Kubernetes Service 类型介绍与对应使用场景
Kubernetes Service 类型介绍与对应使用场景
原文链接:https://www.modb.pro/db/173697
注⚠️:本人记录仅为谨防优质内容迁移或丢失,
今天给大家分享下 Kubernetes Service,文章内容也在鹅厂团队内部分享过,有理解不对的地方,欢迎大家留言指正。文章内容较长,看完预计需要15分钟。
之前我对 Kubernetes Service 只了解其基本用法。这次为了在内部做分享,整体了解了一遍,确实是学到了更多。希望大家看了这篇分享,也能了解更多。
本文主要分为两部分:
- Kubernetes Service 简介
- Kubernetes Service 不同类型与其应用场景的介绍
Kubernetes Service 简介
Kubernetes Service 是什么?
来自官方的解释是:将运行在一组 Pods 上的应用程序公开为网络服务的抽象方法。看完这句话,只能感慨确实是挺抽象的。那我们用一张图来解释下 Kubernetes Service:
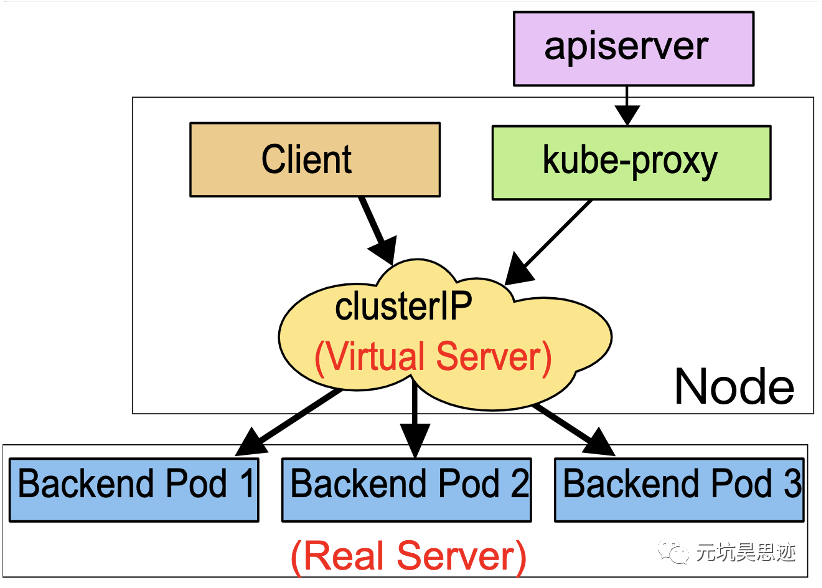
图1 Kubernetes Service 概念图(图片来源于官网)
从图中可以看出,Kubernetes Service 其实充当了一个 VIP 的角色。当 Client 端想要访问 k8s 集群中某个服务时,可以直接访问 Service 的 ClusterIP,Service 会将请求负载均衡到后端的实际服务(图中的 Real Server)上。图中的 kube-proxy,我们稍后再解释它的作用。
让我们先来看下 Kubernetes Service 具体有什么用?
