ForkJoinPool
fork():开启一个新线程(或是重用线程池内的空闲线程),将任务交给该线程处理。join():等待该任务的处理线程处理完毕,获得返回值。
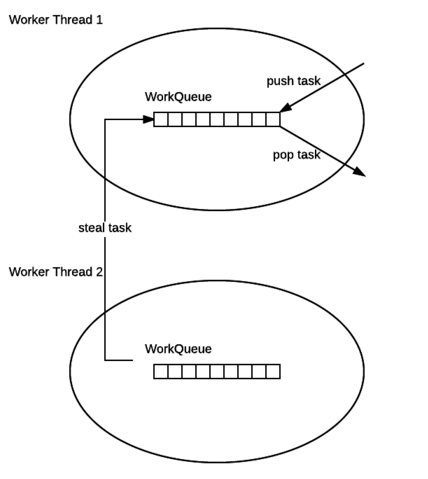
ForkJoinPool 的每个工作线程都维护着一个工作队列(WorkQueue),这是一个双端队列(Deque),里面存放的对象是任务(ForkJoinTask)。
每个工作线程在运行中产生新的任务(通常是因为调用了 fork())时,会放入工作队列的队尾,并且工作线程在处理自己的工作队列时,使用的是 LIFO 方式,也就是说每次从队尾取出任务来执行。
每个工作线程在处理自己的工作队列同时,会尝试窃取一个任务(或是来自于刚刚提交到 pool 的任务,或是来自于其他工作线程的工作队列),窃取的任务位于其他线程的工作队列的队首,也就是说工作线程在窃取其他工作线程的任务时,使用的是 FIFO 方式。
在遇到 join() 时,如果需要 join 的任务尚未完成,则会先处理其他任务,并等待其完成。
在既没有自己的任务,也没有可以窃取的任务时,进入休眠。
fork
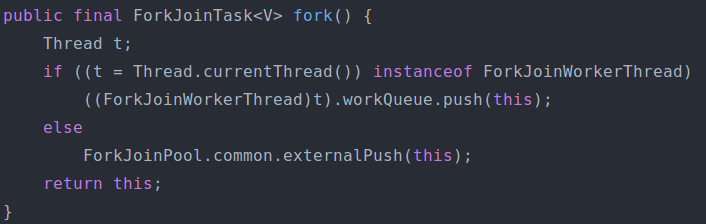
fork() 做的工作只有一件事,既是把任务推入当前工作线程的工作队列里。可以参看以下的源代码:
join
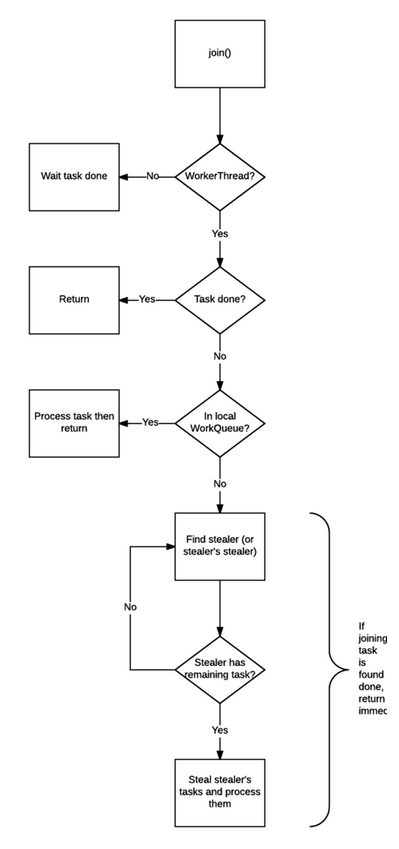
join() 的工作则复杂得多,也是 join() 可以使得线程免于被阻塞的原因——不像同名的 Thread.join()。
1.检查调用 join() 的线程是否是 ForkJoinThread 线程。如果不是(例如 main 线程),则阻塞当前线程,等待任务完成。如果是,则不阻塞。
2.查看任务的完成状态,如果已经完成,直接返回结果。
3.如果任务尚未完成,但处于自己的工作队列内,则完成它。
4.如果任务已经被其他的工作线程偷走,则窃取这个小偷的工作队列内的任务(以 FIFO 方式),执行,以期帮助它早日完成欲 join 的任务。
5.如果偷走任务的小偷也已经把自己的任务全部做完,正在等待需要 join 的任务时,则找到小偷的小偷,帮助它完成它的任务。
6.递归地执行第5步。
以上就是 fork() 和 join() 的原理,这可以解释 ForkJoinPool 在递归过程中的执行逻辑,但还有一个问题
最初的任务是 push 到哪个线程的工作队列里的?
这就涉及到 submit() 函数的实现方法了
其实除了前面介绍过的每个工作线程自己拥有的工作队列以外,ForkJoinPool 自身也拥有工作队列,这些工作队列的作用是用来接收由外部线程(非 ForkJoinThread 线程)提交过来的任务,而这些工作队列被称为 submitting queue 。
submit() 和 fork() 其实没有本质区别,只是提交对象变成了 submitting queue 而已(还有一些同步,初始化的操作)。submitting queue 和其他 work queue 一样,是工作线程”窃取“的对象,因此当其中的任务被一个工作线程成功窃取时,就意味着提交的任务真正开始进入执行阶段。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号