

手写web框架--了解web运行机制。
第一步--写一个服务端
import socket
server = socket.socket() # 默认就是TCP协议
server.bind(('127.0.0.1', 8080))
server.listen(5)
while True:
conn, addr = server.accept() # 三次四次挥手
data = conn.recv(1024) # 接收消息
print(data)
conn.send(b'hello world!')
conn.close()
运行这个服务端。
用浏览器发送请求。
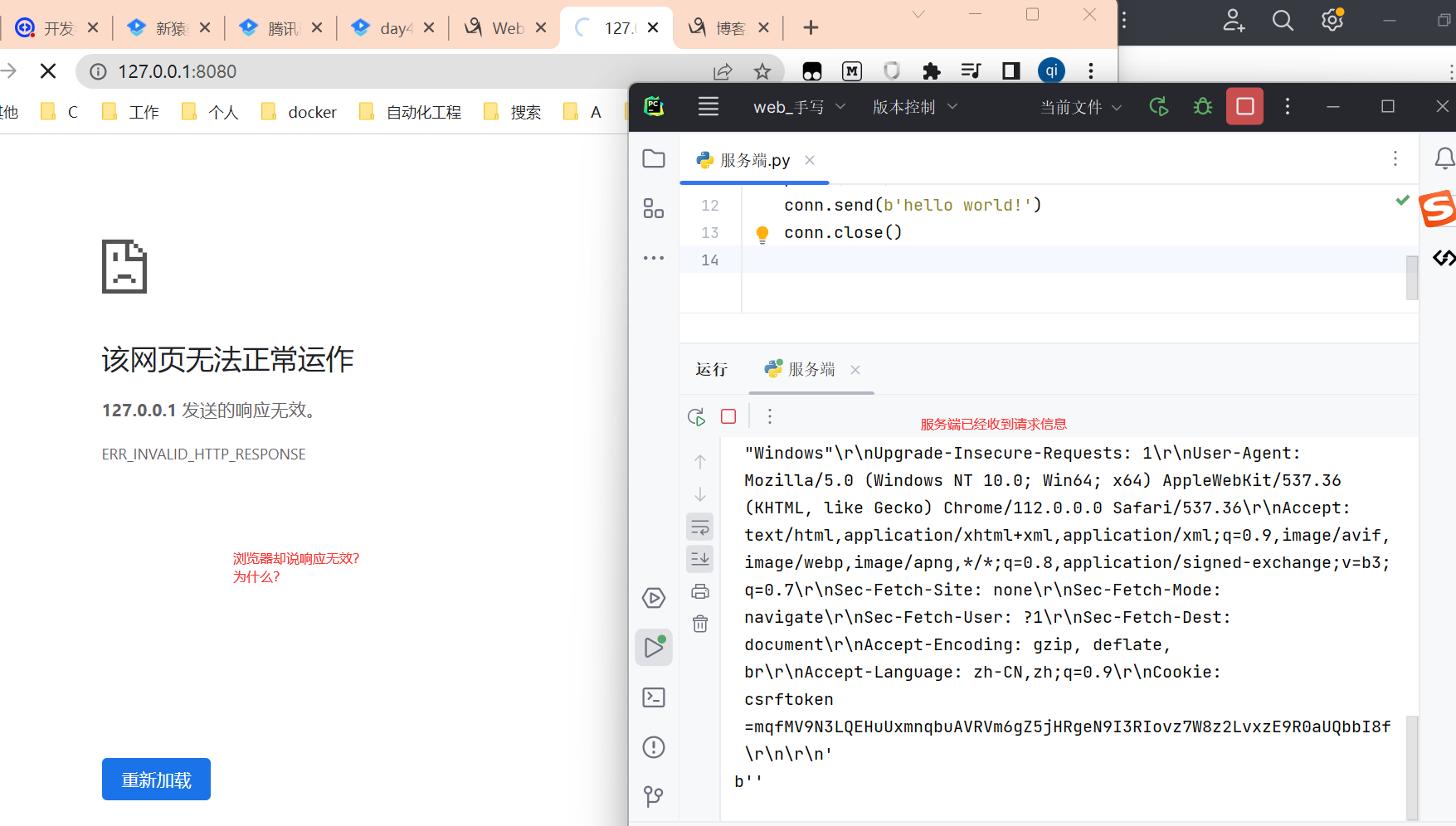
遇到问题,浏览器说,ERR_INVALID_HTTP_RESPONSE 响应无效。
第二步,解决第一步遇到问题。--响应无效
分析是
- 因为浏览器是有自己的规范的,没有安装人家的规范来。
- 人家的规范叫HTTP协议。
解决是:
conn.send(b'HTTP/1.1 200 OK \r\n\r\nhello world!!')
# 按照HTTP协议来
查看结果:
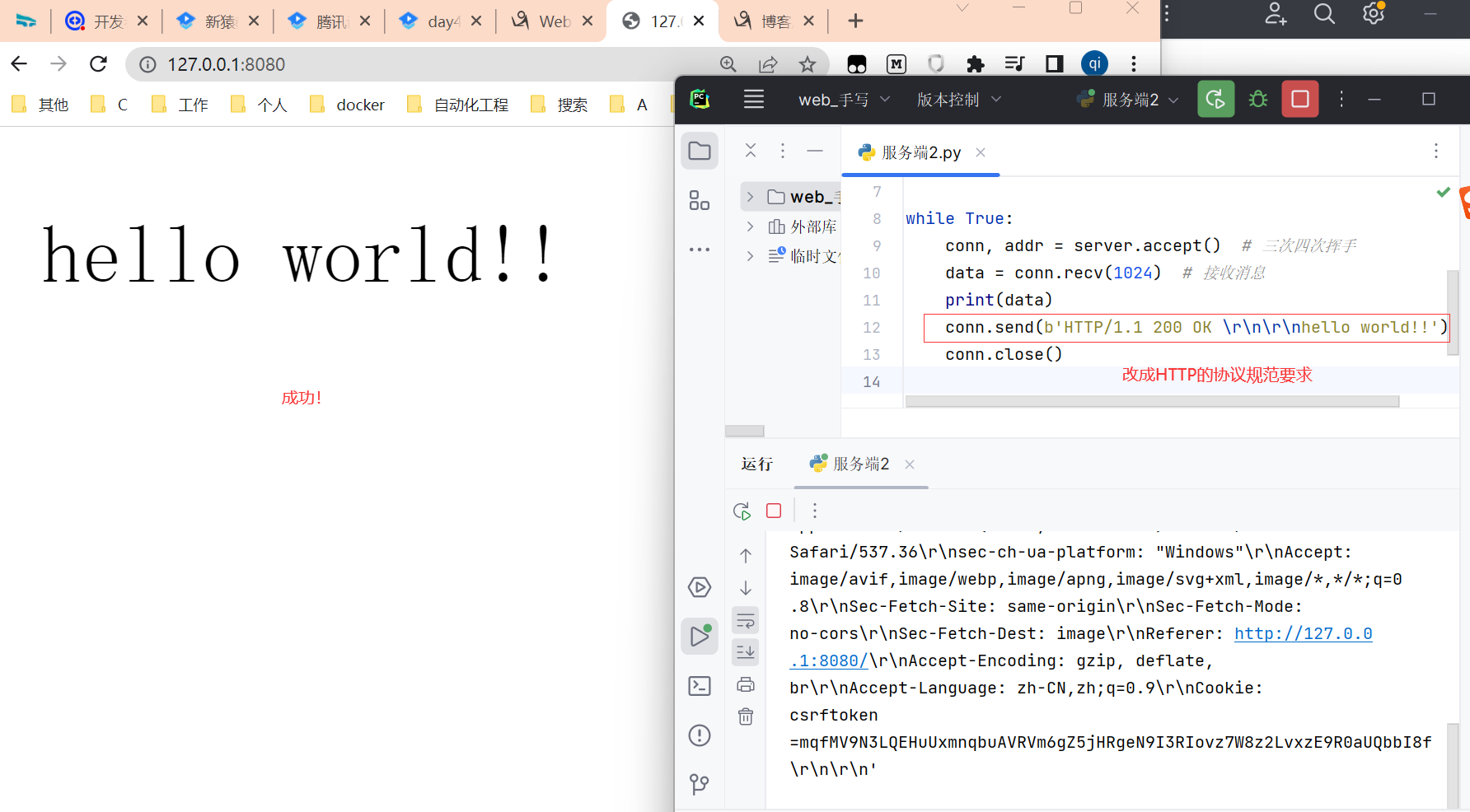
现在一切OK。
新的需求:
可恶的产品经理有新的需求
说要根据不同的url访问不同的页面。
比如:
访问127.0.0.1:8080/login访问一个登录的页面
访问127.0.0.1:8080 访问一个首页
如何解决“ta”的需求?
