《从机器学习到深度学习》笔记(4)划分数据集
任何机器学习算法都是基于对已有数据集或环境的信息挖掘,要求将从现有数据学习得到的模型能够适配于未来的新数据。
1. 训练集(Training set)与测试集(Test set)
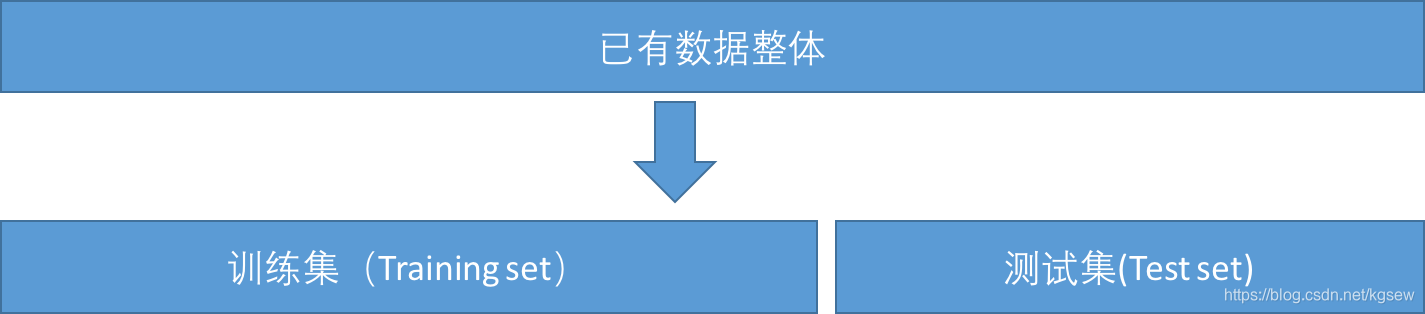
很自然的,在评估模型能力的时候需要采用与模型训练时不同的数据集,因此在训练模型之前需要将已有数据集划分成如图1-13的两部分。
![]()
图1-13 训练集与测试集
顾名思义,图中的训练集用于在训练模型时使用,测试集用于评估模型准确率。一般训练集与测试集一旦划分就无需再变动,因为只有稳定的测试集才能用来衡量不同模型的准确率。一旦重新划分两个集合,那么需要重新训练所有模型并在新的测试集上进行评估。
2. 随机采样(Random Sampling)
一般来说两个集合的划分需加入随机因子,使得每个数据项有相等的机会被分到任一集合中。如不加入随机因子,可能出现类似这样的问题:
数据整体是一年的按时间排序的皮大衣销售数据。不用随机采样策略的话,划分后训练集中只包括春、夏两季的用户数据;而测试集中是秋、冬季的数据。此时用春、夏季数据训练的模型明显无法很好地预测秋、冬季销售情况。
同理,如果医疗诊断系统中训练集与测试集有不同的病人年龄层分布,那也无法训练出适配所有年龄层次人的诊断模型。
3. 分层采样(Stratified Sampling)
划分数据集时的另一个常见陷阱是每种标签的数据没有均匀的被划分到训练集与测试集中。比如在医疗诊断系统中,如果将健康人群都分到了训练集,而有病况的人群都被分到了测试集,那么训练出的模型肯定会漏诊,即将有病况的人预测为健康人。
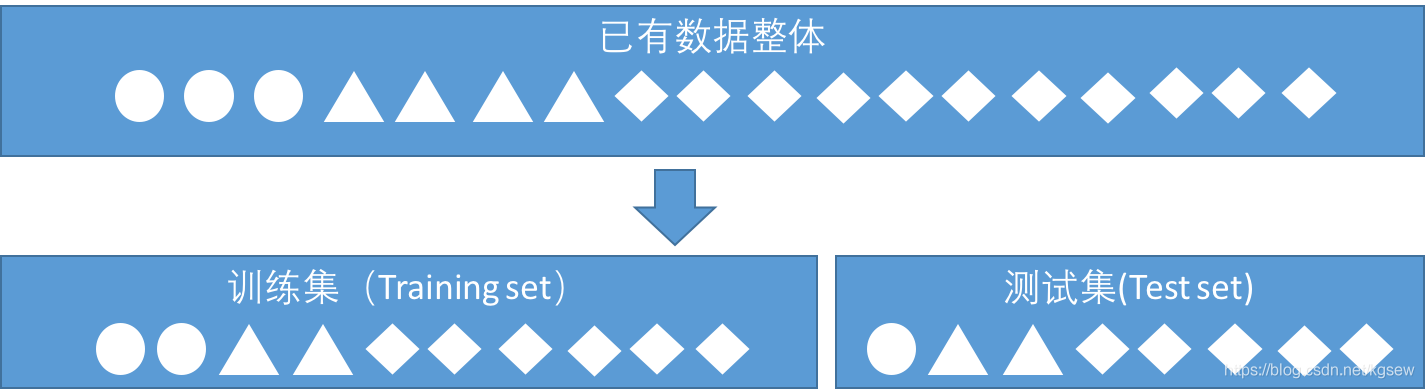
所谓的分层采样就是一种在划分训练/测试集时保持标签数据比例的采样规则,如图1-14所示。
![]()
图1-14 分层采样
图中圆形、三角形、菱形分别代表三种数据标签,分层采样的要求是将所有类型的标签等比例的划分到不同数据集中。
4. 验证集(Validation set)
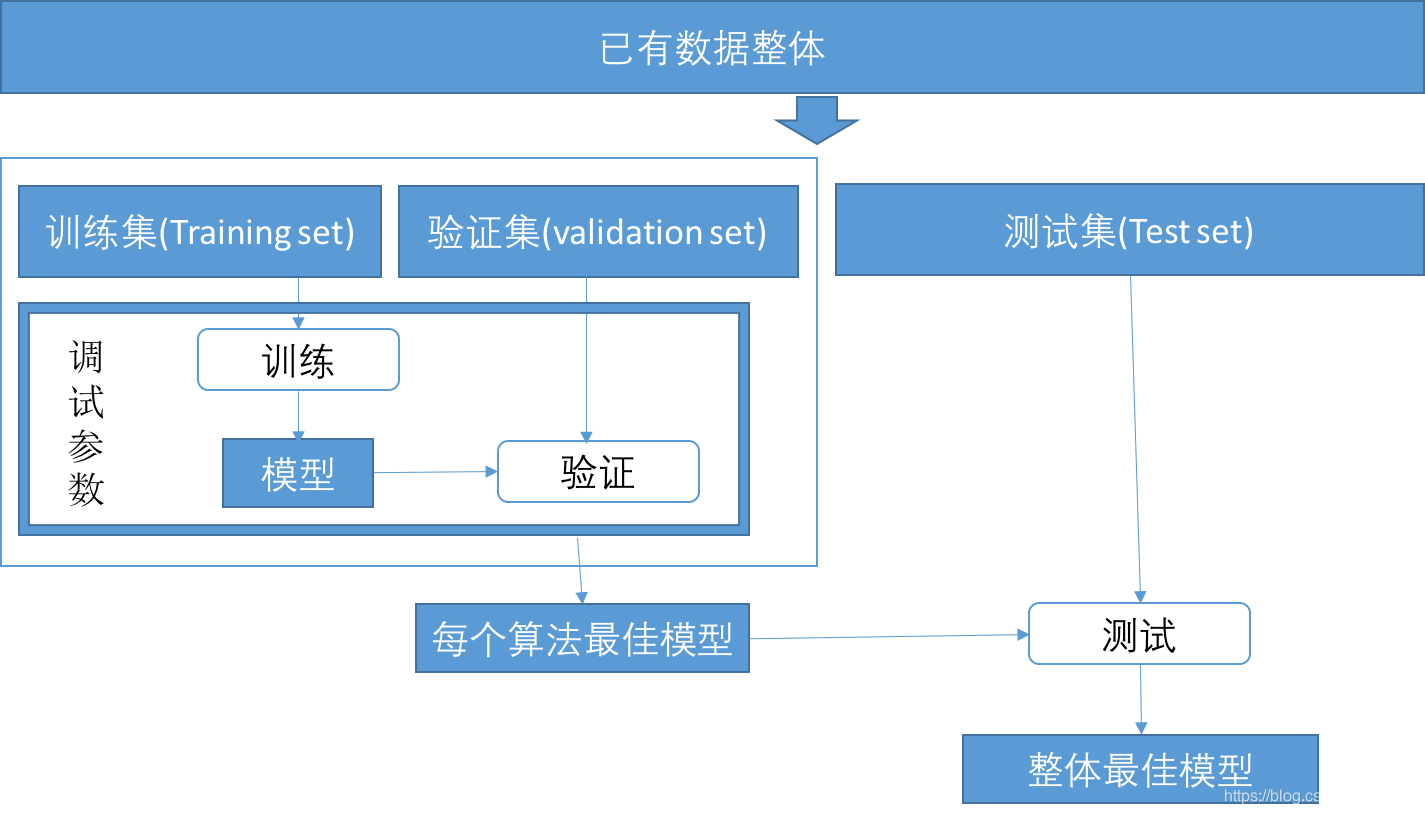
验证集是在某个模型的学习过程中用来调试超参数的数据集。因为大多数算法有可配超参数(如神经网络层数、EM类算法的最大迭代数等),所以验证集在机器学习领域也很常见,其作用如图1-15所示。
![]()
图1-15 训练集、验证集与测试集
图1-15中将图1-13的训练集又拆分成两部分,成为训练集和验证集。验证集的作用是在调试算法参数的不断“训练-验证”迭代中验证参数的性能,以达到选择正确超参数的目的。因为验证集只在备选算法学习时内部使用,可以对每个备选算法选取各自独立的验证集。
如有足够多的已有数据,划分三个子集的整体数量保持如下不等式关系可以提高模型的泛化能力:
训练集数量< 验证集数量 < 测试集数量
也就是说当从小数据集训练出的模型能够适配比其大的数据集时,才能更有把握的相信其学习到了一个普遍适用的知识。
从机器学习,到深度学习
从深度学习,到强化学习
从强化学习,到深度强化学习
从优化模型,到模型的迁移学习
一本书搞定!

![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号