八、面向对象
目录
一、面向过程与面向对象
二、类的定义
三、类的基本使用
四、对象的使用
五、对象属性与类属性
六、对象属性的查找顺序
七、对象访问共有部分,即访问类的属性,属性查找与绑定方法
八、小练习1
九、类型即类
十、小练习2
十一、面向对象的三大特性
十二、子类重用父类的方法
十三、组合
十四、接口与归一化设计
十五、多继承
十六、多态与多态性
十七、封装
十八、绑定方法与非绑定方法
十九、.isinstance()与issubclass()
二十、反射
二十一、内置方法
1.面向过程与面向对象的对比
#面向过程:核心"过程"二字,过程即解决问题的步骤,就是先干什么再干什么 #基于该思想写程序就好比在设计一条流水线,是一种机械式的思维方式 #优点:复杂的过程流程化,进而简单化 #缺点:扩展性差 #面向对象:核心“对象”二字,对象指特征与技能的结合体 #基于该思想编写程序就好比在创造一个世界,世界是由一个个对象组成,是一种“上帝式”的思维方式 #优点:可扩展性强 #缺点:编程复杂高,容易出现过度设计
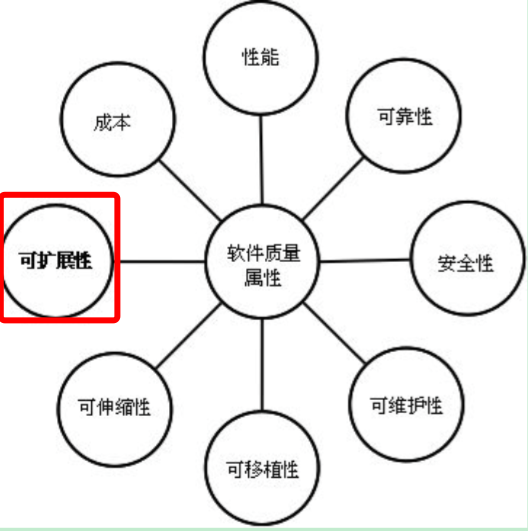
注:面向对象的程序设计并不是全部。对于一个软件质量来说,面向对象的程序设计知识用来解决扩展性。如下图所示:
2.类的定义
#对象是特征与技能的结合体,类就是一系列对象相似的特征与技能的结合体 问:是先有对象还是先有类? 答:在现实世界中,一定是先有一个个具体存在的对象,后总结出的类 在程序中,一定保证先定义类,后产生对象
3.类的基本使用
#类体代码在类的定义阶段就会立刻执行 # 如school='北大’会在内存中开辟空间存放北大并将内存地址赋值给变量school class Student: school = '北大' #类中的特征定义 #类中的功能(技能)定义 def learn(self): #为什会有这么一个位置形参 print ('is learning') def choose_course(self): print ('choose course') #查看类属性和函数 print (Student.school) #数据属性,得到school的值 print (Student.learn) #函数属性,得到learn的内存地址 #属性存在即修改,属性不存在即创建增加 Student.country ='China' print (Student.country) #删除类属性 del Student.country print (Student.country) #报错,类中没有该属性 #类功能使用 print (Student.learn('xxx')) #需要有实参xxx对应形参self,否则报错,
#但是类如果实例化后,就可以无需传实参给对应的self形参,见知识点7
4.对象的使用
class Student: school='北大' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def learn(self): print ('is learning') def choose_course(self): print ('choose course') #调用类的过程又称为实例化 #1.得到一个返回值,即对象,该对象是一个空对象 #2.触发类Student.__init__(stu1,'lisl','男',18) stu1=Student('lisl','男',18) print (stu1.__dict__) #打印出__init__里的属性 print (stu1.Name) #打印名字
5.对象属性与类属性
#对象属性:只有数据属性 #类属性:有数据属性(类的特征)和函数属性(类的功能) class Student: school='北大' def __init__(self,name,sex,age): #__init__也是函数可以执行其他判断语句,不能有返回值return self.Name=name self.Sex=sex self.Age=age def learn(self): print ('is learning') def choose_course(self): print ('choose course') stu1=Student('lisl','男',18) print (stu1.__dict__) #打印出__init__里的属性,只有数据属性 print (Student.__dict__) #有数据属性和函数属性
6.对象属性的查找顺序
class Student: school='北大' Name = '类里名字' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def learn(self): print ('is learning') def choose_course(self): print ('choose course') stu1=Student('lisl','男',18) print (stu1.Name) #打印对象属性里的名字=lisl print (Student.Name) #打印类数据属性里的名字‘类里名字’ #将self.Name=name修改成==》self.Name2=name print (stu1.Name) #打印对象属性里的名字=‘类里名字’ print (Student.Name) #打印类数据属性里的名字=‘类里名字’ #注:如果对象属性里没有Name,类属性里也没有Name,而全局有Name,Student.Name是无法使用全局的Name的,会报错 #总论:对象属性查找:先从对象自己的名称空间(即__dict__)找---》再到类的名称空间(即__dict__)里找,不会再全局找