第三步--解决第二步新的需求--根据路由访问不同的页面
分析:
试了一下,通过浏览器访问不同的url地址。
服务端拿到的数据是有变化的。
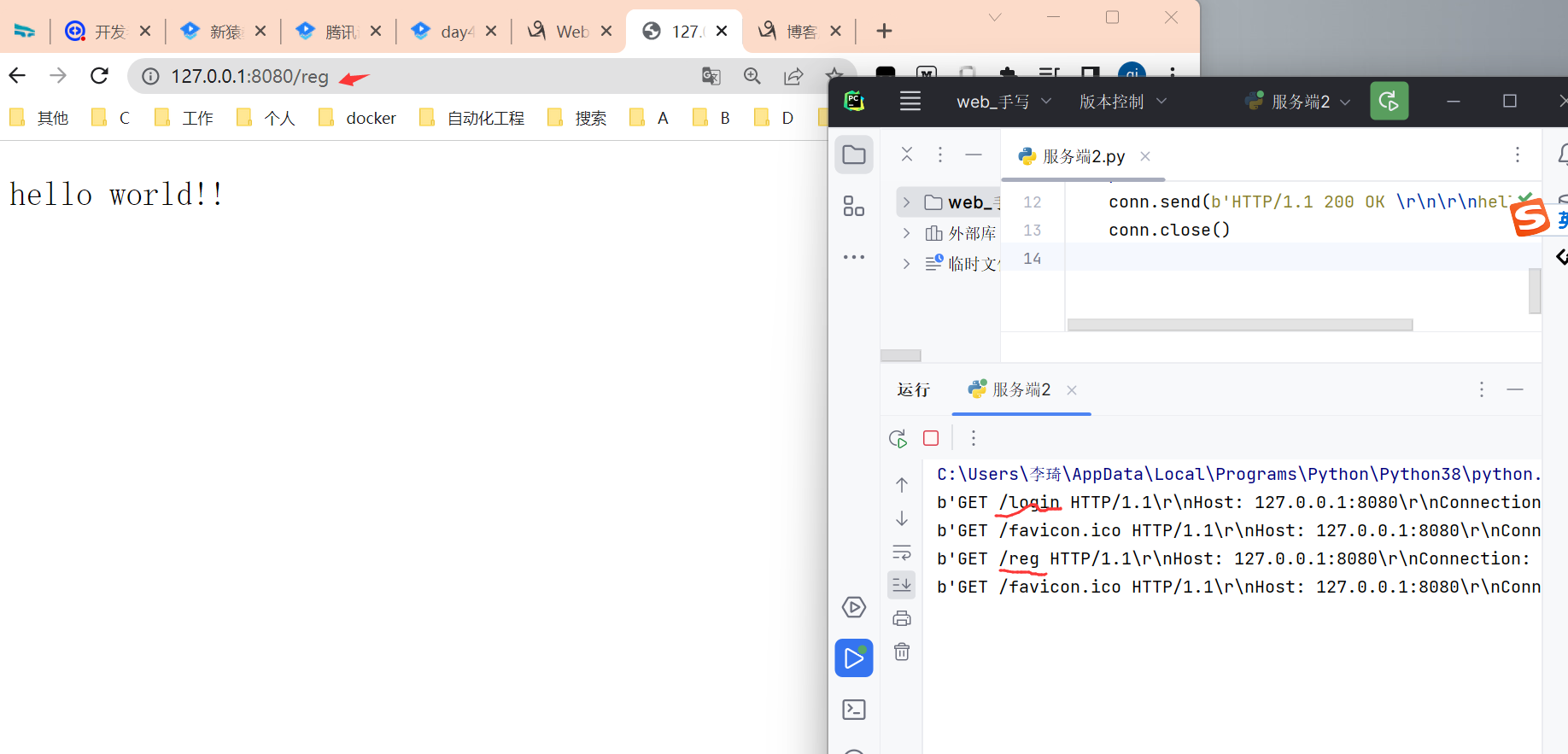
所以,我们看看能否利用字符串切割出想要的reg和login
解决第一步:
先解码,再切割。
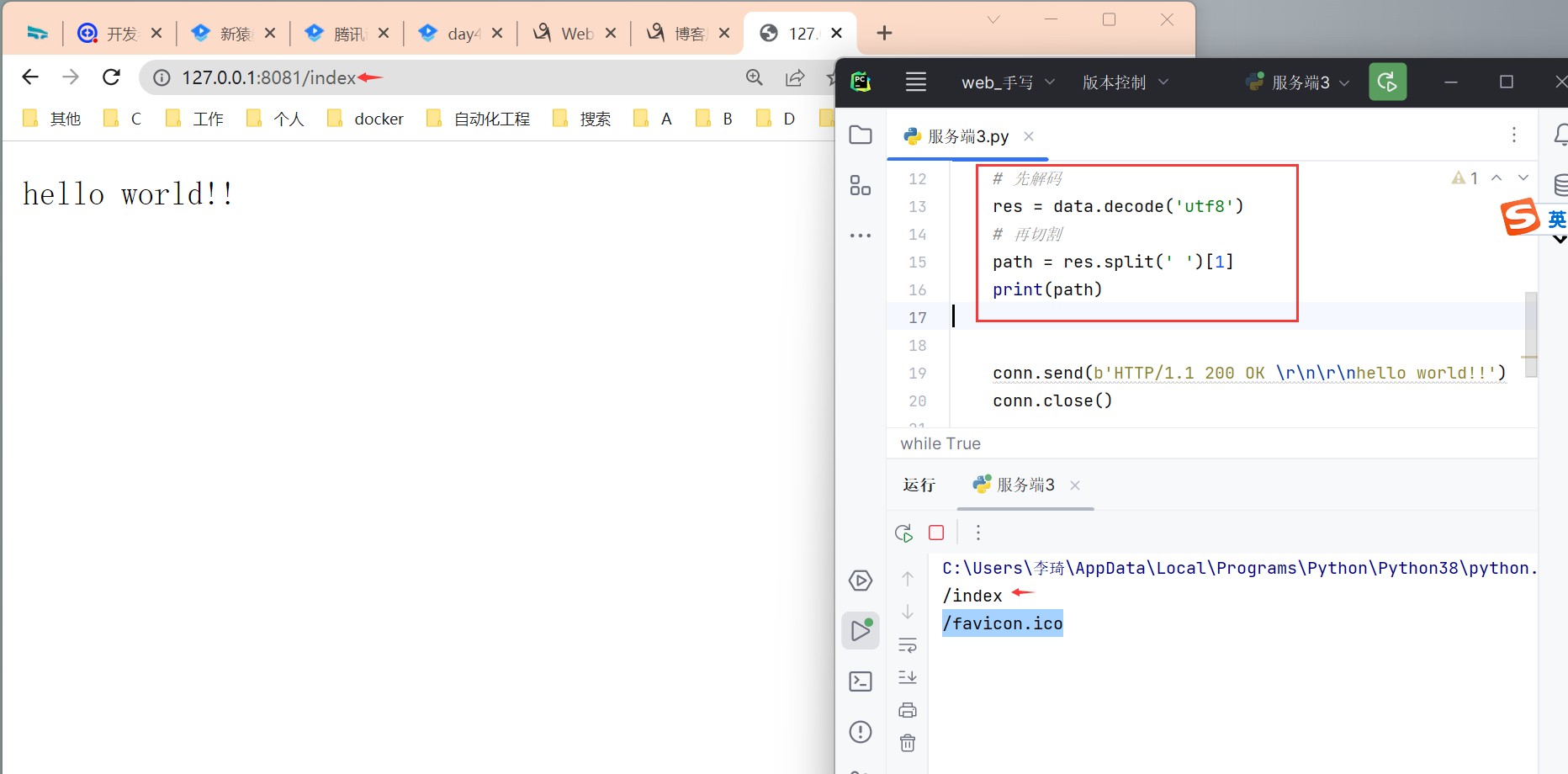
解决第二步:
判断字符
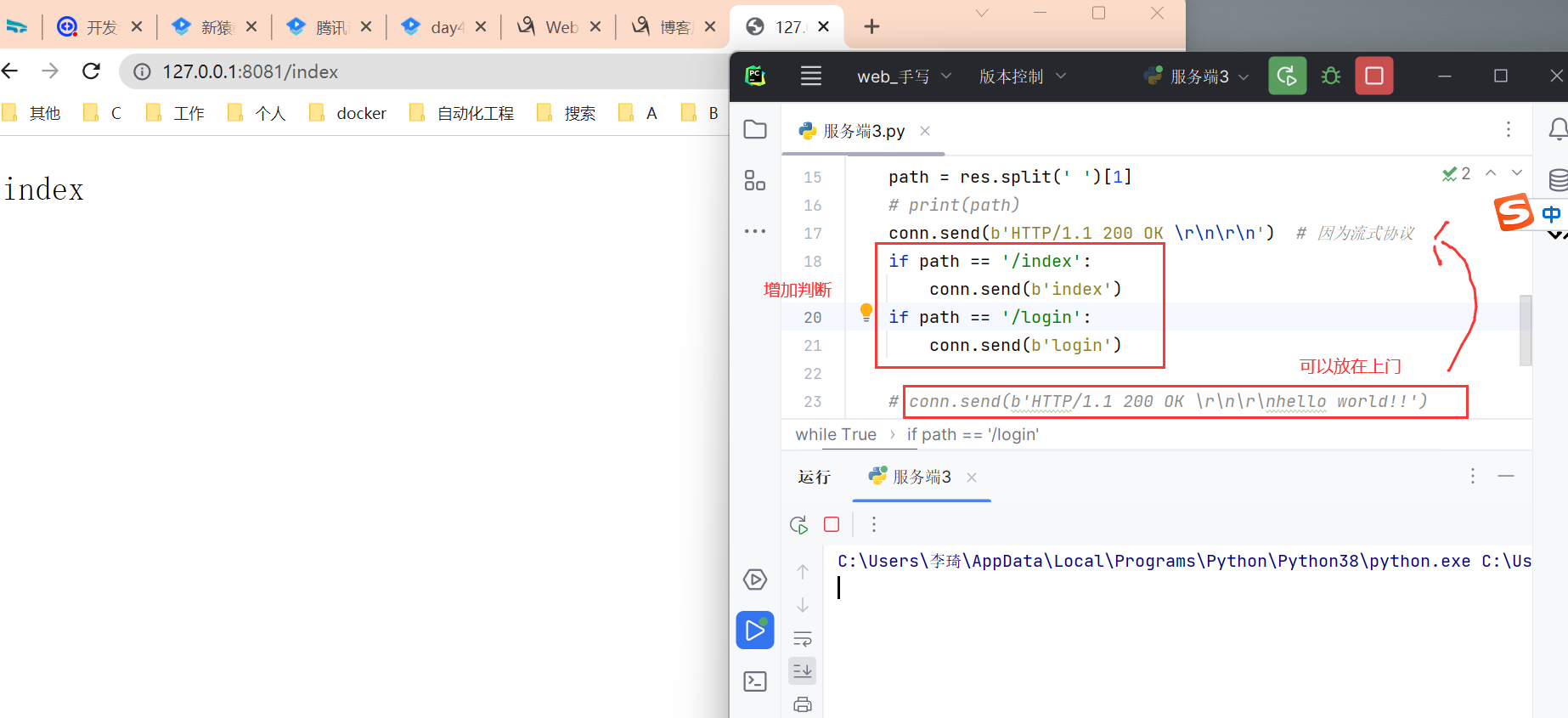
代码是
import socket
server = socket.socket() # 默认就是TCP协议
server.bind(('127.0.0.1', 8081))
server.listen(5)
while True:
conn, addr = server.accept() # 三次四次挥手
data = conn.recv(1024) # 接收消息
# print(data)
# 先解码
res = data.decode('utf8')
# 再切割
path = res.split(' ')[1]
# print(path)
conn.send(b'HTTP/1.1 200 OK \r\n\r\n') # 因为流式协议
if path == '/index':
conn.send(b'index')
elif path == '/login':
conn.send(b'login')
else:
conn.send(b'404 error')
# conn.send(b'HTTP/1.1 200 OK \r\n\r\nhello world!!')
conn.close()
新的需求:
这时候,产品经理说能否展示一个HTML页面?
第四步--解决第三步需求--返回html页面
分析
- 既然能返回字符串
- 为什么不能打开一个文件返回呢?
解决 - 用with open打开文件返回
代码
import socket
server = socket.socket() # 默认就是TCP协议
server.bind(('127.0.0.1', 8081))
server.listen(5)
while True:
conn, addr = server.accept() # 三次四次挥手
