
hashmap里面hash计算疑问点
hashmap里面计算hash和放入数组中的计算疑问点:
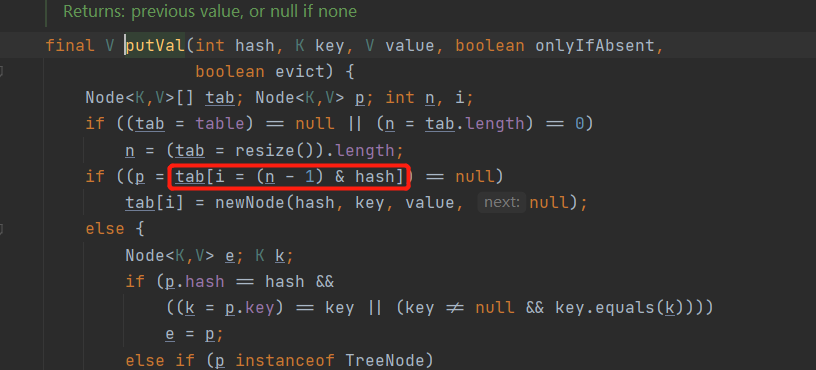
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
1:疑问一,为什么计算不用% ,而是这么写的 i = (n - 1) & hash
今天重点:为什么 hash & (n - 1) = hash % n ??
3556516 转化成二进制是 11 0110 0100 0100 1010 0100
3556516 & 7 结果是,二进制的后三位
3556516 % 8结果也是,二进制的后三位
先说说 3556516 & 7 =二进制的后三位

7=23-1,二进制,最后三位是1,其余全部是0(前面说过,n是2的次方,n-1的二进制一定满足,后面全是1,前面全是0)
& 运算的性质,两者同是1得1,否则得0,
那细想下,3556516 & 7,得到的不就是3556516的二进制的后三位么。这个不懂仔细想想,画画。
至此,3556516 & 7 结果是,二进制的后三位这个就讲完了,
即 3556516 & 7= 4(也就是3556516 二进制的最后三位100)
再说说3556516 % 8=二进制的后三位
先看这两个式子
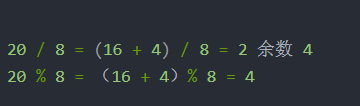
这两个式子,相信大家应该能看懂,20 % 8,把20分成两部分,一部分能整除8,另一部分小于8,肯定就是余数了。
20的二进制 = 10100
二进制转化十进行是这么计算的
10100 = 1 * 24 + 0 * 23 + 1 * 22 + 0 * 21 + 0 * 20 = (1 * 24 + 0 * 23) + (1 * 22 + 0 * 21 + 0 * 20)
20 % 8 = (16 + 4)% 8 = 4 如果这个你懂了的话,上面那上二进制的式子中,第一个括号里的肯定能被8整除,第二个括号里的就是余数。
即:20 % 8 = 二进制10100的后三位。3556516 % 8=二进制的后三位是一个道理。
好了,费了这么大的劲儿,终于解释了
hash & (n - 1) = hash % n
为什么用hash & (n - 1) ,而不是用 hash % n
HashMap 中的哈希函数 hash & (n - 1) 跟取余运算 hash % n 结果是一致的。那它为什么不直接用取余运算呢?
答案两个字——性能。
————————————————
2:疑问二,hash(Object key)原理,为什么(hashcode >>> 16)
由于和(length-1)运算,length 绝大多数情况小于2的16次方。所以始终是hashcode 的低16位(甚至更低)参与运算。要是高16位也参与运算,会让得到的下标更加散列。
所以这样高16位是用不到的,如何让高16也参与运算呢。所以才有hash(Object key)方法。让他的hashCode()和自己的高16位^运算。
所以(h >>> 16)得到他的高16位与hashCode()进行^运算
为什么用^而不用&和|
因为&和|都会使得结果偏向0或者1 ,并不是均匀的概念,所以用^。
这就是为什么有hash(Object key)的原因。
补充一些 为什么0和1结果用^ 更均匀,
-
0000 0100 1011 0011 1101 1111 1110 0001 -
>>> 16 -
0000 0000 0000 0000 0000 0100 1011 0011
hashcode为int类型,4个字节32位,为了确保散列性,肯定是32位都能进行散列算法计算是最好的。
首先要明白,为什么用亦或计算,二进制位计算,a 只可能为0,1,b只可能为0,1。a中0出现几率为1/2,1也是1/2,b同理。
位运算符有三种,|,&,……,或,与,亦或。 a,b进行位运算,有4种可能 00,01,10,11 a或b计算 结果为1的几率为3/4,0的几率为1/4 a与b计算 结果为0的几率为3/4,1的几率为1/4, a亦或b计算 结果为1的几率为1/2,0的几率为1/2 所以,进行亦或计算,得到的结果肯定更为平均,不会偏向0或者偏向1,更为散列。
右移16位进行亦或计算,我将其拆分为两部分,前16位的亦或运算,和后16位的亦或运算, 后16位的亦或运算,即原hashcode后16位与原hashcode前16位进行亦或计算,得出的结果,前16位和后16位都有参与其中,保证了 32位全部进行计算。 前16位的亦或运算,即原hasecode前16位与0000 0000 0000 0000进行亦或计算,结果只与前16位hashcode有关,同时亦或计算,保证 结果为0的几率为1/2,1的几率为1/2,也是平均的。
所以为什么是右移16位,个人觉得博主说的原因是一部分, 也有一个原因是右移16位进行亦或计算的结果中, (1)结果的后16位保证了hashcode32位全部参与计算,也保证了0,1平均,散列性 (2)结果的前16位保证hashcode前16位了0,1平均散列性,附带hashcode前16位参与计算。 (3) 16与16位数相同,利于计算,不需要补齐,移去位数数据 更多情况,hashmap只会用到前16位(临时数据一般不会这么大),所以(1)占主因