7.对象访问共有部分,即访问类的属性,属性查找与绑定方法
class Student: school='北大' # Name = '类里名字' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def learn(self): print ('%s is learning'%self.Name) def choose_course(self): print ('choose course') #实例化对象 stu1 =Student('lisl','boy',18) stu2 =Student('chenhong','girl',28) stu3 =Student('wangdong','boy',17) #值相同,id也相同,说明都是去访问类属性或类方法 print (Student.school,id(Student.school)) print (stu1.school,id(stu1.school,)) print (stu2.school,id(stu2.school,)) print (stu3.school,id(stu3.school,)) #修改某个对象的属性,类似里在对象里创建了该属性,而非在类属性里修改,如 stu1.school='xxx' #如果要修改所有对象的共有部分,则需要对类属性进行修改,如 Student.school='xxx' #总结2:类的数据属性是所有对象共享,所有对象都指向同一个内存地址 print (Student.learn) #结果<function Student.learn at 0x00000000010E1C80> print (stu1.learn) <bound method Student.learn of <__main__.Student object at 0x00000000010FB240>> print (stu2.learn) <bound method Student.learn of <__main__.Student object at 0x00000000010FB278>> print (stu3.learn) #总结3:类中定义的函数(即类的函数属性)是绑定给对象使用: ##1.不同对象就是不同绑定方法 ##2.绑定给谁,就应该由谁来调用就会把谁当做第一个参数传给对应的函数,如: stu1.learn() #绑定给stu1,就将stu1当做实参传递给第一个形参self 结果:lisl is learning
8.小练习:每个对象想统计类被调用了多少次
class Teacher: school='北大' count = 0 def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age Teacher.count +=1 #不能self.count这样就是统计对象自己,类的属性变动才能影响到所有对象 def teacher(self): print ('%s is teaching'%self.name) #实例化对象 teacher1=Teacher('lisl','boy','18') teacher2=Teacher('chenhong','girl','21') teacher3=Teacher('wangdong','boy','12') # 每个对象都知道这个类总共被几个对象调用了 print (teacher1.count) print (teacher2.count) print (teacher3.count)
9.类型即类
#类型即类 l1=[2,3,4,5] l1.append(5) #等于list.append(l1,5),即l1是list类的对象化
10.小练习:对象交互,模拟英雄联盟盖伦攻击瑞文掉血场景


class Galenus: #类是盖伦 camp = 'demoria' #阵营是德玛西亚 def __init__(self,name,life,damage): #名字,生命值,攻击力 self.Name=name self.Life=life self.Damage=damage def attack(self,target_obj): #攻击对象 target_obj.Life -=self.Damage #被攻击对象的生命值等于扣除攻击者的攻击力的剩余生命值 class Raven: #类是瑞文 camp = 'North Texas' #阵营是诺克萨斯 def __init__(self,name,life,damage): #名字,生命值,攻击力 self.Name=name self.Life=life self.Damage=damage def attack(self,target_obj): #攻击对象 target_obj.Life -=self.Damage #被攻击对象的生命值等于扣除攻击者的攻击力的剩余生命值 #创造俩个人物 g1=Galenus('草丛猥琐男',1000,100) r1=Raven('奔跑瑞文',200,500) print (r1.Life) #瑞文被攻击前生命值 g1.attack(r1)#盖伦g1攻击瑞文r1 print (r1.Life)#瑞文被攻击后生命值
