



分析 ajax 请求并抓取 “今日头条的街拍图”
今日头条抓取页面:
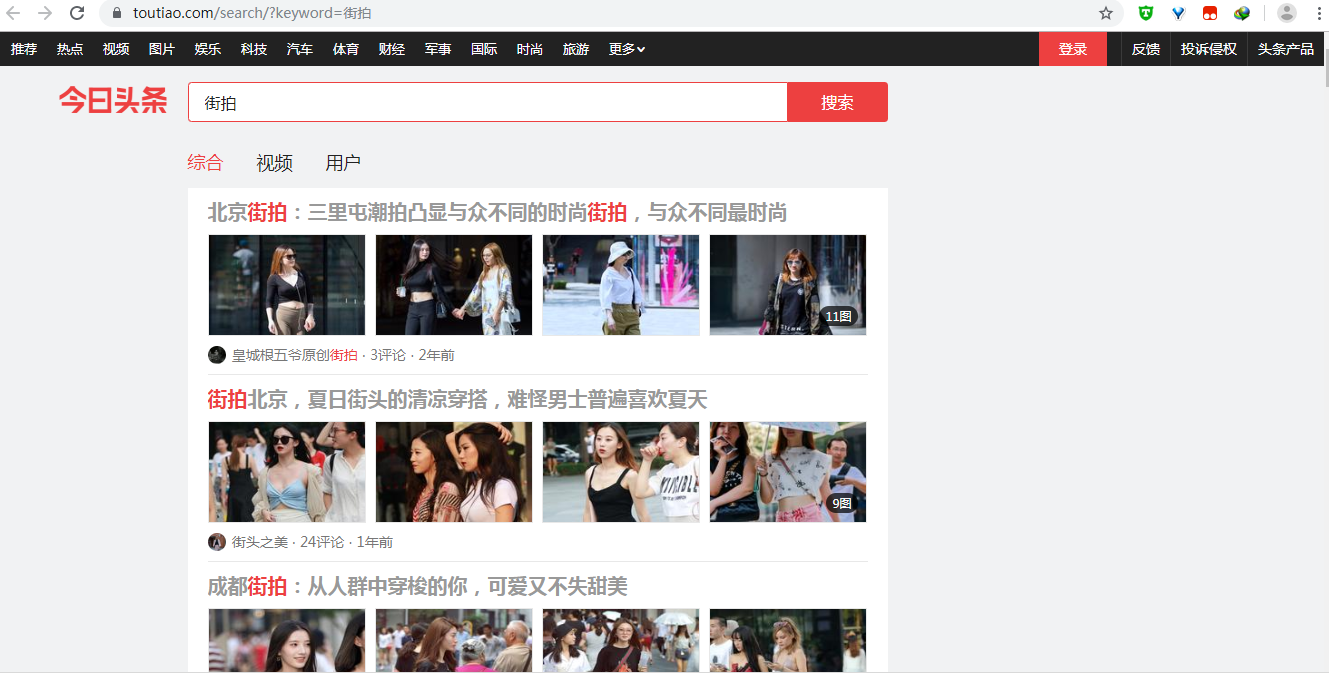
分析街拍页面的 ajax 请求:
通过在 XHR 中查看内容,获取 url 链接,params 参数信息,将两者进行拼接后取得完整 url 地址。data 中的 article_url 为各详情页的链接地址。
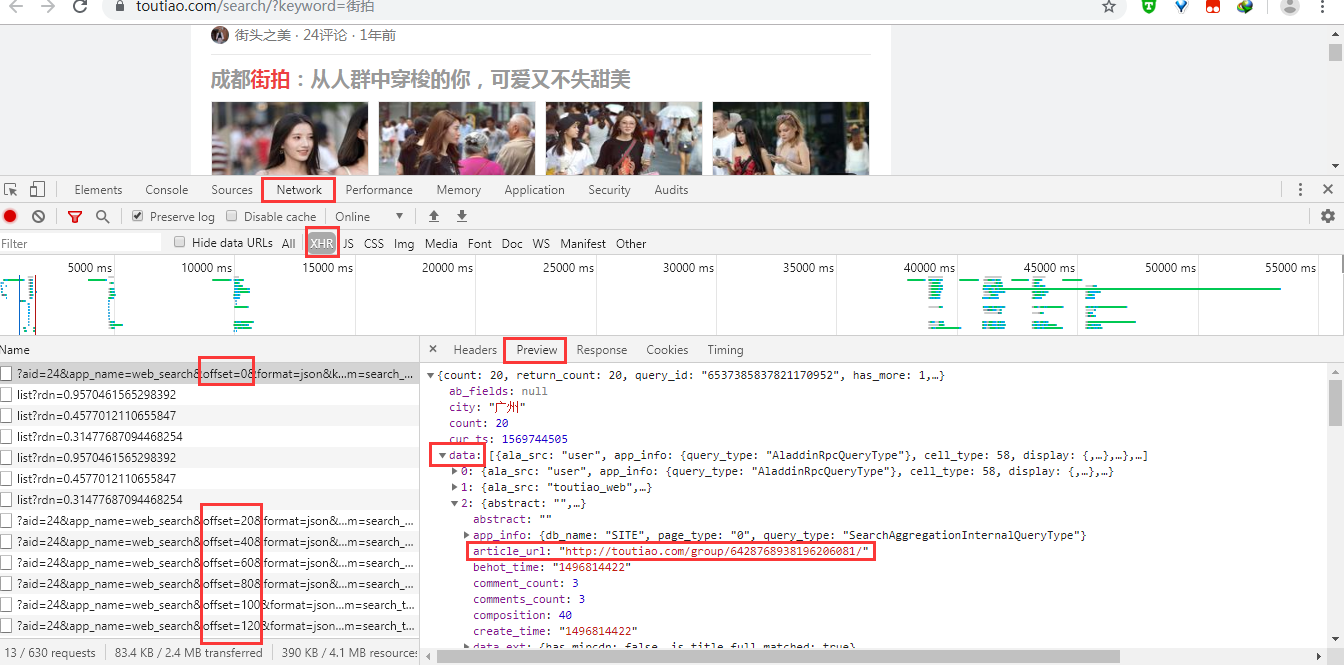
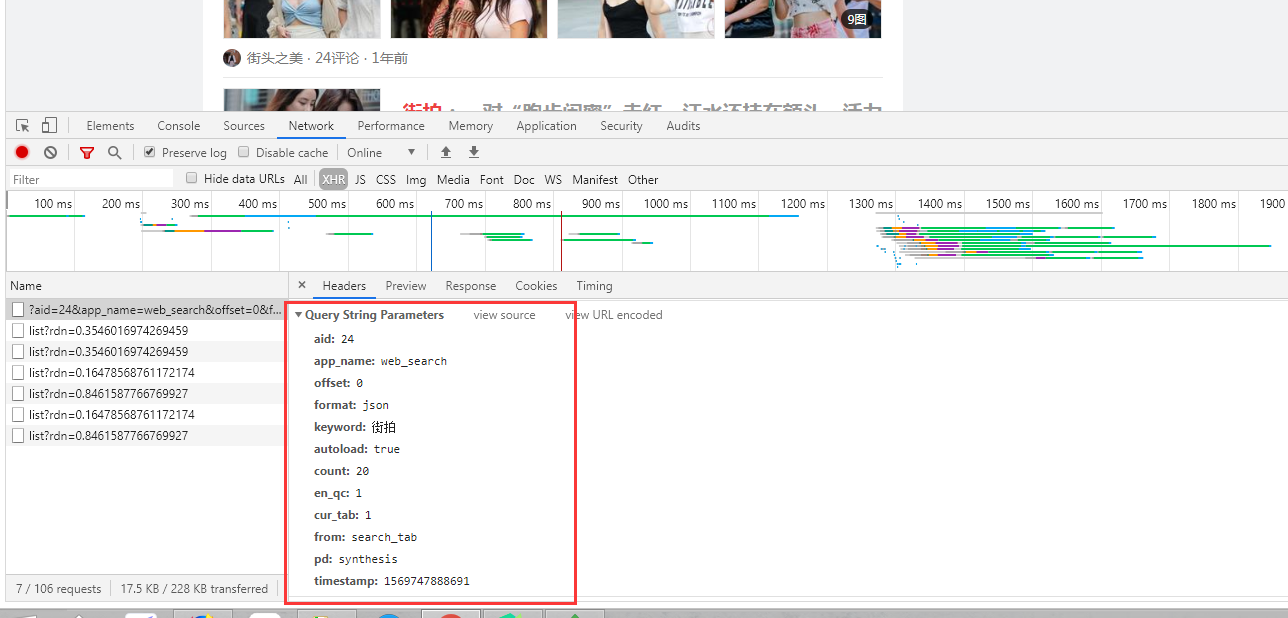
代码显示:


1 # 获取街拍页面; 2 def one_page_index(offset, keyword, headers): 3 params = { 4 'aid': 24, 5 'app_name': 'web_search', 6 'offset': offset, 7 'format': 'json', 8 'keyword': keyword, 9 'autoload': 'true', 10 'count': 20, 11 'en_qc': 1, 12 'cur_tab': 1, 13 'from': 'search_tab', 14 'pd': 'synthesis', 15 } 16 url = "https://www.toutiao.com/api/search/content/?" + urlencode(params) 17 try: 18 response = requests.get(url, headers=headers) 19 if response.status_code == 200: 20 return response.text 21 return None 22 except RequestException: 23 print('请求索引页出错!') 24 return None
1 # 解析街拍页面的信息; 2 def parse_one_page(html): 3 data = json.loads(html) 4 if data and 'data' in data.keys(): 5 for item in data.get('data'): 6 yield item.get('article_url')
详情页的解析:
需将获取到的数据进行格式调整;
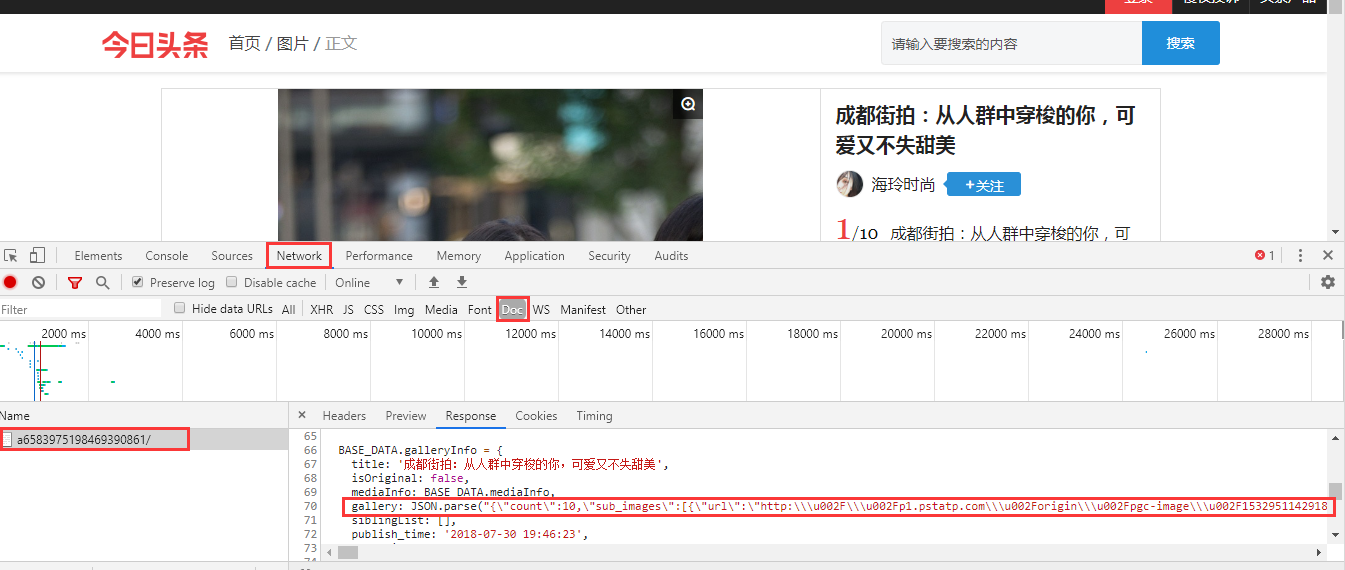
代码显示:
1 def parse_detail(html, url): 2 soup = BeautifulSoup(html, 'lxml') 3 title = soup.select('title')[0].get_text() 4 image_pattern = re.compile('gallery: JSON.parse\("(.