一般,在 k8s 集群内,如果没有 service,我们只能通过 pod ip 进行服务间的访问。如下图所示:
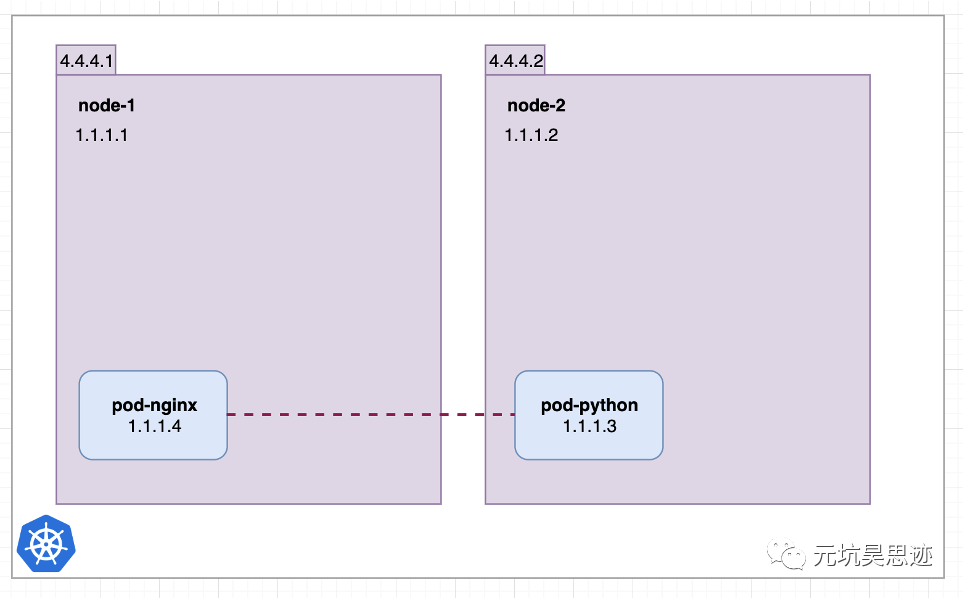
图2 通过 pod ip 进行服务访问(图片来源于参考文章)
从图中可以看到,nginx pod 想要访问 python pod,可以通过 pod ip:1.1.1.3 进行访问。但有个问题是当 pod 挂掉重建时,pod ip 是会变的。如下图所示:
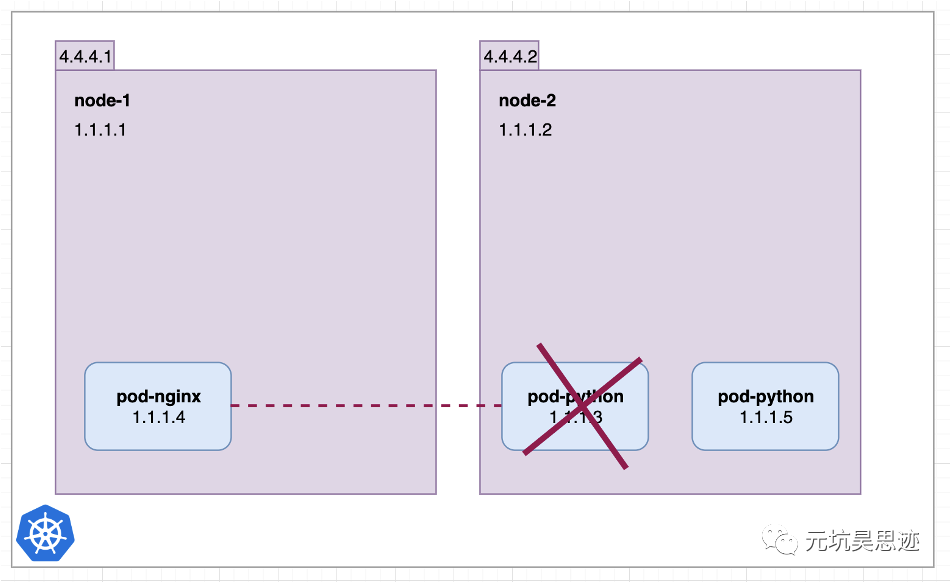
图3 pod ip是会变的(图片来源于参考文章)
从图中可以看出,当 python pod 重建后,ip 变成了 1.1.1.5,这时候 nginx pod 配置的还是 1.1.1.3,直接就访问不通了。这时候就体现了 Service 的作用了,如下图所示:
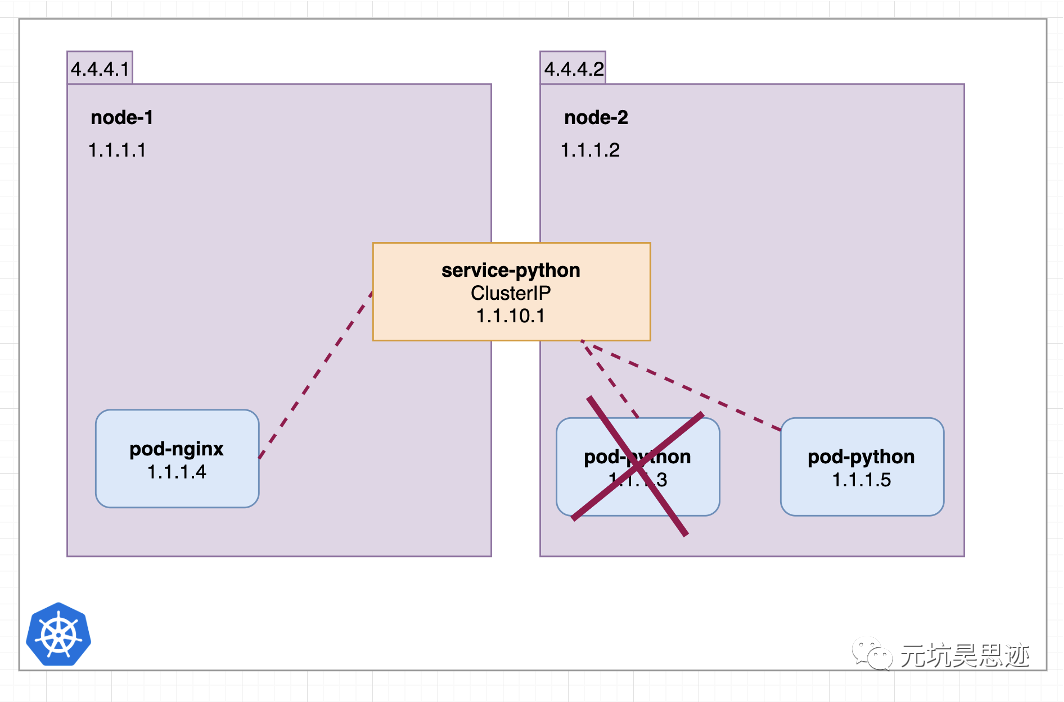
图4 通过 service ip 访问服务(图片来源于参考文章)
从图中可以看出 ,nginx pod 可以通过 python service 来访问实际的 python pod,当 pod 发生重建后,service 的 ClusterIP 是不变的。这样 nginx pod 还是能够正常访问到重建后的 python pod。
那 service 要怎么与 pod 关联起来呢?我们来看个示例,如下图所示:
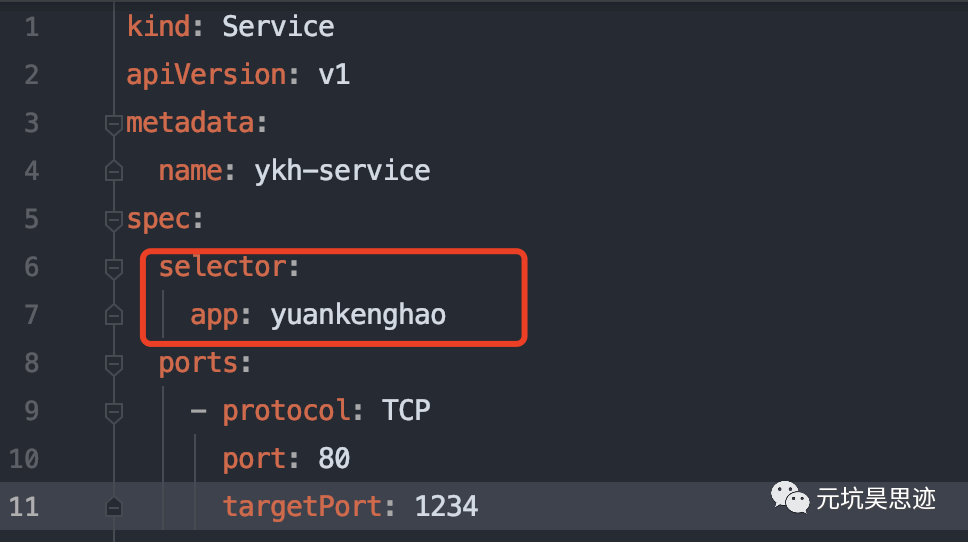
图5 service label selector