11.面向对象的三大特性
继承、封装、多态(见16知识点)
11.1 继承
''' 1 什么是继承 是一种新建类的方式,新建的类成为子类,子类会遗传父类的属性,可以减少代码冗余 在python中,子类(派生类)可以继承一个或者多个父类(基类,超类) ''' #简单写法: class Parent1: pass class Parent2: pass class Sub1(Parent1): #单继承 pass class Sub2(Parent1,Parent2): #多继承 pass #查看子类继承了什么父类,已元组形式返回 print (Sub1.__bases__) #结果:(<class '__main__.Parent1'>,) print (Sub2.__bases__) #结果:(<class '__main__.Parent1'>, <class '__main__.Parent2'>) print (Parent1.__bases__) #结果:(<class 'object'>,),父类默认继承object类 #在python2中类分为两种: #1.经典类,指的就没有继承object类的类,以及该类的子类 #2.新式类,指的就是继承object类的类,以及该类的子类 #在python3中统一都为新式类
继承举例:
class People: school='北大' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def tell_info(self): print ('<姓名:%s,性别:%s,年龄:%s>'%(self.Name,self.Sex,self.Age)) class Student(People): def learn(self): print ('%s is learning'%self.Name) def tell_info(self): #父类中的tell_info函数属性不满足子类,可以自行创建,会优先使用子类的 print ('我是学生:',end='') print ('<姓名:%s,性别:%s,年龄:%s>'%(self.Name,self.Sex,self.Age)) #下面有更简洁的办法,重用父类代码 ,方法:People.tell_info(self) class Teacher(People): def teach(self): print ('%s is teaching'%self.Name) stu1 = Student('lisl','boy',18) print (stu1.school) #查找顺序:对象属性---》子类,Student属性---父类,People属性 stu1.tell_info()
小练习,看你混淆不混淆
class Foo: def f1(self): print ('Foo.f1') def f2(self): #self=obj print ('Foo.f2') self.f1() #obj.f1()
class Bar(Foo): def f1(self): print ('Bar.f1') obj = Bar() obj.f2() #结果: Foo.f2 Bar.f1
12.子类重用父类的方法
方法一:指明道姓,即父类名.父类方法()
#子类想扩展父类某个函数功能,如何避免代码重用 class People: school='北大' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def tell_info(self): print ('<姓名:%s,性别:%s,年龄:%s>'%(self.Name,self.Sex,self.Age)) class Student(People): def learn(self): print ('%s is learning'%self.Name) def tell_info(self): print ('我是学生:',end='') People.tell_info(self) #调用People类中的tell_info函数属性,使用代码重用,此处不是继承关系,此处的self=stu1 stu1 = Student('lisl','boy',18) print (stu1.school) stu1.tell_info()
方法二:super()
#子类想扩展父类某个函数功能,如何避免代码重用 #方法二: class People: school='北大' def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age def tell_info(self): print ('<姓名:%s,性别:%s,年龄:%s>'%(self.Name,self.Sex,self.Age)) class Student(People): def __init__(self,name,sex,age,course): super().__init__(name,sex,age) #super()是一个特殊的对象,既是对象调用方法,默认第一个形参对应的实参就不用写 self.Course=course def learn(self): print ('%s is learning'%self.Name) def tell_info(self): print ('我是学生:',end='') super().tell_info() #python2的格式是super(Student,self).tell_info(),下面会额外讲解 stu1 = Student('lisl','boy',18,'python') stu1.tell_info()