*)"\)', re.S) 5 result = re.search(image_pattern, html) 6 if result: 7 # group(1)即为第一个括号里面的内容; 8 # 将获取的数据格式进行调整; 9 newResult = result.group(1).replace("\\\\u002F", '\/') 10 newResult = newResult.replace("\\", '') 11 data = json.loads(newResult) 12 if data and 'sub_images' in data.keys(): 13 sub_images = data.get('sub_images') 14 images = [item.get('url') for item in sub_images] 15 for image in images: download_image(image) 16 return { 17 "title": title, 18 "url": url, 19 "images": images 20 }
例外:
在街拍主页中,有些网页的内容不是图集,而是在单个页面中显示所有的图片,其解析的内容与图集形式的网页内容不同,无法正常解析出内容,会获取 None 。在写入数据库时需进行判断。
最后将抓取的数据保存到 MongoDB 数据库中,且将图片保存到本地文件中。

完整代码:
1 # config.py 文件 2 3 MONGO_URL = "localhost" 4 MONGO_DB = 'toutiao' 5 MONGO_TABLE = 'toutiao' 6 7 GROUP_START = 1 8 GROUP_END = 20 9 KEYWORLD = '街拍'
1 import json 2 import os 3 import re 4 from hashlib import md5 5 from urllib.parse import urlencode 6 import pymongo 7 from bs4 import BeautifulSoup 8 from requests.exceptions import RequestException 9 import requests 10 from toutiao.config import * 11 from multiprocessing import Pool 12 13 14 client = pymongo.MongoClient(MONGO_URL) 15 db = client[MONGO_DB] 16 17 # 获取街拍页面; 18 def one_page_index(offset, keyword, headers): 19 params = { 20 'aid': 24, 21 'app_name': 'web_search', 22 'offset': offset, 23 'format': 'json', 24 'keyword': keyword, 25 'autoload': 'true', 26 'count': 20, 27 'en_qc': 1, 28 'cur_tab': 1, 29 'from': 'search_tab', 30 'pd': 'synthesis', 31 } 32 url = "https://www.toutiao.com/api/search/content/?" + urlencode(params) 33 try: 34 response = requests.get(url, headers=headers) 35 if response.status_code == 200: 36 return response.text 37 return None 38 except RequestException: 39 print('请求索引页出错!') 