Python--数据库--学习笔记
1.数据库管理软件的本质?
本质就是C/S架构的套接字程序
- 服务器套接字
- 操作系统:linux
- 计算机(本地文件)
2.为什么要用数据库管理软件?
可以自己写,
要结合套接字程序,解决并发问题,加入用户认证机制,保证数据安全等。
所以,有人帮我写了。
这就是数据库管理软件的由来。
3.常用的数据库管理软件有哪些?
关系型数据库管理软件(有数据关联)---数据清晰
mysql、oracle
ps:阿里提出,去IOE运动(去掉国外的影响)
非关系型数据库管理软件(key-value)---查询速度快。
redis \ memcache \ mongodb
缓存redis用的多
mongodb
4.学习sql语句本质是学习命令规范?
- 对的。
s --------------------c
select C:\user.text name
跟我们自己写个套接字程序是一样的。有服务端,有客户端。
传输的数据是:select C:\user.txt name 就是查询C盘下面的user.txt里的name是多少
服务端拿到数据,进行切割,(内部自己处理粘包问题)。拿到数据select C:\user.txt name
服务端切割开,知道了,查询C盘下面的user.txt里的name是多少。找到数据,返回给客户端。
5.所以,sql是?
套接字管理软件的作者为使用者规定的命令规范。
6.数据库核心概念总结:
数据------>事物的状态
记录------> 文件的中的一条信息
表-------> 一个文件
库------->一个文件夹
数据库管理软件---------->套接字程序: mysqld ,mysql
数据库服务器--------->运行mysqld的计算机
7.人们的指的数据库具体指?
库
数据库管理软件
数据库服务器
8.安装mysql
我环境是Ubuntu 20 ,官方默认是8.0
我这里就选择8.0版本了。
具体操作:https://www.cnblogs.com/liqi175/p/17219591.html
9.查看mysql状态
sudo service mysql status # 查看服务状态 sudo service mysql start # 启动服务 sudo service mysql stop # 停止服务 sudo service mysql restart # 重启服务
ps aux | grep mysql
10.进入mysql8.0
sudo mysql
11.mysql 8.0的配置文件在哪里?
/etc/mysql/debian.cnf
- 查看配置和密码都是这个
sudo cat /etc/mysql/debian.cnf
12.配置文件的一些解释
[client] default-character-set = utf8mb4 [mysql] default-character-set = utf8mb4 [mysqld] character-set-client-handshake = FALSE character-set-server = utf8mb4 collation-server = utf8mb4_unicode_ci init_connect='SET NAMES utf8mb4'
utf8mb4是utf-8的一种格式 ,支持表情
mysqld是服务端的配置。
13.如何查看配置文件?
可以查看
cd /etc/mysql
ls

13.5 创建个day01的库,就是创建个文件夹?
是的
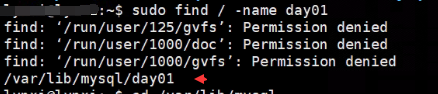
sudo su # 临时提升权限 cd /var/lib/mysql/ ls

14.SQL语句的学习
库-->文件夹
-
增
create database day01
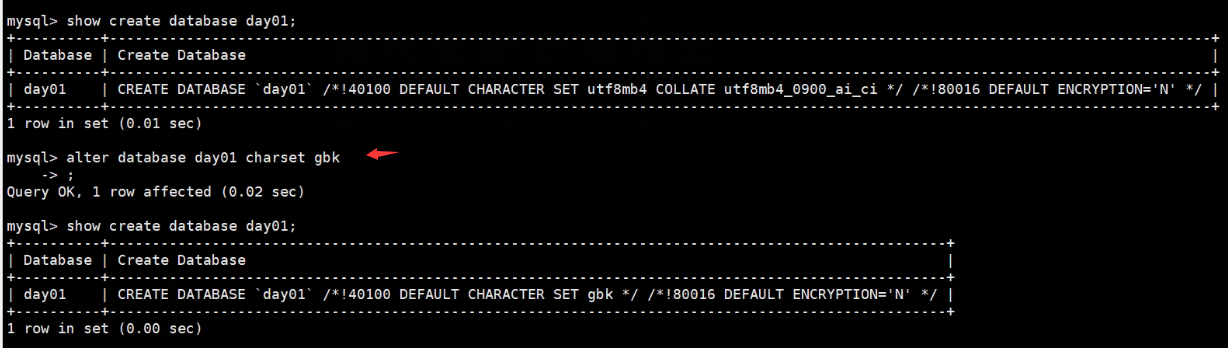
- 改
# 在库的级别,不能改名字,只能改编码 alter database day01 charset gbk;
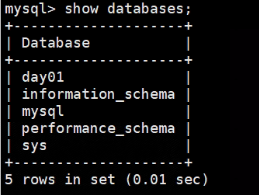
- 查
show databases;
注意这个datebases是复数形式
show create database day01;

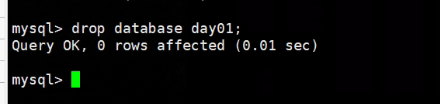
- 删
drop database day01;
表
use day01; # 对应 cd day01文件夹
select database(); # 对应pwd
- 增
create table t1; # 对应 touch t1
create day01.table t1 ; # 对应绝对路径,touch day01/t1
# 注意t1创建的时候,不能为空。要有一些基本的标题

-
-
create table t1(id int,name varchar(16)); # 本质就是多了个文件
-
![]()

![]()
- 版本不一样,东西不一样。

- 改
-
alter table t1 rename t2; # 重命名,对应 mv t1 t2
![]()
-
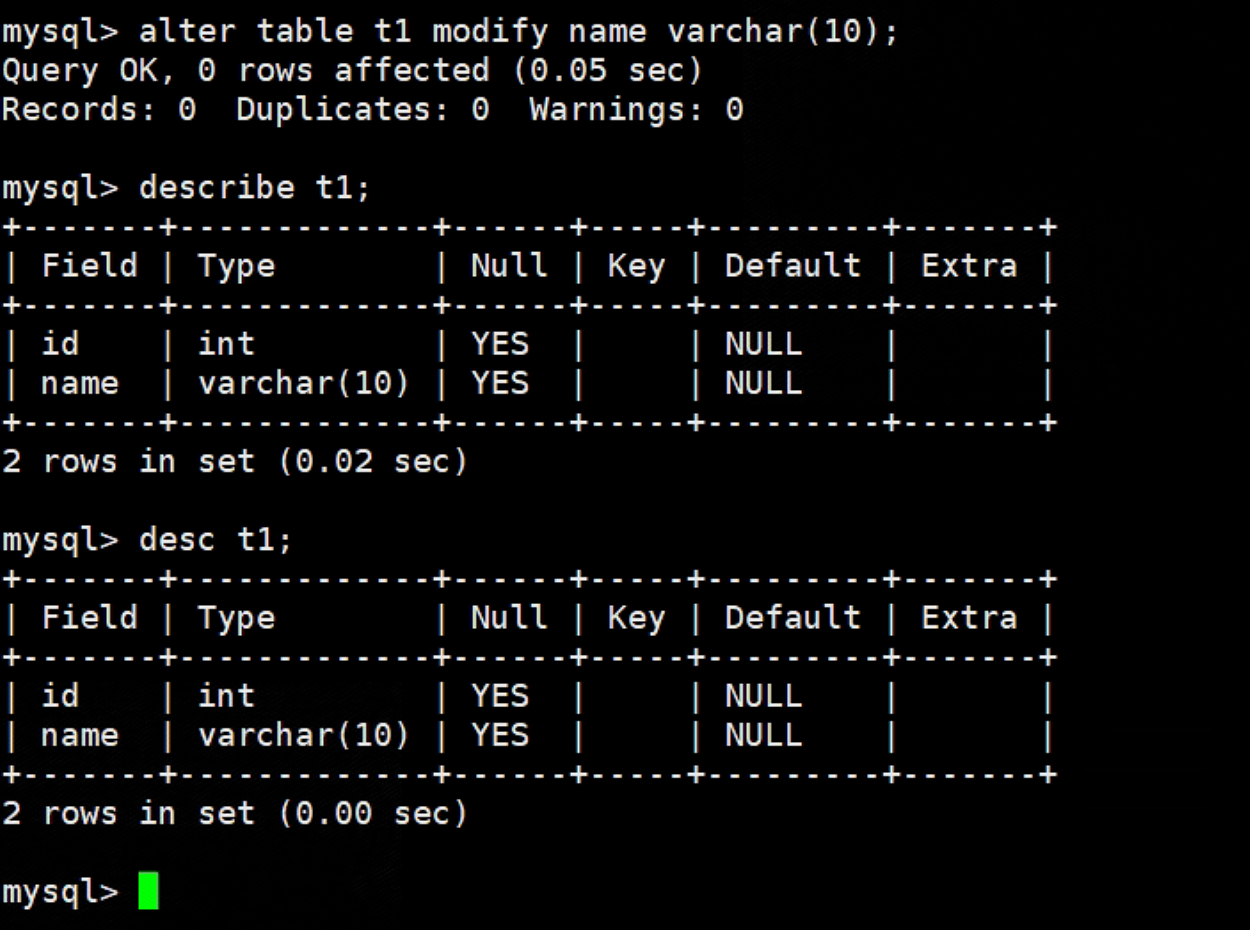
alter table t1 modify name varchar(10); # 更改表name属性的长度为10
![]()
-
- 查
-
show tables; # 查看表,对应是ls
-
describe t1; #展示详细字段 desc t1; #是上面的简写
- 删
-
drop table t1; # 删除表1 对应 rm t1

