Python学习笔记-常用模块介绍--log和re
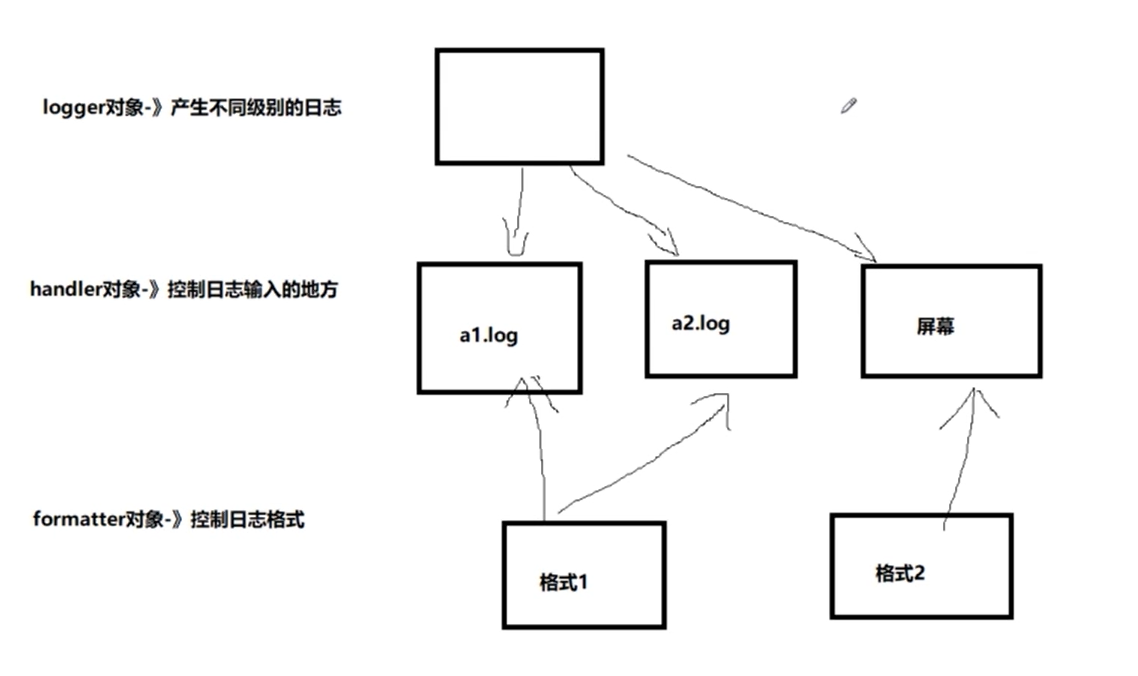
1.log日志-几个常用对象
- logger对象--》产生不同级别的对象
- handle对象--》控制日志输入的地方
- formatter对象--》控制日志格式
2.借用他人模块图个方便?
- 是的。
- 部分程序员容易陷入追求技术的极致,往往忽略能技术带来的价值。
- 公司有些代码,不开源的部分原因,是往往写的很简单,但是却带来的价值。
3.日志模块模板
# setting.py
""" logging配置 """ import os # 1、定义三种日志输出格式,日志中可能用到的格式化串如下 # %(name)s Logger的名字 # %(levelno)s 数字形式的日志级别 # %(levelname)s 文本形式的日志级别 # %(pathname)s 调用日志输出函数的模块的完整路径名,可能没有 # %(filename)s 调用日志输出函数的模块的文件名 # %(module)s 调用日志输出函数的模块名 # %(funcName)s 调用日志输出函数的函数名 # %(lineno)d 调用日志输出函数的语句所在的代码行 # %(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示 # %(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数 # %(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒 # %(thread)d 线程ID。可能没有 # %(threadName)s 线程名。可能没有 # %(process)d 进程ID。可能没有 # %(message)s用户输出的消息 # 2、强调:其中的%(name)s为getlogger时指定的名字 standard_format = '%(asctime)s %(filename)s: %(levelname)s %(name)s %(levelname)s %(message)s' simple_format = '%(asctime)s %(message)s' # 3、日志配置字典 LOGGING_DIC = { 'version': 1, 'disable_existing_loggers': False, 'formatters': { 'standard': { 'format': standard_format }, 'simple': { 'format': simple_format }, }, 'filters': {}, 'handlers': { # 打印到终端的日志 'console': { 'level': 'DEBUG', 'class': 'logging.StreamHandler', # 打印到屏幕 'formatter': 'standard', }, # 打印到文件的日志,收集info及以上的日志 'file1': { 'level': 'DEBUG', 'class': 'logging.FileHandler', # 保存到文件 'formatter': 'standard', 'filename': 'a1.log', 'encoding': 'utf-8', }, # 打印到文件的日志,收集info及以上的日志 'file2': { 'level': 'DEBUG', 'class': 'logging.FileHandler', # 保存到文件 'formatter': 'simple', 'filename': 'a2.log', 'encoding': 'utf-8', }, }, 'loggers': { # logging.getLogger(__name__)拿到的logger配置 '': { 'handlers': ['file1',"file2",'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕 'level': 'ERROR', # loggers(第一层日志级别关限制)--->handlers(第二层日志级别关卡限制) 'propagate': False, # 默认为True,向上(更高level的logger)传递,通常设置为False即可,否则会一份日志向上层层传递 # propagate 没啥用 }, }, }
# common.py import setting import logging.config logging.config.dictConfig(setting.LOGGING_DIC) logger1 = logging.getLogger('用户交易') logger1.debug("hhh") logger1.info("你好") logger1.error("错误日志") logger1.critical("危机")
4.re模块--基本
(黄色和绿色是要重点掌握)
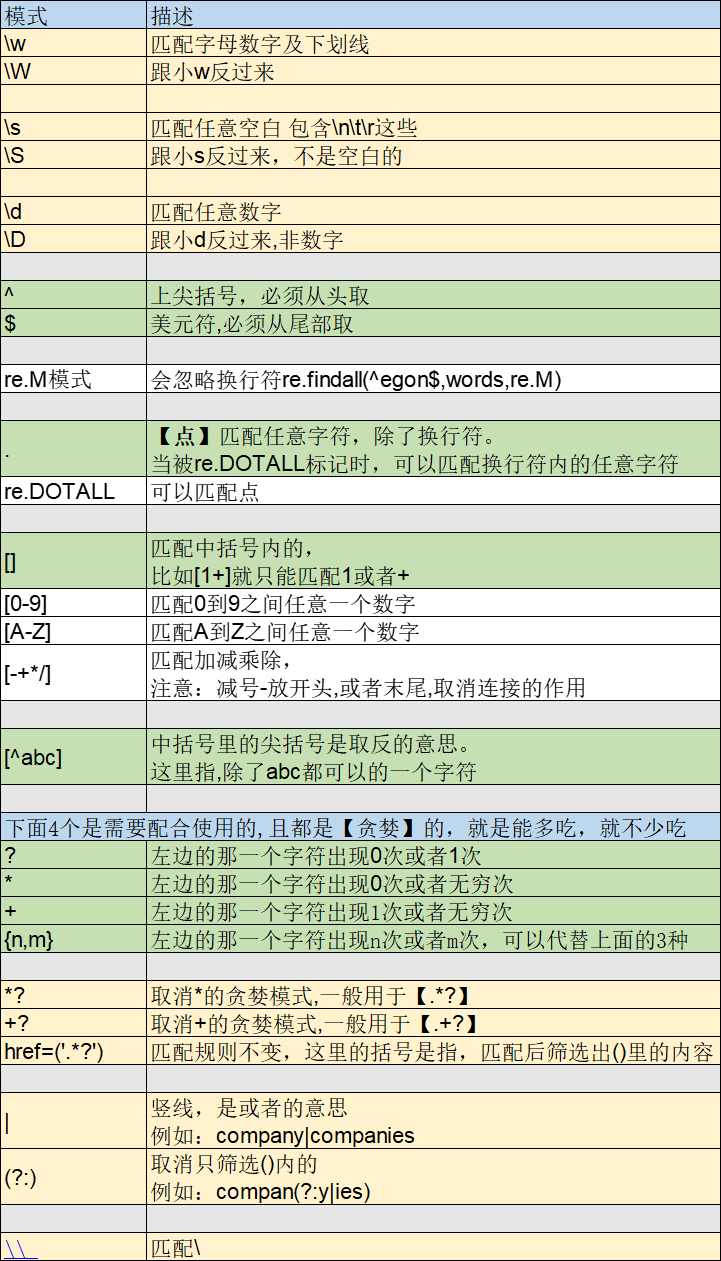
\{ 斜杠+大括号,取消大括号的特殊含义。匹配大括号
4.1 re模式 -- re.M
import re #re.M模式 string = """ egon 124egon egon123 egon """ res = re.findall("^egon$",string,re.M) print(res) # ['egon', 'egon']
4.2 re模式 -- ()的示例
import re string = "<a href='http://www.baidu.com'>'我是百度'</a> <a href='http://www.sina.com.cn'>'我是新浪'</a>" res = re.findall("href=('.*?')", string=string) print(res)
4.3 re模式 .*?和.+?区别
res = re.findall("a.*?b","as5b ab") print(res) #结果 ['as5b', 'ab'] res = re.findall("a.+?b","as5b ab") print(res) #结果 ['as5b']
4.4 re模式\处理
print(re.findall(r'a\\c','a\c')) #r代表告诉解释器使用rawstring,即原生字符串,把我们正则内的所有符号都当普通字符处理,不要转义 print(re.findall('a\\\\c','a\c')) #同上面的意思一样,和上面的结果一样都是['a\\c']
5.正则表达式练习1
-
匹配 'abc11dad33.4adasfd21111asd3.4' 把里面的数字匹配出来
-
# 匹配 'abc11dad33.4adasfd21111asd3.4' 把里面的数字匹配出来 words = 'abc11dad33.4adasfd21111asd3.4dfg99.00,dfgsd88.00' print(re.findall('\d+(?:\.\d+)?',words)) # ['11', '33.4', '21111', '3.4', '99.00', '88.00'] # \d+ 匹配数字 # \. 匹配点 # (?:) 取消只匹配括号里的 # ()? 括号里的匹配0次或者1次
6.re.search用法
res = re.search("egon","124 egon 325 egon egon") # 结果是一个对象 # <re.Match object; span=(4, 8), match='egon'> print(res) # 如果没有找到是 None print(res.group()) # egon
