
Python学习笔记--基本类型的高级用法
1.可变类型与不可变类型的区别是什么?
- 看id是否变化。内存地址是否变化。
- 一般短的,像整型,字符串,是不可变类型。长的像列表,字典,是可变类型。
- (我认为)这个变与不变,看你数据的用途。没有一成不变的数据
2.x=18背后的机制是什么?
-
x=18 # 等同于x = int(18)
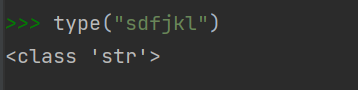
3.工厂函数是什么?如何查看呢?
- 工厂函数是 int str 等等
- 用type() 查看
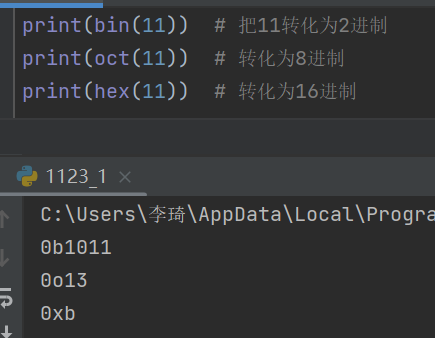
4.转化进制怎么转化?
- 常用的转化操作,python已经帮我们集成了。
-
print(bin(11)) # 把11转化为2进制 print(oct(11)) # 转化为8进制 print(hex(11)) # 转化为16进制
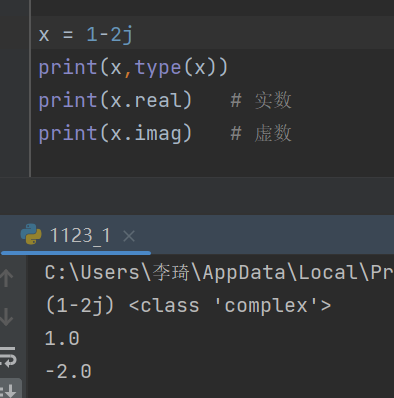
5.python如何表示复数?
6.字符串如何取消转义?
- 字符串前面加个r
- //
7.什么叫函数?什么叫方法?
- len()# 叫函数
- "".strip() # 叫方法
- 用.调出来的的叫方法。
- 直接使用的叫函数。
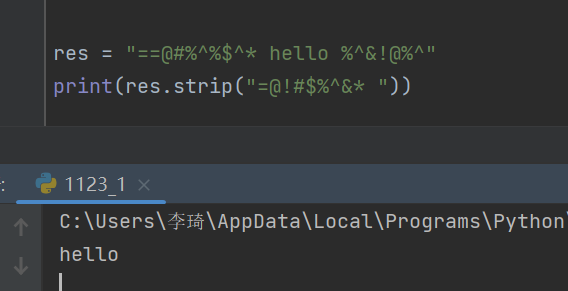
8.如何去掉字符串两边不要的字符?
- 用strip(要去掉字符集合),会帮我们去掉两边的字符
res = "==@#%^%$^* hello %^&!@%^" print(res.strip("=@!#$%^&* "))
9.字符串切分,可以指定次数吗?
- 可以的。指定步长。
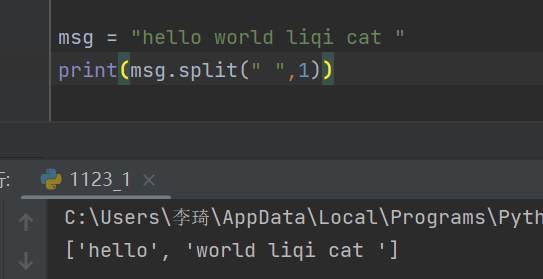
10.字符串的join怎么使用?