service 其实是通过 label 选择器进行 pod 关联的,在创建 service 的时候,需要设置好 label selector。图中设置的是 app:yuankenghao。再看看 pod 要怎么定义,如下图所示:
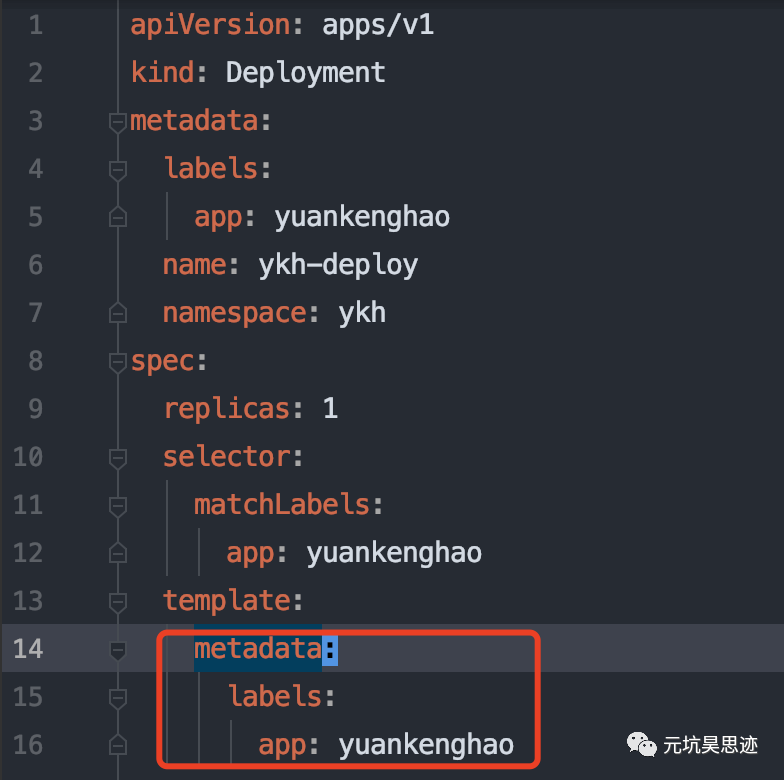
图6 pod 的 label 定义
从图中可以看出,ykh-deploy 是通过 deployment 来定义的 pod,在 pod template 的定义中增加了 label 的定义,即 app:yuankenghao,这样通过 deployment 创建的所有 pod 都会带上 app:yuankenghao 这个 label。最终,pod 上声明的 label 就与 service 上声明的 label 选择器对应起来了,这样通过 service 就可以将请求负载均衡到实际的 pod 上。
接下来我们看看,service 通过 label 关联 pod 后,是怎么将请求转发到 pod 上的。
这里就要介绍下 kube-proxy 了。如下图所示,service 是通过 iptables 规则将请求转发到 pod 上的。而 kube-proxy 的作用就在于管理所有 service 对应的 iptables 规则。kube-proxy 会监听 apiserver 上 service 的生命周期,从而对物理机上的 iptables 规则做对应的修改。
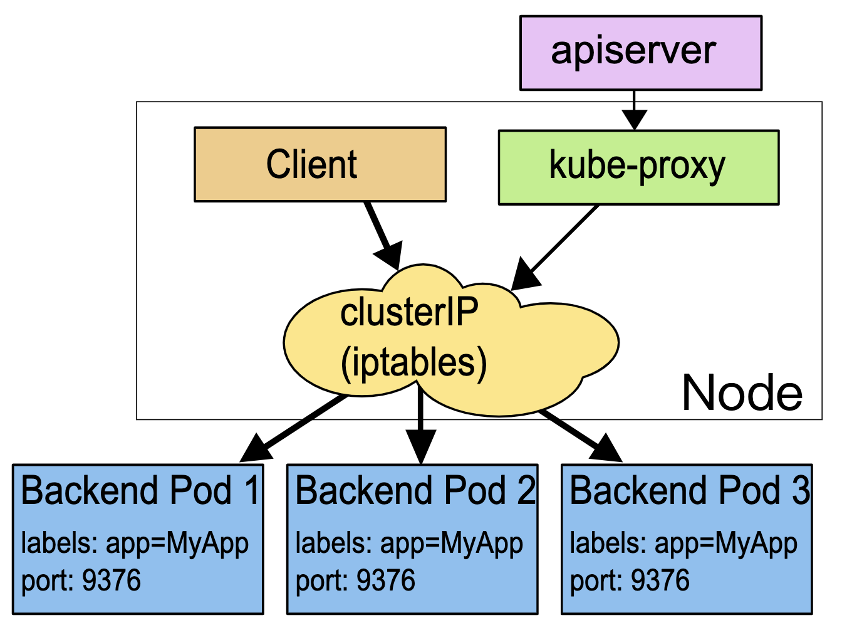
图7 service 通过 iptables 转发请求(图片来源于官网)
我们来看一下具体的 iptables 规则,如下所示:
# kubectl describe svc nginx-web-1
...
