数据结构与算法10—图的遍历
图的遍历
1. 在图中有回路,从图中某一顶点出发访问图中其它顶点时,可能又会回到出发点,而图中可能还剩余有顶点没有访问到。
2. 我们可以设置一个全局型标志数组visited来标志某个顶点是否被访问过,未访问的值为0,访问过的值为1。
3. 图的遍历有两种方法:深度优先搜索遍历(DFS)、广度优先搜索遍历(BFS)。
深度优先搜索
深度优先搜索思想
- 首先访问顶点i,并将其访问标记置为访问过,即visited[i] =1;
- 然后搜索与顶点i有边相连的下一个顶点j,若j未被访问过,则访问它,并将j的访问标记置为访问过,visited[j]=1,然后从j开始重复此过程,若j已访问,再看与i有边相连的其它顶点;
- 若与i有边相连的顶点都被访问过,则退回到前一个访问顶点并重复刚才过程,直到图中所有顶点都被访问完为止。
例如:
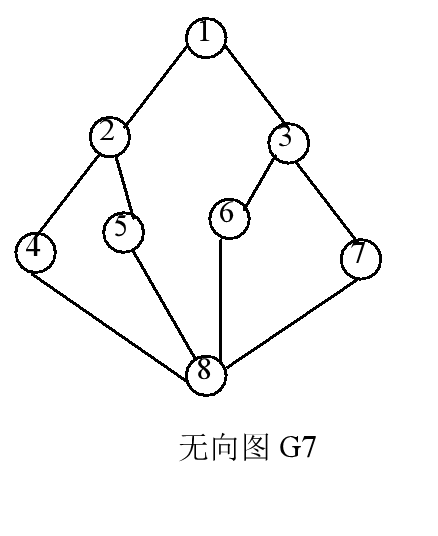
对下图所示无向图G7,从顶点1出发的深度优先搜索遍历序列可有多种,下面仅给出三种,其它可作类似分析。

1, 2, 4, 8, 5, 6, 3, 7
1, 2, 5, 8, 4, 7, 3, 6
1, 3, 6, 8, 7, 4, 2, 5
可以看出,从某一个顶点出发的遍历结果是不唯一的。但是,若我们给定图的存贮结构,则从某一顶点出发的遍历结果应是唯一的。
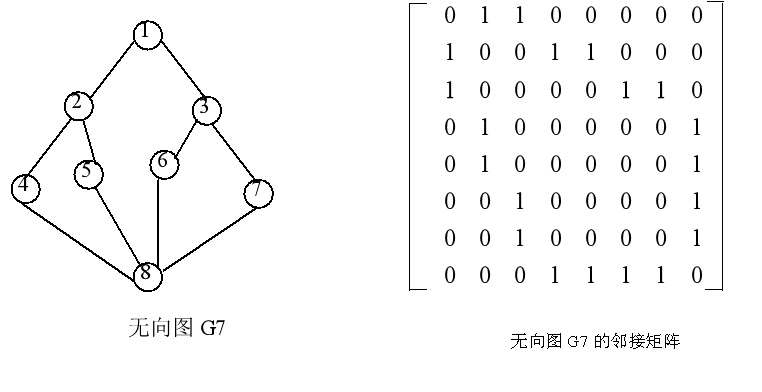
1. 用邻接矩阵实现图的深度优先搜索
#define MAX_VERTEX_NUM 100 typedef int VertexType; /*假设图中结点的数据类型为整型*/ typedef struct { VertexType v[MAX_VERTEX_NUM]; /*顶点表*/ int A[MAX_VERTEX_NUM][MAX_VERTEX_NUM]; /*邻接矩阵*/ int vexnum,arcnum; /*图的顶点数和弧数*/ }MGraph; int visited[MAX_VERTEX_NUM]; void DFSM(MGraph G, int i) { printf("%5d",G.v[i]); /*访问顶点i*/ visited[i]=1; /*标记顶点i已访问*/ for(int j=0;j<G.vexnum;j++) { if (!visited[j] && G.A[i][j]==1) DFSM(G,j); /*若某个邻接顶点尚未访问,则递归访问它*/ } }
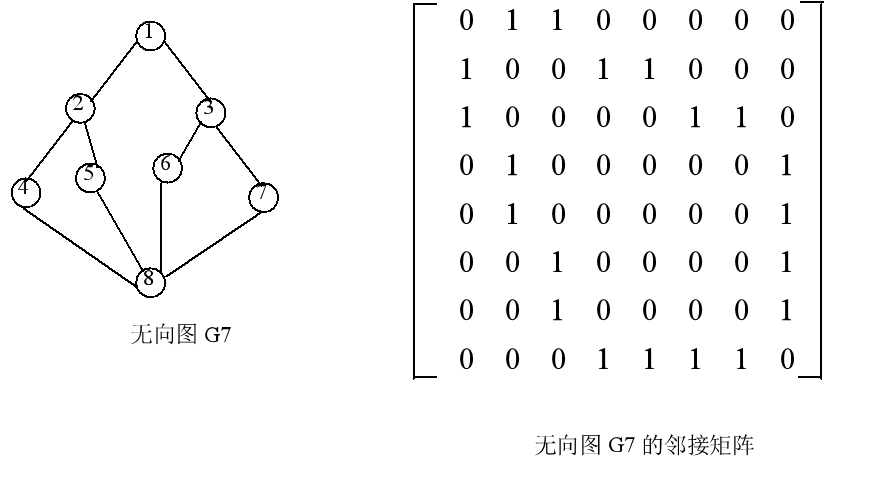