- join是把列表里的东西,用指定的字符连接起来。
- 优点:比+效率高点。
- 缺点:不能把数字类型同字符串连接起来。
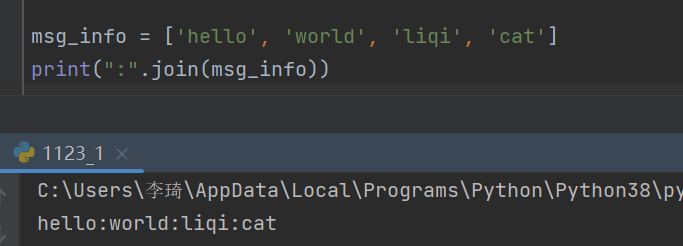
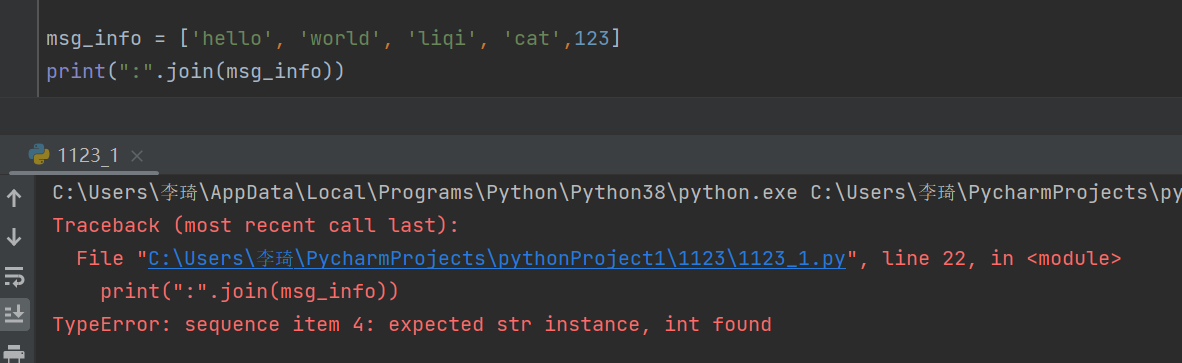
11.如何判断字符串是不是数字?
-
用isdigit这个方法
-
 是否是数字
是否是数字1 number = "18" 2 print(number.isdigit())

12.如何判断字符串里面是否有某个值?
- 用"".find() 返回找到索引,找不到返回-1
- 好处:是不会报错。
- 坏处:不能直接用不了if 判断
-
View Code
1 msg = "hello world liqi cat " 2 if msg.find("liqi"): 3 print("找到啦liqi") 4 if msg.find("asdf")>0: 5 print("又找到了asdf") 6 if msg.find("asdf")<0: 7 print("没找到了asdf")
13.列表list函数可以把哪些类型转化为列表?
- 可迭代类型
- (粗略)如何判断可迭代类型呢?可以被for循环遍历的。
14.列表的删除元素的操作有哪些?
- del # 万能删除
- l.remove() # 指定元素删除
- l.pop() # 按照索引删除 这个有返回值
15.列表的复制的原理是什么?
- 例如用[:]复制
- 代码
-
View Code
1 l = [11, 22, ["xx", "yy"]] 2 new_l = l[:] 3 4 new_l[1] = 99 # 改变了新的列表 5 new_l[-1][0] = "====" 6 # l[0] = 999 7 # l[-1][-1] = "000" 8 print("原来的列表:", l) 9 print("新的列表:", new_l)
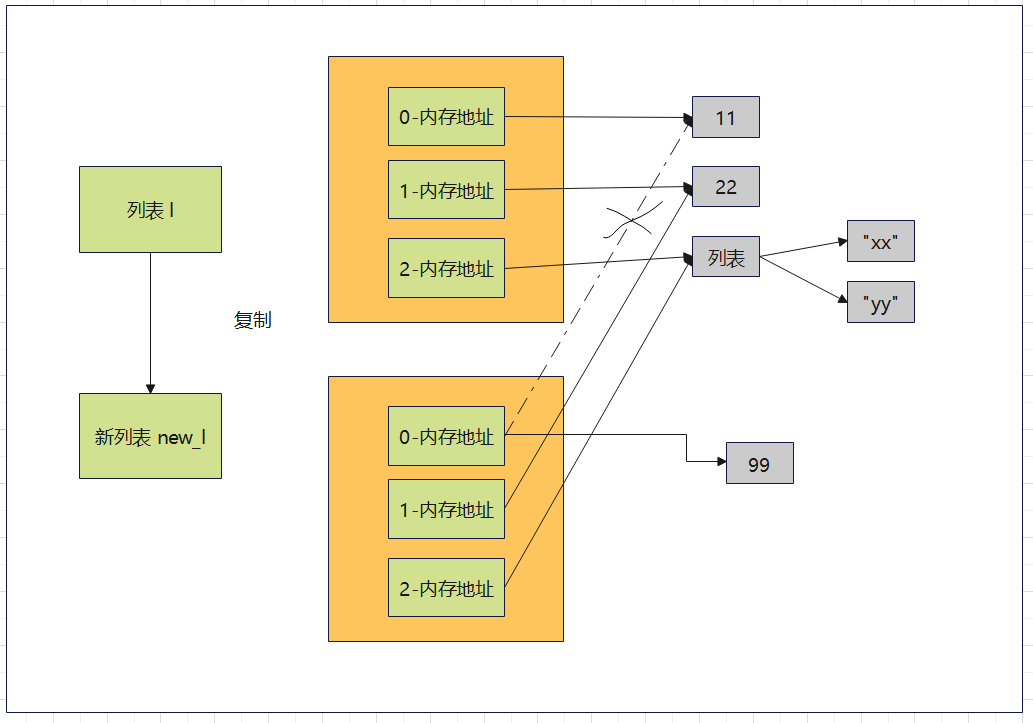
16.浅拷贝和深拷贝的区别是什么?