Type: ClusterIP
IP: 172.30.132.253
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.129.1.22:80
Session Affinity: None
...
# iptables-save | grep nginx-web-1
-A KUBE-SEP-UWNFTKZFYWNNNTK7 -s 10.129.1.22/32 -m comment --comment "demo/nginx-web-1:" \
-j KUBE-MARK-MASQ
-A KUBE-SEP-UWNFTKZFYWNNNTK7 -p tcp -m comment --comment "demo/nginx-web-1:" \
-m tcp -j DNAT --to-destination 10.129.1.22:80
-A KUBE-SERVICES -d 172.30.132.253/32 -p tcp -m comment \
--comment "demo/nginx-web-1: cluster IP" -m tcp --dport 80 -j KUBE-SVC-SNP24T7IBBNZDJ76
-A KUBE-SVC-SNP24T7IBBNZDJ76 -m comment --comment "demo/nginx-web-1:" \
-j KUBE-SEP-UWNFTKZFYWNNNTK7
以 nginx-web-1 这个 service 来说明,可以看到这个 service 的 ClusterIP 是 172.30.132.253,端口是 80,对应的 Endpoints 只有 1 个 pod,地址为 10.129.1.22:80。
此时,在物理机上,kube-proxy 会根据 service 的配置来生成 iptables 规则。如上所示,可以看到通过 iptable-save 命令过滤的 nginx-web-1 service 的 iptables 规则。
当客户端访问 service 的地址 172.30.132.253:80 时,命中了第三条规则,从而转向了第 4 条规则 KUBE-SVC-SNP24T7IBBNZDJ76。由于实际对应的 pod 只有 1 个,所以全部请求流量都会通过第 4 条规则转发到 KUBE-SEP-UWNFTKZFYWNNNTK7,即第 1、2 条规则。
第 1 条规则的意思是,将数据包跳转到 KUBE-MARK-MASQ,而 KUBE-MARK-MASQ 的作用是将数据包打上 Kubernetes 特有的标签。这个标签的作用是,在 POSTROUTING 时,对于带有标签的数据包进行 SNAT。POSTROUTING 规则如下:
-A KUBE-POSTROUTING -m comment --comment "kubernetes service traffic requiring SNAT" -m mark --mark 0x4000/0x4000 -j MASQUERADE
