(三十三)什么是自动化测试模型之自动化测试模型介绍
随笔记录方便自己和同路人查阅。
#------------------------------------------------我是可耻的分割线-------------------------------------------
学习selenium自动化之前,最好先学习HTML、CSS、JavaScript等知识,有助于理解定位及操作元素的原理。关于python和selenium安装请自行搜索别的资料,这里就不多做介绍了,所有例子均使用python3.6+selenium执行的。
在介绍自动化测试模型之前,我们试着来解释自动化测试库、框架和工具之间的区别。
库的英文单词加library,库是有代码集合成一个产品,供程序员调用,面向对象的代码组织形成的库叫类库,面向过程的代码组织形成的库叫函数库,所以从这个角度来看,我们以前学习的WebDriver就属于库的范畴,因为它提供了一组操作Web页面的类与方法,所以我们可以称它为Web自动化测试库。
框架的英文单词叫Framework,框架是为解决一个或一类问题而开发的产品,用户一般只需要使用框架提供的类或函数,即可实现全部功能,所以从这个角度来理解unittest框架,它主要用于实现测试用例的组织和执行,以及测试结果的生成,因为它的主要任务就是帮助我们完成测试工作,所以我们通常把它叫做单元测试框架。
工具的英文单词叫Tools,在笔者看来工具与框架所作的事情类似,只是工具会有更高的抽象,屏蔽了底层代码,一般会提供单独的操作界面供用户操作。例如,selenium IED和QTP就是自动化测试工具。
回到自动化测试模型的概念上,笔者认为自动化测试模型可以看作自动化测试框架与工具设计的思想。随着自动化测试技术的发展,演化为以下几种模型:线性测试、模块化驱动测试、数据却动测试和关键字驱动测试。
在后面几篇文章中我们一一介绍以上几种测试模型。
#------------------------------------------------我是可耻的分割线-------------------------------------------
线性测试
通过录制或编写对应程序的操作步骤产生相应的线性脚本,每个测试脚本相对独立,且不产生其他依赖与调用,这也是早期自动化测试的一种形式:他们其实就是单纯的来模拟用户完整的操作厂家。前几篇文章所用到的测试脚本都属于线性测试,如下代码:
from selenium import webdriver driver = webdriver.Chrome() driver.get("http://www.baidu.com") driver.find_element_by_id('kw').send_keys('selenium') driver.find_element_by_id('su').click() driver.quit()
这种模型的优势就是每一个脚本都是完整且独立的。所以,任何一个测试用例脚本拿出来都可以单独执行。当然,缺点也是相当明显,测试用例的开发与维护成本很高:
(1)开发成本很高,测试用例之间可能会存在重复的操作,不得不为每一个用例去录制或编写这些重复的操作。例如每个用例中重复的用户登录或退出操作等。
(2)维护成本很高,正是因为测试用例之间存着重复的操作,所以当这些重复的操作发生改变时,就需要逐一地对它们进行修改。例如登录输入库的定位发生了改变,就需要对每一个包含登录的用例进行调整。
模块化驱动测试
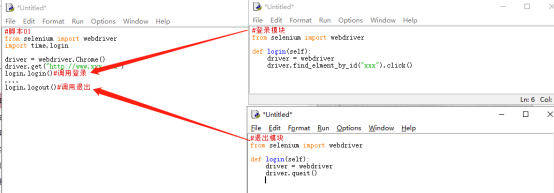
正是由于线性测试的缺陷非常明显,因此早期的自动化测试专家就考虑用新的自动化测试模型来代替线性测试。做法也很简单,借鉴了变成语言中模块化的思想,把重复的操作独立成公共模块,当用于执行过程中需要用到这一个模块操作时则被调用,这样就最大限度地消除了重复,从而提高测试用例的可维护性。
需要说明的是,早期的自动化测试以工具为主。
模块化的结构很好地解决了线性结构性的两个问题:
(1)提高了开发效率,不用重复编写相同的操作脚本。假如,已经写好了一个登录模块,后续测试用例在需要登录的地方调用即可。
(2)简化了维护的复杂性,加入登录按钮的定位发生了变化,那么只需要修改登录模块的脚本即可,对于所有调用登录模块的测试脚本来说不需要做任何修改。
数据驱动测试
虽然模块化驱动测试很好地解决了脚本的重复问题,但是,自动化测试脚本在开发的过程还是发现了诸多不便。例如,现在我要测试不同用户的登录,首先用的是“张三”的用户名登录;下一次测试用例要换成“李四”的用户名登录。在这种情况下,还是需要重复的编写登录脚本,因为虽然登录的步骤相同,但是登录所用的测试数据不同。
于是,数据驱动测试的概念就为了解决这类问题而被提出。从它的本意来解释,就是数据的改变从而驱动自动化测试的执行,最终引起测试结果的改变。这听上去的确是个高大上的概念,而在早期的商业自动化工具中,也的确把这一概念作为一个卖点。对于数据驱动所需要的测试数据,也是通过工具内置的Datapool管理。
如下代码所示,数据驱动说的直白点就是数据的参数化,因为输入数据的不同从而引起输出结果的不同。
#脚本01 from selenium import webdriver import time,info f = open('xxx.txt','r')#读取文件 u = f.read() driver = webdriver.Chrome() driver.get("http://www.xxx.com") driver,find_element_by_id('xxx').send_key(username) driver,find_element_by_id('xxx').send_key(password) ......