12.2 关于子类重用父类方法的方法二中,python2与python3中的不同点
#python2中格式: #super(子类,self).父类方法 #如上面的方法二的例子: super(Student,self).tell_info() #python3中格式: #super().父类方法 #如上面的方法二的例子: supper().tell_info()
12.3 关于子类重用父类方法的方法一与方法二区别
#1.方法一,指明道姓,用的是类而不是对象,因此没有所谓继承关系 #2.方法二,super()是特殊的对象,有继承关系。 当你使用super()函数时,Python会在MRO列表(继承顺序,见15.3)上继续搜索下一个类。只要每个重定义的方法统一使用super() 并只调用它一次,那么控制流最终会遍历完整个MRO列表,每个方法也只能被调用一次(ps:使用super调用的所有属性,都是从MRO 列表当前的位置(即super()所在类在MRO列表里往后查找,不在本类查找)往后找,千万不要通过看代码去找继承关系,一定要看MRO列表)
12.4 super()在MRO列表查找例子
class Foo: def f1(self): print ('FOO.f1') super().f2() #super()所处在Mro列表里的FOO,继续往后查找下一个类,看是否有f2()方法 class Bar: def f2(self): print ('Bar.f2') class Sub(Foo,Bar): pass print (Sub.mro()) #[<class '__main__.Sub'>, <class '__main__.Foo'>, <class '__main__.Bar'>, <class 'object'>] s= Sub() s.f1()
13.组合
''' 减少代码冗余除了使用继承,还可以使用组合 组合指的是,在一个类中以另外一个类的对象作为数据属性,称为类的组合 组合与继承的区别: 1.继承的方式 通过继承建立了派生类与基类之间的关系,它是一种'是'的关系,比如白马是马,人是动物。 当类之间有很多相同的功能,提取这些共同的功能做成基类,用继承比较好,比如老师是人,学生是人 2.组合的方式 用组合的方式建立了类与组合的类之间的关系,它是一种‘有’的关系,比如教授有生日,教授教python和linux课 程,教授有学生s1,s2,s3...。当类之间有显著不同,并且较小的类是较大的类所需要的组件时,用组合比较好 ''' class People: def __init__(self,name,sex,age): self.Name=name self.Sex=sex self.Age=age class Course: def __init__(self,name,period,price): self.Name=name self.Period=period self.Price=price def tell_info(self): print ('<%s %s %s>'%(self.Name,self.Period,self.Price)) class Teacher(People): def __init__(self,name,sex,age,job_title): People.__init__(self,name,sex,age) self.Job_title=job_title self.Course=[] self.Students=[] class Student(People): def __init__(self,name,sex,age): People.__init__(self,name,sex,age) self.Course=[] #实例化对象 lisl = Teacher('lisl','boy',18,'python讲师') wangdong = Student('王东','boy',22) python = Course('python','3mons',3000.0) linux = Course('linux','3mons',2000.0) #为老师lisl和学生wangdong添加课程,即组合 lisl.Course.append(python) lisl.Course.append(linux) wangdong.Course.append(python) #为老师lisl添加学生s1 lisl.Students.append(wangdong) #使用:打印所教的课程信息 for obj in lisl.Course: obj.tell_info()
14.接口与归一化设计
14.1 什么是接口
提取了一群类共同的函数,可以把接口当做一个函数的集合。然后让子类去实现接口中的函数,这么做的意义,在于归一化。
14.2什么是归一化?