data = conn.recv(1024) # 接收消息
# print(data)
# 先解码
res = data.decode('utf8')
# 再切割
path = res.split(' ')[1]
# print(path)
conn.send(b'HTTP/1.1 200 OK \r\n\r\n') # 因为流式协议
if path == '/index':
with open(r'fh.html','rb') as f:
data = f.read()
conn.send(data)
elif path == '/login':
conn.send(b'login')
else:
conn.send(b'404 error')
conn.close()
HTML文件
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<body>
<h1 >这是一个非常牛的页面</h1>
</body>
</html>
现在ok了。
新的需求
可恶的产品经理和技术总监说,能否把代码优化一下?
提出:
1.服务端代码重复。
2.需要手工去处理http的请求。
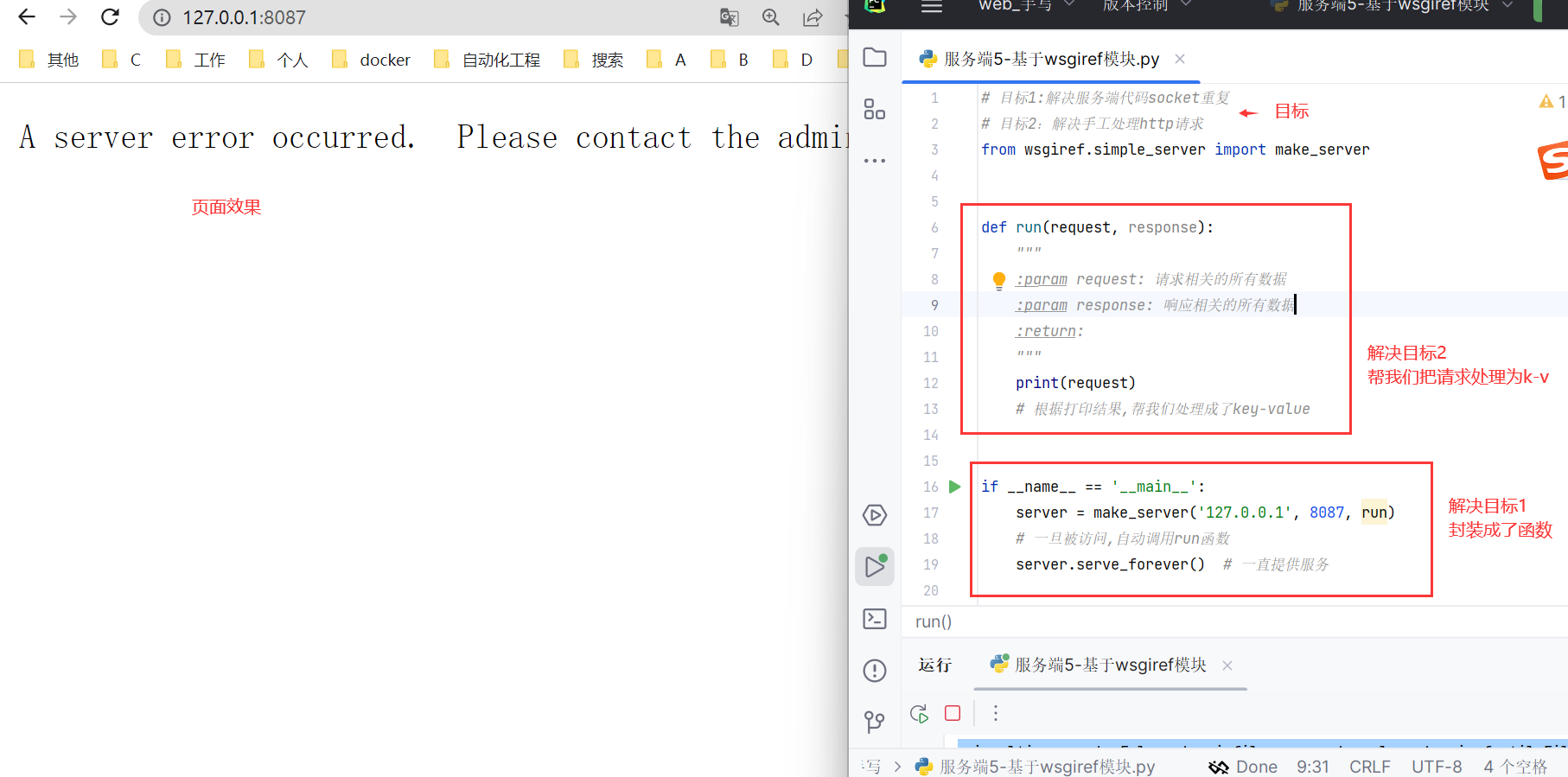
第五步--基于wsgiref模块--解决第4步的2个需求
分析
*经高人j哥,提示可以引入wsgiref模块
代码
# 目标1:解决服务端代码socket重复
# 目标2:解决手工处理http请求
from wsgiref.simple_server import make_server
def run(request, response):
"""
:param request: 请求相关的所有数据
:param response: 响应相关的所有数据
:return:
"""
print(request)
# 根据打印结果,帮我们处理成了key-value
if __name__ == '__main__':
server = make_server('127.0.0.1', 8087, run)
# 一旦被访问,自动调用run函数
server.serve_forever() # 一直提供服务
效果
新的需求
刚才的怎么报错?