不管我们读取的是自定义数组、字典,或者是外都文件(excel、csv、txt、xml等),都可以看作是数据驱动,它的毛菊地就是实现数据与脚本的分离。
这样做的好处同样显而易见,它进一步增强了脚本的复用性。同样以登录为例,首先是重新设计登录模块,使其可以接收不同的数据,把接收到的数据作为登录操作的一部分,这样可以很好地适应相同操作、不同数据的情况。当指定登录用户是“张三”时,那么登录之后的结果就是“欢迎张三”;当指定登录用户是“李四”时,那么登录之后的结果就是“欢迎李四”。这就是数据驱动所希望达到的目的。
关键字驱动测试
理解了数据驱动后,无非是把“数据”换成了“关键字”,通过关键字的改变引起测试结果的改变。
目前市面上典型的关键字驱动工具以QTP(目前已更名为UFT-Unified Functional Testing)、Robot Framework(RIDE)工具为主。这类工具封装了底层的代码,提供给用户独立的图形界面,以“填表格”的形式免除测试人员对写代码的恐惧,从而降低脚本的编写难度,我们只需要使用工具所提供的关键字以“过程式”的方式来编写用例即可。
当然,Selenium家族中Selenium IDE也可以看作是一种传统的关键字驱动的自动化工具。
|
Baidu Test Case (Selenium IDE) |
||
|
open |
http://www.baidu.com |
|
|
type |
Id=kw |
selenium |
|
click |
Id=su |
|
上面的脚本由Selenium IDE录制产生,它把每一个动作分为三部分:
- 做什么?例如打开、输入、点击等操作。
- 对谁做?通过定位方式找到要操作的对象。
- 如何做?例如输入框输入的内容为“selenium”等。
当然,关键字驱动技术也在不断发展和进步。下面以功能更为强大的关键字驱动测试框架Robot Framework为例,它也可以像变成一样写测试用例。
- If分支语句
|
If(Robot Framework) |
||||
|
${a} |
Set variable |
2 |
|
|
|
${b} |
Set variable |
5 |
|
|
|
Run keyword if |
${a}>=1 |
log |
a大于1 |
|
|
... |
ELSE IF |
${b}>=1 |
log |
b小于或等于5 |
|
... |
ELSE |
log |
上面两个条件都不满足 |
|
首先,定义a,b两个变量,分别赋值2和5;然后,通过run keyword is关键字判断a是否大于或等于1,如果满足条件则通过Log输出“a大于或等于1”,否则继续判断b是否小于或等于5,如果满足条件则通过Log输出“b小于或等于5”。如果以上两个条件都不满足,则通过log输出“以上两个条件都不满足”。
- for循环
|
For(Robot Framework) |
||||
|
:FOR |
${I} |
in range |
10 |
|
|
|
log |
${i} |
|
|
这个例子很好理解,for循环i从1到10,没循环一次都通过log输出i的值。
- 读取外部文件
|
ReadFlie(Robot Framework) |
|
|
Import Resource |
${CURDIR;/resource.txt} |
|
Import Resource |
${CURDIR;/../resource//resource.html} |
通过Import Resource关键字读取指定的外部文件。
- import引入外部类库
|
Import(Robot Framework) |
||||
|
Import Libray |
MyLibrary |
|
|
|
|
Import Libray |
${CURDIR;/Libaray.py} |
csom |
args |
|
|
Import Libray |
${CURDIR;/../libs/Lib.java} |
arg |
WITHNAME |
JavaLib |
首先,定义a,b两个变量,分别赋值2和5;然后,通过run keyword is关键字判断a是否大于或等于1,如果满足条件则通过Log输出“a大于或等于1”,否则继续判断b是否小于或等于5,如果满足条件则通过Log输出“b小于或等于5”。如果以上两个条件都不满足,则通过log输出“以上两个条件都不满足”。
2.for循环
|
For(Robot Framework) |
||||
|
:FOR |
${I} |
in range |
10 |
|
|
|
log |
${i} |
|
|
这个例子很好理解,for循环i从1到10,没循环一次都通过log输出i的值。
3.读取外部文件
|
ReadFlie(Robot Framework) |
|
|
Import Resource |
${CURDIR;/resource.txt} |
|
Import Resource |
${CURDIR;/../resource//resource.html} |
通过Import Resource关键字读取指定的外部文件。
4.import引入外部类库
|
Import(Robot Framework) |
||||
|
Import Libray |
MyLibrary |
|
|
|
|
Import Libray |
${CURDIR;/Libaray.py} |
csom |
args |
|
|
Import Libray |
${CURDIR;/../libs/Lib.java} |
arg |
WITHNAME |
JavaLib |
通过Import Libray关键字引入外部文件,
关键字驱动也可以像写代码一样写用例,在变成的世界中,没有什么不能做;不过这样的用例同样需要较高的学习成本,与学习一门编程语言几乎相当。这样的框架越到后期越难维护,可靠性也会变差,关键字的用途与经验被局限在自己的框架内,你所学到的知识也很难用到其他地方。所以,从测试人员的经验与技术积累价值来讲,笔者更倾向于直接通过变成的方式开发自动化脚本。
这里简单介绍了几种测试模型的发展过程与特点,虽然时从自动化测试模型的发展顺序逐一介绍的,但他们并非后者淘汰前者的关系。在实际自动化实施过程中,应以项目需求为出发点,综合运用上述模型来开展自动化测试。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号