只要是基于同一个接口实现的类,那么所有的这些类产生的对象在使用时,从用法上来说都一样
14.3归一化的好处:
1.让使用者无需关心对象的类是什么,只需要知道这些对象都具备某些功能就可以了,这极大地降低了使用者的使用难度
2.归一化使用高层的外部使用者可以不加区分的处理所有接口兼容的对象集合
2.1就好像linux的泛文件概念一样,所有的东西都可以当文件处理,不必关心它是内存、磁盘、网络还是屏幕(当然,对底层设计者,当然也可以区分出‘字符设备’和‘块设备’,然后做出针对性的设计)
2.2再比如:我们有一个汽车接口,里面定义了汽车所有的功能,然后有本田汽车的类,奥迪汽车的类,大众汽车的类,他们都实现了汽车接口,这样就好办了,大家只需要学会了怎么开汽车,那么无论是本田,还是奥迪,还是大众我们都会开了,开的时候根本无需关心我开的是哪一类车,操作手法(函数调用)都一样
14.4 用python模拟出类似jave interface的功能
需求:让子类严格按照父类来定义,实现类似java interface的功能 import abc class Animal(metaclass=abc.ABCMeta): @abc.abstractmethod #定义一个abc的抽象方法 def eat(self): pass @abc.abstractmethod def run(self): pass class People(Animal): #子类一定要有eat方法和run方法,否则报错。 def eat(self): print ('people is eating') def run(self): print ('people is running') class Pig(Animal): def eat(self): print ('pig is eating') def run(self): print ('pig is running')
15.多继承
15.1 多继承的顺序
在Java和C#中子类只能继承一个父类,而Python中子类可以同时继承多个父类,如A(B,C,D)
如果继承关系为非菱形结构(没有闭环),则会按照先找B这一条分支,然后再找C这一条分支,最后找D这一条分支的顺序直
到我们想要的属性
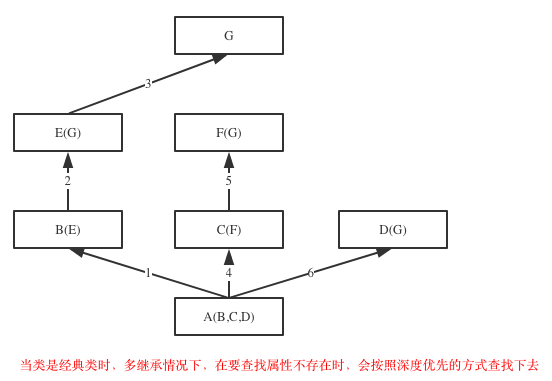
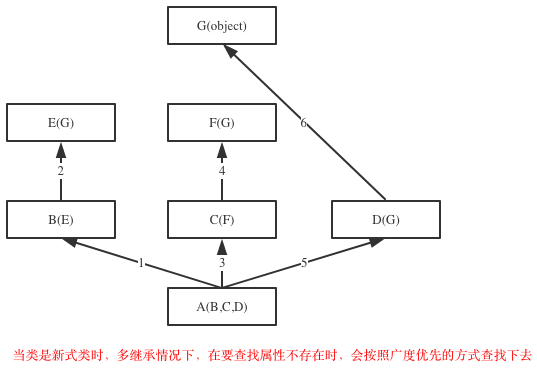
如果继承关系为菱形结构,那么属性的查找方式有两种,分别是:(经典类)深度优先和(新式类)广度优先,如下图所示
15.2 演示代码
class A(object): def test(self): print('from A') class B(A): def test(self): print('from B') class C(A): def test(self): print('from C') class D(B): def test(self): print('from D') class E(C): def test(self): print('from E') class F(D,E): # def test(self): # print('from F') pass f1=F() f1.test() print (F.__mro__) #只有新式类才有这个属性可以查看线性列表(继承顺序),经典类没有这个属性 #结果: #(<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>) #经典类继承顺序:F-->D-->B--->A--->E--->C #新式类继承顺序:F-->D-->B--->E--->C--->A #python2中才分新式类与经典类 #python3中统一都是新式类
15.3 继承原理
python到底是如何实现继承的,对于你定义的每一个类,python会计算出一个方法解析顺序(MRO)列表,这个MRO列表就是一个派生类简单的所有基类(父类)的线性顺序列表,例如
>>>F.mro() #等同于F.__mro__ [<class '__main__.F'>, <class '__main__.D'>, <class '__main__.B'>, <class '__main__.E'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>]
16.多态与多态性
16.1 什么是多态
同一种事物的多种形态
import abc class Animal(metaclass=abc.ABCMeta): @abc.abstractmethod #统一接口 def speak(self): pass class Cat(Animal): #动物的形态一:猫 def speak(self): print ('喵喵') class Dog(Animal): #动物的形态二:狗 def speak(self): print ('汪汪') class People(Animal): #动物的形态三:人 def speak(self): print ('say hello')
16.2 什么是多态性
不考虑对象具体类型的情况下,直接使用对象下的方法
#多态性 import abc class Animal(metaclass=abc.ABCMeta): @abc.abstractmethod #统一接口 def speak(self): pass class Cat(Animal): def speak(self): print ('喵喵') class Dog(Animal): def speak(self): print ('汪汪') class People(Animal): def speak(self): print ('say hello') def talk(obj): #定义一个统一接口函数来使用 obj.speak() people1=People() cat1=Cat() dog1=Dog() #人、猪、狗都是动物,只要是动物肯定有speak方法 #多态性,无需考虑对象的类型 talk(people1) #people1.speak() talk(cat1) talk(dog1)
