python开发concurent.furtrue模块:concurent.furtrue的多进程与多线程&协程
一,concurent.furtrue进程池和线程池
1.1 concurent.furtrue 开启进程,多进程&线程,多线程
1 # concurrent.futures创建并行的任务 2 # 进程池 ProcessPoolExecutor,ThreadPoolExecutor 3 # 下面例子是Io密集型,所以时间上比叫多 4 from concurrent.futures import ProcessPoolExecutor 5 import os,time,random 6 def task(n): 7 print('%s is running' %os.getpid()) 8 time.sleep(2) 9 return n**2 10 11 # if __name__ == '__main__': 12 # p=ProcessPoolExecutor(max_workers=4) #进程池 max_workers最大的工作任务 13 # l=[] 14 # start=time.time() 15 # for i in range(10): 16 # obj=p.submit(task,i) #submit 异步提交,后面加入.result就变成同步了 17 # l.append(obj) 18 # p.shutdown() #shutdown(wait=True) == p.close + p.join 19 # print('='*30) 20 # print([obj for obj in l]) #结果内存地址 21 # print([obj.result() for obj in l]) 22 # print(time.time()-start) 23 24 25 #线程池,用线程来探测上面的例子,时间少了很多 26 from concurrent.futures import ThreadPoolExecutor 27 import threading 28 import os,time 29 def task(n): 30 print('%s:%s is running' %(threading.currentThread().getName(),os.getpid())) 31 time.sleep(2) 32 return n**2 33 34 # if __name__ == '__main__': 35 # p=ThreadPoolExecutor() #线程池 max_workers=20 一个进程多少线程,默认线程cpu的个数乘以5 36 # l=[] 37 # start=time.time() 38 # for i in range(10): 39 # obj=p.submit(task,i).result() 40 # l.append(obj) 41 # p.shutdown() 42 # print('='*30) 43 # print([obj.result() for obj in l]) 44 # print(time.time()-start) 45 46 47 #p.submit(task,i).result()即同步执行,进程池,线程池都有 48 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 49 import os,time,random 50 def task(n): 51 print('%s is running' %os.getpid()) 52 time.sleep(2) 53 return n**2 54 55 # if __name__ == '__main__': 56 # p=ProcessPoolExecutor() 57 # start=time.time() 58 # for i in range(10): 59 # res=p.submit(task,i).result() #同步执行 60 # print(res) 61 # print('='*30) 62 # print(time.time()-start)
1.2 concurrent.futures map方法
1 # concurrent的方法map,前面是一个函数,后面是一个可迭代对象 2 from concurrent.futures import ProcessPoolExecutor 3 import os,time,random 4 def task(n): 5 print('%s is running' %os.getpid()) 6 time.sleep(2) 7 return n**2 8 9 if __name__ == '__main__': 10 p=ProcessPoolExecutor() 11 obj=p.map(task,range(10)) 12 p.shutdown() 13 print('='*30) 14 print(list(obj)) 15 16 17 # 上面的例子改成map 18 # if __name__ == '__main__': 19 # p=ThreadPoolExecutor() #线程池 max_workers=20 一个进程多少线程,默认线程cpu的个数乘以5 20 # l=[] 21 # for i in range(10): 22 # obj=p.submit(task,i).result() 23 # l.append(obj) 24 # p.shutdown() 25 # print([obj.result() for obj in l]) 26 27 28 # if __name__ == '__main__': 29 # p=ThreadPoolExecutor() #线程池 max_workers=20 一个进程多少线程,默认线程cpu的个数乘以5 30 # obj = p.map(task,range(10)) 就可以了 31 # p.shutdown() 32 # print(list(obj)) 33 34 # *** 没法得到其中一个,因为是迭代器,而且这个东西没有回调函数,只是提交任务的话Map最好
1.3 concurrent.futures 爬网页例子
1 from concurrent.futures import ProcessPoolExecutor,ThreadPoolExecutor 2 import requests 3 import os 4 import time 5 from threading import currentThread 6 def get_page(url): 7 print('%s:<%s> is getting [%s]' %(currentThread().getName(),os.getpid(),url)) 8 response=requests.get(url) 9 time.sleep(2) 10 return {'url':url,'text':response.text} 11 def parse_page(res): 12 res=res.result() #参数传过来是对象,所以需要得到结果 13 print('%s:<%s> parse [%s]' %(currentThread().getName(),os.getpid(),res['url'])) 14 with open('db.txt','a') as f: 15 parse_res='url:%s size:%s\n' %(res['url'],len(res['text'])) 16 f.write(parse_res) 