粗粒度可重构架构
CGRA介绍
粗粒度可重构架构 (CGRA) 是一种替代硬件平台,相比FPGA细粒度的可重构架构,由于CGRA内部的IS(ALU)模块已经构建完成(IssueSlot+RegistryFile+MUX构成的组合结构),且CGRA的interconnect也要比FPGA更简单、规模更小,其延时和性能要显著好于在门级上进行互连形成组合计算逻辑的FPGA,因此我们常讲CGRA更适合word-wise类型(32bit为单位)的可重构计算,而且可以缓解 FPGA 存在的时序、面积和功率开销问题,并有望用于未来的 高性能计算系统(HPC)。CGRA通常具有处理单元(PE)阵列以及PE之间的互连网络。每个PE由简单的算术逻辑单元(ALU)、多路复用器和小型本地存储(例如寄存器文件RF或FIFO缓冲区)组成。多路复用器从邻居 PE 发送的传入数据中选择进入 ALU 的操作数。PE阵列可以通过优化ALU的指令映射和互连来形成目标计算内核的专用流水线。
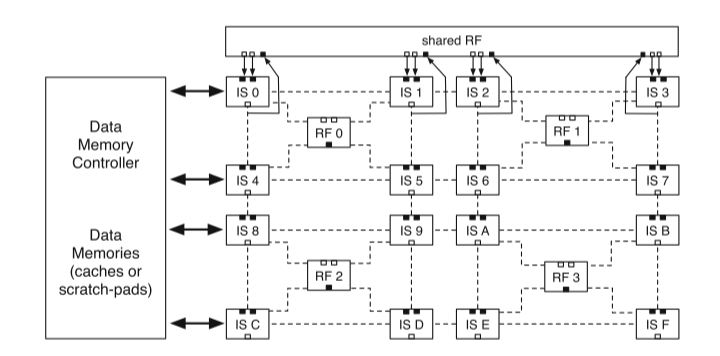
ADRES架构
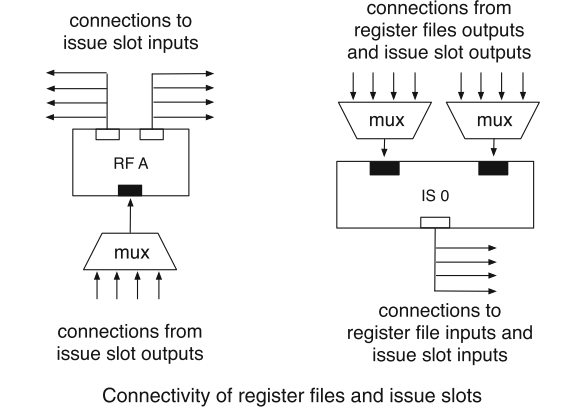
在这方面,CGRA的可重构性粒度被计为word level,即ALU的位宽,如32位和64位。它比 FPGA 粗糙得多。此外,较粗的粒度降低了编译过程的复杂性,配置信息相比FPGA更少,因此可以支持动态可重构,,而FPGA属于静态可重构,从这个角度而言,编译器也可以在CGRA上应用更良好的优化。
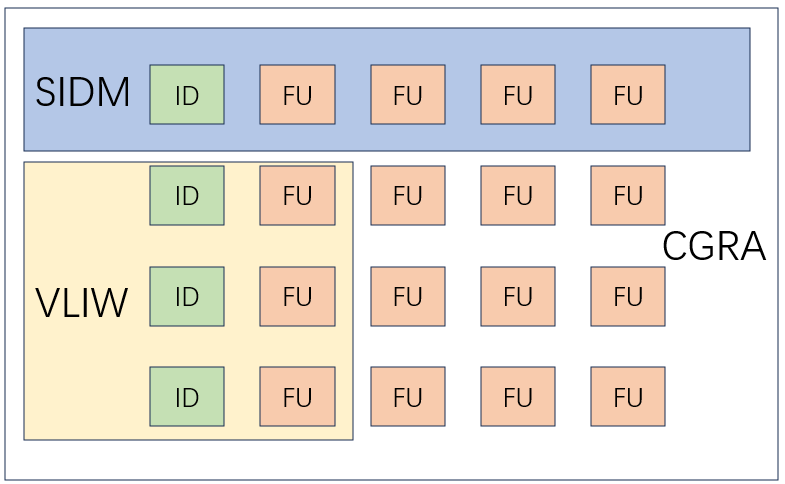
从另一个种角度来看,可以看出当一个ID模块与多个FU模块相连时,CGRA此时相当于一个SIMD处理器;当多个ID与多个FU相连时,CGRA相当于一个VLIW处理器,CGRA也可以看作是VLIW在2D上的一种扩展,下图所示。
通用CGRA运行的应用程序通常以循环为主,一般与其他核心共同完成相应任务,如下图所示,MorphoSys CGRA和TinyRISC共同组成一个处理系统来完成相应的复杂任务,其中CGRA复杂任务中的循环部分,而其他核心如TinyRISC复杂任务中的其他部分,因此这种方式可以比 CPU 更快、更节能地执行循环和加速,同时从上图来看,CGRA可以在循环中更好的利用数据级和指令级并行性。