记录
create database day01; # 创建库
use day01 ;# 切入day01
create table t1(id int,name varchar(18)); # 创建表,并写好标题和属性
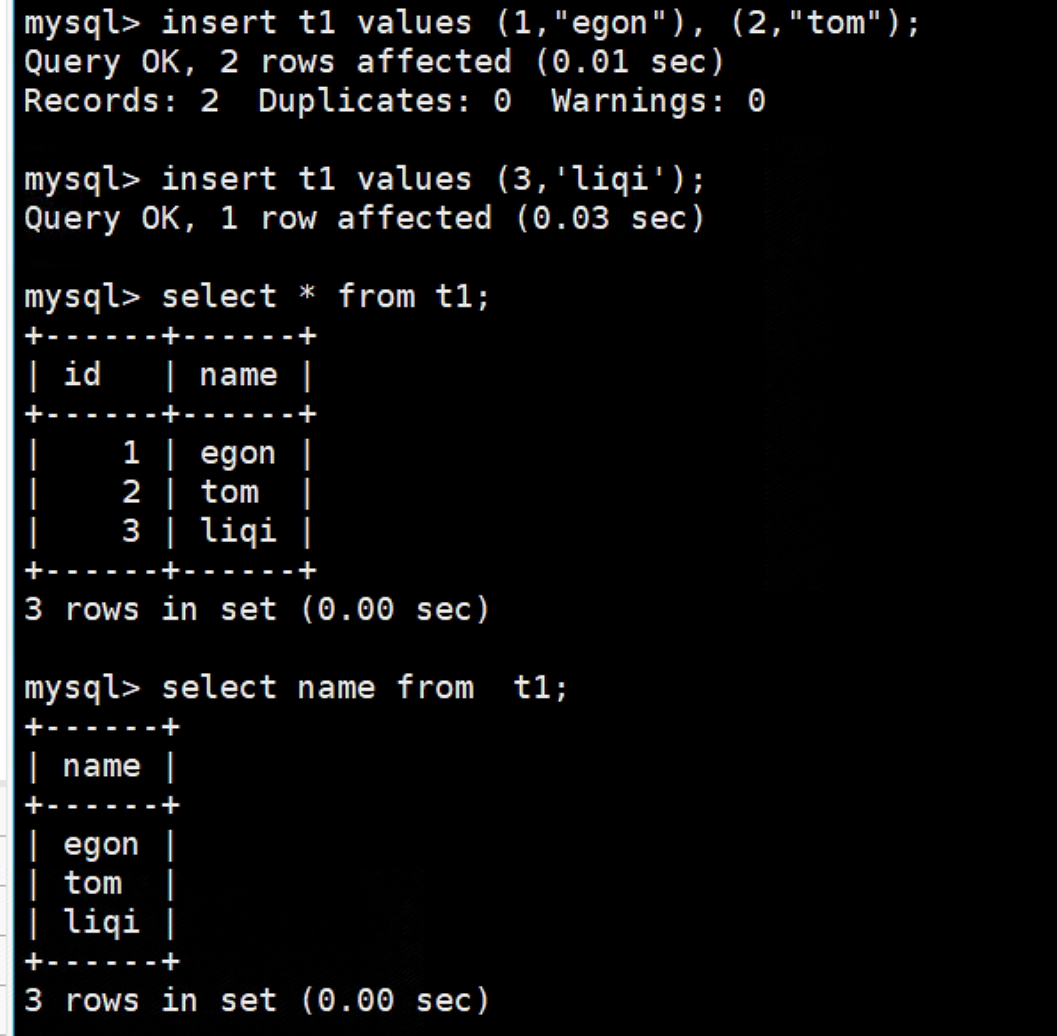
增
insert t1 values(1,"egon"),(2,"tom");
insert t1 values(3,'liqi'); # 这里双引号,单引号不敏感
改
-
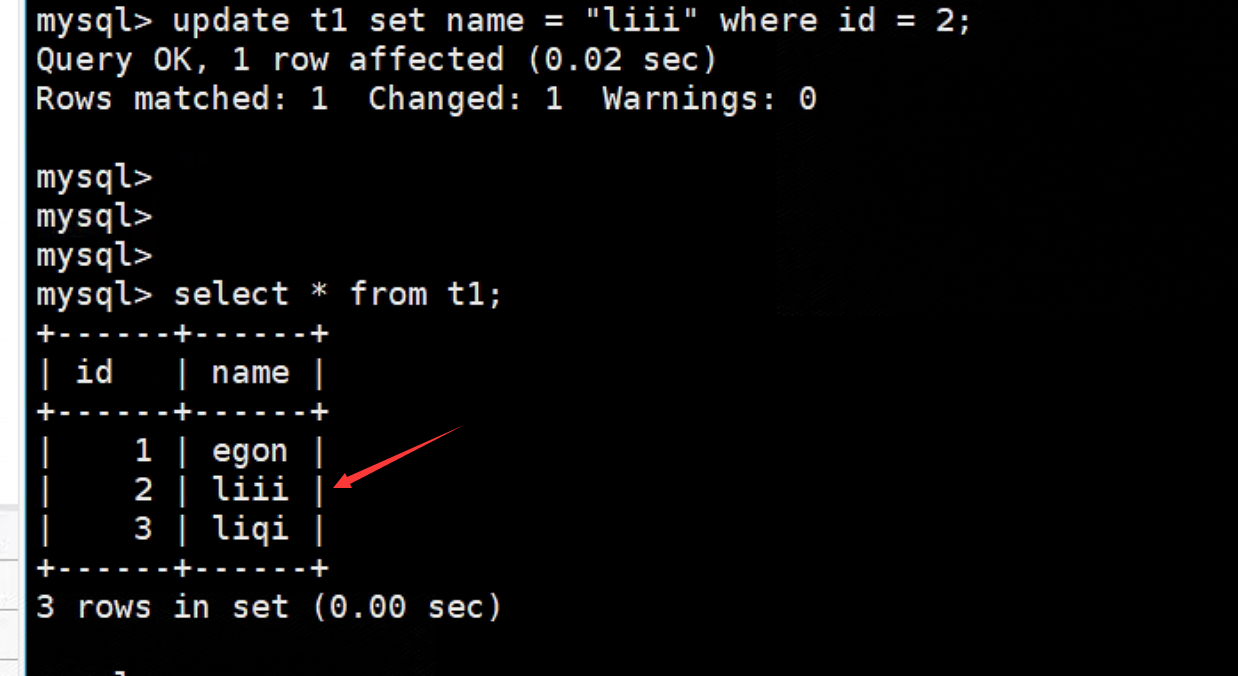
update t1 set name = "lili" where id = 2; # 把id等于2的改为lili
![]()
查
select * from t1; # 如果用绝对路径,就是select * from day01.t1 找day01库下面的t1表。
select name from t1; # 指定字段去查询
![]()
-
select * from t1 where id>=2; # 查找id大于等于2的
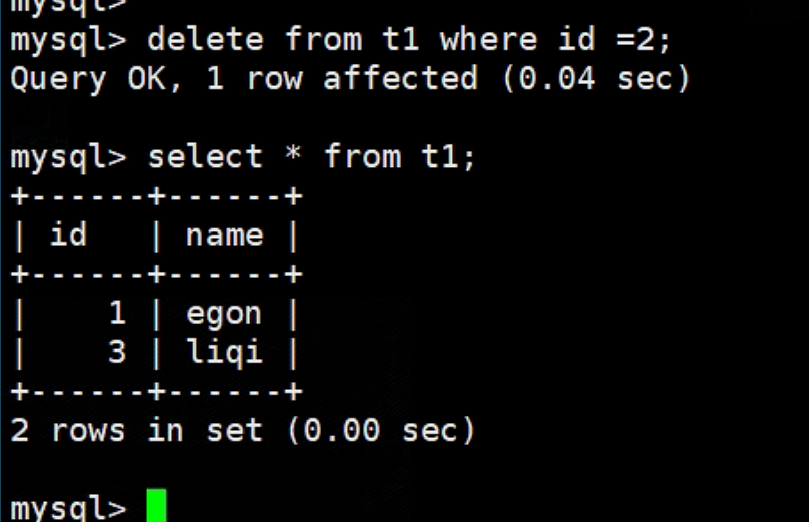
删
-
delete from t1; # 全部删除 delete from t1 where id =2; # 只删除id为2的
![]()
- 当有自增id字段时,用delete from t1;删除表的时候,还有保留id字段。
- 所以想恢复初始值的,用truncate [ˈtrʌŋkeɪt]
- truncate t1;
15.MySQL的语句小结
15.1 库
- 增
-
create databases db1 charset utf8mb4;
-
- 改
-
alter database db1 charset gbk;
-
- 查
-
show databases; select database(); show create database db1;
-
- 删
-
drop database db1;
-
15.2 表
use db1;
- 增
-
create table t1(id int,name varchar(10));
-
- 改
-
alter table t1 rename ttt1;
alter table ttt1 modify name varchar(8);
-
- 查
-
show tables; show create table ttt1; desc ttt1;
-
- 删
-
drop table ttt1;
-
15.3 记录
create database db1; use db1; create table t1(id int,name varchar(8));
- 增
-
insert t1 values (1,"egon"), (2,"tom");
-
- 改
-
update t1 set name = "xxx" where id =2;
-
- 查
-
select id,name from t1 where id =1; select * from t1 where id=1; select name from t1 where id =1;
-
- 删
-
delete from t1 where id =1; delete from t1; #会保留自增字段
truncate t1; # 不会保留自增字段
-
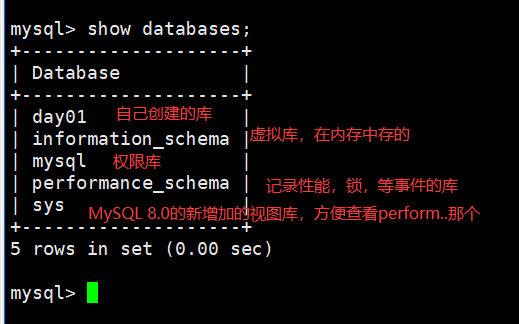
16.创建的时候,那四个表都是什么?
- 除了day01是我自己创建的,剩下的都是系统自带的。
- 说明见下图。
![]()
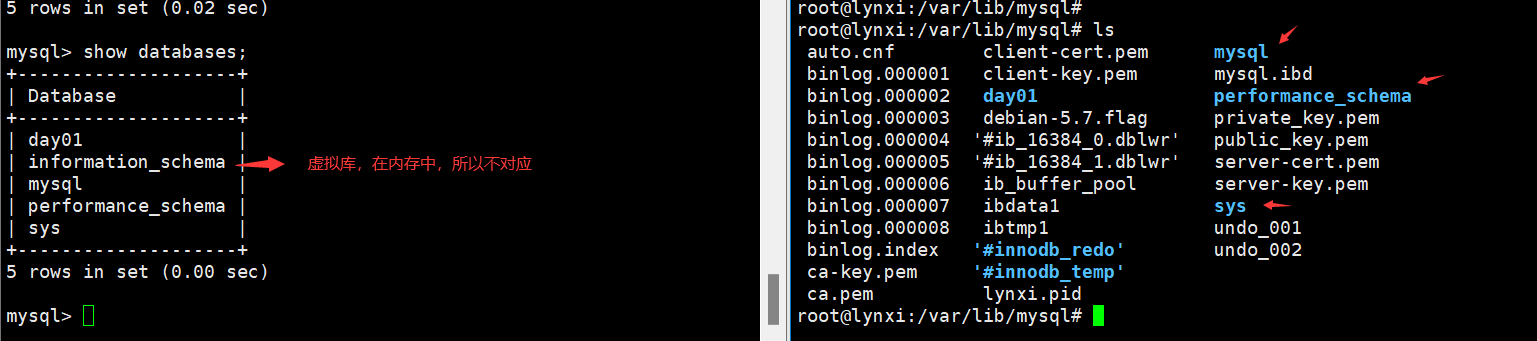
17.库对应都是文件夹?
- 对的。
![]()
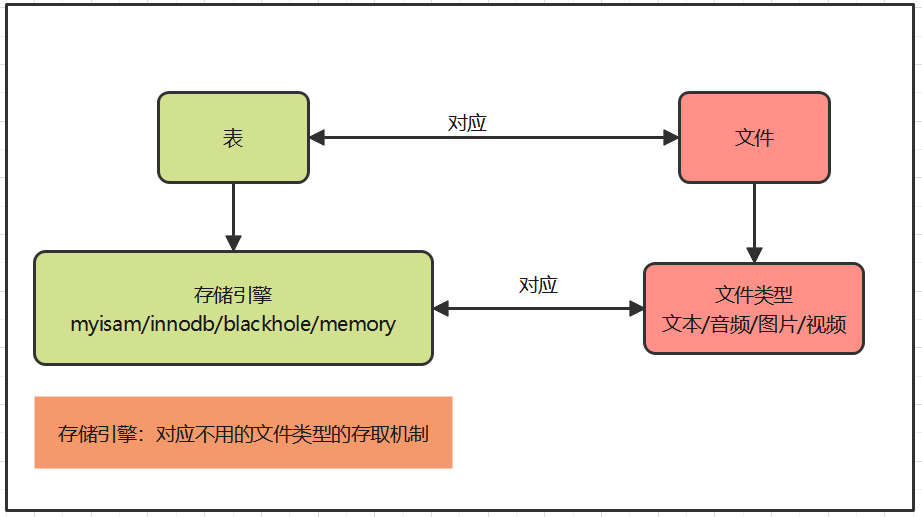
18.存储引擎是什么?
- 处理不同文件类型的一段代码。
![]()
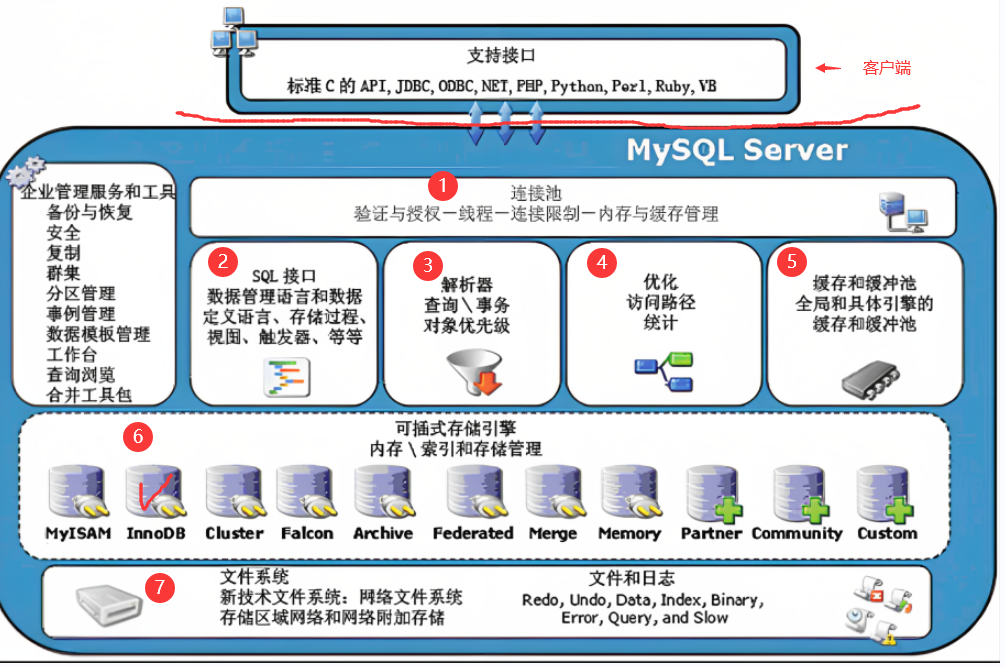
19.mysql的内部机制?
- 连接池-->SQL接口-->解析命令(是查询呀,还是更新)-->优化IO(减少文件的读写)-->缓存(看看缓存里面有没有)-->存储引擎(看看是用哪种储存引擎来打开)-->文件系统(最后打开)
![]()
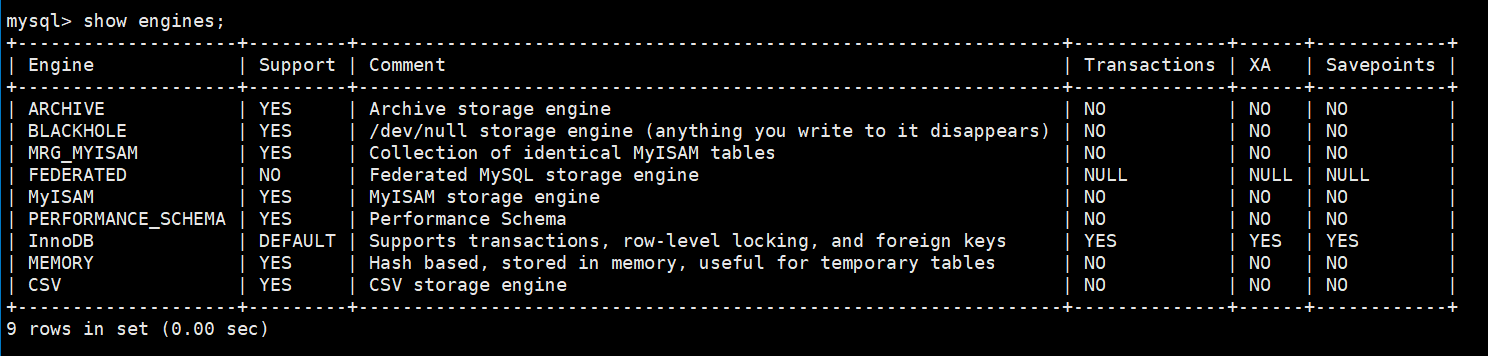
20.如何查看我的mysql支持哪些引擎?
-
show engines;
.
![]()
21.不同引擎的差异?
-
执行下面语句
-
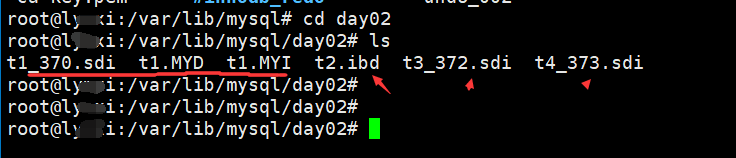
create database day02; use day02; # 创建 create table t1 (id int) engine = myisam; create table t2 (id int) engine = innodb; create table t3 (id int) engine = blackhole; create table t4 (id int) engine = memory; # 插入数据 insert t1 values (111); insert t2 values (111); insert t3 values (111); insert t4 values (111); # 查看数据 select * from t1; select * from t2; select * from t3; select * from t4;
- 可以看到myisam引擎会创建3个文件,innodb会创建1个,blackhole会创建1个,memory也会创建1个。
![]()
-
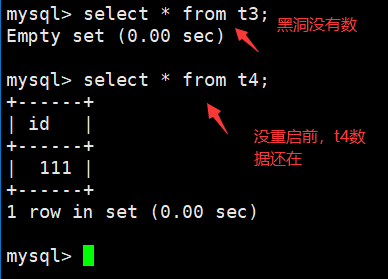
数据上,blackhole没有数据(黑洞吃掉数据,类似Linux系统的中的/dev/null),memory是存在内存里的(重启mysql的服务端,就没了)
![]()
22.什么叫虚拟表?
- 在内存上的表。不是在硬盘存在的表。
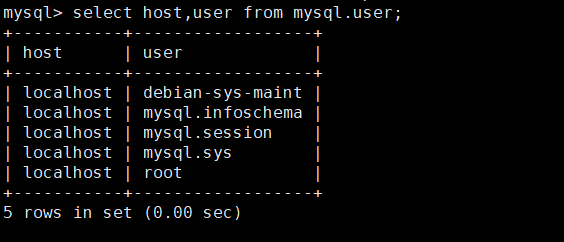
- 比如:筛选出mysql.user表里面的host和user
![]()
-
展示的过程是,从硬盘中读取mysql.user表,读到内存里,筛选出host和user这两个自动,打印到终端显示。
-
而下面的这个图,是展示mysql.user表的全部内容,这个就是硬盘的实际存在的表。
-
![]()
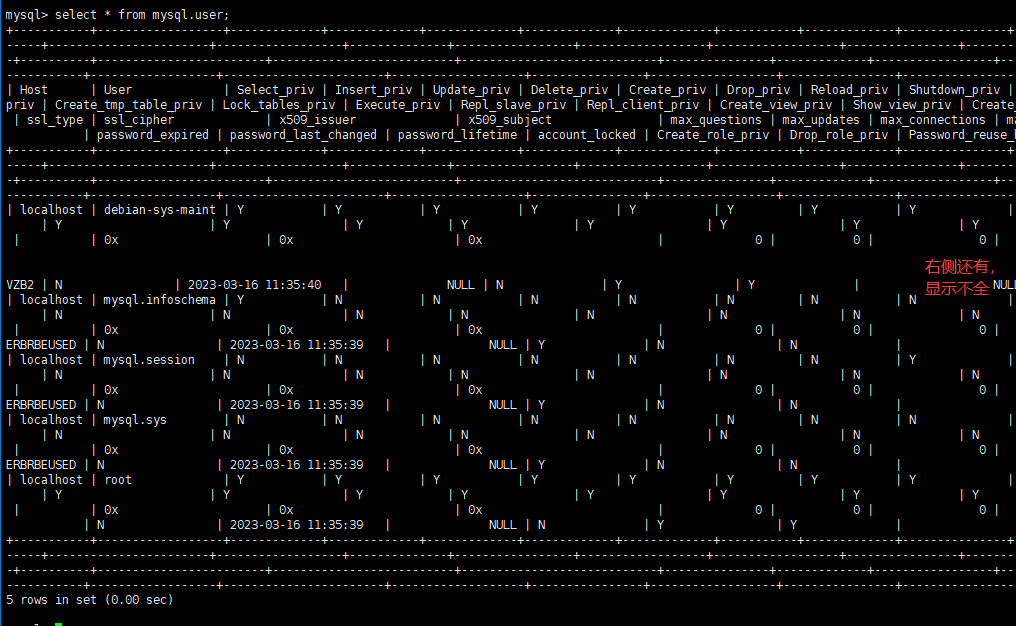
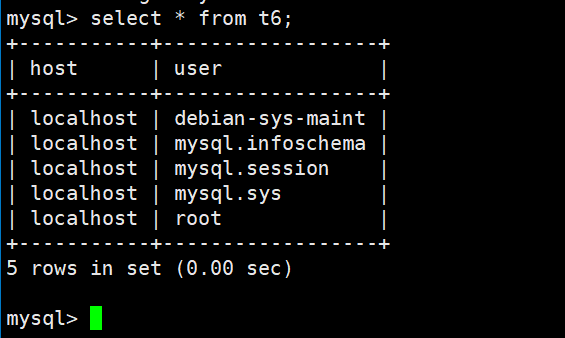
23.如何复制表呢?
- 在22的基础上,增加create t6
-
create t6 select host,user from mysql.user;
![]()
-
![]()
-
相当于把查询到的结果输出到t6表里