如何返回结果不报错?
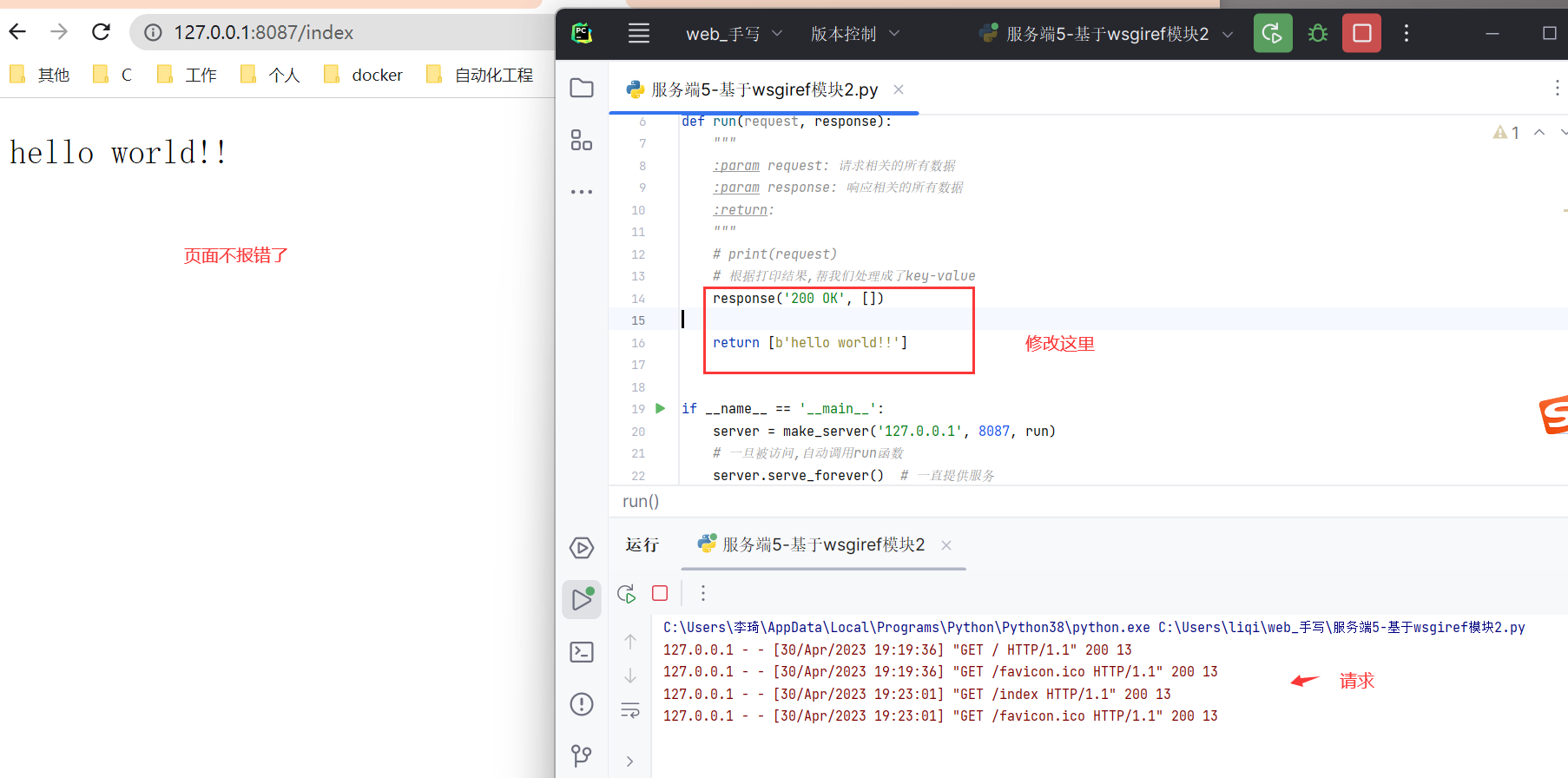
第6步--基于wsgiref模块--解决返回错误
分析
修改run函数代码
response('200 OK', [])
return [b'hello world!!']
效果
新的需求
可恶的产品经理,又又又叕 像刚才那样提出需求。
要求跟之前一样,根据不同的url访问不同的页面
第7步--基于wsgiref模块--解决url
分析
查看run里面的request请求。
发现在key为PATH
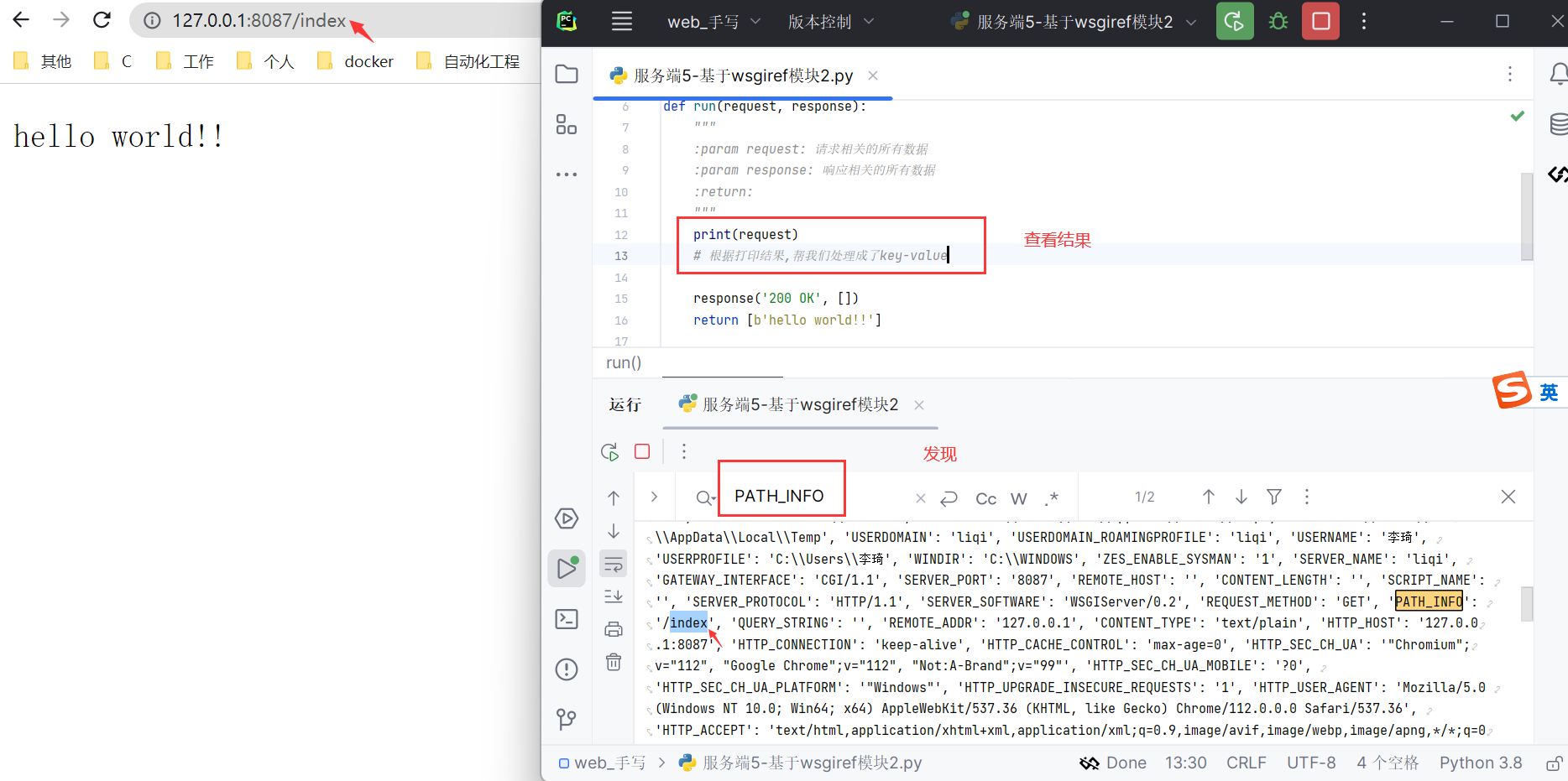
解决
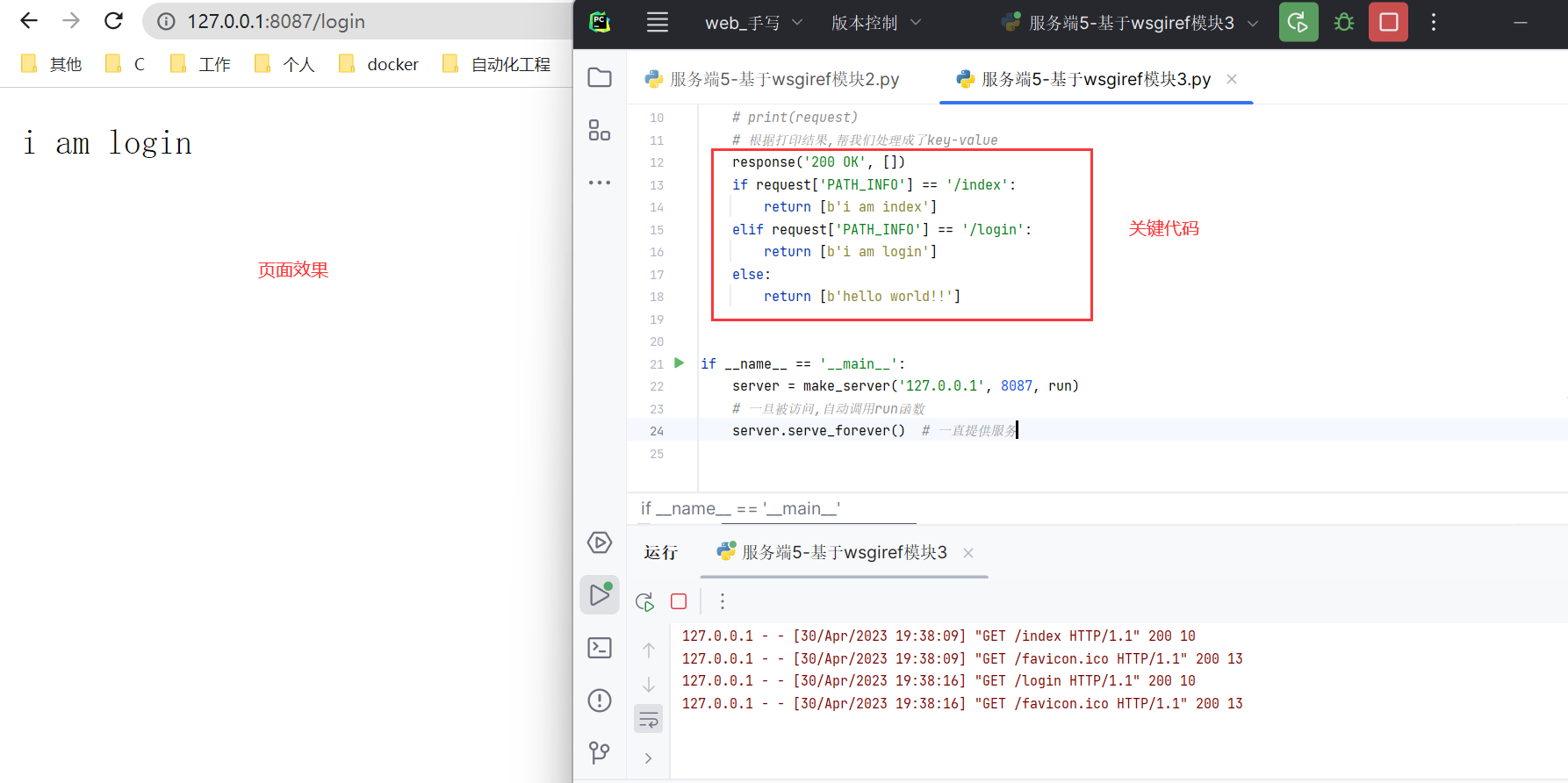
根据request['PATH_INFO']来进行判断
代码
from wsgiref.simple_server import make_server
def run(request, response):
"""
:param request: 请求相关的所有数据
:param response: 响应相关的所有数据
:return:
"""
# print(request)
# 根据打印结果,帮我们处理成了key-value
response('200 OK', [])
if request['PATH_INFO'] == '/index':
return [b'i am index']
elif request['PATH_INFO'] == '/login':
return [b'i am login']
else:
return [b'hello world!!']
if __name__ == '__main__':
server = make_server('127.0.0.1', 8087, run)
# 一旦被访问,自动调用run函数
server.serve_forever() # 一直提供服务
效果
新的需求