-
15的这种[:]拷贝方式就是浅拷贝。
- 浅拷贝只拷贝了一层。(手伸的比较浅)
- 深拷贝多层都拷贝。(手伸的比较深)
- (扩展)深拷贝是对可变类型进行特殊处理。
- 应用场景:
- 面试的时候
- 了解底层原理的时候
17.列表的append和extend有什么区别?
- append只添加一个
- extend 遍历可迭代元素添加
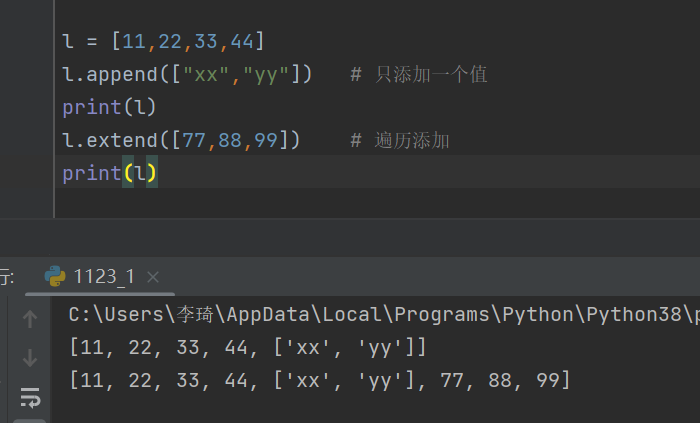
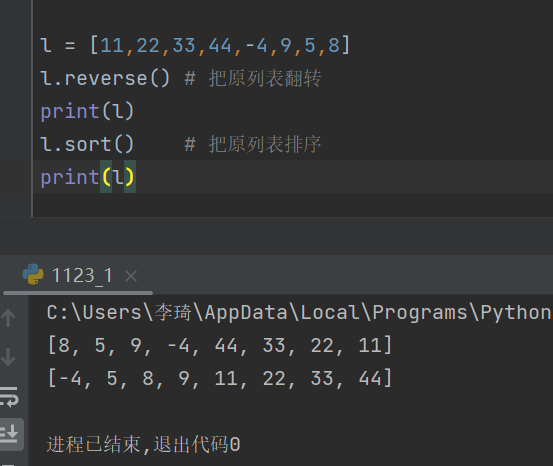
18.列表什么操作?
-
l.reverse() # 把原列表翻转
-
l.sort() # 把原列表排序
19. 什么时候用元组,列表,字典?