用上述算法和无向图G7,可以描述从顶点1出发的深度优先搜索遍历过程,其中实线表示下一层递归调用,虚线表示递归调用的返回。 可以得到从顶点1的遍历结果为 1, 2, 4, 8, 5, 6, 3, 7。同样可以分析出从其它顶点出发的遍历结果。
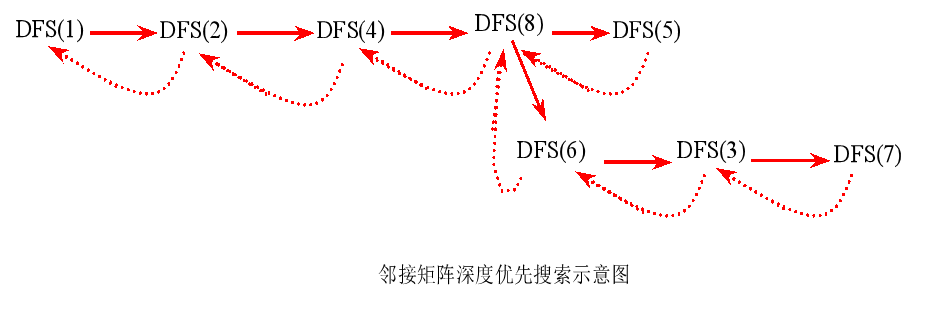
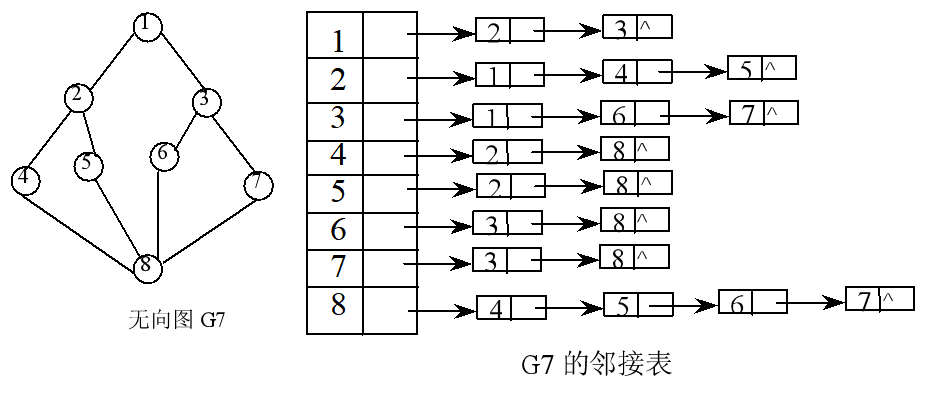
2. 用邻接表实现图的深度优先搜索
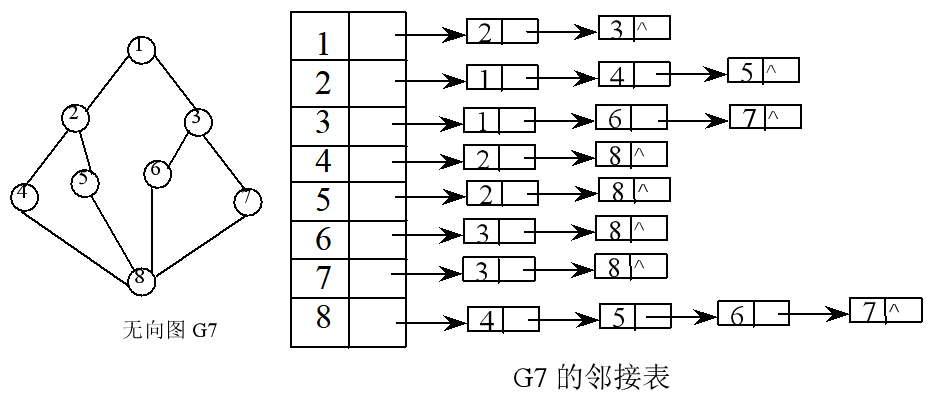
图的邻接表存储结构定义:
typedef struct ArcNode { int adjvex; /*该弧所指向的顶点的位置*/ struct ArcNode *nextarc; /*下一条弧*/ InfoType info; /*该弧上的权值*/ } ArcNode; typedef int VertexType; typedef struct VNode { VertexType data; ArcNode *firstarc; }VNode; typedef struct { VNode vertices[MAXV]; int vexnum, arcnum; } ALGraph;
邻接表存储时的深度优先搜索算法:
int visited[MAX_VERTEX_NUM]; void DFS(ALGraph G, int v) { ArcNode *p; printf("%5d",G.vertices[v].data); /*访问顶点v*/ visited[v]=1; /*标记顶点v已访问*/ p=G.vertices[v].firstarc; /*取第一个邻接边*/ while (p) { if (!visited[p->adjvex]) DFS(G,p->adjvex); /*递归访问*/ p=p->nextarc; /*找顶点v的下一个邻接点*/ } }
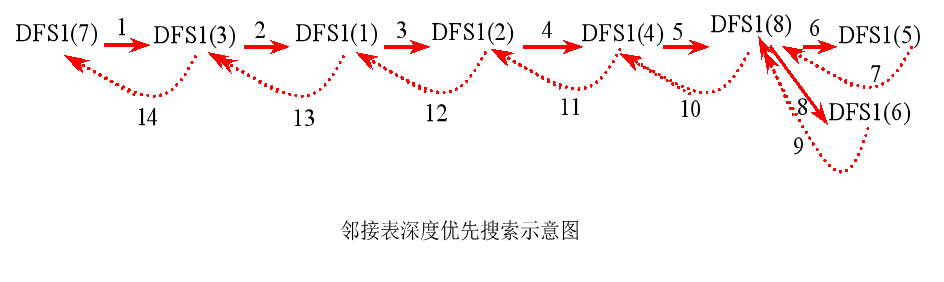
用刚才算法,可以描述从顶点7出发的深度优先搜索遍历示意图,其中实线表示下一层递归,虚线表示递归返回,箭头旁边数字表示调用的步骤。遍历序列为 7, 3, 1, 2, 4, 8, 5, 6。
广度优先搜索
广度优先搜索的思想
借助队列先进先出的特点实现
- 首先访问顶点i,并将其访问标志置为已被访问,即visited[i]=1;
- 接着依次访问与顶点i有边相连的所有顶点W1,W2,…,Wt;
- 然后再按顺序访问与W1,W2,…,Wt有边相连又未曾访问过的顶点;