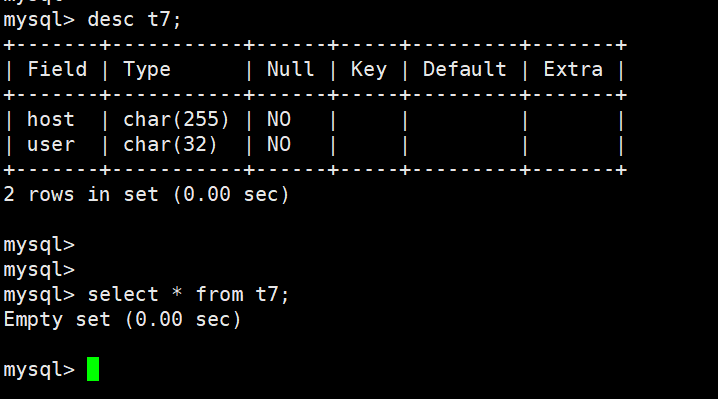
24.如何只复制表结构?
- 在23的基础上,增加一个where 为假的条件。
-
create table t7 select host,user from mysql.user where 1<0;
![]()
- 查看表结构,查看表内容
-
desc t7; select * from t7;
![]()

25.数据类型--整形
- 其他都是存储宽度
- 整型的宽度是例外
- int不指定宽度,非要指定的话,()括号里指的是显示宽度,
- 但是超过的话,也会显示。
- 所以,不用指定。
26.数据类型--浮点型
- float(255,30) 意思是最长255位数字,小数部分最长30位
27.数据类型--日期
- datetime和timestamp区别是
- timestamp可以自动添加默认值
- datetime范围比timestamp大
- timestamp存储空间为4字节,datetime使用8字节
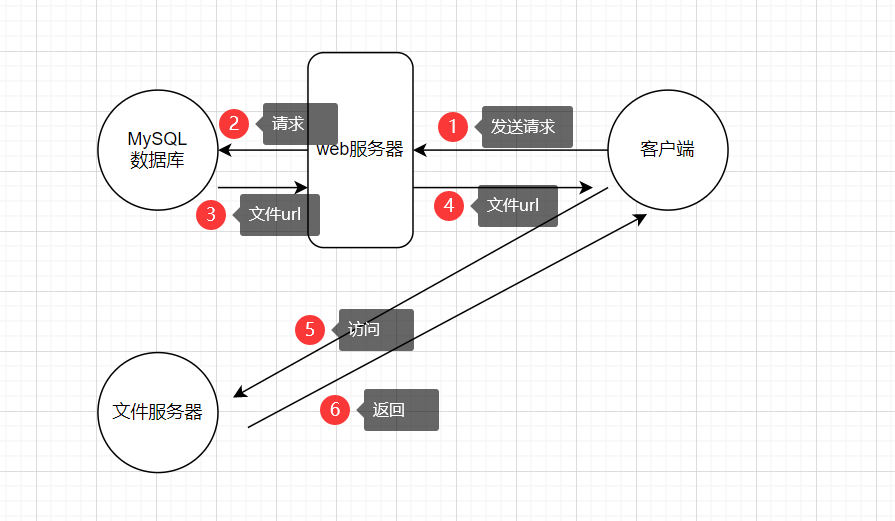
28.大文件在数据库中怎么存的?
- 大文件一般都是放在专门的文件服务器上
- 实际场景中,MySQL一般是存储文件的url,再由客户端通过Url去访问大文件。
![]()
29,查询中,等号查询是会忽略空格?
- 是的
30,like查询,不会忽略末尾的空格?
- 是的。
- like里面,用_代表一个任意字符
- like里面,用%代表无穷多个任意字符。
31.在查询角度,varchar比char更方便?
- 是的。
- 因为varchar中存的是实实在在的数据。
32.约束条件是什么?
- 约束条件是对数据类型进行的一种补充说明。
- 例如:约束条件中的主键,外键,能否为空,是否唯一,默认值,自动增长等。
33、innodb是索引组织表?
- 是的。
34.innodb和myisam区别是什么
- innodb和myisam都是mysql的存储引擎。
- 在锁的实现方式不一样。
- innodb是会锁定表的特定行。
- myisam是会锁定整个表。
35.innodb内部一定有一个主键?
- 是的。内部实现方式时b+树。
36.为什么不能把所有数据写到同一张表里?
- 不方便读写,改动麻烦。
-
通常情况下,将所有数据都写入一张表中并不是一个好的设计选择,因为这可能会导致以下问题:
-
数据冗余:如果将所有数据都写入一张表中,那么可能会导致大量的数据冗余,即相同或类似的数据在多个记录中重复出现,从而浪费存储空间并增加了数据更新和维护的难度。
-
缺乏灵活性:将数据分散到不同的表中,可以更好地组织和管理数据。如果将所有数据都放在一个表中,那么可能会导致数据结构过于复杂,难以管理和查询。
-
性能问题:如果所有数据都存储在一张表中,那么可能会导致查询性能下降,因为在单个表中查询大量数据时,需要处理的数据量非常大,可能会导致查询变慢。
因此,通常情况下,我们应该将数据分散到不同的表中,并使用关系型数据库的特性(如外键)将它们连接起来,以便更好地组织和管理数据,并提高查询性能。——《chatGPT》
-
37.表与表之间建立关联关系
- 创建表
-
# 先创建被管理的表 create table dep( id int primary key auto_increment, name varchar(20), comment varchar(50) ); # 再创建管理的表 create table emp( id int primary key auto_increment, name varchar(16), age int, dep_id int, foreign key(dep_id) references dep(id) on update cascade on delete cascade );
- 说明:
- on update cascade 同步关联更新
- on delete cascade 同步关联删除
- 查看
-
# 查看一下 desc emp; desc dep;
![]()
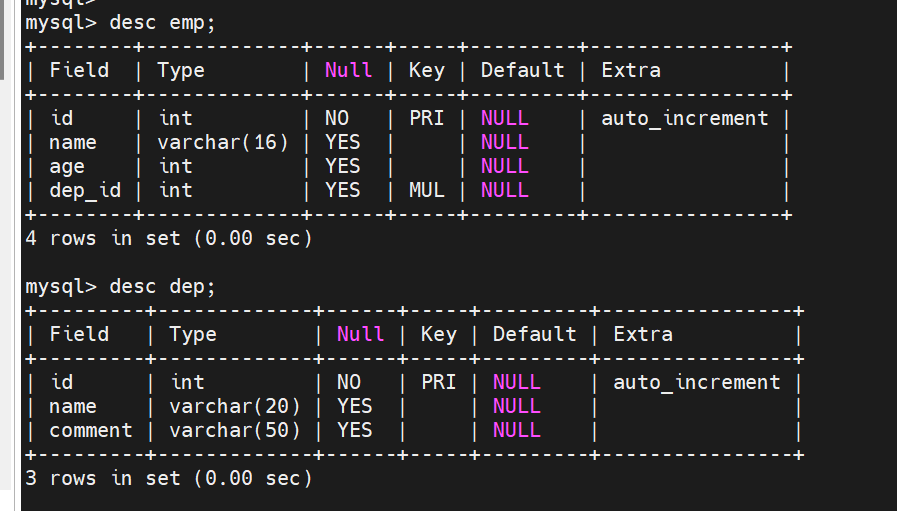
38.如何插入数据?
-
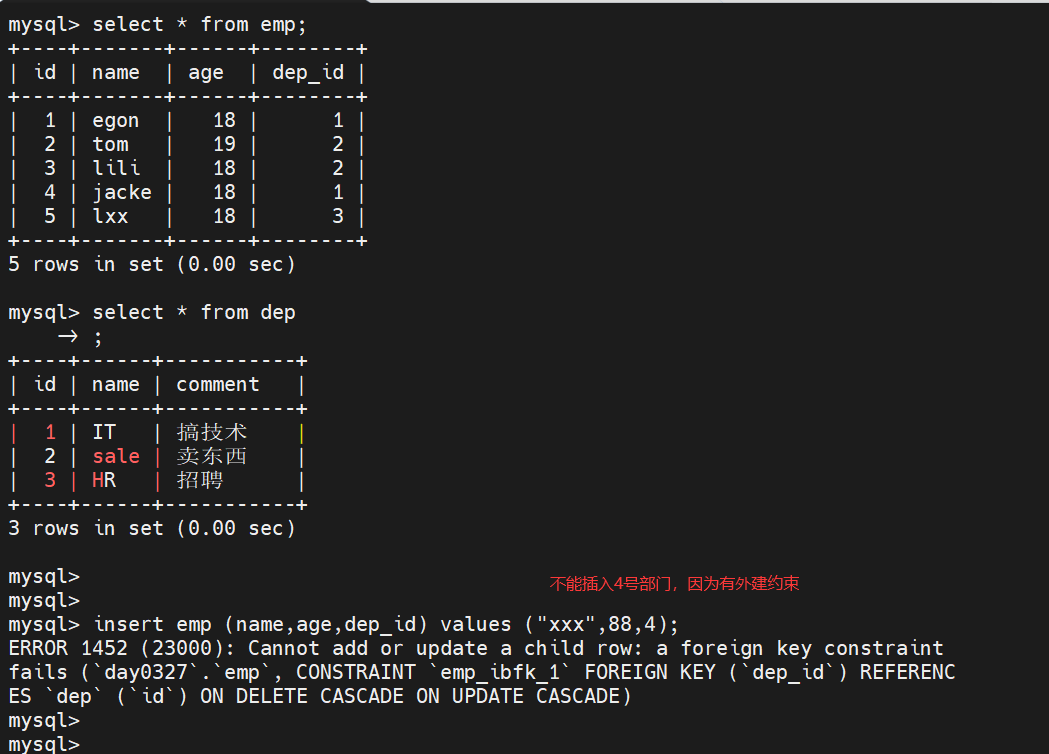
# 插入数据的时候,应该先往dep部门表,插入数据,再往emp员工表插入数据 insert dep (name,comment) values ('IT','搞技术'), ('sale','卖东西'), ('HR','招聘'); insert emp(name,age,dep_id) values ('egon',18,1), ('tom',19,2), ('lili',18,2), ('jacke',18,1), ('lxx',18,3);
39.有外键约束的情况下,能否插入约束以外的?
- 不可以。
![]()
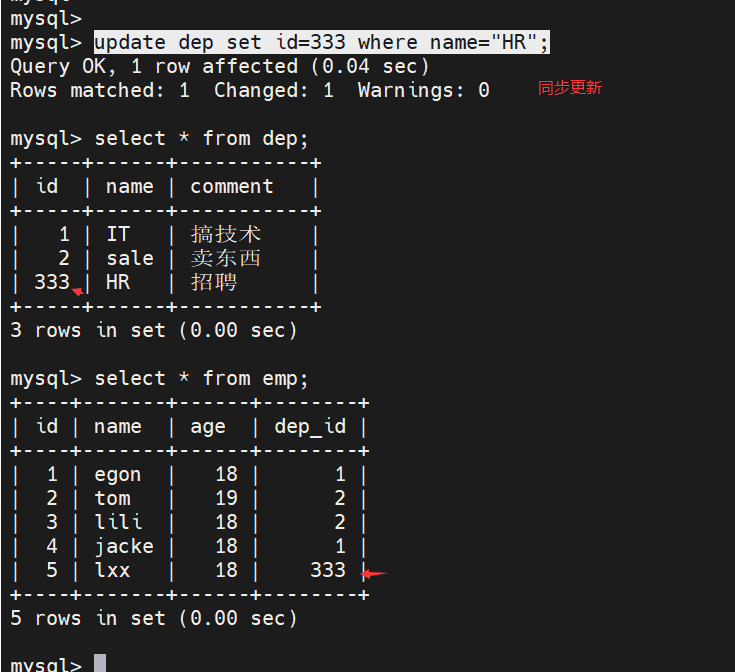
40.级联更新演示?
- 会同步更新。
-
update dep set id=333 where name="HR";
![]()
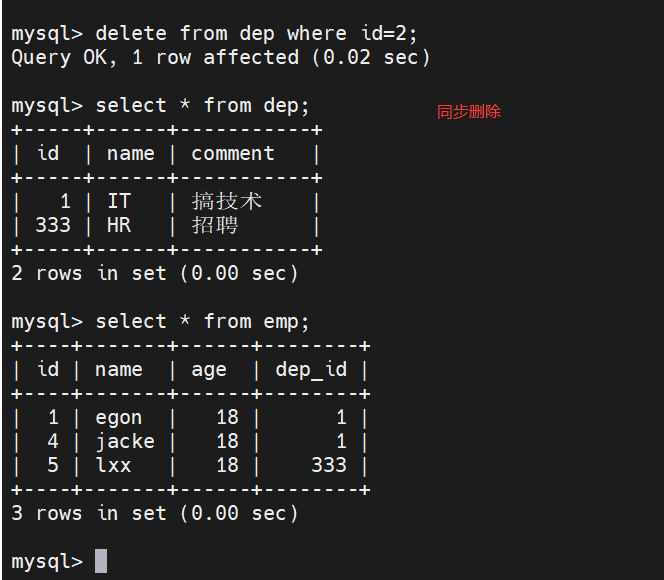
41.同步删除演示:
- 例如删除2号销售部门,销售的部门的员工都解散了。
-
delete from dep where id=2;
![]()
42.外键的优劣?
-
会把两张表强耦合在一起
- 看你个人需求
43.什么是多对一,什么是多对多?
- 构建多对多,通过建立第3张表来实现。
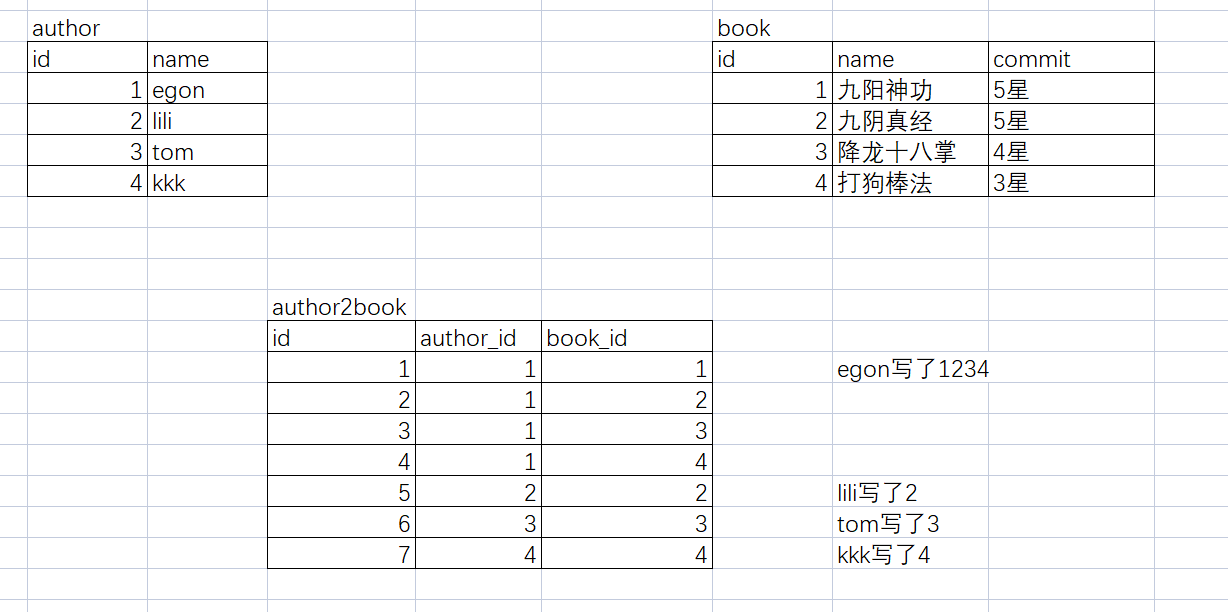
44.如何区分表与表之间的关联关系?
- 先把一个大表拆分成小的。
- 再站在A表,去思考B表。
- 再站在B表,去思考A表。
45.如何创建多对多的关联表?
-
# 多对多的创建 create table author( id int primary key auto_increment, name varchar(16) ); create table book( id int primary key auto_increment, name varchar(20) ); create table author2book( id int primary key auto_increment, author_id int, book_id int, foreign key(author_id) references author(id) on update cascade on delete cascade, foreign key(book_id) references book(id) on update cascade on delete cascade );
-
![]()
46.一对一怎么关联?
- 原则:在少的那边,建立forergn key 外键
![]()
![]()