17 if __name__ == '__main__': 18 # p=ProcessPoolExecutor() 19 p=ThreadPoolExecutor() 20 urls = [ 21 'https://www.baidu.com', 22 'https://www.baidu.com', 23 'https://www.baidu.com', 24 'https://www.baidu.com', 25 'https://www.baidu.com', 26 'https://www.baidu.com', 27 ] 28 29 for url in urls: 30 # multiprocessing.pool_obj方式:p.apply_async(get_page,args=(url,),callback=parse_page),这是自己调用get得到结果给回掉函数 31 p.submit(get_page, url).add_done_callback(parse_page) #回掉函数,前面的结果就是参数,这个参数是对象,所以需要get 32 # p.map(get_page,urls) map写法 33 p.shutdown() 34 print('主',os.getpid())
二,协程
一 引子
本节的主题是基于单线程来实现并发,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发,为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长
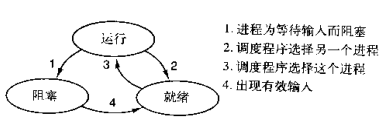
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
#1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级 #2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换


#串行执行
import time
def consumer(res):
'''任务1:接收数据,处理数据'''
pass
def producer():
'''任务2:生产数据'''
res=[]
for i in range(10000000):
res.append(i)
return res
start=time.time()
#串行执行
res=producer()
consumer(res)
stop=time.time()
print(stop-start) #1.5536692142486572
#基于yield并发执行
import time
def consumer():
'''任务1:接收数据,处理数据'''
while True:
x=yield
def producer():
'''任务2:生产数据'''
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
start=time.time()
#基于yield保存状态,实现两个任务直接来回切换,即并发的效果
#PS:如果每个任务中都加上打印,那么明显地看到两个任务的打印是你一次我一次,即并发执行的.
producer()
stop=time.time()
print(stop-start) #2.0272178649902344
而在任务一遇到io情况下,切到任务二去执行,这样就可以利用任务一阻塞的时间完成任务二的计算,效率的提升就在于此。
import time
def consumer():
'''任务1:接收数据,处理数据'''
while True:
x=yield
def producer():
'''任务2:生产数据'''
g=consumer()
next(g)
for i in range(10000000):
g.send(i)
time.sleep(2)
start=time.time()
producer() #并发执行,但是任务producer遇到io就会阻塞住,并不会切到该线程内的其他任务去执行
stop=time.time()
print(stop-start)
对于单线程下,我们不可避免程序中出现io操作,但如果我们能在自己的程序中(即用户程序级别,而非操作系统级别)控制单线程下的多个任务能在一个任务遇到io阻塞时就切换到另外一个任务去计算,这样就保证了该线程能够最大限度地处于就绪态,即随时都可以被cpu执行的状态,相当于我们在用户程序级别将自己的io操作最大限度地隐藏起来,从而可以迷惑操作系统,让其看到:该线程好像是一直在计算,io比较少。
协程的本质就是在单线程下,由用户自己控制一个任务遇到io阻塞了就切换另外一个任务去执行,以此来提升效率。
因此我们需要找寻一种可以同时满足以下条件的解决方案:
1. 可以控制多个任务之间的切换,切换之前将任务的状态保存下来,以便重新运行时,可以基于暂停的位置继续执行。
2. 作为1的补充:可以检测io操作,在遇到io操作的情况下才发生切换
二 协程介绍
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。、
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) #2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
- 必须在只有一个单线程里实现并发
- 修改共享数据不需加锁
- 用户程序里自己保存多个控制流的上下文栈
- 附加:一个协程遇到IO操作自动切换到其它协程(如何实现检测IO,yield、greenlet都无法实现,就用到了gevent模块(select机制))
三 Greenlet
如果我们在单个线程内有20个任务,要想实现在多个任务之间切换,使用yield生成器的方式过于麻烦(需要先得到初始化一次的生成器,然后再调用send。。。非常麻烦),而使用greenlet模块可以非常简单地实现这20个任务直接的切换
#安装 pip3 install greenlet

from greenlet import greenlet
def eat(name):
print('%s eat 1' %name)
g2.switch('egon')
print('%s eat 2' %name)
g2.switch()
def play(name):
print('%s play 1' %name)
g1.switch()
print('%s play 2' %name)
g1=greenlet(eat)
g2=greenlet(play)
g1.switch('egon')#可以在第一次switch时传入参数,以后都不需要
单纯的切换(在没有io的情况下或者没有重复开辟内存空间的操作),反而会降低程序的执行速度
#顺序执行
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print('run time is %s' %(stop-start)) #10.985628366470337
#切换
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print('run time is %s' %(stop-start)) # 52.763017892837524
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
四 Gevent介绍
#安装 pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
