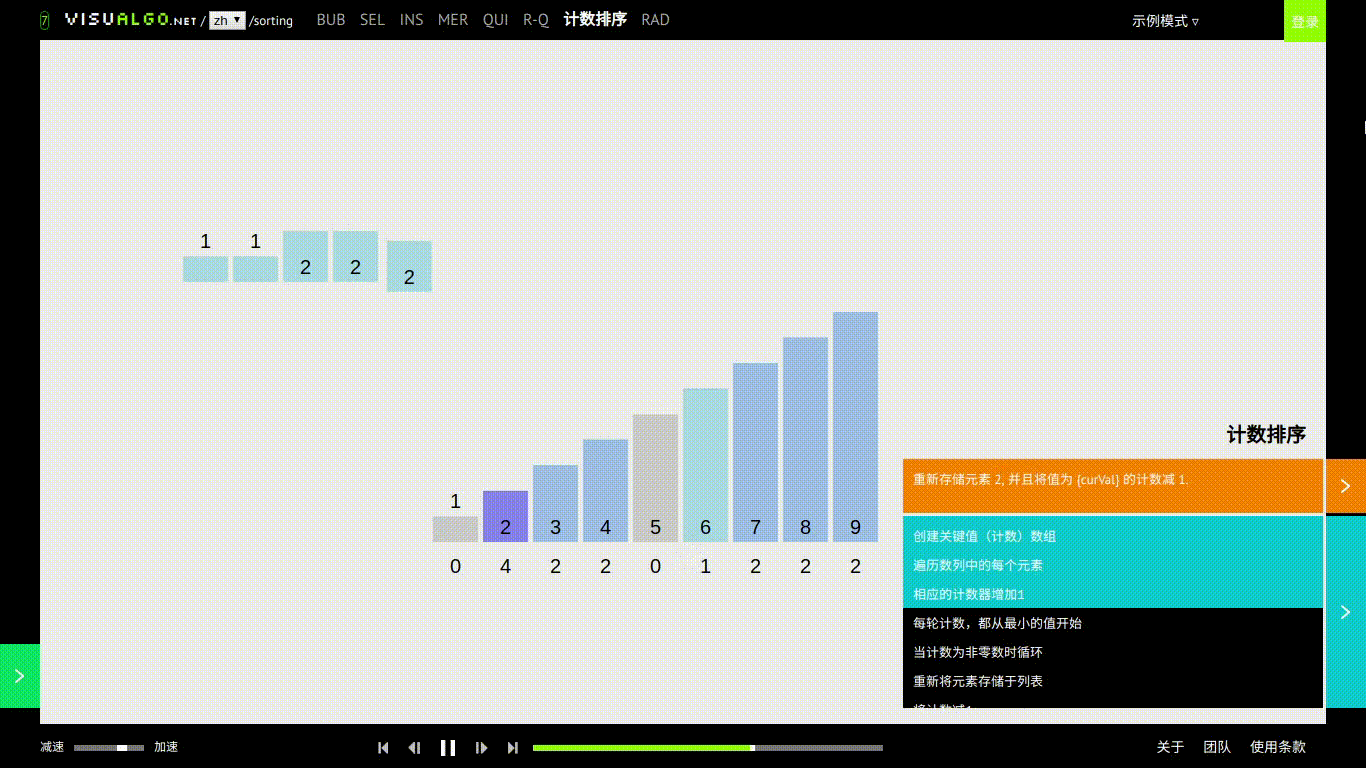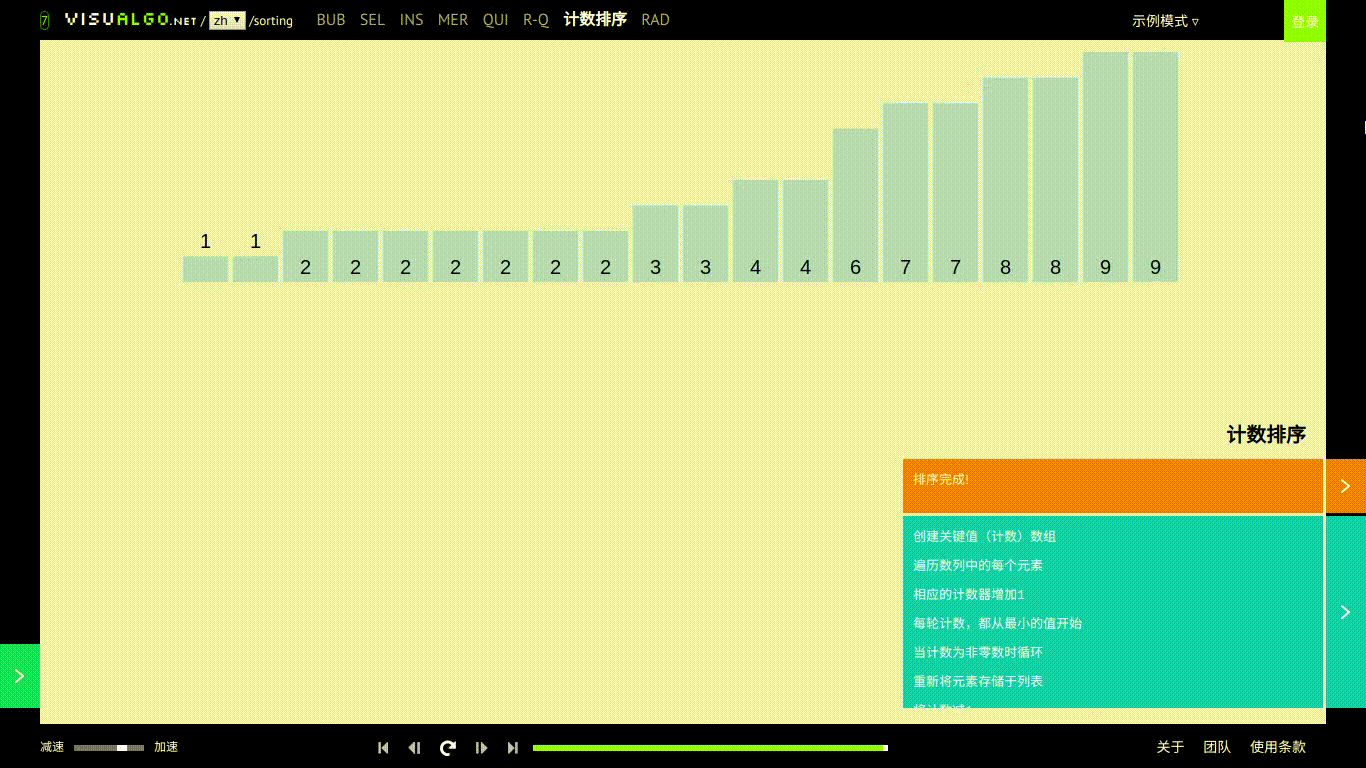
计数排序
基本思想
计数排序对每一个输入的元素elem[i],确定小于 elem[i] 的元素个数。也就是说需要有一个大于待排序数组最大值长度的数组,然后直接把 elem[i] 放到它输出数组中的位置上对于每个待排序的元素数据都有自己用来记录自己的个数。
代码实现
public void bucket_sort(int[] elem, int length, int max) {
int[] bucket = new int[max];
for (int i = 0; i < length; i++) {
bucket[elem[i]]++;
}
for (int i = 0, j = 0; i < max; i++) {
while((bucket[i]--) > 0) {
elem[j++] = i;
}
}
bucket = null;
}