- 依此类推,直到图中所有顶点都被访问完为止 。
在无向图G7中,从顶点1出发的广度优先搜索遍历序列举三种为:
1, 2, 3, 4, 5, 6, 7, 8
1, 3, 2, 7, 6, 5, 4, 8
1, 2, 3, 5, 4, 7, 6, 8
1. 用邻接矩阵实现图的广度优先搜索遍历
根据该算法用及图7-14中的邻接矩阵,可以得到图G7的广度优先搜索序列,
若从顶点1 出发,广度优先搜索序列为:1,2,3, 4,5, 6,7,8。
若从顶点3出发,广度优先搜索序列为:3, 1, 6, 7, 2, 8, 4, 5。
邻接矩阵存储时的宽度优先搜索算法:
void BFSM(MGraph G,int i) { int j; Queue Q; InitQueue(&Q); InQueue(&Q,i); printf("%5d",G.v[i]); /*访问初始顶点v*/ visited[i]=1; /*置已访问标记*/ while(OutQueue(&Q,&i)) { /*若队列不空时循环*/ for(j=0;j<G.vexnum;j++) { if (!visited[j] && G.A[i][j]==1) { visited[j]=1; printf("%5d",G.v[j]); /*访问v*/ InQueue(&Q,j); /*该顶点进队*/ } } } }
2. 用邻接表实现图的广序优先搜索遍历
可以得到图G7的广度优先搜索序列,
若从顶点1出发,广度优先搜索序列为:1,2,3,4,5,6,7,8,
若从顶点7出发,广度优先搜索序列为:7,3,8,1,6,4,5,2。
邻接表存储时的宽度优先搜索算法:
void BFS(ALGraph G,int v) { ArcNode *p; int x; Queue Q; InitQueue(&Q); InQueue(&Q,v); printf("%5d",G.vertices[v].data); /*访问初始顶点v*/ visited[v]=1; /*置已访问标记*/ while(OutQueue(&Q,&x)) { /*若队列不空时循环*/ p=G.vertices[x].firstarc; /*与x邻接的第一个顶点*/ while(p!=NULL) { if (visited[p->adjvex]==0) { /*若未被访问*/ visited[p->adjvex]=1; printf("%5d",G.vertices[p->adjvex].data); InQueue(&Q,p->adjvex); /*该顶点进队*/ } p=p->nextarc; /*找下一个邻接点*/ } } }