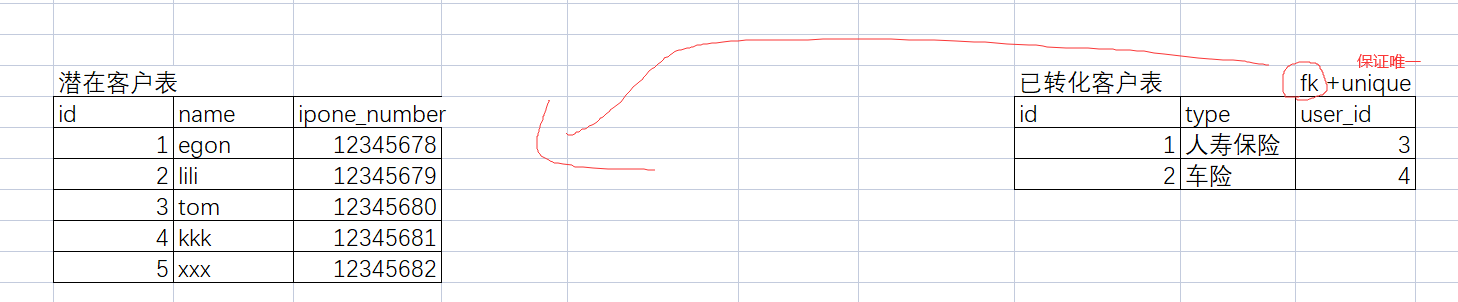
47.foreign key这个字段一定保证我的字段时来自于别人的。
- 不加unique唯一性,就有可能是多对1的关系。
- 加了unique唯一性,就是一对一的关系。
48.数据库表的结构决定整个项目的基石?
- 是的。
- 所以,设计好表的结构很重要。
49.如何设计好表的结构?
- ①专门的数据放在专门的表里。
- ②表与表之间建立好关系。
- ③在有争议的时候,能用多对多,就不用多对一;能用多对一,就不用一对一;或者不用foreign key
50.单表查询的语法?
select distinct 字段1,字段2,字段3 from 库.表 where 条件 group by 分组字段 having 条件 order by 排序字段 limit 限制条数;
distinct 【dɪˈstɪŋkt】 不同的,明显的。dis分开,tinct =stinct刺。把刺分开,表示明显的,不同的,去重的。
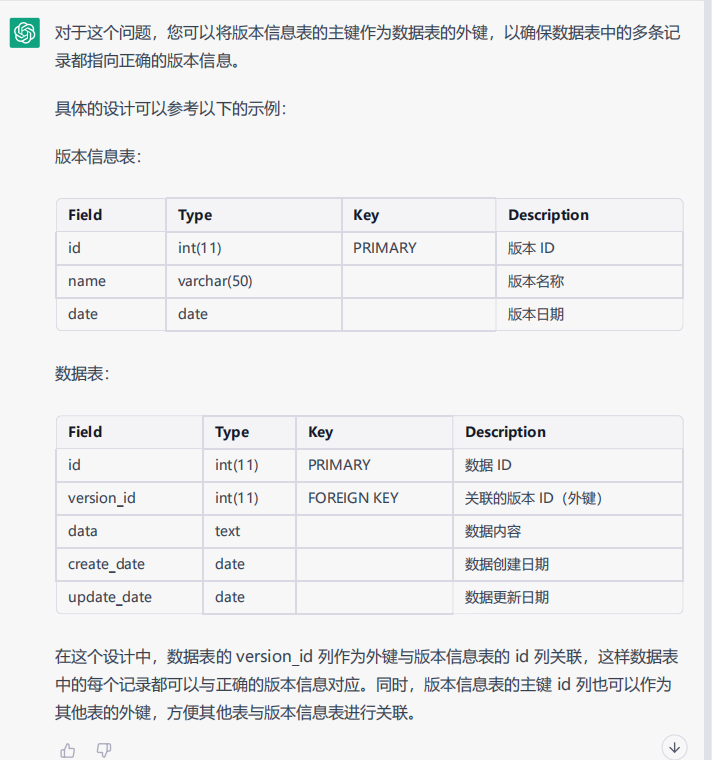
51.mysql设计表的时候,我有一个版本信息表,还有一个数据表,这个数据表里面会有多条数据指向同一一个版本信息,我该如何设计这两个表?
52. where和group by 区别是什么?
- where是过滤掉一些,去掉一些。
- group by 不会去掉。是分组的意思。
- 比如 查看每个部门的薪资情况。
- 这里的“每”后面,就是分组的依据。
53. group by 不能select * from xxx?
- 是的
- group只能显示要分组的那个列,可以和聚合函数max | min | count | sum | avg 等连用。
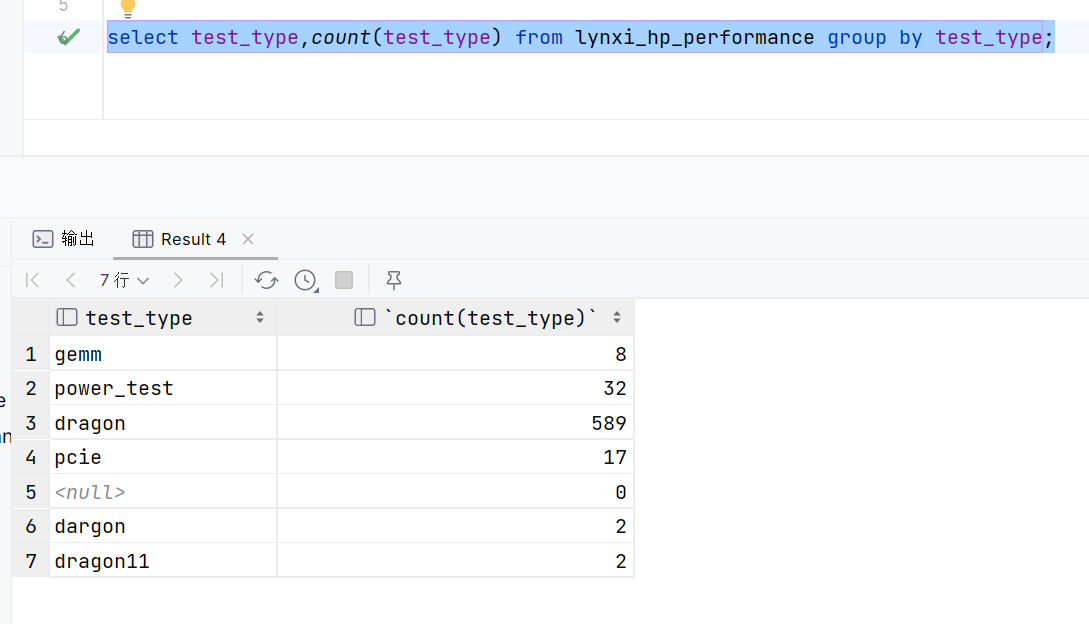
-
select test_type,count(test_type) from lynxi_hp_performance group by test_type;
![]()
54.如何取出每个部门男员工的平均薪资?
- 先用where 筛选出男,
- 再用group by 筛选出部门。
- 最后算平均值
- (怎么感觉跟做英语分析似的)
-
select * from emplyee where sex = '男';# 第一步 select * from emplyee where sex = '男' group by post ;# 第二步 select post ,avg(salary) from emplyee where sex = '男' group by post ; # 第三步
55. having是什么?
- 是分组后的过滤,可以理解是后处理。where是前处理。
- 示例:取出男员工平均薪资大于10000的部门。
-
select post,avg(salary) from emplyee where sex = '男' group by post having avg(salary) >10000;
- 相当于在54的最后一步,增加了一个having 后处理。
56.可以在where后面加聚合函数吗?
- 不可以
![]()

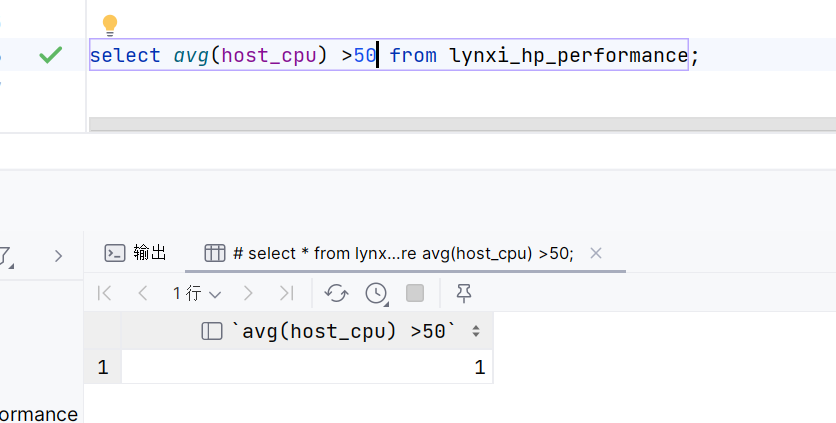
57.可以在select avg(host_cpu) from xxx;
- 可以
![]()
58.order by使用
- 默认升序。加desc就是降序
- 示例:
-
select id,test_type,produce_name,host_mem,host_cpu from lynxi_hp_performance order by host_mem asc ; select id,test_type,produce_name,host_mem,host_cpu from lynxi_hp_performance order by host_mem desc ;
- 示例2:在年龄一样的情况下,再按照id降序排列。
-
select * from employee order by age , id desc;
![]()
-
示例3 : 取出男员工薪资平均大于10000的部门,且按照平均薪资的降序排列。(在55之后增加order by)
-
select post,avg(salary) from emplyee where sex = '男' group by post having avg(salary) >10000 order by avg(salary) desc;