python里一切皆对象,像之前学过的str().list().tuple()等等都是对象,都是具有多态性的,比如:
l=list([1,2,3]) s=str('hello world') t=tuple(('a','b','c')) #不用管对象是什么类型,可以直接调用对象里的方法__len__ l.__len__() s.__len__() t.__len__()
16.3 多态性优点
1.增加了程序的灵活性
2.增加了程序的可扩展性
16.4 多态性分类
静态多态性:如任何类型都可以用运算符+进行运算
动态多态性,如16.2例子
17.封装
#封装 class Foo: __N=1 #__符号为隐藏 def __init__(self,x,y): self.X=x self.__Y=y #__符号为隐藏 def __f1(self): #__符号为隐藏 print ('Foo.f1') def f2(self): print (self.__N,self.__Y) #检测语法时,已转换成self._Foo__N,self._Foo__Y,因此内部可以正常访问 #类直接调用属性 print (Foo.__N) #报错,提示__N不存在 print (Foo.__dict__) #查看Foo名称空间的key,value,可看到key为_FOO__N print (Foo._Foo__N) #可查看到隐藏__N的值 #实例化对象结果与类直接调用属性一样的结果 obj=Foo(1,2) print (obj.__N) #报错,提示__N不存在 print (obj.__dict__) #查看obj对象的名称空间的key,value,可看到{'X': 1, '_Foo__Y': 2} print (obj._Foo__N) #可查看到隐藏__N的值 obj=Foo(1,2) obj.__M=2 print (obj.__dict__) print (obj.__M) #总结1:只在定义类阶段变形(存在名称空间里的值有__N变成_Foo__N,只有变形的才不可被外部访问),赋值阶段不变形 #总结2:所谓的不可被外部访问,是指语法上(obj.__N)的不可访问,使用print (obj._Foo__N还是可以被访问的) #总结3:这种隐藏这对外不对内,因为类内部定义的属性统一在类定义阶段统一发生了变形
总结4:在继承中,父类如果不想让子类覆盖自己的方法,可以将方法定义为私有的(隐藏的),如下:
class Foo: def __f1(self): #_Foo__f1 print ('Foo.f1') def f2(self): print ('Foo.f2') #Foo.f1(self) #方法一,注意,有几个参数传几个参数 self.__f1() #方法二, self._Foo__f1() class Bar(Foo): def __f1(self): #_Bar__f1 print ('Bar.f1') b=Bar() b.f2()
17.2 封装的意义
#封装隐藏的意义之一:我将xx隐藏,外部需要访问,我统一给外部开一个接口 class People: def __init__(self): pass def tell_info(self): #开放统一输出接口 print ('姓名:<%s> 年龄:<%s>'%(self.__Name,self.__Age)) def set_info(self,name,age): #开放统一输入接口 #判断用户输入合法性 if type(name) is not str: raise TypeError('name must be str') elif type(age) is not int: raise TypeError('age must be int') #赋值给隐藏变量 self.__Name=name self.__Age=age p=People() p.set_info('lisl',18) p.tell_info()
17.3封装总结:
封装的真谛在于明确地区分内外,封装的属性可以直接在内部使用,而不是被外部直接使用,然而定义属性的目的终归是要用,外部要想用类隐藏的属性,需要我们为其开辟接口,让外部能够间接地用到我们隐藏起来的属性
1.封装数据:将数据隐藏起来这不是目的。隐藏起来然后对外提供操作该数据的接口,然后我们可以在接口附加上对该数据操作的限制,以此完成对数据属性操作的严格控制
2.封装方法:目的是隔离复杂度
17.4 特性((property)
#有时候需要把函数属性包装成数据属性,符合大众的认知观
#实现查看
class People: def __init__(self,name,age,height,weight): self.name=name self.age=age self.height=height self.weight=weight @property #函数属性包装成数据属性 def bmi(self): return self.weight / (self.height **2) p1=People('lisl',18,1.8,65) p1.height=1.75 print (p1.bmi) #调用函数属性不用加()
18.绑定方法与非绑定方法