第 2 条规则的意思是,对数据包进行 DNAT,即将目的地之改写为 10.129.1.22:80。这样,访问 service 的请求就转发到了 pod 上。
至此,对于 service 的简要介绍就到这里。接下来我们具体看看 service 的不同类型以及应用场景。
Kubernetes Service 不同类型与其应用场景的介绍
Kubernetes Service 一共可以设置 4 种类型,外加一种特殊用法,即:
- ClusterIP
- NodePort
- LoadBalancer
- ExternalName
- Headless Service(特殊用法)
其中,ClusterIP、NodePort 和 LoadBalancer 有一定的继承关系,如下图所示:
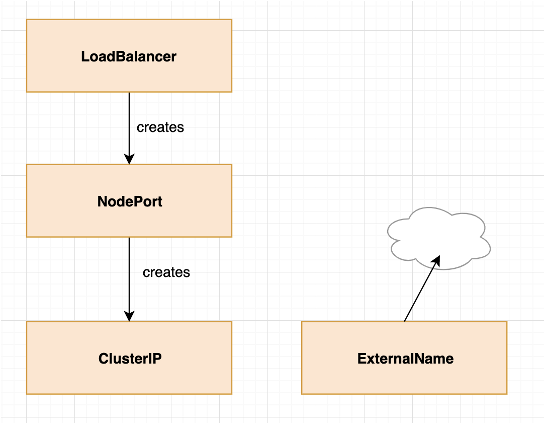
图8 service 的几种类型(图片来源于官网)
这种继承关系的意思是,创建了 NodePort 类型的 service,这个 service 也属于 ClusterIP 类型。具体原因我们讲到对应类型时具体看看。
(1)ClusterIP 类型
ClusterIP 类型是 service 的默认类型,如下图所示:
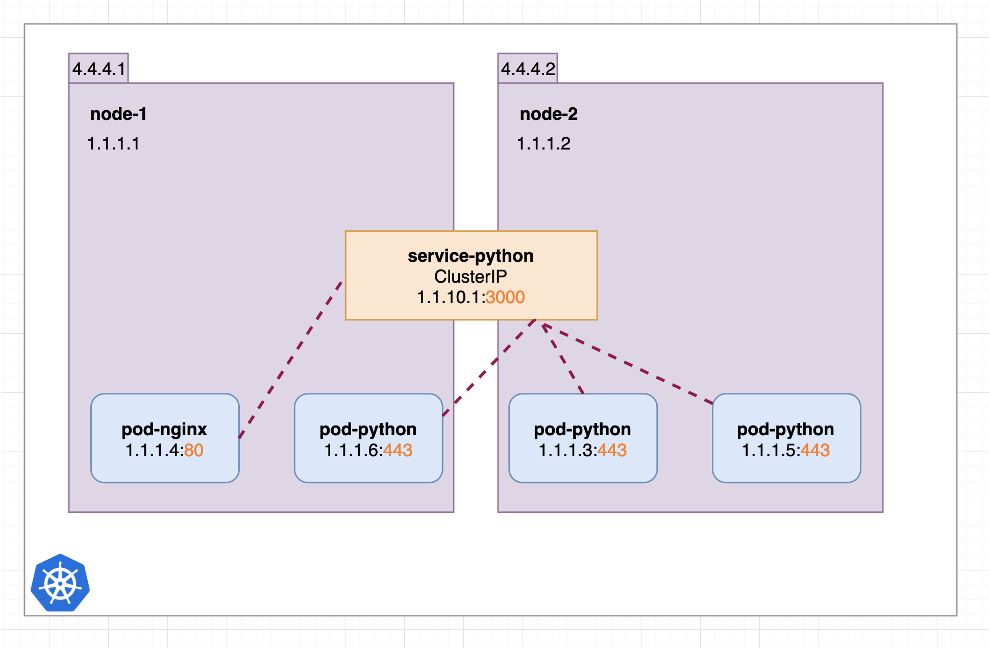
图9 ClusterIP 类型的 service*(图片来源于参考文章)*
默认的 ClusterIP 类型是用的最为普遍的类型,一般在 k8s 集群内部部署的服务,互相之间访问都是通过 ClusterIP 类型的 service。从图中可以看出,service-python 后对应了 3 个 pod,nginx pod 通过 service 的 cluster ip 能够访问到实际的 3 个pod。
ClusterIP 类型的 service yaml 如下图所示,可以看到只要将 type 设定为 ClusterIP 即可:
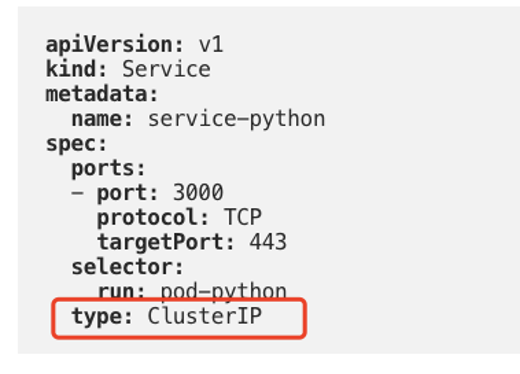
图10 ClusterIP 类型 service 的 yaml 定义*(图片来源于参考文章)*
使用 yaml 创建后,通过命令行能够看到 service 的信息如下:

图11 ClusterIP 类型 service 的命令行信息*(图片来源于参考文章)*
所以,针对于默认的 ClusterIP 类型,其使用场景就是在 k8s 集群内。因为 ClusterIP 只能在集群内被访问。
(2)NodePort 类型
NodePort 类型的 service 主要是为了将集群内的服务暴露到集群外部,如下图所示:
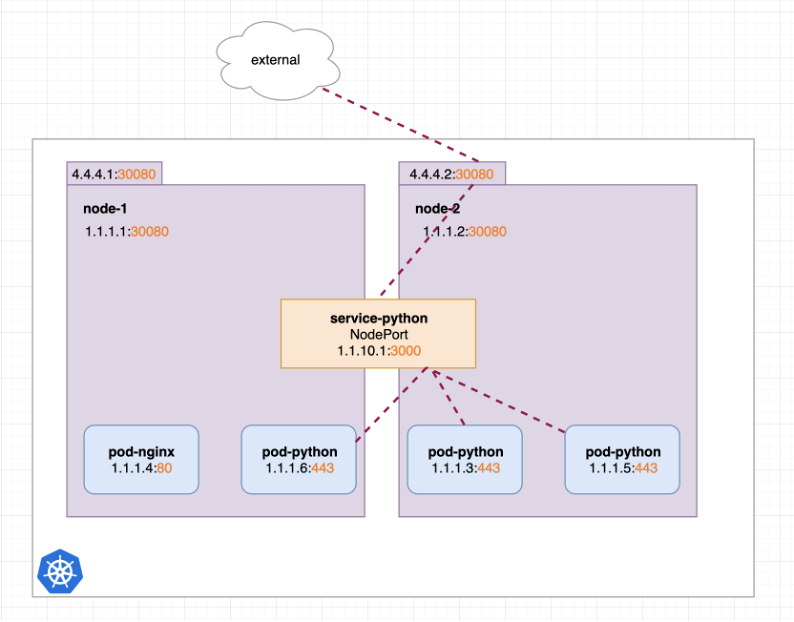
图12 NodePort 类型的 service*(图片来源于参考文章)*