7.re.match用法
- 从头匹配。等同于re.search(^)
print(re.search("egon","124 egon 325 egon egon")) # <re.Match object; span=(4, 8), match='egon'> print(re.match("egon","124 egon 325 egon egon")) # None print(re.match("egon","egon 325 egon egon")) # <re.Match object; span=(0, 4), match='egon'> print(re.search("^egon","egon 325 egon egon")) # <re.Match object; span=(0, 4), match='egon'>
8.re.sub用法
- 替换字符串
print(re.sub('^(\w+)(.*?\s)(\w+)(.*?\s)(\w+)$',r'\5\2\3\4\1','lxx is sb')) # 结果 ==> sb is lxx # lxx 空格 is 空格 sb print(re.sub('^\w+','LXXXXXXX','lxx is sb')) # 结果 ==> LXXXXXXX is sb # 替换
9.re.compile用法
- 想要复用写好的正则表达式,把它变为正则对象。
- 例如:下面就是把字符串"egon"转换为正则对象pattern,来使用。
pattern = re.compile("egon",re.M) # 把这个"egon"字符串转换为一个正则对象pattern,每次使用就可以使用正则对象pattern 去调用 print(pattern.findall("egon xxx egon")) # 结果 ['egon', 'egon'] print(pattern.search("asdfegoneer")) # 结果 <re.Match object; span=(4, 8), match='egon'>
10.re.VERBOSE用法
re模块的re.VERBOSE可以把正则表达式写成多行,并且自动忽略空格。
11.处理字符编码的代码样式
import re # 7-bit C1 ANSI sequences ansi_escape = re.compile(r''' \x1B # ESC (?: # 7-bit C1 Fe (except CSI) [@-Z\\-_] | # or [ for CSI, followed by a control sequence \[ [0-?]* # Parameter bytes [ -/]* # Intermediate bytes [@-~] # Final byte ) ''', re.VERBOSE) result = ansi_escape.sub('', sometext)
12.有时候,re.match匹配不到,就用re.findall吧
- 可以无脑入re.findall,不会让你失望的。TvT
13.正则表达式,在线测试器:
- 巨推荐!!
https://c.runoob.com/front-end/854/
参考资料:
正则表达式工具: https://c.runoob.com/front-end/854/
林海峰博客 https://www.cnblogs.com/linhaifeng/articles/6384466.html
处理ssh字符链接:https://stackoverflow.com/questions/14693701/how-can-i-remove-the-ansi-escape-sequences-from-a-string-in-python

 浙公网安备 33010602011771号
浙公网安备 33010602011771号