#绑定方法与非绑定方法 #绑定方法:绑定给谁就应该由谁来调用,谁来调动就会把谁当做第一个参数自动传入 import settings import time,hashlib class MySQL: def __init__(self,host,port): self.host=host self.port = port def func(self): #默认是绑定给对象 print ('%s说今天天气好'%self.host) @classmethod #绑定给类 def from_conf(cls): return cls(settings.HOST,settings.PORT) @staticmethod #不绑定给类,也不绑定给对象,即形参可以有,也可无,对象要一一对应 def create_id(): m=hashlib.md5() m.update(str(time.clock()).encode('utf-8')) return m.hexdigest() conn=MySQL.from_conf() #返回的是一个实例化后的对象 print (conn.host,conn.port) print (conn.create_id()) #对象无需传参 #settings.py文件里 HOST='127.0.0.1' PORT='3306'
19.isinstance()与issubclass()
#1.判断数据类型 l=[] isinstance(l,list) #返回True #2.判断子类 class Foo: pass class Bar(Foo): pass print (issubclass(Bar,Foo)) #返回True,Bar是Foo的子类
20.反射
#通过字符串反射到对象的属性上 print (hasattr(obj,'name')) #判断有没有obj.name属性,有返回True print (getattr(obj,'name',None)) #取到obj.name的属性值,没有返回None setattr(obj,'age',18) #设置obj.age=18,如果age存在,则视为更新操作 print (getattr(obj,'age')) #del obj.name delattr(obj,'name') #删除obj.name属性 print (getattr(obj,'name',None))
20.1反射应用
class Ftpclient: def __init__(self,host,port): self.host=host self.port=port self.conn = 'xxx' def interactive(self): while True: cmd=input('>>:').strip() if not cmd:continue cmd_l=cmd.split() if hasattr(self,cmd_l[0]): #是否存在get关键字 func=getattr(self,cmd_l[0]) #映射到get方法 func() #执行get方法 def get(self): print ('上传。。。。。') obj=Ftpclient('172.16.1.1',53) obj.interactive() #结果 >>:get a.txt ['get', 'a.txt'] 上传。。。。。
21.内置方法
#__str__ class People: def __init__(self,name,age): self.name=name self.age=age def __str__(self): return '%s,%s' %(self.name,self.age) #对象后返回指定的字符串内容 lisl=People('lisl',18) print (lisl) #结果:lisl,18 #__del__ class Foo: def __del__(self): # 当对象被回收前,会触发此方法,一般用于关闭文件或数据库操作,避免只打开不关闭 print('对象被回收了,我要被关闭了') m = Foo() del m #删除对象,即回收内存空间,触发__del__ print('拜拜')
22.元类
22.1 一切皆对象
class People: #People = 元类(...) county='china' def __init__(self,name,age): self.name=name self.age=age def eat(self): print('%s is eating' %self.name) p1=People('egon',18) # 元类----实例化----》类----实例化----》对象 # print(type(p1)) print(type(People)) # 默认的元类是type
22.2 定义一个类有三大关键部分
#1.类名 #2.类的基类们 #3.类的名称空间 class People: #People = type(类名,类的基类们,类的名称空间) county='china' def __init__(self,name,age): self.name=name self.age=age def eat(self): print('%s is eating' %self.name) # print(People,People.__dict__) p1=People('egon',18) print(p1.__dict__)
22.3 class关键字底层执行的操作
#1.拿到类名class_name='People' #2.拿到基类们class_bases=(object,) 元组形式 #3.执行类体代码,产生类的名称空间,将类体代码执行中产生的名字丢进去,class_dic={...} #4.调用元类产生People类,People=type(class_name,class_bases,class_dic) ##模拟class效果 class_name="People" class_bases=(object,) class_dic={} class_body=""" county='china' def __init__(self,name,age): self.name=name self.age=age def eat(self): print('%s is eating' %self.name) """ exec(class_body,{},class_dic) # print(class_dic) People=type(class_name,class_bases,class_dic) # print(People,People.__dict__) p2=People('egon',18) print(p2.__dict__) #结果{'name': 'egon', 'age': 18}