从图中可以看出,NodePort 类型的 service 会在每台物理机上占用一个端口,图中为 30080。这样在集群外部就可以通过 nodeIP:Port 来访问内部的 pod 服务。
NodePort 类型的 service yaml 如下图所示,可以看到跟 ClusterIP 的区别在于 type 设定为 NodePort,并且指定了 nodePort 为 30080。这里如果没有指定 nodePort,则 k8s 会在设定范围默认分配一个没有被占用的 port。
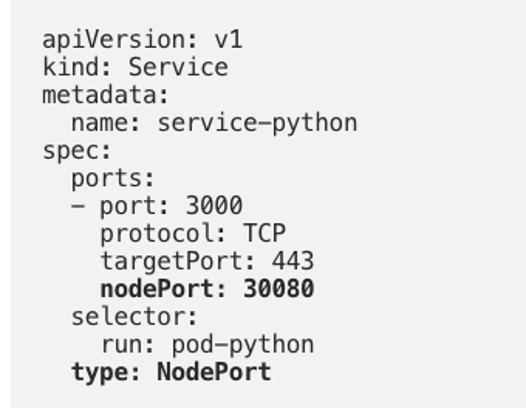
图13 NodePort 类型 service 的 yaml 定义*(图片来源于参考文章)*
使用 yaml 创建后,通过命令行能够看到 service 的信息如下,可以看到 NodePort 类型的 service 也存在一个 ClusterIP。

图14 NodePort 类型 service 的命令行信息*(图片来源于参考文章)*
所以,针对于 NodePort 类型,其使用场景就是在 k8s 集群外通过 node ip 来访问集群内的服务。
(3)LoadBalancer 类型
LoadBalancer 类型的 service 一般用在公有云场景,需要云服务商实现 LoadBalancer 才能使用。在私有化场景下,一般是不会使用这种类型的 service。如下图所示:
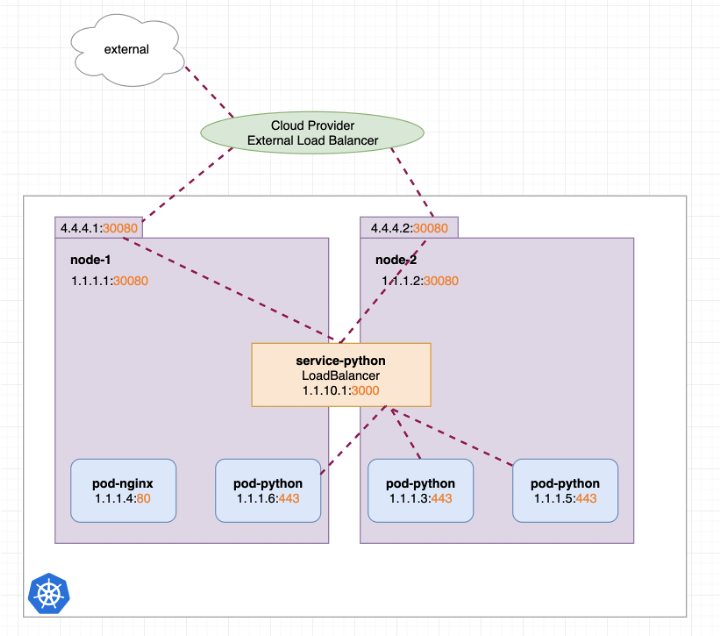
图15 LoadBalancer 类型的 service*(图片来源于参考文章)*
在公有云上,如果通过 NodePort 的形式来暴露服务,就需要给每个 node 申请一个公网 ip,而公网 ip 的资源是比较稀缺的。所以,通过 LoadBalancer 类型的 service 只需要对外暴露一个公网 ip 即可。另外,通过 LoadBalancer,请求可以负载均衡到多个 node 上,不会给单个 node 造成比较大的请求压力。
LoadBalancer 类型的 service yaml 如下图所示,可以看到跟 NodePort 的区别在于 type 设定为 LoadBalancer,并且也指定了 nodePort 为 30080。同样,这里如果没有指定 nodePort,则 k8s 会在设定范围默认分配一个没有被占用的 port。
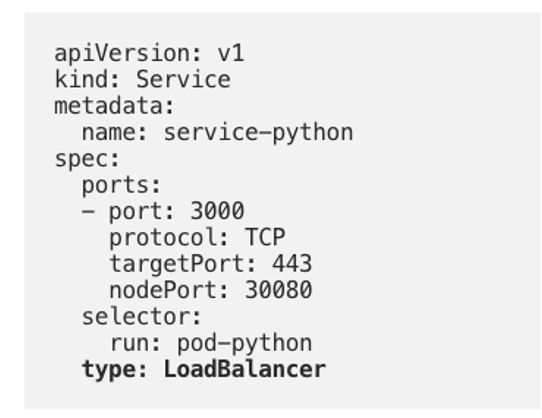
图16 LoadBalancer 类型 service 的 yaml 定义*(图片来源于参考文章)*
使用 yaml 创建后,通过命令行能够看到 service 的信息如下,可以看到除了 NodePort 该有的信息之外,还存一个 external ip。

图17 LoadBalancer 类型 service 命令行信息*(图片来源于参考文章)*