技术总监看了我的代码说,
问题1:假如有100个url地址你如何处理?
问题2:当一个login有自己的逻辑判断,有很多这样的login,怎么办?
第8步--基于wsgiref模块--解决更多的url和逻辑
分析
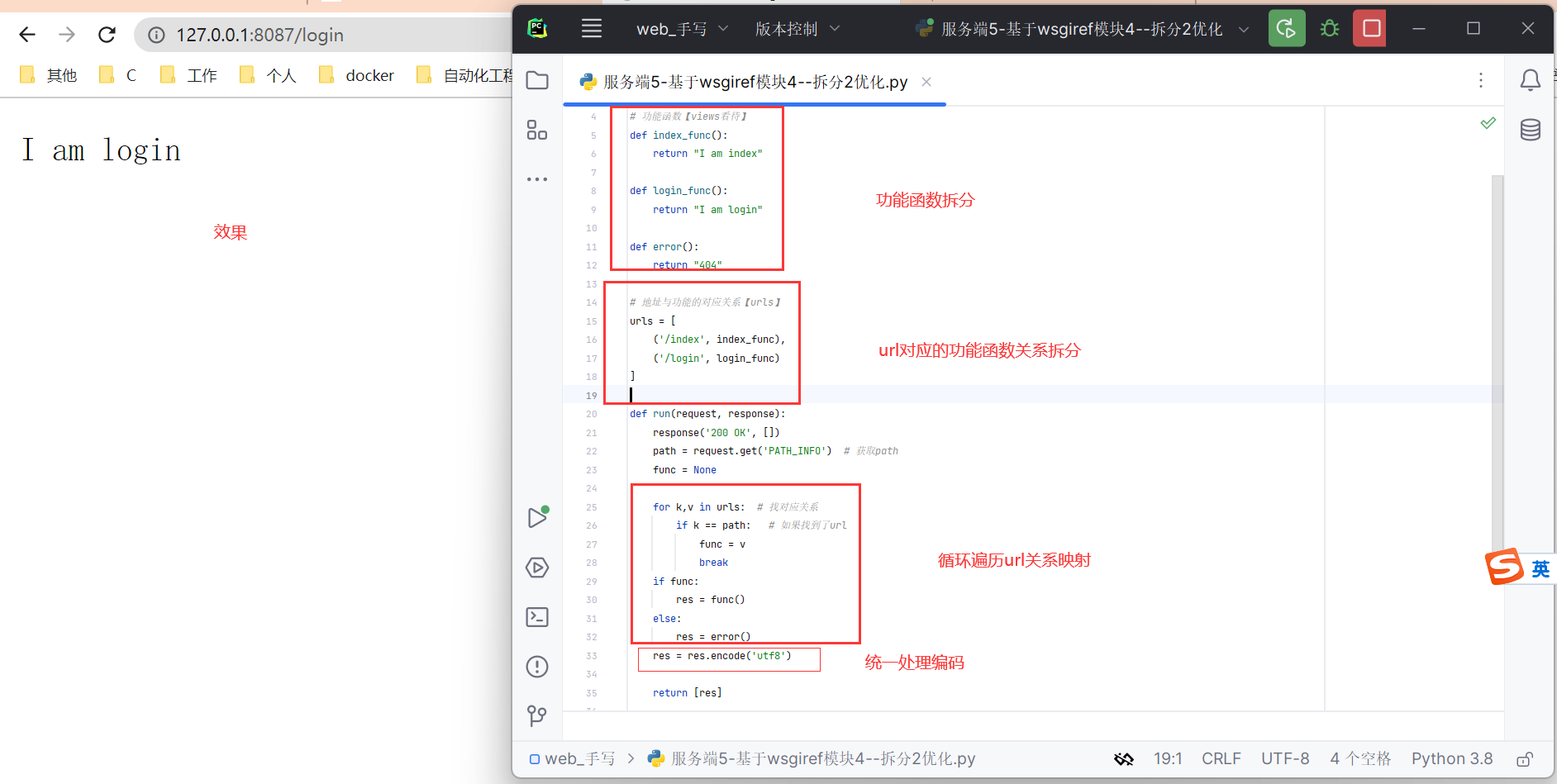
第一步,拆分
解决第一步
from wsgiref.simple_server import make_server
# 功能函数【views看待】
def index_func():
return "I am index"
def login_func():
return "I am login"
def error():
return "404"
# 地址与功能的对应关系【urls】
urls = [
('/index', index_func),
('/login', login_func)
]
def run(request, response):
response('200 OK', [])
path = request.get('PATH_INFO') # 获取path
func = None
for k,v in urls: # 找对应关系
if k == path: # 如果找到了url
func = v
break
if func:
res = func()
else:
res = error()
res = res.encode('utf8')
return [res]
if __name__ == '__main__':
server = make_server('127.0.0.1', 8087, run)
server.serve_forever() # 一直提供服务
效果
继续分析
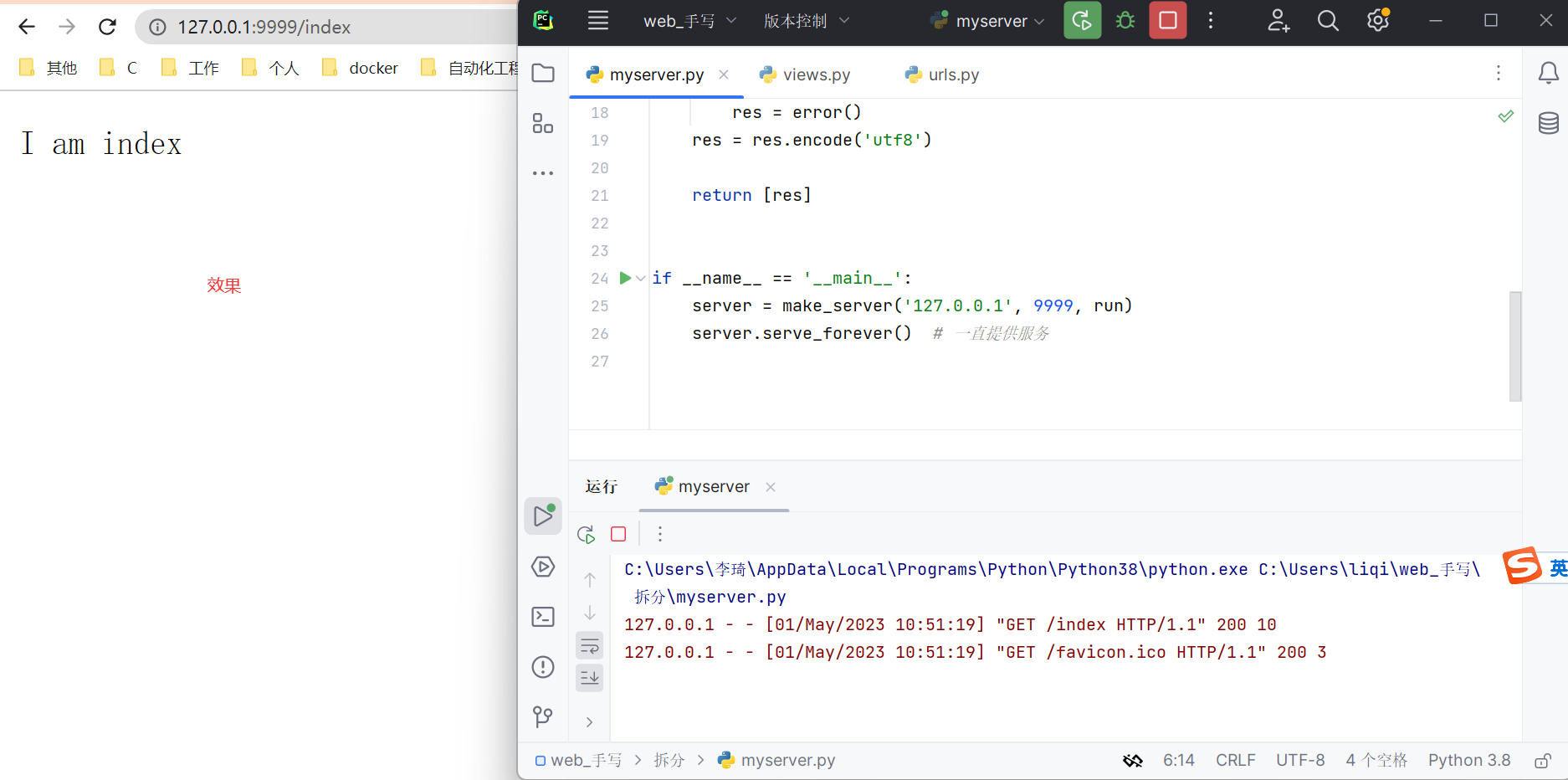
可以继续拆分。
把模块拆到不同的py文件中
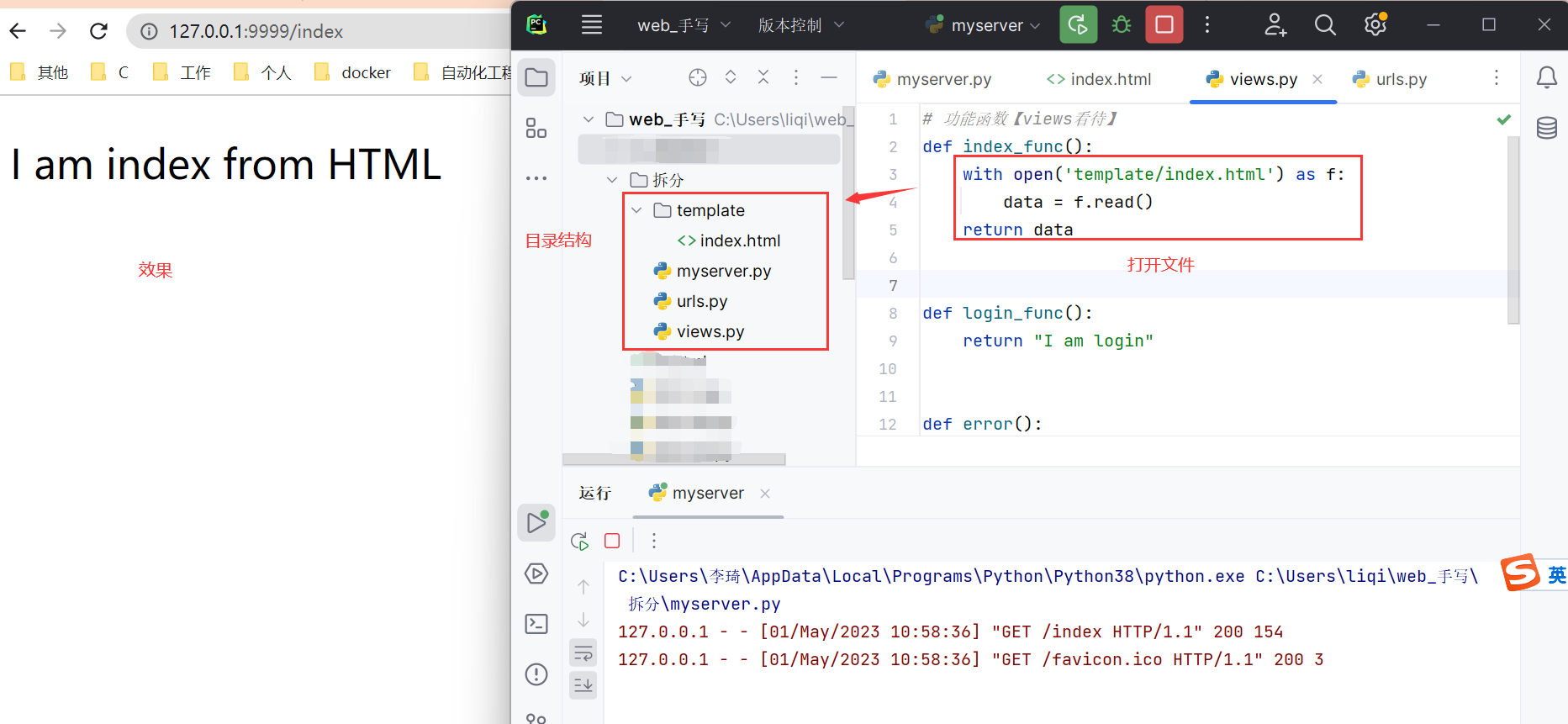
设计结构如下

解决第2步
# views.py
# 功能函数【views看待】
def index_func():
return "I am index"
def login_func():
return "I am login"
def error():
return "404"
# urls
from views import *
# 地址与功能的对应关系【urls】
urls = [
('/index', index_func),
('/login', login_func)
]
# myserver.py # 提供服务的函数
from wsgiref.simple_server import make_server
from urls import urls
from views import *
def run(request, response):
response('200 OK', [])
path = request.get('PATH_INFO') # 获取path
func = None
for k, v in urls: # 找对应关系
if k == path: # 如果找到了url
func = v
break
if func:
res = func()
else:
res = error()
res = res.encode('utf8')
return [res]
if __name__ == '__main__':
server = make_server('127.0.0.1', 9999, run)
server.serve_forever() # 一直提供服务
效果
扩展优化
返回HTML页面
解决
在view里面打开html文件
def index_func():
with open('template/index.html') as f:
data = f.read()
return data
效果
新的需求
能否写一个动态页面?