40 return None 41 42 43 # 获取街拍各详情页的信息; 44 def get_detail_page(url, headers): 45 try: 46 response = requests.get(url, headers=headers) 47 if response.status_code == 200: 48 return response.text 49 return None 50 except RequestException: 51 print('请求详情页出错!') 52 return None 53 54 55 # 解析街拍页面的信息; 56 def parse_one_page(html): 57 data = json.loads(html) 58 if data and 'data' in data.keys(): 59 for item in data.get('data'): 60 yield item.get('article_url') 61 62 63 # 街拍各详情页的解析; 64 # 使用正则解析数据; 65 def parse_detail(html, url): 66 soup = BeautifulSoup(html, 'lxml') 67 title = soup.select('title')[0].get_text() 68 image_pattern = re.compile('gallery: JSON.parse\("(.*)"\)', re.S) 69 result = re.search(image_pattern, html) 70 if result: 71 # group(1)即为第一个括号里面的内容; 72 # 将获取的数据格式进行调整; 73 newResult = result.group(1).replace("\\\\u002F", '\/') 74 newResult = newResult.replace("\\", '') 75 data = json.loads(newResult) 76 if data and 'sub_images' in data.keys(): 77 sub_images = data.get('sub_images') 78 images = [item.get('url') for item in sub_images] 79 for image in images: download_image(image) 80 return { 81 "title": title, 82 "url": url, 83 "images": images 84 } 85 86 87 # 下载图片; 88 def download_image(url): 89 print('正在下载', url) 90 try: 91 response = requests.get(url) 92 if response.status_code == 200: 93 # 返回图片使用content; 94 save_image(response.content) 95 return None 96 return None 97 except RequestException: 98 print('请求图片出错!') 