所以,针对于 LoadBalancer 类型,其使用场景一般是公有云上集群外的服务需要访问集群内的服务。
(4) ExternalName 类型
ExternalName 类型的 service,其使用场景较为特殊。一般是在迁移服务到 k8s 集群过程中会被使用到。如下图所示,当前有一个服务 nginx pod 已经迁移到了集群内部,还有一个服务 python 未进行迁移。
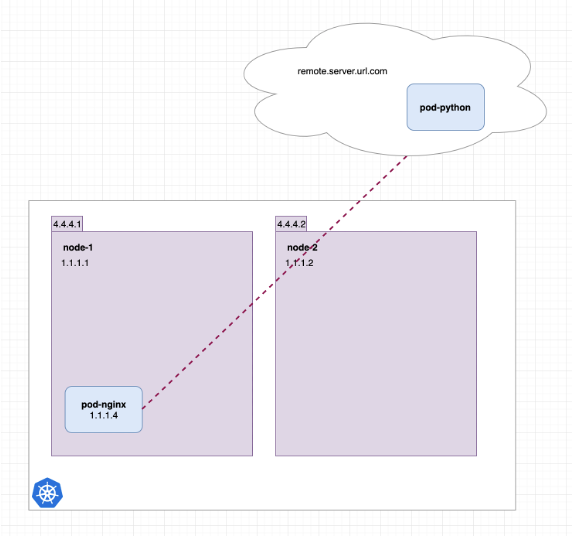
图18 部分服务迁移到 k8s 集群内*(图片来源于参考文章)*
从图中可以看出,此时 nginx 服务要访问 python 服务,需要通过外网域名进行访问。此时,可以通过使用 ExternalName 类型的 service 来代替外网域名,如下图所示。
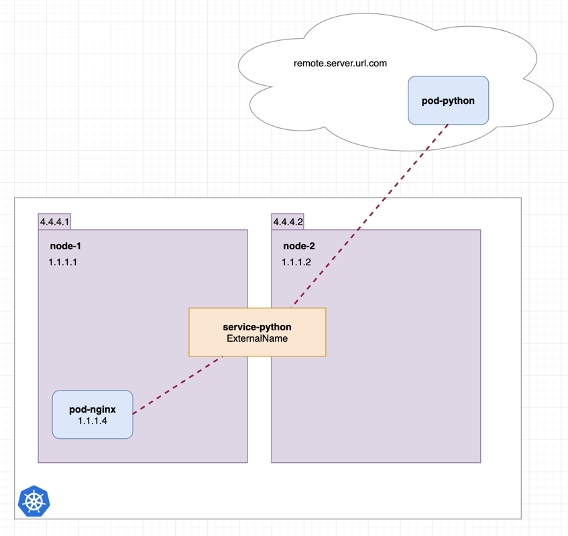
图19 使用 ExternalName 类型的 service 代替外网域名*(图片来源于参考文章)*
从图中可以看出,创建一个 ExternalName 类型的 python service,此时 nginx pod 可以通过访问这个 service 来重定向到 python 服务。当 python 服务迁移到集群内部时,只需要简单地将 service 的类型改成 ClusterIP 即可,如下图所示:
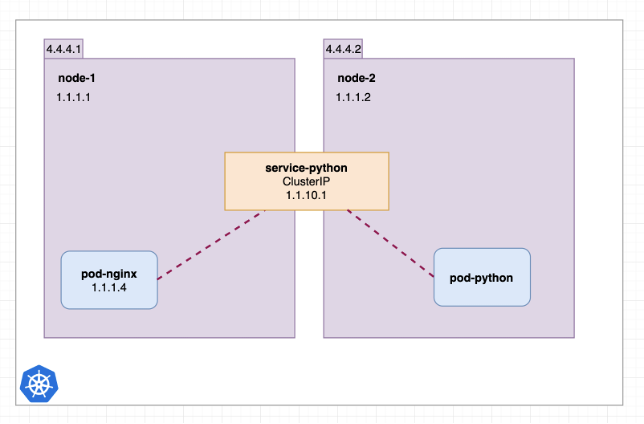
图20 服务迁移到集群内部后,更改 ExternalName 类型为 ClusterIP*(图片来源于参考文章)*
所以,针对于 ExternalName 类型,其使用场景一般是在迁移服务到 k8s 集群过程中会进行使用。
最后,我们来看下比较特殊的类型,即 Headless Service。
Headless Service 的主要使用场景是,不希望通过 service 负载均衡请求到后端的多个服务实例。因为在某些场景,后端实际服务是有状态,而非无状态的。所以,一般 Headless Service 会配合 k8s Statefulset 负载类型一起使用。如下图所示,Headless service 实际上是将后端所有实例的 ip 返回给访问端。
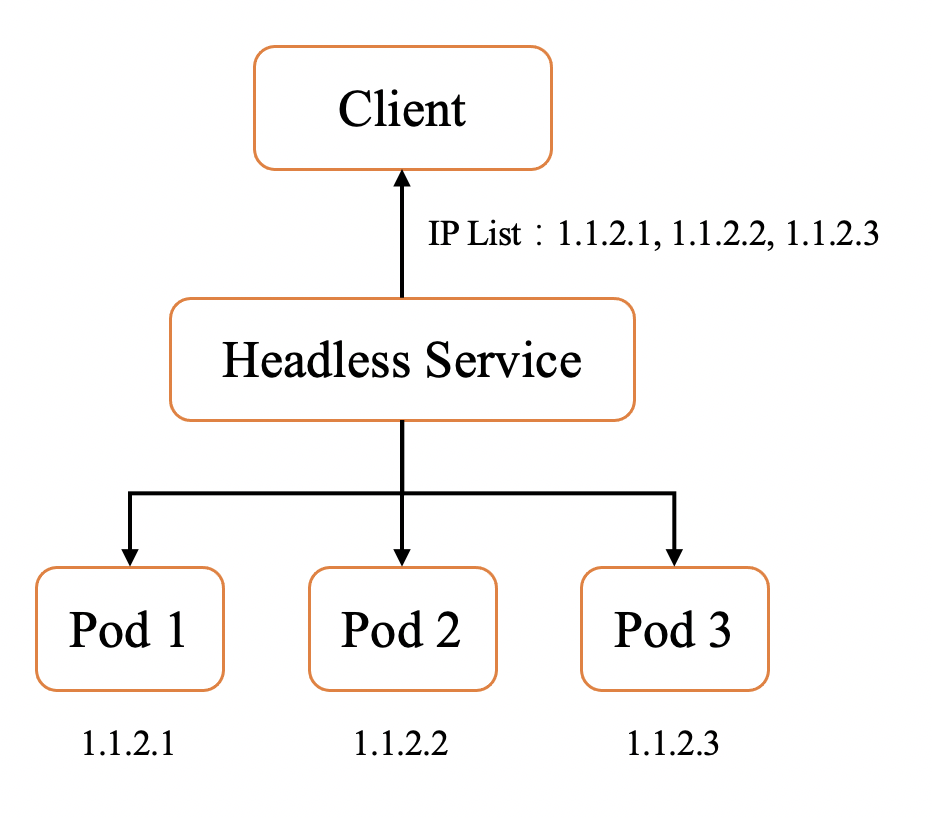
图21 Headless service 返回所有 pod 实例的 ip 信息
使用 Headless service,需要访问端能够对多个 ip 进行处理,并与实际的服务端进行访问协商最终访问的服务节点是哪一个。例如 HDFS、ElasticSearch、Redis 等服务就需要使用到 Headless Service。
One More Thing
在做内部分享过程中,有同学问了个比较有意思的问题,这里也分享给大家。
问题:在 Pod 内能看到一堆跟 service 相关的环境变量,作用是什么?