数据来源后端?比如一个时间页面。
第9步--增加动态页面
分析
1.用with open 打开一个html
2.在html增加一个flag标记
3.替换这个flag
代码
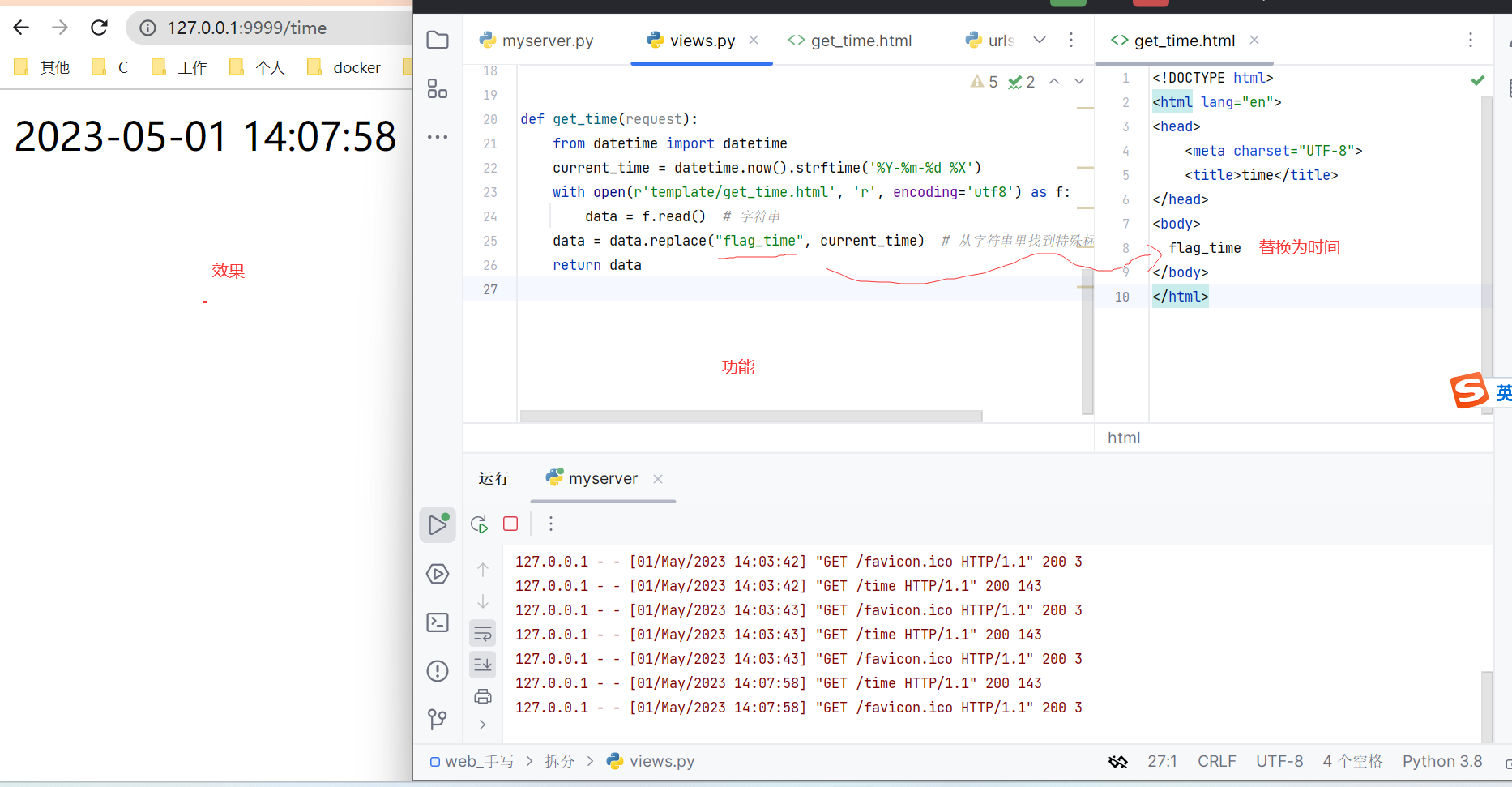
def get_time(request):
from datetime import datetime
current_time = datetime.now().strftime('%Y-%m-%d %X')
with open(r'template/get_time.html', 'r', encoding='utf8') as f:
data = f.read() # 字符串
data = data.replace("flag_time", current_time) # 从字符串里找到特殊标记,并替换
return data
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>time</title>
</head>
<body>
flag_time
</body>
</html>
效果
新的需求
后端传给html页面一个字典,HTML页面可以调用?
(现在的主要矛盾是,日益更新的需求与程序员的能力的匹配程度)
T_T
第10步,解决HTML可以调用后端的HTML页面
分析
根据J哥,引入新的模块jinja2
jinja2有一个模板语法
pip3 install jinja2
ps:这个模块是flask的必备模块
代码
#views.py
...
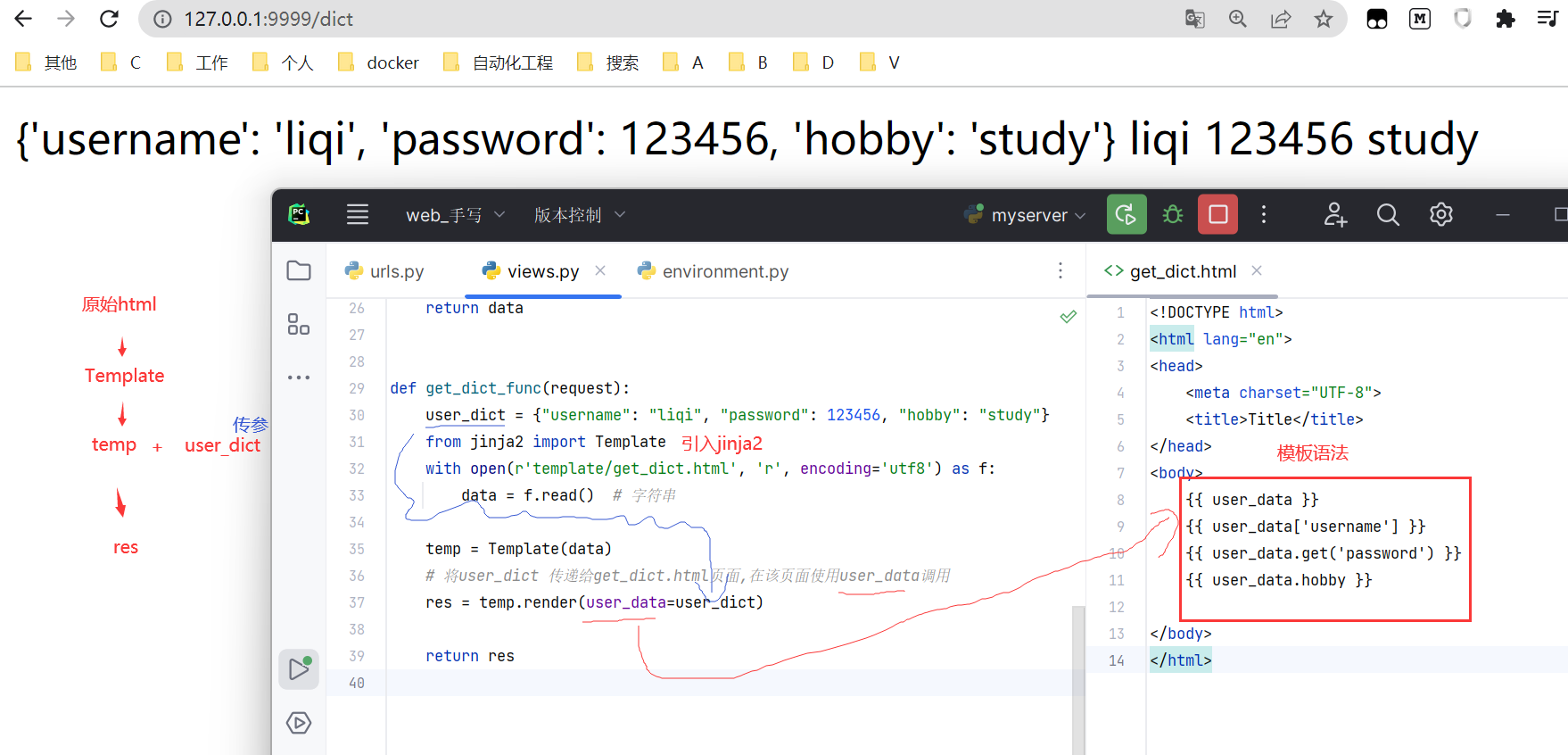
def get_dict_func(request):
user_dict = {"username": "liqi", "password": 123456, "hobby": "study"}
from jinja2 import Template
with open(r'template/get_dict.html', 'r', encoding='utf8') as f:
data = f.read() # 字符串
temp = Template(data)
# 将user_dict 传递给get_dict.html页面,在该页面使用user_data调用
res = temp.render(user_data=user_dict)
return res
...