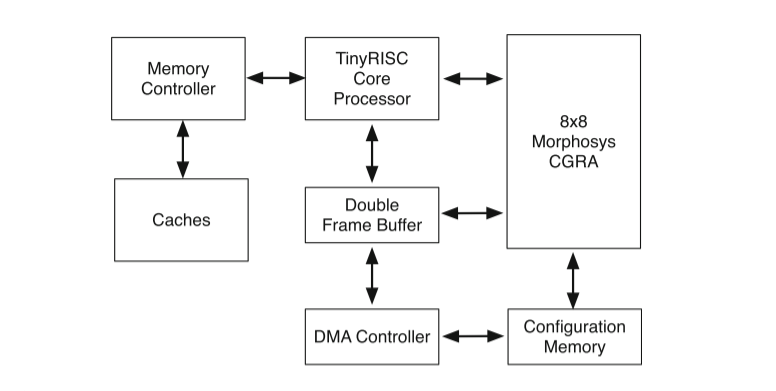
A TinyRISC main processor loosely coupled to a MorphoSys CGRA array.
CGRA 根据其重新配置策略分为两类:1)空间配置的 CGRA 和 2)具有时间复用配置的 CGRA。前一种类型的 CGRA 在可重新配置的结构上形成完全管道化的数据流,并在运行时保持配置。它在计算吞吐量和重新配置开销方面具有优势,但常常面临硬件资源耗尽的问题。
后一类中的 CGRA 在重复更改配置的同时执行循环内核。他们通常以软件管道的方式同时处理多个迭代,来提高吞吐率。
通用CGRA编译流程
CGRA 的编译流程通常分为两个步骤:1)从应用程序代码中提取数据流;2)将数据流映射到 PE 阵列中。提取的数据流表示为数据流图(DFG)或控制数据流图(CDFG),并将其传递到下一步。
第一个任务是从代码中提取计算密集型内核并生成与目标 CGRA 兼容的 DFG。它被视为编译流程的前端。然后,将提取的DFG映射到PE阵列,下一步生成映射结果对应的配置文件。此过程强烈依赖于目标 CGRA,并被视为后端。
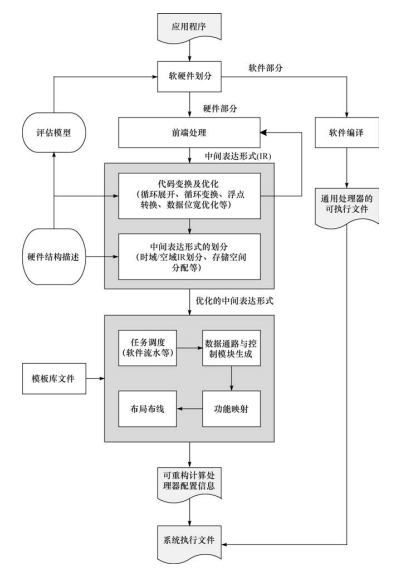
通用可重构处理器编译流程
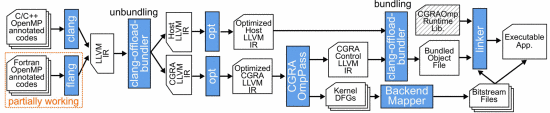
支持OpenMP的CGRA编译流程
现有的 CGRA 编译器是基于自己的编程模型开发的,或者是专门针对某个 CGRA 的。上图所显示的是支持OpenMP的CGRA编译流程,这项研究声称提出一种独立于特定 CGRA 并面向任何 CGRA 的新编译器框架。编译采取 OpenMP offloading,这是一种标准的异构编程模型。得益于这样的标准模型,只需有限的努力即可重用 HPC 工作负载的现有源代码,因为许多源代码是用 C/C++ 或 Fortran 编写的,而 OpenMP 支持这些源代码。此外,一些 HPC 基准测试已经使用 OpenMP 实现。这项工作声称是 CGRA 在 C 语言之外使用 OpenMP 作为编程模型并使用 Fortran 作为前端语言的首次尝试。