59.limit 限制显示条数。
-
示例1:取前10条
-
select * from employee limit 10;
- 示例2:按照位置取第90到第95条 (对应分页的效果)
-
select * from employee limit 90,5;
- 实际中,分页不一定靠limit实现,效率一般。会考虑缓存,python中的生成器,迭代器等。
60.regexp 正则表达
- mysql支持正则表达式。
- 示例:筛选出Lyn开头的
-
select test_type,sdk_version from lynxi_hp_performance where sdk_version regexp 'Lyn*';
61.练习多表查询
- 插入数据
-
#建表 create table department( id int, name varchar(20) ); create table employee( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into department values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into employee(name,sex,age,dep_id) values ('egon','male',18,200), ('alex','female',48,201), ('wupeiqi','male',38,201), ('yuanhao','female',28,202), ('liwenzhou','male',18,200), ('jingliyang','female',18,204) ;
62.多表查询--内连接
- SQL语句是
# 内连接 用where形式 select * from employee,department where employee.dep_id = department.id; # 内连接 select * from employee inner join department on employee.dep_id =department.id; select * from employee e inner join department d on e.dep_id = d.id;
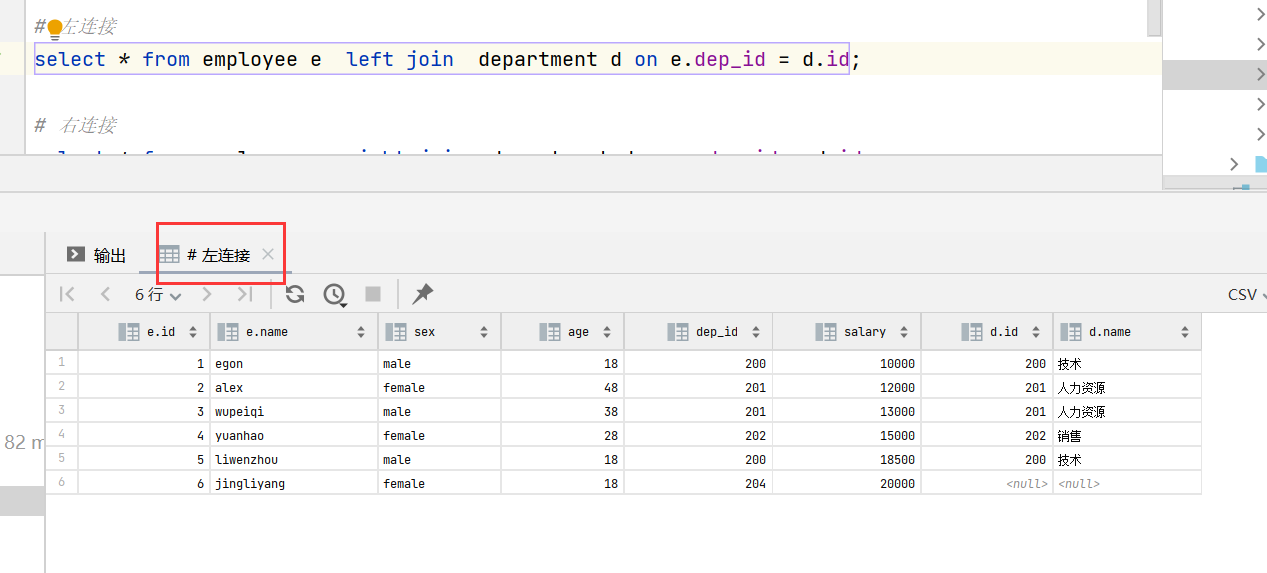
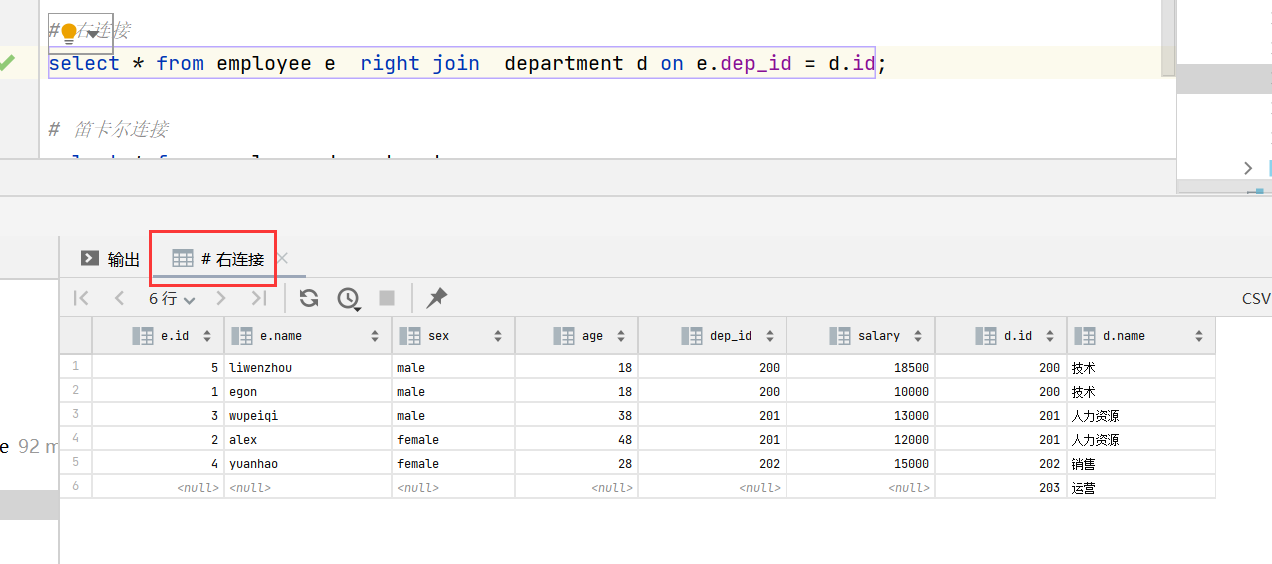
63.多变查询--左右连接
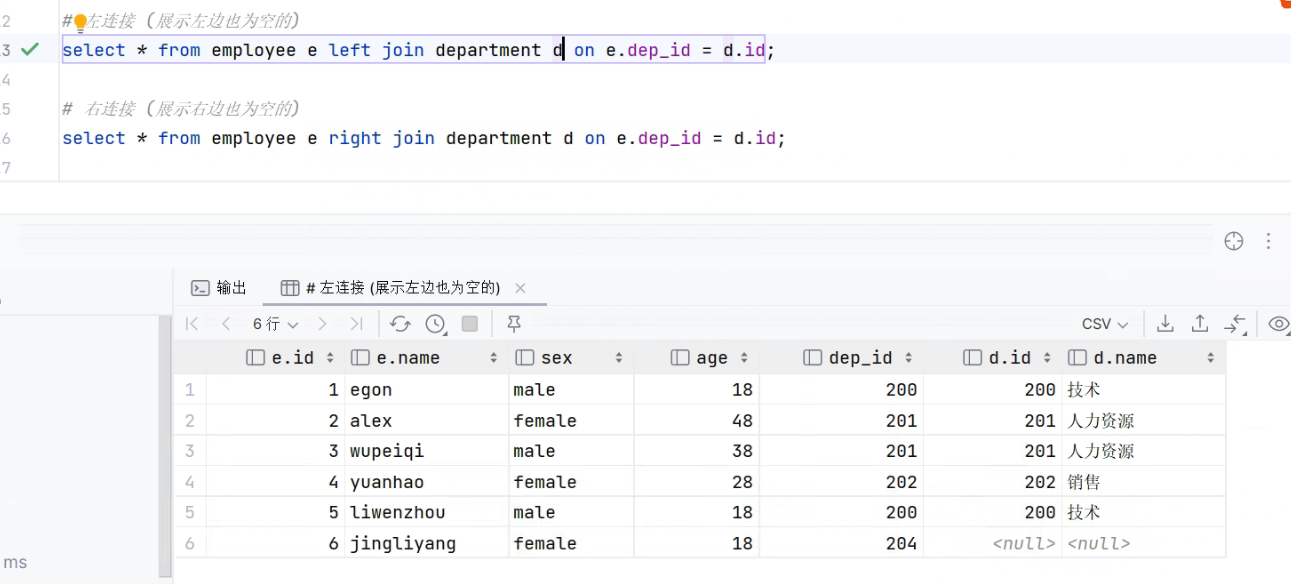
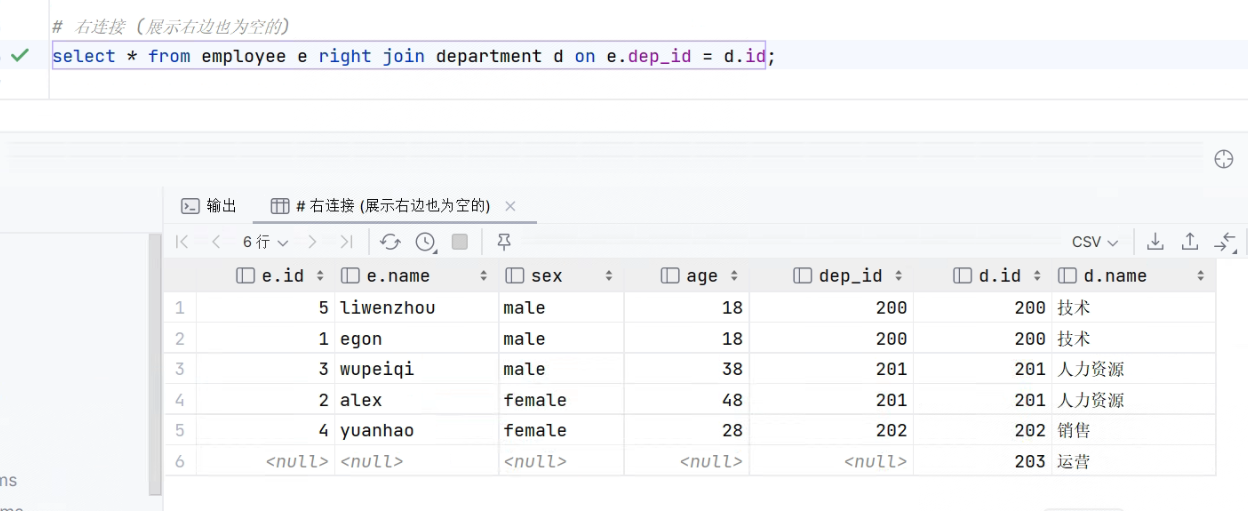
-
# 左连接 (展示左边也为空的) select * from employee e left join department d on e.dep_id = d.id; # 右连接 (展示右边也为空的) select * from employee e right join department d on e.dep_id = d.id;
![]()
![]()
64.左连接是?
- 在内连接的基础上保留左表多余记录。
65.右连接是?
- 在内连接的基础上保留右表多余的记录。
65.5 小结--内连接,左连接,右连接,笛卡尔连接
- employee表的内容为:
![]()
- department表的内容:
![]()
![]()
-
![]()
-
![]()
-
![]()
-
![]()
-
![]()
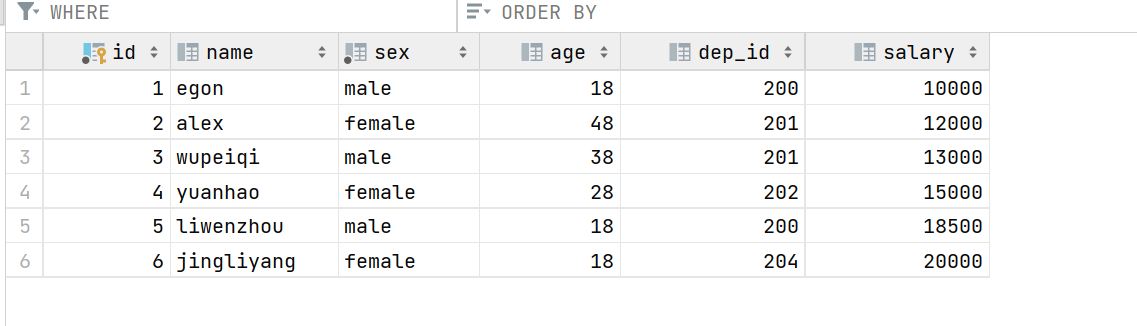
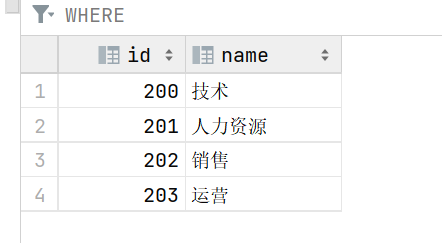

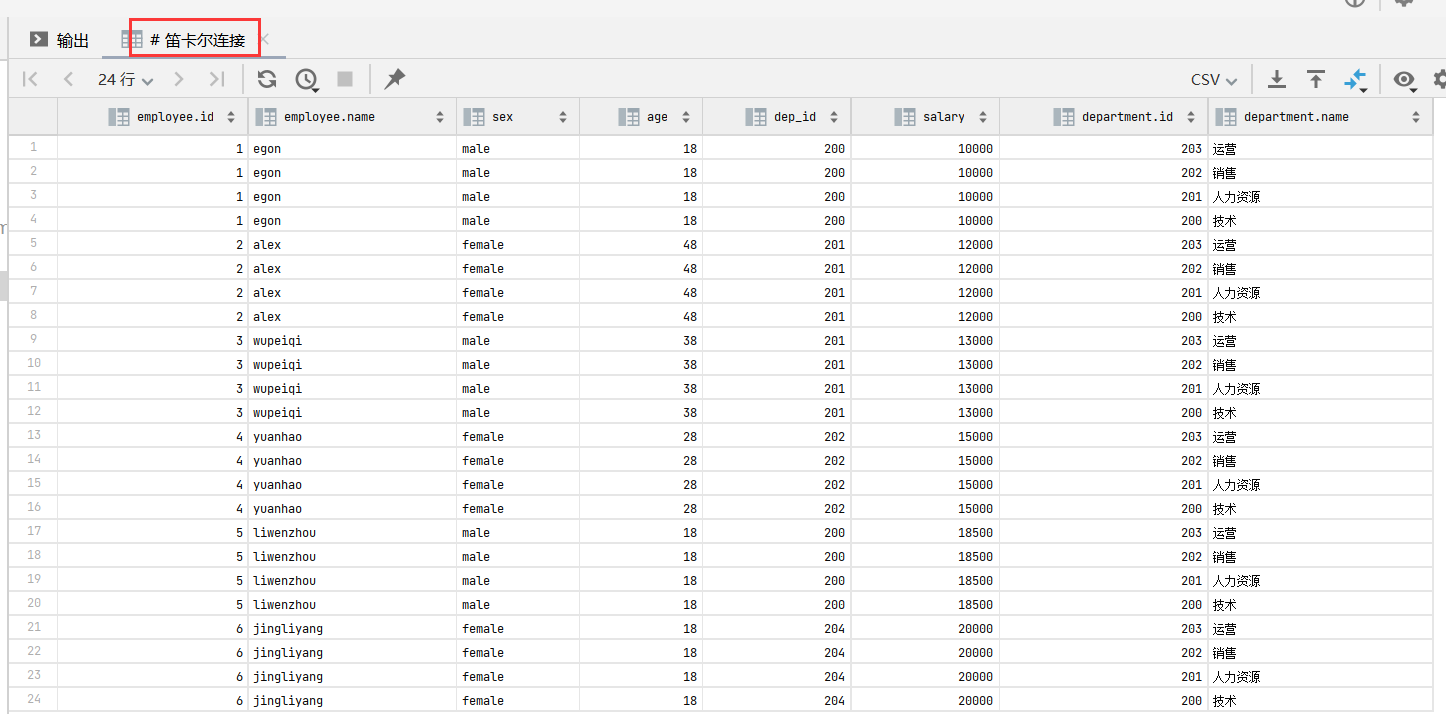
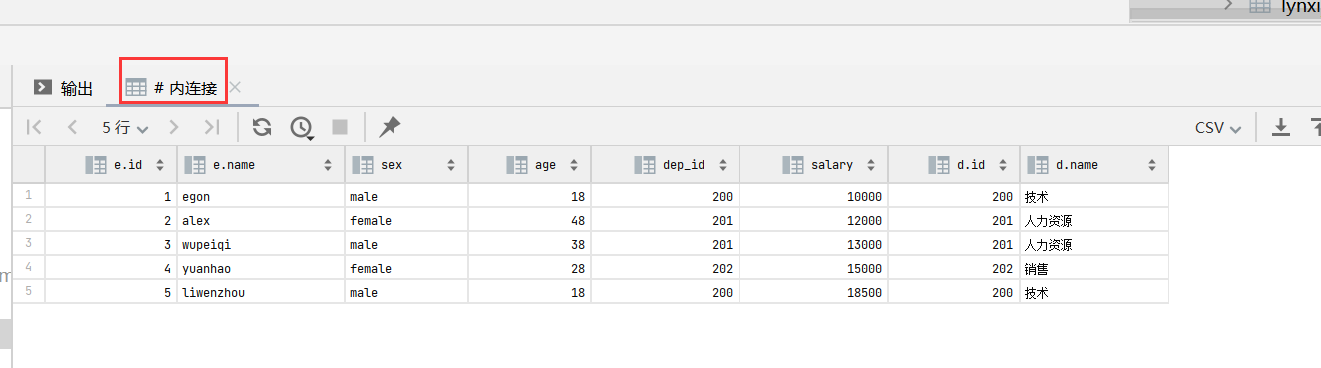

66.多表查询--全外连接
- full json
- 在MySQL不支持
- 所以用下面的语句
-
select * from employee e left join department d on e.dep_id = d.id union select * from employee e right join department d on e.dep_id = d.id;
![]()