#用法 g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
遇到IO阻塞时会自动切换任务
import gevent
def eat(name):
print('%s eat 1' %name)
gevent.sleep(2)
print('%s eat 2' %name)
def play(name):
print('%s play 1' %name)
gevent.sleep(1)
print('%s play 2' %name)
g1=gevent.spawn(eat,'egon')
g2=gevent.spawn(play,name='egon')
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print('主')
上例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,
而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
from gevent import monkey;monkey.patch_all()
import gevent
import time
def eat():
print('eat food 1')
time.sleep(2)
print('eat food 2')
def play():
print('play 1')
time.sleep(1)
print('play 2')
g1=gevent.spawn(eat)
g2=gevent.spawn(play_phone)
gevent.joinall([g1,g2])
print('主')
我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程
五 Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print('Task %s done' % pid)
def synchronous():
for i in range(10):
task(i)
def asynchronous():
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
if __name__ == '__main__':
print('Synchronous:')
synchronous()
print('Asynchronous:')
asynchronous()
#上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,后者阻塞当前流程,并执行所有给定的greenlet。执行流程只会在 所有greenlet执行完后才会继续向下走。
六 Gevent之应用举例一
from gevent import monkey;monkey.patch_all()
import gevent
import requests
import time
def get_page(url):
print('GET: %s' %url)
response=requests.get(url)
if response.status_code == 200:
print('%d bytes received from %s' %(len(response.text),url))
start_time=time.time()
gevent.joinall([
gevent.spawn(get_page,'https://www.python.org/'),
gevent.spawn(get_page,'https://www.yahoo.com/'),
gevent.spawn(get_page,'https://github.com/'),
])
stop_time=time.time()
print('run time is %s' %(stop_time-start_time))
七 Gevent之应用举例二
通过gevent实现单线程下的socket并发(from gevent import monkey;monkey.patch_all()一定要放到导入socket模块之前,否则gevent无法识别socket的阻塞)
from gevent import monkey;monkey.patch_all()
from socket import *
import gevent
#如果不想用money.patch_all()打补丁,可以用gevent自带的socket
# from gevent import socket
# s=socket.socket()
def server(server_ip,port):
s=socket(AF_INET,SOCK_STREAM)
s.setsockopt(SOL_SOCKET,SO_REUSEADDR,1)
s.bind((server_ip,port))
s.listen(5)
while True:
conn,addr=s.accept()
gevent.spawn(talk,conn,addr)
def talk(conn,addr):
try:
while True:
res=conn.recv(1024)
print('client %s:%s msg: %s' %(addr[0],addr[1],res))
conn.send(res.upper())
except Exception as e:
print(e)
finally:
conn.close()
if __name__ == '__main__':
server('127.0.0.1',8080)
服务端
#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
from socket import *
client=socket(AF_INET,SOCK_STREAM)
client.connect(('127.0.0.1',8080))
while True:
msg=input('>>: ').strip()
if not msg:continue
client.send(msg.encode('utf-8'))
msg=client.recv(1024)
print(msg.decode('utf-8'))
from threading import Thread
from socket import *
import threading
def client(server_ip,port):
c=socket(AF_INET,SOCK_STREAM) #套接字对象一定要加到函数内,即局部名称空间内,放在函数外则被所有线程共享,则大家公用一个套接字对象,那么客户端端口永远一样了
c.connect((server_ip,port))
count=0
while True:
c.send(('%s say hello %s' %(threading.current_thread().getName(),count)).encode('utf-8'))
msg=c.recv(1024)
print(msg.decode('utf-8'))
count+=1
if __name__ == '__main__':
for i in range(500):
t=Thread(target=client,args=('127.0.0.1',8080))
t.start()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号