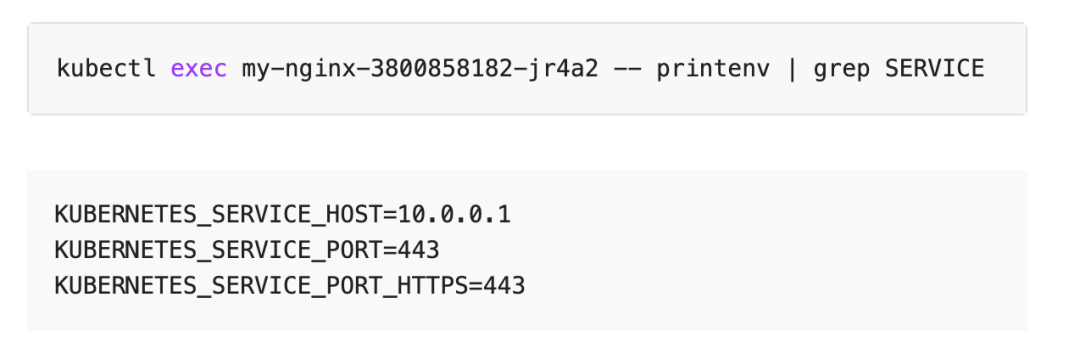
图22 pod 中看到的 service env*(图片来源于官网)*
经过查阅,这些 env 是 k8s 用来做服务发现的。k8s 会把集群中所有 active service 以环境变量的形式注入 pod,这样 pod 就可以知道当前集群内有哪些存活的服务。参考:https://kubernetes.io/docs/concepts/services-networking/service/,如下图所示:
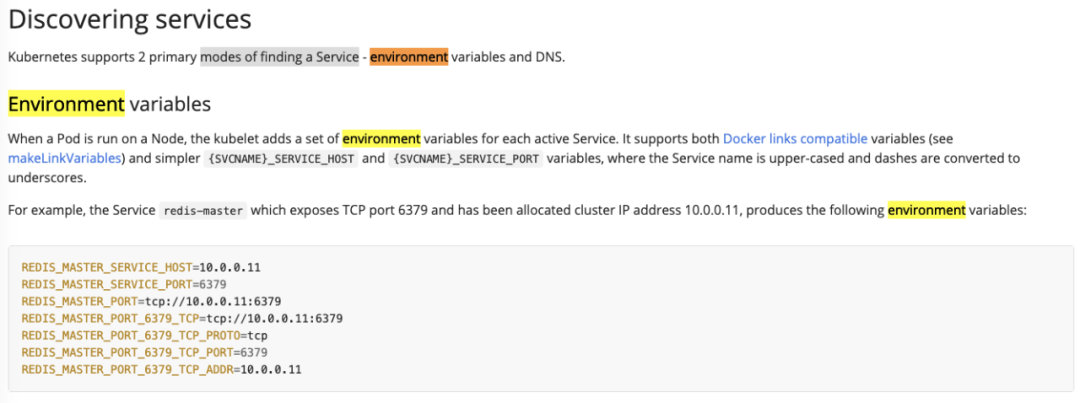
图23 pod 中 service env 的官方解释*(图片来源于官网)*
不过,现在一般都不这么用了,推荐使用 dns 来做服务发现。如下图所示,k8s 源码注释也是这么建议的。
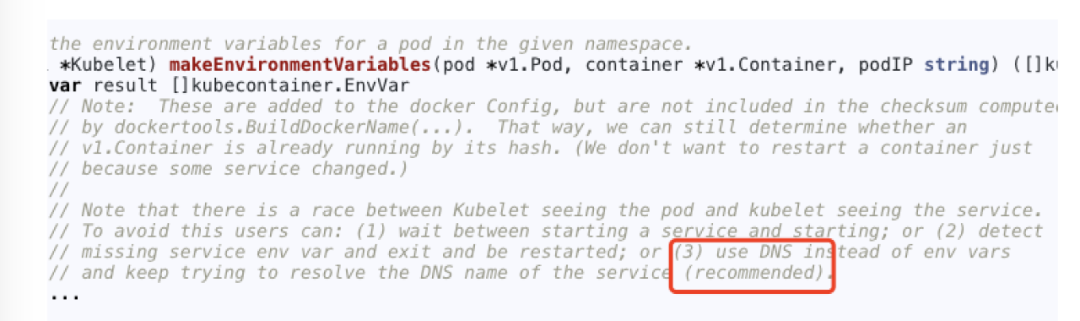
图24 k8s 源码中对 service env 的解释*(图片来源于参考文章)*
所以,后来有 issue 讨论,是不是要把这种默认注入行为做成开关。最终,就有了 enableServiceLinks 这个开关来控制,默认是注入的,可以选择关掉。参考:https://github.com/kubernetes/kubernetes/issues/60099,如下图所示,源码中对 enableServiceLinks 的解释。

图25 k8s 源码对 enableServiceLinks 开关的解释*(图片来源于参考文章)*
总结
本文主要是对 Kubernetes service 做一个简单的介绍,并描述了 service 不同类型的作用与使用场景。不同类型的使用场景总结如下:
- ClusterIP 场景:集群内部服务间的访问
- NodePort 场景:集群外部通过 Node IP 访问集群内部服务
- LoadBalancer 场景:集群外部通过一个 IP 地址访问集群内部服务
- ExternalName 场景:集群外部服务平滑迁移到集群内部
- Headless Service 场景:客户端需要所有 Pod 实例地址
参考链接
- K8S Service 官网:https://kubernetes.io/zh/docs/concepts/services-networking/service/
- K8S 网络博客:https://medium.com/swlh/kubernetes-services-simply-visually-explained-2d84e58d70e5
- Kubernetes service iptables 解释:https://www.ucloud.cn/yun/33179.html
Kubernetes service 确实是个很好的设计,在此次学习之前,也不了解原来 service 有这么多种类型与不同的使用场景。需要学习的东西还有很多。一起加油吧,各位。