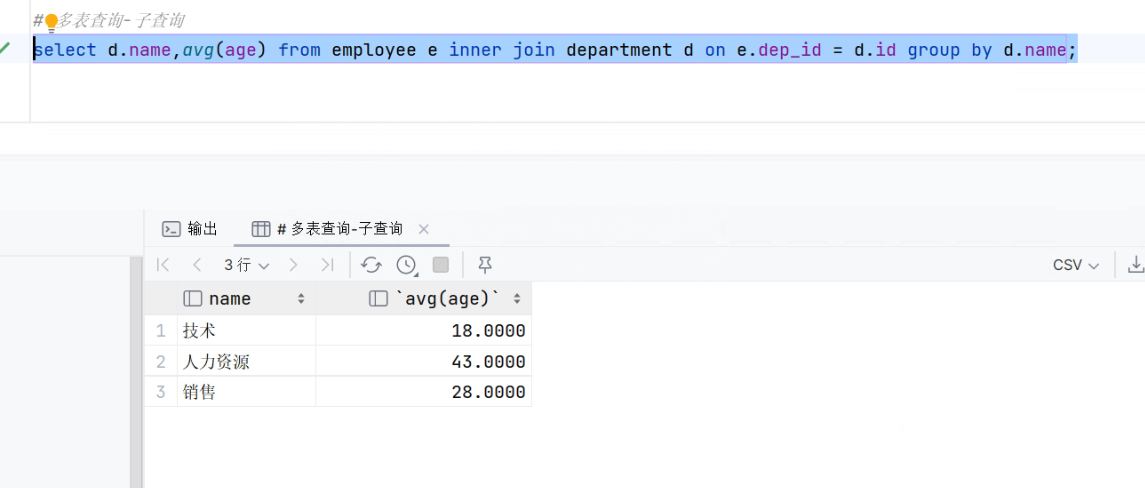
67.多表查询--符合条件的查询
- SQL
-
select d.name,avg(age) from employee e inner join department d on e.dep_id = d.id group by d.name;
![]()
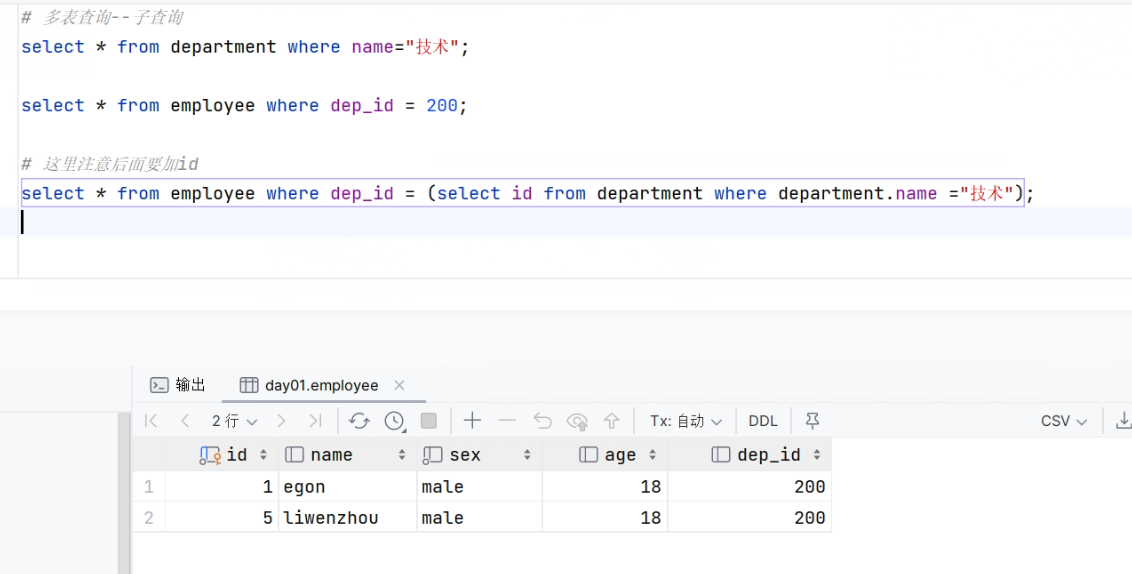
68.把第一个表的结果作为条件,查询第二个表。
- SQL
-
# 多表查询--子查询 select * from department where name="技术"; select * from employee where dep_id = 200; # 这里注意后面要加id select * from employee where dep_id = (select id from department where department.name ="技术");
![]()
69.多表查询--子查询 in的形式
- SQL
-
# 查询技术部和销售部的人员 # ① 先找子查询 select id from department where name="技术" or name="销售"; # ② 再查询 select * from employee where dep_id in (select id from department where name="技术" or name="销售");
![]()
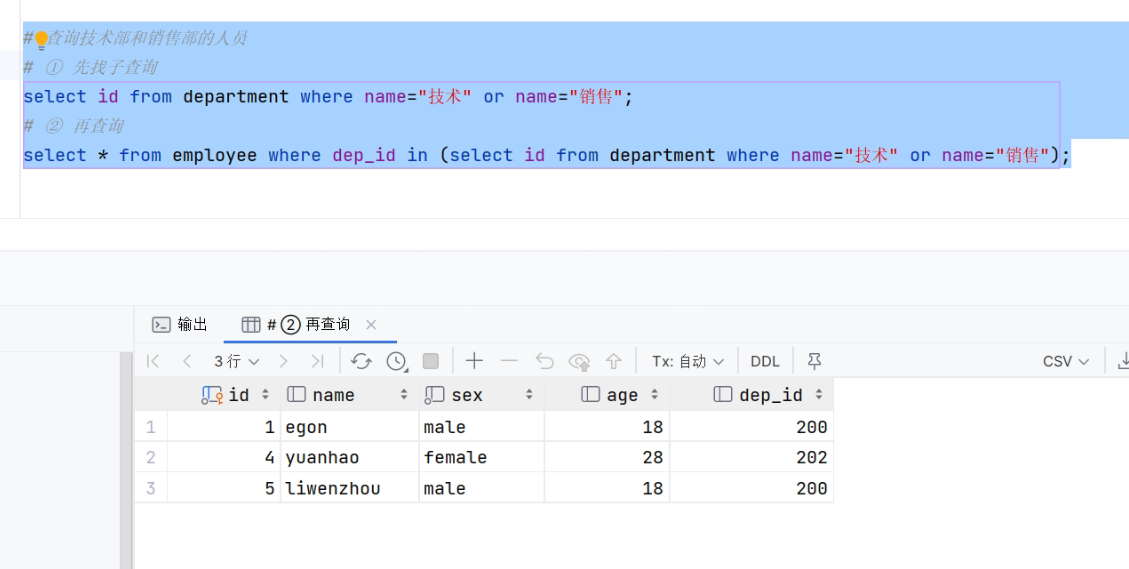
70.any的用法
- 一般和<>连用。意思是,大于/小于任意一个值。
- SQL
-
# any 一般和大于号 小于号连用。和等号=连用 效果等于in,区别是any 只能接select语句,in可以接数组 select * from employee where dep_id > any (select id from department where name="技术" or name="销售"); # 上面的会查询出201,202,204的结果 # 查询出小于销售202的 select * from employee where dep_id < any (select id from department where name="销售");
![]()
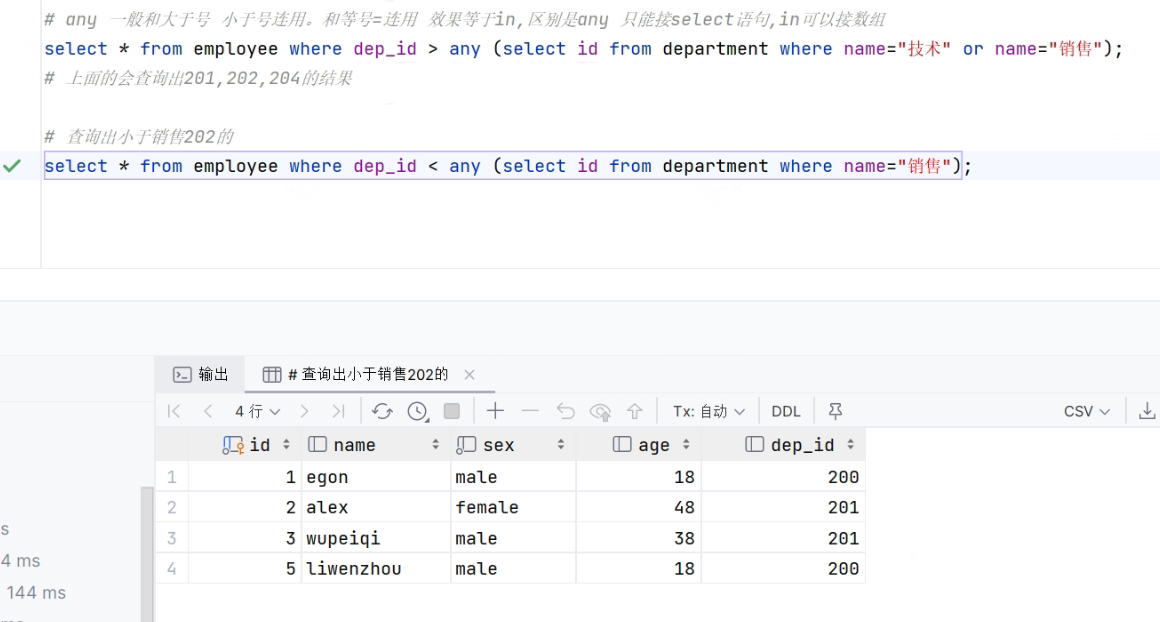
71.筛选出部门里比平均工资高的。
- SQL
-
# 筛选平均薪资 select avg(salary) from employee ; # 筛选比平均薪资高的 select * from employee where salary > any (select avg(salary) from employee ) ; # 筛选部门的平均薪资 select avg(salary) from employee group by dep_id; # 筛选部门里出比平均薪资高的 select * from employee where salary > any (select avg(salary) from employee group by dep_id) ;
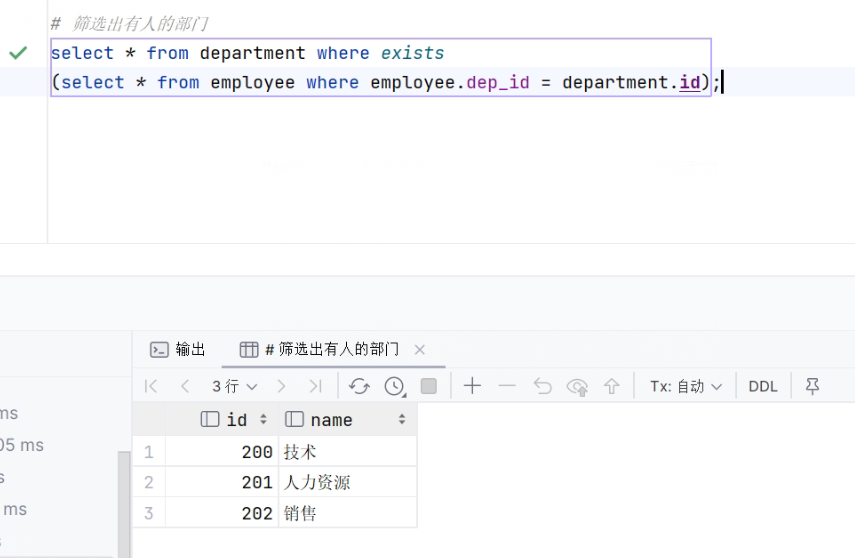
72. 筛选出有人的部门,利用exists
- SQL
-
# 筛选出有人的部门 select * from department where exists (select * from employee where employee.dep_id = department.id);
![]()
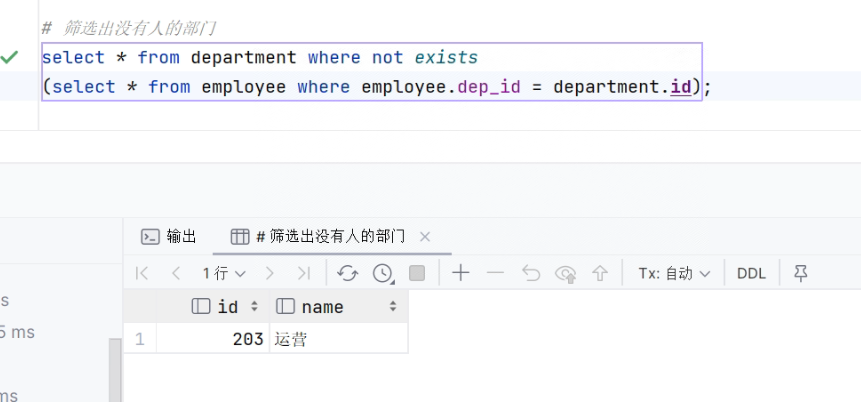
73.筛选出没有人的部门 not exists
- SQL
-
# 筛选出没有人的部门 select * from department where not exists (select * from employee where employee.dep_id = department.id);
![]()
74.找出部门里最新入职的员工。
- 创建表
-
create table employee( id int not null unique auto_increment, name varchar(20) not null, sex enum('male','female') not null default 'male', #大部分是男的 age int(3) unsigned not null default 28, hire_date date not null, post varchar(50), post_comment varchar(100), salary double(15,2), office int, #一个部门一个屋子 depart_id int ); desc employee; #插入记录 #三个部门:教学,销售,运营 insert into employee(name,sex,age,hire_date,post,salary,office,depart_id) values ('egon','male',18,'20170301','老男孩驻沙河办事处外交大使',7300.33,401,1), #以下是教学部 ('alex','male',78,'20150302','teacher',1000000.31,401,1), ('wupeiqi','male',81,'20130305','teacher',8300,401,1), ('yuanhao','male',73,'20140701','teacher',3500,401,1), ('liwenzhou','male',28,'20121101','teacher',2100,401,1), ('jingliyang','female',18,'20110211','teacher',9000,401,1), ('jinxin','male',18,'19000301','teacher',30000,401,1), ('成龙','male',48,'20101111','teacher',10000,401,1), ('歪歪','female',48,'20150311','sale',3000.13,402,2),#以下是销售部门 ('丫丫','female',38,'20101101','sale',2000.35,402,2), ('丁丁','female',18,'20110312','sale',1000.37,402,2), ('星星','female',18,'20160513','sale',3000.29,402,2), ('格格','female',28,'20170127','sale',4000.33,402,2), ('张野','male',28,'20160311','operation',10000.13,403,3), #以下是运营部门 ('程咬金','male',18,'19970312','operation',20000,403,3), ('程咬银','female',18,'20130311','operation',19000,403,3), ('程咬铜','male',18,'20150411','operation',18000,403,3), ('程咬铁','female',18,'20140512','operation',17000,403,3) ;
- 查询SQL
-
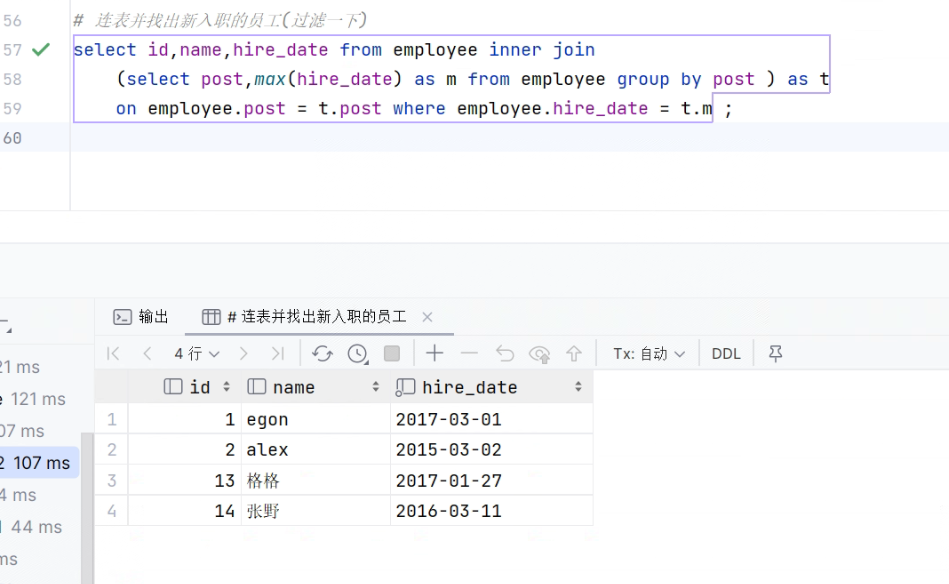
# 查找部门最新入职的员工 select post,max(hire_date) from employee group by post; # 连表 select * from employee inner join (select post,max(hire_date) from employee group by post ) as t on employee.post = t.post; # 连表并找出新入职的员工 select * from employee inner join (select post,max(hire_date) as m from employee group by post ) as t on employee.post = t.post where employee.hire_date = t.m ; # 连表并找出新入职的员工(过滤一下) select id,name,hire_date from employee inner join (select post,max(hire_date) as m from employee group by post ) as t on employee.post = t.post where employee.hire_date = t.m ;
![]()
75. not in 后面不能跟Null
- 对的
76.视图是什么?
- 视图是为了解决,某个查询结果,我们要经常使用,就把查询的结果作为结果报存下来。
- 举例:
- 两个表查询的结果,后续要经常使用,怎么报错下来?
- 示例:
-
select * from employee e inner join department d on e.dep_id = d.id; # 上面的这个连表查询结果,可能要执行多次, # 为了方便后续使用,我们可以把这个查询结果报存下来,这就叫视图 create view emp_dep as select e.* ,d.name as dep_name from employee e inner join department d on e.dep_id = d.id;
- 遇到[42S21][1060] Duplicate column name 'name' 怎么办?
- 这是,因name字段重复了,所以要改个名字,像我的,就把d.name改为dep_name
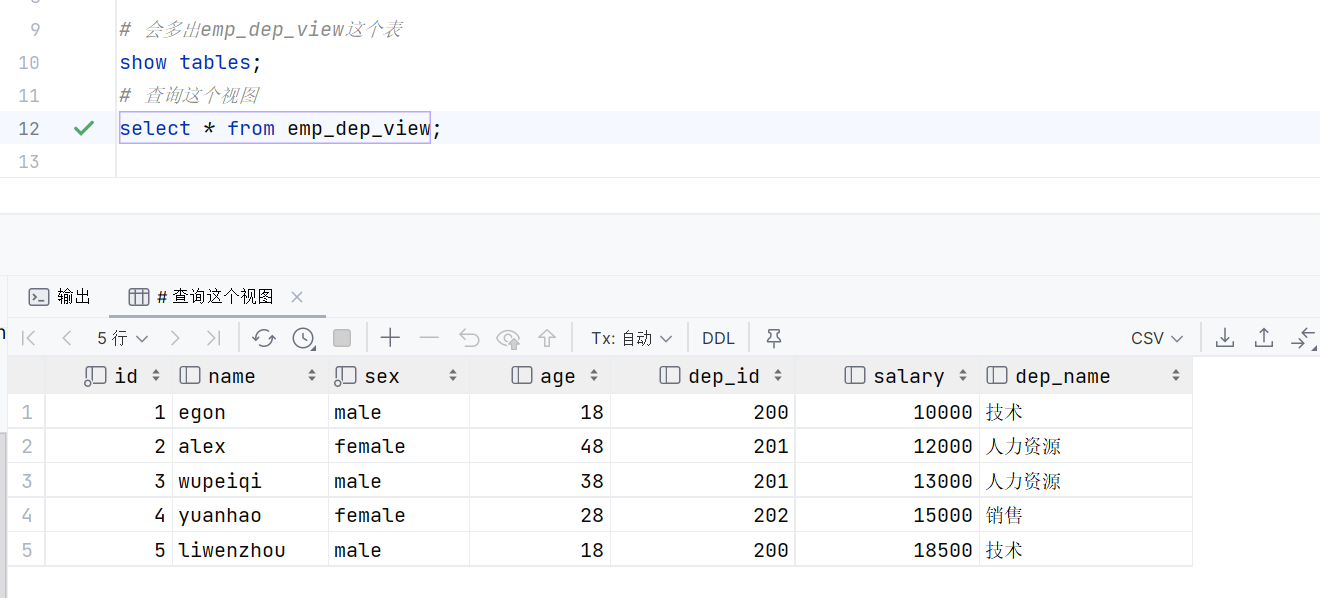
-
# 会多出emp_dep_view这个表 show tables; # 查询这个视图 select * from emp_dep_view;
![]()
77.视图实际上只存了表的结构,没有存数据?
- 是的
- 在mysql 5.6中
![]()
-
我的是mysql8.0
-
查看是:
-
![]()
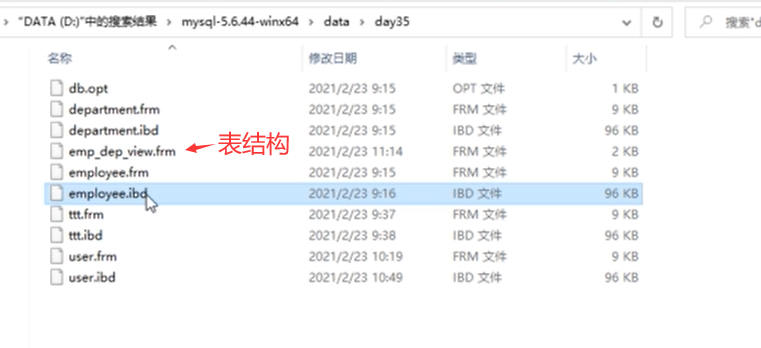
-
没有 emp_dep_view这个文件