<body>
{{ user_data }}
{{ user_data['username'] }}
{{ user_data.get('password') }}
{{ user_data.hobby }}
</body>
...
效果
需求
能否展示MySQL数据库中的数据?
第11步--展示MySQL的数据
分析
利用pymysql模块查询出来
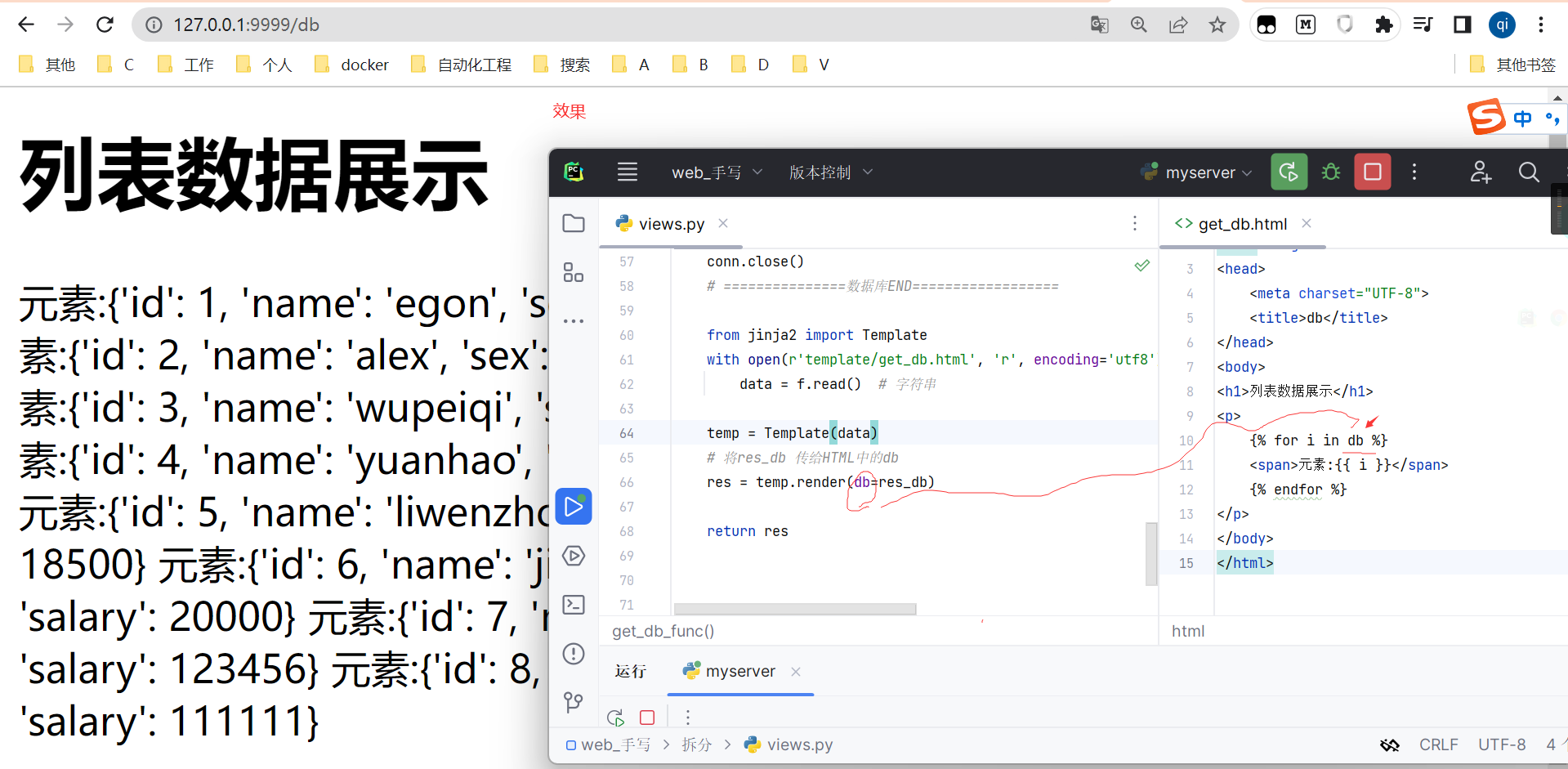
def get_db_func(request):
# ===============数据库==================
import pymysql
conn = pymysql.connect(host="127.0.0.1", port=3306, database="day01", user="root", password="liqi1234")
# 建立一个游标,这个游标可以类比为cmd命令行
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
# cursor=pymysql.cursors.DictCursor 设为以字典的形式返回,不设置,则以元组的形式
rows = cursor.execute("select * from employee") # 这里输入sql语句
# print(rows)
res_db = cursor.fetchall() # 显示所有值
print(res_db)
cursor.close()
conn.close()
# ===============数据库END==================
from jinja2 import Template
with open(r'template/get_db.html', 'r', encoding='utf8') as f:
data = f.read() # 字符串
temp = Template(data)
# 将res_db 传给HTML中的db
res = temp.render(db=res_db)
return res
...
<h1>列表数据展示</h1>
<p>
{% for i in db %}
<span>元素:{{ i }}</span>
{% endfor %}
</p>
效果
扩展
jinja2是在哪里完成这些操作的?
A,前端浏览器。B,后端
选B,后端。
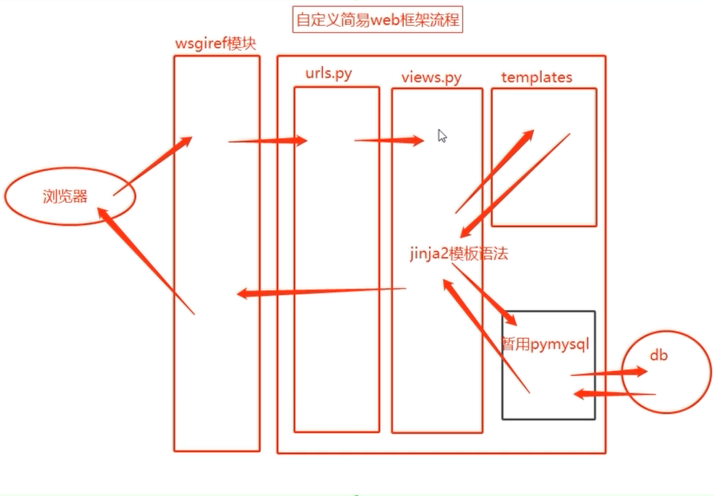
总结
参考资料:https://www.cnblogs.com/Dominic-Ji/articles/16294929.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY