《从机器学习到深度学习》笔记(2)无监督学习
有监督学习用于解决分类问题的前提是必须有一个带标签数据的样本集,但获得数据标签的代价往往是非常昂贵的。同时,这些标签通常都是人工标注,标注错误的情况也时有发生。这样就促使了无监督学习策略的发展,简单的说它就是:
对无标签数据进行推理的机器学习方法。
1. 场景
由于无监督学习的前提是不需要前期的人类判断,所以它一般是作为某项学习任务的前置步骤,用于规约数据;在无监督学习之后,需要加入人类知识以使成果有实用价值。图1-10从人类知识加入的时间点比较了两种学习策略。
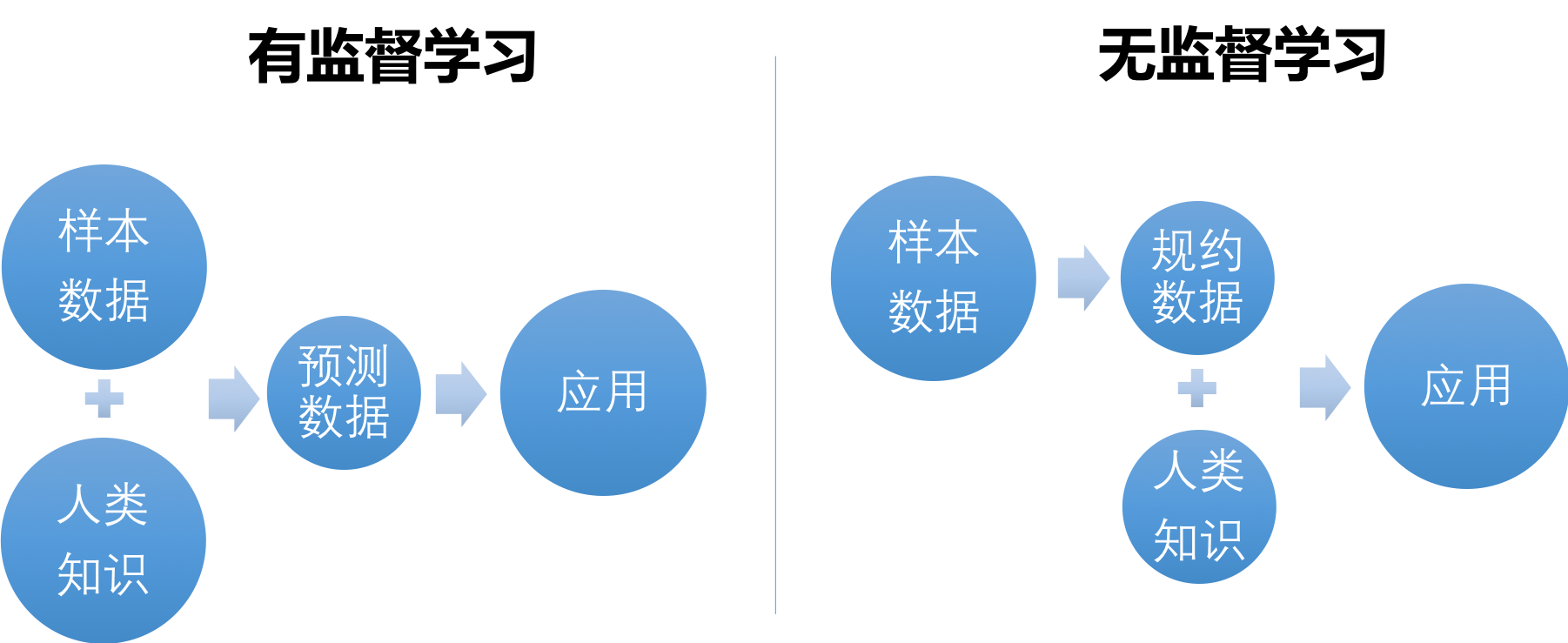
图1-10 有监督学习与无监督学习
一般来说人类理解由无监督学习规约后的数据比整理样本数据中的标签更容易些,所以总体上无监督学习需要更少的人工参与。
无监督学习的算法比较丰富,按整理数据的方式有两大分支:
- 聚类(Clustering):是最主要的无监督学习方式,是指将已有的样本数据分成若干个子集。生成的模型也可用于为新样本划分类别。
- 降维(Dimensionality Reduction):即以保持数据之间现有距离关系不变为目标,将高维数据转换为低维数据,。
此外还有一些小的算法族群比如协方差分析(Covariance Estimation)、边缘检测(Outlier Detection)等。
图1-11举例说明作为最重要无监督学习方式的聚类适用场景。它是一个银行客户的聚类示意图,其将已有的客户总体分成两个子集。在进行聚类训练后,新客户也可用已有的模型划分到相应子集。

图1-11 聚类场景举例
聚类只是提供子集划分方案,而划分的逻辑意义需要人类进行辨别。在图1-11中,从结果看算法将所有客户按存款额和贷款额的多少分为了两类。对于大多数银行来说,可能子集1对应的是普通用户,子集2对应的是重要客户。
2. 聚类算法
聚类算法仍然是当下一个不断发展领域,各种方法比较繁杂。本书主要学习目前比较成熟的几种聚类策略,它们是:
- 距离切分方法(Partition Methods):是一种最基础的算法,根据特征之间的距离进行聚类划分。具体算法主要是指K-means和及其派生算法。
- 密度方法(Density Methods):其通过定义每个子集的最小成员数量和成员之间距离实现划分。最典型的算法是DBSCAN,即Density-Based Spatial Clustering of Applications with Noise。
- 模型方法(Model Methods):用概率模型(以高斯混合模型为典型,即Gaussian Mixture Model)和神经网络模型(SOM,Self Organizing Maps)为主要代表。其特点是不完全将样本认定为属于某子集,而是指出样本属于各子集的可能性的大小。
- 层次方法(Hierarchical Methods):不像其他聚类将总体划分成彼此地位平等的多个子集,层次方法最终将数据集划分成有父子关系的树形结构。这样就可以在聚类的同时考察各子类之间的亲缘关系,比较典型的是birch模型。
3. 降维算法
如前所述,降维一般被用来压缩特征数量以便后续处理,其相对聚类来说略显抽象。本书介绍两类降维策略:
- 线性降维:顾名思义用来处理线性问题。模型比较简单,包括常见的主成分分析(PCA,Principle Component Analysis)和线性判别分析(LDA,Linear Discriminant Analysis)
- 流行学习(Manifold Learning):是近期学术界的热点,可以处理非线形降维。目前比较成熟的算法包括Isomap、局部线性嵌入(LLE,Locally Linear Embedding)等。
本书第4、5章分别详细讨论聚类和降维的主要算法原理与实践。
从机器学习,到深度学习
从深度学习,到强化学习
从强化学习,到深度强化学习
从优化模型,到模型的迁移学习
一本书搞定!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号