78.视图的弊端是?
- 是个虚拟表,依赖性强,但安全性高。
- 遇到跨部门合作,比如让DBA去修改这个视图,可能有沟通流程上的问题。
- 更多资料:http://c.biancheng.net/view/7232.html
79.如何修改视图?
- SQL
-
alter view emp_dep_view as select e.* ,d.name as dep_name from employee e inner join department d on e.dep_id = d.id;
80.如何删除视图?
- SQL
-
drop view emp_dep_view;
81.触发器是什么?
- 当执行SQL的增删改的,(没有查),自动触发的一种机制。
- 跟python中的if判断一样,。
- 可以用python在应用层面实现。
- 企业中,更多的可能是在应用层去实现。
- 也有在日志记录,审计数据等方面会用到。
- 示例:
-
#准备表 CREATE TABLE cmd ( id INT PRIMARY KEY auto_increment, USER CHAR (32), priv CHAR (10), cmd CHAR (64), sub_time datetime, #提交时间 success enum ('yes', 'no') #0代表执行失败 ); CREATE TABLE errlog ( id INT PRIMARY KEY auto_increment, err_cmd CHAR (64), err_time datetime ); #创建触发器
#先改变分割符为//,这里的NEW是对象,刚刚插入数据的那个对象delimiter // CREATE TRIGGER tri_after_insert_cmd AFTER INSERT ON cmd FOR EACH ROW BEGIN IF NEW.success = 'no' THEN #等值判断只有一个等号 INSERT INTO errlog(err_cmd, err_time) VALUES(NEW.cmd, NEW.sub_time) ; #必须加分号 END IF ; #必须加分号 END// delimiter ; #往表cmd中插入记录,触发触发器,根据IF的条件决定是否插入错误日志 INSERT INTO cmd ( USER, priv, cmd, sub_time, success ) VALUES ('egon','0755','ls -l /etc',NOW(),'yes'), ('egon','0755','cat /etc/passwd',NOW(),'no'), ('egon','0755','useradd xxx',NOW(),'no'), ('egon','0755','ps aux',NOW(),'yes');
- 说明:
-
delimiter 为设置分割符为//,
- 这里的NEW是对象,刚刚插入数据的那个对象
-
82.存储过程?
- 可以类比为python中的函数。
- 可以反复调用。
- 一般是大型公司,分工很细的时候,开发型DBA把相关的数据,写成一个存储过程,类似一个API
- 我们应用程序员直接去调用这个API,不用自己写原生的SQL语句。
- 应用程序员,更专注于业务。
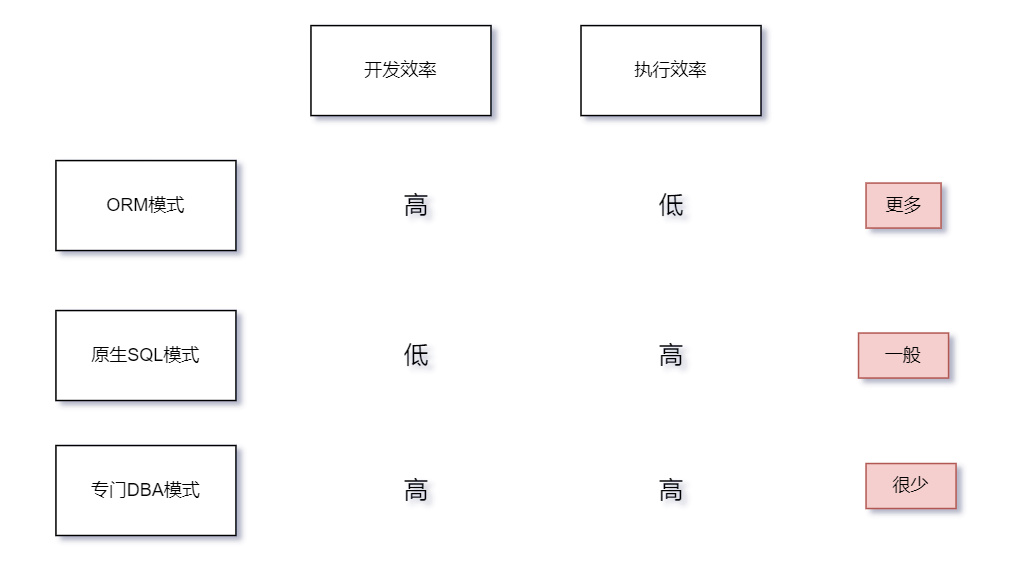
83.开发有三种模式?
84.如何按照年月分类来查询?
-
#1 准备表和记录 CREATE TABLE blog ( id INT PRIMARY KEY auto_increment, NAME CHAR (32), sub_time datetime ); INSERT INTO blog (NAME, sub_time) VALUES ('第1篇','2015-03-01 11:31:21'), ('第2篇','2015-03-11 16:31:21'), ('第3篇','2016-07-01 10:21:31'), ('第4篇','2016-07-22 09:23:21'), ('第5篇','2016-07-23 10:11:11'), ('第6篇','2016-07-25 11:21:31'), ('第7篇','2017-03-01 15:33:21'), ('第8篇','2017-03-01 17:32:21'), ('第9篇','2017-03-01 18:31:21'); #2. 提取sub_time字段的值,按照格式后的结果即"年月"来分组 SELECT DATE_FORMAT(sub_time,'%Y-%m'),COUNT(1) FROM blog GROUP BY DATE_FORMAT(sub_time,'%Y-%m'); #结果 +-------------------------------+----------+ | DATE_FORMAT(sub_time,'%Y-%m') | COUNT(1) | +-------------------------------+----------+ | 2015-03 | 2 | | 2016-07 | 4 | | 2017-03 | 3 | +-------------------------------+----------+ 3 rows in set (0.00 sec)
85.什么是索引?
- 是数据的一种组织方式。
- 建立索引,相当于书建立目录页。会占用一些硬盘空间。
- 又称之为Key
86.为何要用索引?
- 为了优化查询效率
- 注意的是:
- 建立索引后,会降低增,改,删的效率
- 好在,一般来说,读写比例为10:1
87.索引到底是什么数据结构?
- 是B+树
88.B+树是由什么发展而来?
- 由二叉树-->平衡二叉树-->B树-->B+树
89.MySQL的读取单位是页?什么是页?
- 是的,是页。
- 一页大约16KB,
- 一页等于操作系统的一块磁盘空间
90.为什么要用B+树,B+树是为了解决什么问题?
- B+树,是为了解决查询效率的问题。
- B+树是由二叉树一步一步演变的。
- 二叉树:
- 是为了解决查询效率
- 降低树的高度。(高度等于查询次数)
- 平衡二叉树:
- 是为了解决,二叉树有时候不平衡,
- 限制左右两边的高度差小于一(保证进一步降低高度)
- B树:
- 根据操作系统,每次是按照一块一块磁盘空间读取的。
- 在MySQL中innodb引擎下,一块一块对应的就是一页一页的,一页的数据量是16kb
- 如果16KB只用来读取1个根节点的数据,有点浪费。
- 所以,一次读取1页。1页包含多个节点。就比较省空间了,效率也高了。
- B+树:
-
- 在B树的基础上,1个节点包含指针和内容,有时候内容很大,一页也包含不了几个节点。
- 为了尽可能的在1次读取,多读几个节点,就把统一内容放到叶子节点。
- 所有的非叶子节点只存指针,并在叶子节点之间用链表连接起来,这样遍历一遍就可以找到数据。
- 这样效率更高。
91.平衡二叉树,是怎么保证平衡的?
- 根据算法。
- 常见的算法包括AVL树、红黑树等。
92.(扩展)什么是跳表?跟B+树一样吗?
- chatGPT
-
跳表(Skip List)是一种基于链表的数据结构,用于高效地支持快速查找、插入和删除操作。跳表通过在链表上增加多级索引,使得元素查找的时间复杂度保持在O(log n)的级别,从而实现了高效的操作。
跳表和B+树类似,都是一种支持快速查找的数据结构。但是它们的实现原理和数据结构不同。
B+树是一种基于树结构的数据结构,用于存储有序的键值对。B+树通过在节点中维护多个关键字,使得节点的容量比传统的二叉搜索树更大,从而减少树的高度,提高了查询效率。B+树的查询复杂度为O(log n)。
而跳表是一种基于链表的数据结构,它的节点包含了一个或多个指向其他节点的指针。每个节点的指针都以一定的概率随机指向后面的节点,形成了多级索引。这些索引提供了跳表的高效查找功能,使得跳表的查询复杂度为O(log n)。
跳表的优点在于它比B+树更简单,实现起来也更容易。同时,它也可以支持类似于删除操作等动态操作。在某些场景下,跳表比B+树更适合用于实现高效的查找操作。
93.B+树和B树的一个例子。
- 执行select * from id >12 and id <15时。
- 对于计算机来讲要查找的就是id=13 ,id = 14
- 对于高度为3的B树(其中根节点是常驻内存,不吃资源)
- 最大要找2+2 = 4次
- 对于B+树而言,
- 最大要找2+1 = 3次
- 为什么B+树查找14的时候,只用1次,因B+树内部使用链表进行连接。
- 相当于B+数,都是用链表连接。所有范围查询快。
- B+树遍历整棵树只需要遍历所有的叶子节点即可,而不需要像B树一样需要对每一层进行遍历,这有利于数据库做全表扫描。
- 参考资料https://www.cnblogs.com/sunlong88/p/15002056.html
94.B+树的优点?
- 是在二叉树,平衡二叉树,B树的基础上进一步发展而来。
- ①最主要的特点是,只在叶子节点存放真正的数据。意味着在等量数据下,B+树的高度是最低的
- 并且叶子节点都是排好序的,在范围查询上,比B树更快。一旦找到一个树叶节点,不用在从树根查起。
- ②在范围查询上,B+树是最快的。因为叶子节点都是排好序的。
94.5 补充 B树和B+树的图片
- B树
![]()
- B+树
![]()
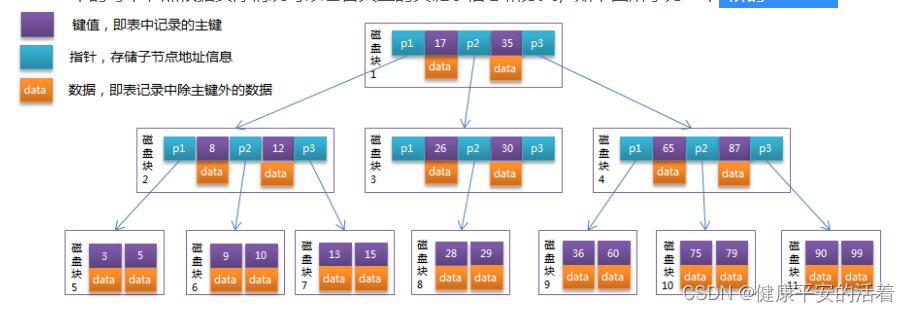
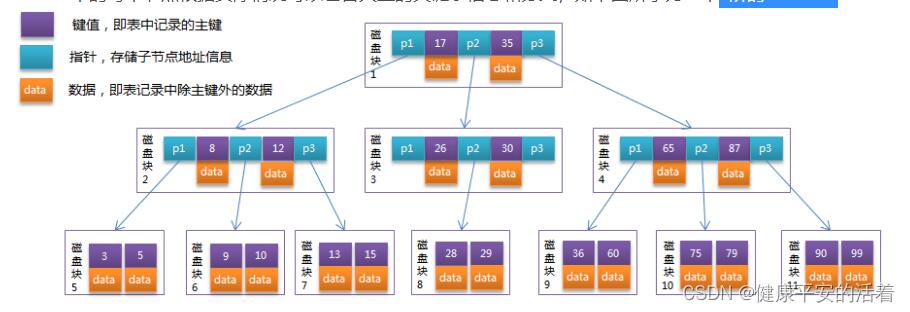
95.innodb引擎的分类?
- hash索引:更适合等值查询,不适合范围查询。
- B+树索引:
- 聚集索引/聚簇索引 -->以主键id的值作为key,一张表只有1个。
- 辅助索引--> 可以有多个,自己建立的索引。
96.辅助索引会不会放完整的数据?
- 不会。
- 辅助索引的叶子节点,放指向真实数据的id(key)
97.innodb是索引组织表?
- 是的。
- 索引组织表,是以索引为基础排好序的表。
98.什么是回表查询?
- 假设有个user表,id为主键,name为辅助索引。
- select name,age,gender from user where id =3;
- 这会直接通过主键的索引,也就是聚集索引就能查到。
- select name,age,gender from user where name='liqi';
- 这会第一步,通过辅助索引查询,拿到id,再去聚集索引,去查询。这个过程叫回表查询。
- 所以,
- 回表查询,是通过辅助索引拿到主键值,然后再回答聚集索引从根再查一下。
99.什么是覆盖索引?
- 不需要回表,就能拿到你要的全部数据。
- 比如98中的例子中,
