
我的天啊:字符编码
我的天啊:字符编码
首先声明,只讲大概,不说历史发展,不说字符编码占的长度等等。。。。
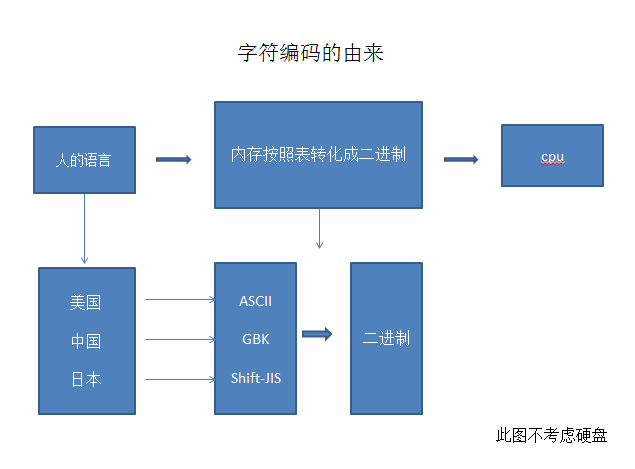
一、字符编码的由来
计算机硬件都是靠二进制交流的,因此,我们向计算机发出的指令也必须是二进制。这就是机器语言的由来,但是太麻烦了,,于是就制定出来一个按照我们输入的字符自动转化成计算机识别的二进制的一张表,每次我们输入的字符,内存按照表来转化成二进制数,这样就减轻我们的工作量了。
但是问题又来了,我们人类的语言也不相同啊,于是世界上就出来好几种表,每个语言都有自己的对照表了。比如美国的ascii码表,中国的gbk表等等等等。
二、字符编码的发展
现在大家都是地球村的村民了,计算机也都连在一起了,这个时候出现问题了。
按照对方的表来翻译自己的语言,结果就变得谁都不知道这是啥玩意了啊!!!!于是万国码表unicode就闪亮登场了。
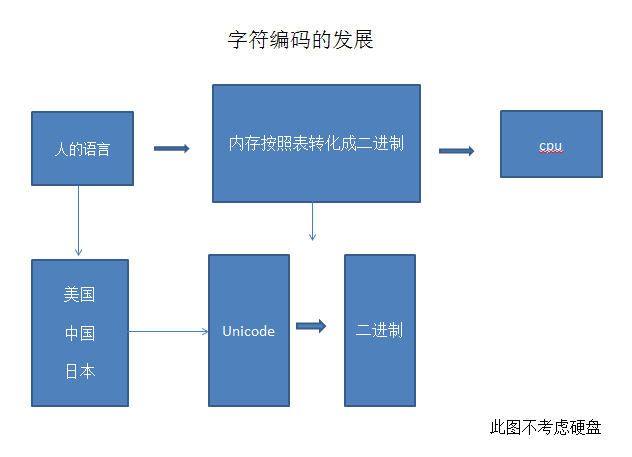
自此以后,地球村村民过上了幸福快乐的日子。全剧终。。
谢谢观看,下次再见。。。。再见再见你个鬼啊,上面就是特么太监版的字符编码啊。。。。
三、字符编码详解
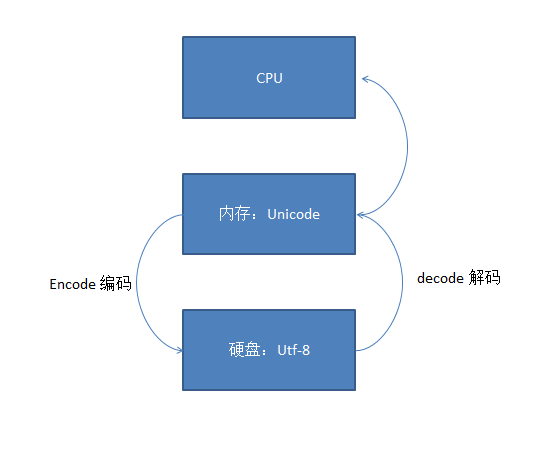
上面只是大概了解了,现在进行全面剖析,首先我们要清楚有关软件运行的三大核心硬件间的关系。
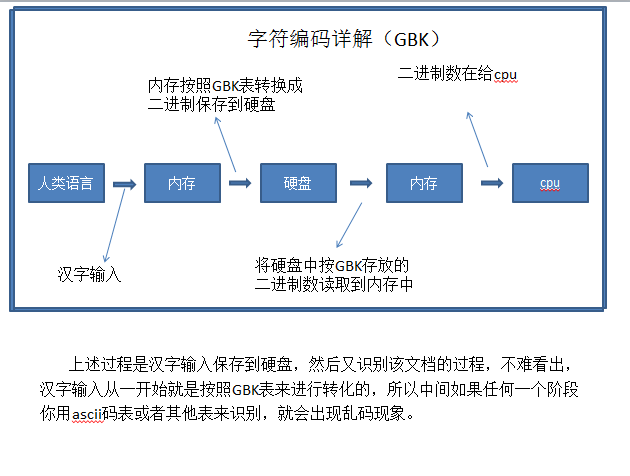
所以这就是乱码的由来。所以大兄弟,一定要记得
你按照什么表存进去的,你就按什么表取出来*
后来,unicode表被地球村村民整出来了,号召所有内存用这个表来识别语言。
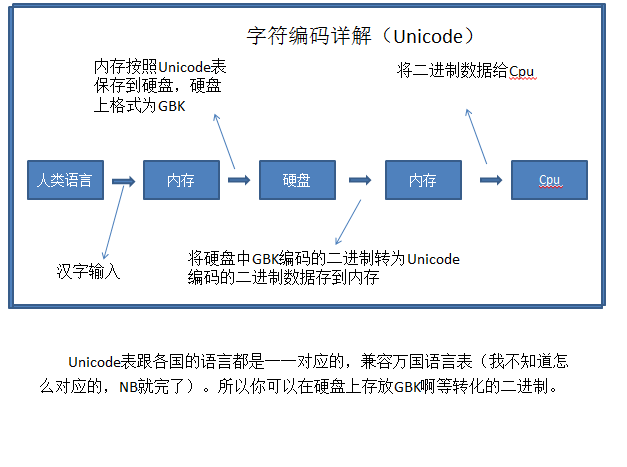
然后发现,某个小国家仰慕中国文化,想在文章中加点中国字符,彰显自己的风度,结果发现:不行啊,识别不出来中国字符啊,装逼失败了很尴尬的啊。于是就研究出来了utf-8。当我们把硬盘上存放的格式改为utf-8时,在用Unicode读出来,可以显示多国的语言。
要记得,把文件存成utf-8是历史的进步,存成ascii码等是历史的退步,utf-8终究是历史发展的方向。