99 return None 100 101 102 # 将图片保存到本地; 103 # 使用md5形式的文件名,内容相同的md5值也相同,防止下载重复的图片; 104 def save_image(content): 105 file_path = '{0}/{1}.{2}'.format(os.getcwd(), md5(content).hexdigest(), 'jpg') 106 if not os.path.exists(file_path): 107 with open(file_path, 'wb') as f: 108 f.write(content) 109 f.close() 110 111 112 # 将数据存储到MongoDB中; 113 # 某些网页的图片全部在单页中显示,代码与图集形式显示的网页不同,解析会匹配不到内容,无法插入数据库; 114 def save_to_mongodb(result): 115 if result and db[MONGO_TABLE].insert(result): 116 print('存储到MongoDB成功', result) 117 return True 118 return False 119 120 121 def main(offset): 122 headers = { 123 "User-Agent": 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36', 124 "cookie": 'tt_webid=6741657574736889357; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6741657574736889357; csrftoken=9e7ac598957d2ec36c80c6f1e05b9622; s_v_web_id=2ab2b8ff35fc91cacdec489ca9a5570f; __tasessionId=d6osr6e6r1569719745562; UM_distinctid=16d7a9f7f4724e-0d4cc2a69d799-3c375d0d-100200-16d7a9f7f4a4f1' 125 } 126 html = one_page_index(offset, KEYWORLD, headers) 127 for url in parse_one_page(html): 128 if url: 129 html = get_detail_page(url, headers) 130 result = parse_detail(html, url) 131 save_to_mongodb(result) 132 133 # 运行; 134 if __name__ == '__main__': 135 groups = [x * 20 for x in range(GROUP_START, GROUP_END + 1)] 136 Pool = Pool() 137 Pool.map(main, groups)