- select name,id from user where name='liqi';
- 这个就是覆盖索引了。因为辅助索引,里面存的部分数据就包含name和id(主键)
100.上百万的数据占多大?
- 老师上课演示,250万条数据占164MB
- 换算是500万的数据,300MB
- 上百万的数据,占几百MB。
- ============
- 我的数据库有3400条数据,占9MB。
- 换算是1万是数据30MB,
- 1百万数据是3GB(3000MB)
101.mysql的常用索引?
- 普通索引:
- index:加速查找
- 唯一索引:
- 主键索引:primary key : 加速查找+约束(不为空,不能重复)
- 唯一索引:unique :加速查找+约束(不能重复)
- 联合索引:
- primary key(id,name) : 联合主键索引
- unique(id,name) : 联合唯一索引
- index(id,name):联合普通索引
102.explain是什么意思?
- 显示后面的SQL语句的查询计划。
- (更多自己查资料)
103.命中索引后,一定走索引吗?
- 不一定。mysql查询的时候,会有N个方案去查询。
- 假设命中索引是方案A,但还是内部方案B,方案C。
- mysql不见得走方案A。
104.什么是索引下推?
- 示例:
- 比如查询a =1 and b = 2 and c =3;
- 假设a没有索引,b有索引,那么mysql会优先根据b来进行查询。
- 是mysql 5.6版本上进行推出的。
105.命中索引后依旧没有很好的查询提速效果,怎么回事?
- 1.对区分度高度并且占用空间小的字段建立索引。
- 区分度不高,就会建立一个直线型的树,高度很好,效果就不好。
- 空间小,意味着每块空间能容纳的索引就多。
- 2.针对范围查询命中了索引,如果范围大,查询效率已经很低。如何解决?
- 把范围缩小。
- 要么分段取值,一段一段取。(比如,某宝搜索商品,一次显示一部分)
- 3.索引下推技术(默认开启)
- 4.不要把查询字段放到函数或者参与运算。
- select count(*) from where id*12 = 3;(×)
- select count(*) from where id = 3/12;(√)
- 5.索引覆盖
- 6.最左前缀匹配原则。
- 联合索引的时候。
- id
- id name
- id gender
- id name gender
- 这里要是id已经有了主键,就不要建立在联合索引了。
- 建立索引,带id也没关系,mysql会自动识别,选择最优方案。
106.查询慢怎么回事?
107.什么是事务?
- mysql的一种机制。
108.事务有四大特性?
- 原子性
- 一致性
- 隔离性
- 持久性
109.四大特性具体讲解?
- 原子性:
- 不可分割。
- 比如银行转账,A账户-100元,B账户+100元。这两个SQL语句构成了一个事务。是不可分割的。
- 不可分割。
- 一致性:
- 状态一致。
- A账户转账前是正整数,转账后变为负数了,这就不行。
- 总和一致。
- A账户原来有500元,B账户原来有500元,总和是1000元。
- A转给B200元,A变为300元,B变为700元,保证总和是还是1000元。
- 状态一致。
- 隔离性。
- 事务之间互相不影响
- 比如,A想要往B账户赚钱,C也要往B账户转钱。
- 这会开启2个事务。这两个事务,应该互相不影响。
- 事务之间互相不影响
- 持久性。
- 事务提交后,数据库实实在在的有数据。
- 我提交后,数据库里真的有数据,持久化写入了硬盘里。不能出现数据没了。
- 事务提交后,数据库实实在在的有数据。
110.如何开启事务?
- 事务,有隐式开启,显示开启。
- 事务,有隐式提交,显示提交。
- 默认,都是隐式提交,隐式开启。
- 原来MySQL背后帮我们默默做了这么多贡献,
- 哪有什么岁月静好,总有人替我们负重前行。感动了感动了 T_T
111.默认开启事务?
-
start transaction; update user set name='LIQI' where id =1; commit;
112.如何开启事务?
- start transaction;或者begin; commit;提交事务 rollback; 回滚事务 注意:commit或者rollback后事务都结束。
113.并发会引发的问题是?
- 脏读
- 不可重复读
- 幻读
114.什么是脏读?不可重复读?幻读?
- 脏读
- 读到一个无效的数据。另外一个事务,更新后且回滚了。
- 不可重复读
- 读的数据不准确。另外一个事务,把我要的数据改掉了。
- 幻读
- 不可能重复读,一种特殊现象。
- 查询id>3的改为xxx,但id=11的数据没改。(id=11是别人提交的)
115.我们需要考虑脏读,不可重复读,幻读吗?
- 不需要。
- MySQL内部已经帮我处理好了。内部有处理机制。
- (它真的,我哭死)
116.数据库锁的机制,跟python的锁有什么区别?
- Python----MySQL
- 互斥锁----排他锁----------单把锁
- 信号量----共享锁----------多把锁
117.锁的分类?
- 按照锁的粒度,可分为
- 行级锁,表级锁,页级锁
- 按照锁级别划分,可分为
- 共享锁,排他锁
- 按照使用方式划分,可分为
- 乐观锁,悲观锁
- 按照加锁方式,可分为
- 自动锁,显示锁
- 按照操作划分,可分为
- DML锁,DDL锁
118.insert ,update,delete都是默认加排他锁的?
- 是的。
119.select 不受锁影响?
- 对的
120.innodb行级锁,锁的是索引?
- 是的。
- 锁的是索引,如果没有命中索引,就会锁所有行相当于锁了表。
121.如果只是对某几行加锁,怎么加?
- 用select
- select ... from 表 ... for update;排他锁
- select ... from 表 ... lock in share mode ; 共享锁
122.排他锁缩写为(X锁),共享锁缩写为(S锁)?
- 对的。
123.互斥锁和共享锁有什么区别?
- 互斥锁,也叫独占锁,写锁。
- 一旦有个事务对某一行加了互斥锁,就可以可读可写。
- 对应上厕所的拉粑粑。其他人进不来。进去的人,可以拉粑粑(写),也可以洗手(读)。
- 共享锁,也叫读锁。
- 一旦有个事务对某一行,开启了共享锁。该行只能读,不能写。后来的人,也就只能读。
- 对应上厕所的洗手。其他人也可以进来上厕所。但不能拉粑粑。
- 参考资料:https://www.cnblogs.com/kyoner/p/11314624.html
124.什么是死锁?
- 有两个事务A和B,
- 都对字段id =1 的加了共享锁。
- 这时候,事务A,打算更新id =1的这条记录。(排他锁)
- 这时候,事务B,后打算更新id = 1的这条记录。
- 他们都等待对方释放掉(排他锁)。
- 这就是死锁。
- MySQL为了解决这个问题,当发现死锁问题是,会立马停掉第二个加排他锁的那个事务。所以,上面这个例子中。事务B执行排他锁的时候,会立马遇到ERROR,终止掉。
125.innodb锁的机制?
- 如果一条SQL语句操作,命中了主键索引,MySQL就会锁定这条命中的主键索引的行。
- 如果一条SQL语句操作,命中了辅助索引,MySQL就会锁定,辅助索引和对应的主键索引的行。
- 如果一条SQL语句操作,没有命中索引,MySQL就会锁定所有行,等同于锁定整个表。
![]()
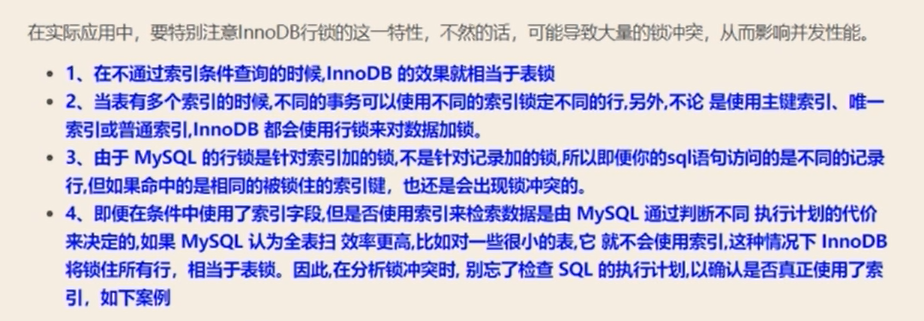
126.还有哪些情况会导致死锁?
- 并发情况,都是1条sql语句。
- 事务1: 命中的是辅助索引的neme
- 事务2:命中的是辅助索引的age。
- 有交叉,所以互相锁住了。
- 举例:
![]()
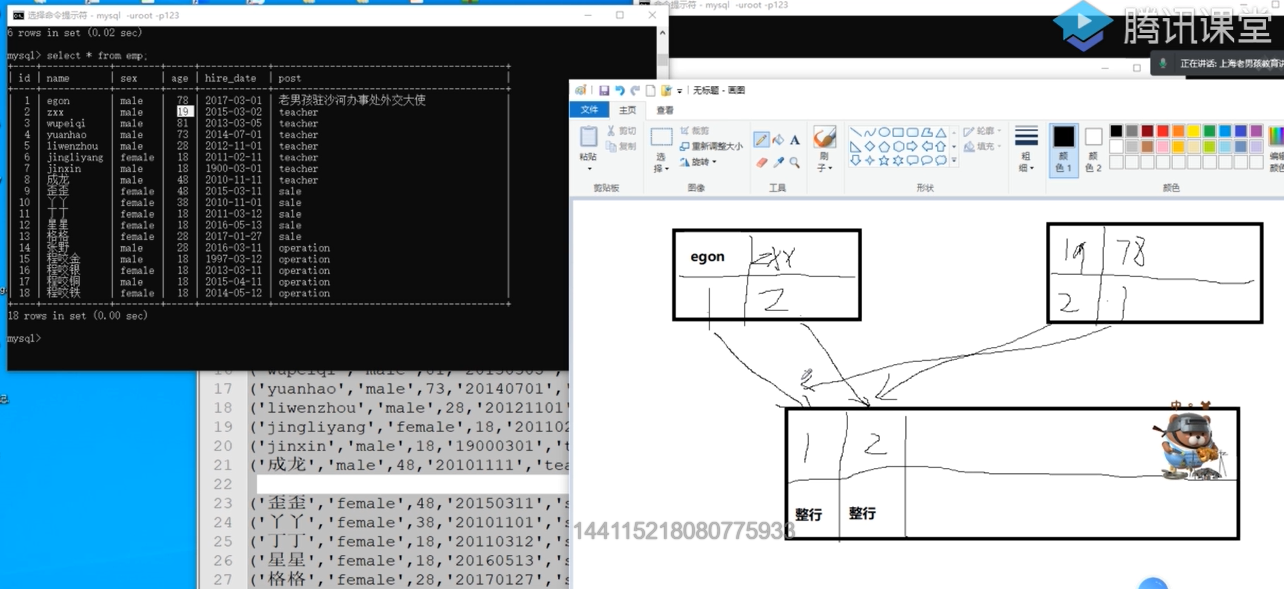
127.innodb有三种锁的算法?
- Record Lock 行级锁
- Gap Lock 间隙锁
- Next-Key Lock 等于行级锁+间隙锁。为了解决幻读问题。
128.数据库的隔离机制有哪四种?
- 数据库事务的隔离级别有4个,由低到高依次为Read uncommitted 、Read committed、Repeatable read 、Serializable ,这四个级别可以逐个解决脏读 、不可重复读 、幻读 这几类问题。
![]()
- 参考资料1:https://cloud.tencent.com/developer/article/1833688
- 参考资料2:https://learnku.com/articles/40258
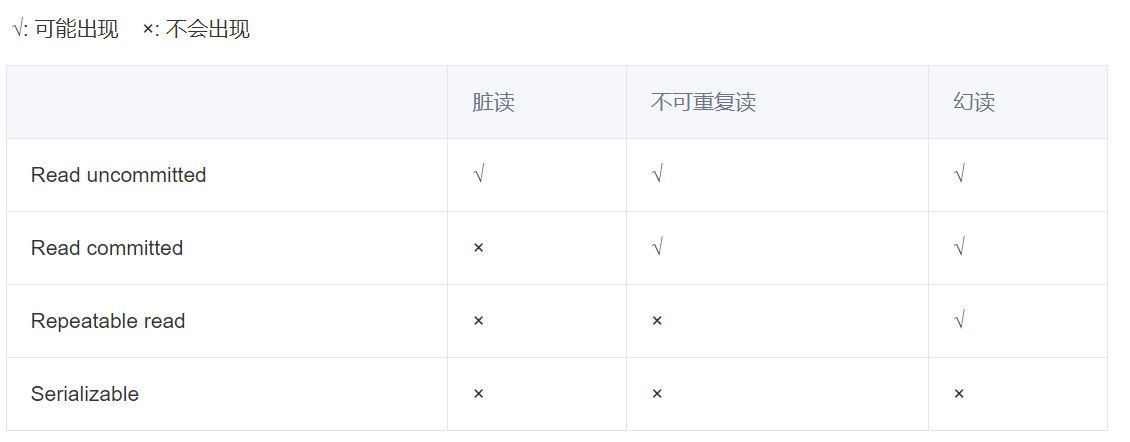
129.MySQL默认的隔离机制是?
- RR可重复读。
130.Django层面选择是的隔离机制是?
- RC,从业务层面解决不可重复读问题
131.乐观锁,悲观锁?
- 其实是一种编程思想。
- 悲观锁,每次读写数据都加一个排他锁。(很安全,并发量很低)
- 实现方式时数据库内部的排他锁
- 乐观锁,每次读写,认为没有更改。
- 业务层面实现。
- 实现方式1,增加一个字段任务ID
- 每次更新的时候,检测这个ID,有没有人动过。
- 发现有人更改的时候,再查询并执行。
- 实现方式2,增加一个时间戳字段。
- 每次更新的时候,检测一次更新时间。
- 发现有人更改账号金额是的时候,再查询并执行。
132.MVCC是什么?
- chatGPT
MVCC(多版本并发控制)是MySQL中用于控制并发访问的一种技术。在MVCC中,每个事务都能看到一个特定时间点的数据快照,这使得多个事务可以同时读取数据库中的数据而不会相互干扰。同时,MVCC也能够确保每个事务的修改都不会影响到其他正在执行的事务。
在MySQL中,MVCC的实现主要依靠以下两种机制:
事务版本号:每个事务都有一个唯一的版本号,用于标识该事务对数据库的修改。每个数据行也有一个版本号,用于标识该行最后一次被修改的版本号。
Undo日志:在执行一个事务修改操作时,MySQL会将原始数据保存到Undo日志中,以便在事务回滚时能够恢复原始数据。
通过这些机制,MySQL能够实现多版本并发控制,从而实现高并发访问数据库的需求。
- 默认读,都是快照读。
- 加锁读,是当前读。
最后:
从3月15日到4月9日,历时25天左右,我胡万三终于站起来了,我学完了数据库了!!!!!
参考资料:
https://www.cnblogs.com/linhaifeng/articles/7126847.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号