# 补充:exec的使用
local_dic={}
exec("""
x=1
y=2
z=3
""",{},local_dic) #第2个参数{},为全局参数,第3个参数local_dic为局部参数
print(local_dic) #{'x': 1, 'y': 2, 'z': 3}
22.4 自定义元类来控制类的产生
#People = Mymeta('People',(object,),{....}) #__init__(People,'People',(object,),{....}) class Mymeta(type): # 自定义元类必须继承了type类才能称之为元类 def __init__(self,class_name,class_bases,class_dic): super(Mymeta,self).__init__(class_name,class_bases,class_dic) # print(class_name) # print(class_bases) # print(class_dic) #要求类名必须为首字母大写 if not class_name.istitle(): raise TypeError('类名%s的首字母必须大写' %class_name) # print(class_dic) #要求类必须有注释,且不能为空 if '__doc__' not in class_dic or len(class_dic['__doc__'].strip(' \n')) == 0: raise TypeError('必须有文档注释') class People(object,metaclass=Mymeta): #People=Mymeta('People',(object,),{....}) """ 注释必须有 """ county='china' def __init__(self,name,age): self.name=name self.age=age def eat(self): print('%s is eating' %self.name) #注意:在类定义阶段就会检查是否符合自定义 设定类标准
22.5 自定义元类来控制产生对象的过程(难,多多理解)
#类产生对象的本质是调用元类的__call__方法 class People(object): county='china' def __init__(self,name,age): self.name=name self.age=age def eat(self): print('%s is eating' %self.name) def __call__(self, *args, **kwargs): print('===>',self) print(args) print(kwargs) obj=People('egon',18) obj(1,2,3,x=1,y=2) #触发类People中的__call__,即调用对象就是在触发对象所在类的中的__call__ #即对象之所以可以调用,一定是对象的类中定义了一个__call__
#自定义元类来控制类产生对象的过程 class Mymeta(type): def __call__(self, *args, **kwargs): #self=<class '__main__.People'> # print('=====>',self) # print('=====>',args) # print('=====>',kwargs) #1、先造一个People类的空对象obj obj=self.__new__(self) # print(obj.__dict__) #2、调用People类中__init__函数,完成初始化空对象obj的操作 # print(self.__dict__) self.__init__(obj,*args,**kwargs) # print(obj.__dict__) # dic={} # for k,v in obj.__dict__.items(): # dic['_%s__%s' %(self.__name__,k)]=v # # # print(dic) # obj.__dict__=dic
#隐藏属性值
obj.__dict__={'_%s__%s' %(self.__name__,k):v for k,v in obj.__dict__.items()} #3、返回对象obj return obj class People(object,metaclass=Mymeta): county='china' def __init__(self,name,age,sex): self.name=name self.age=age self.sex=sex def eat(self): print('%s is eating' %self.name) p1=People('egon',18,'male') # 调用对象People,一定是对象People的类Mymeta中有一个__call__ # print(p1) print(p1.__dict__) # print(People.__dict__)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号