- 需要存放不同类型的值的时候,用字典比较合适。
- 需要存放同种类型,且有改的需求,用列表比较合适。
- 需要存放同种类型,且只有读的需求,用元组比较合适。
- (注意,这里只是建议。不是绝对的,要根据实际情况来决定。)
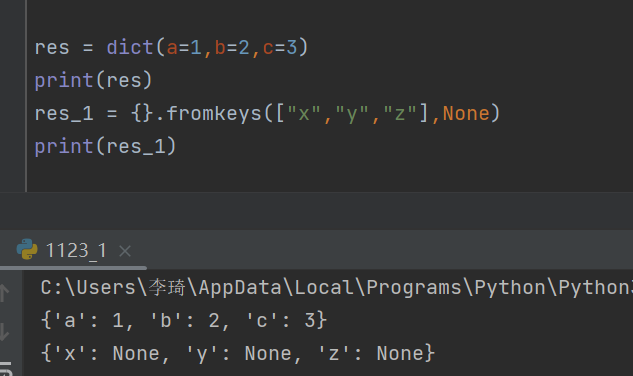
20.如何快速造字典类型的数据?
-
res = dict(a=1,b=2,c=3)
-
res_1 = {}.fromkeys(["x","y","z"],None)
21.什么文件容易出现编码问题?
- 文本文件
- 像其他文件,视频,音频文件,都是以二进制来存储了。所以,不会出现这类问题。
- 只有输入输出字符这类文本文件会出现。
- 出现的原因,也很简单。就是读取和写入的不是同一张参照表。
22.如何用列表实现一个简单的队列和堆栈的概念?
- 队列
-
l = [] l.append(11) #[11] l.append(22) #[11,22] l.append(33) #[11,22,33] l.pop(0) # 11 l.pop(0) # 22 l.pop(0) # 33
-
- 堆栈
-
l = [] l.append(11) #[11] l.append(22) #[11,22] l.append(33) #[11,22,33] l.pop(-1) # 33 l.pop(-1) # 22 l.pop(-1) # 11
-
23.如果把一个字典更新到另一个字典里?
- 代码
-
d = {"name": "liqi", "age": "18"} d.update({"gender": "male"}) # 把字典加进去 如果有这个,就变更。 print(d)
24.字典里update和setdefault区别是什么?
-
update没有返回值,传入的是字典
-
setdefault有返回值,传入的是要设置的key和value
-
d = {"name": "liqi", "age": "18"} res = d.update({"gender": "male"}) # 把字典加进去 # 没有返回值 print(d) print(res) res1 = d.setdefault("gender", "xxx") # 有返回值 返回值找到的那个值 print(d) print(res1)
25.为什么要操作文件?
- 数据产生是在内存中,而内存一旦断电,数据就没了。故需要文件。一种操作硬盘的机制,把文件永久保存。
- 操作文件分为哪几步?
- 打开文件
- 读/写文件
- 关闭文件
26.打开文件open本质上在干啥?
- open本质上在于操作系统交互。
- python是一种建立在操作系统的语言。
- open本质上是用python语言告诉操作系统帮我打开一个文件。
- 所以,此时就需要把文件在操作系统的路径 告诉open。
- open 才能打开文件。
27.什么是句柄?
- (我的理解)像一个门把手,可以控制门的。
- 像电视遥控器,可以控制电视。
- 为什么要有句柄?
- 我猜测)是因为,句柄是操作文件的,文件有可能数据很大。
- 为了方便使用,操作系统建立了一个“数据表”,给我们一个数据表的id,也就是句柄。
- 帮助我们操作。
28.文件的一些操作解释?
-
f = open("bb/a.txt", mode="rt", encoding="utf-8") # 这句是获得句柄
- f.read() # 按下了读的按钮,拿到了读取的数据
- f.close() # 按下了关闭的按钮,关闭文件。
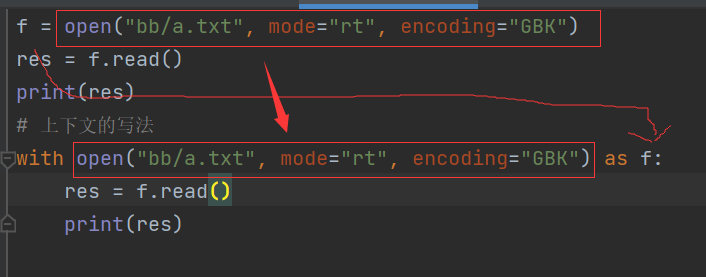
29.为什么要有with 上下文管理机制?
- 每次打开文件都要关闭,(操作系统一段时间内打开的文件有上限),最好每次都要关闭。
- 但每次都要写f.close()比较麻烦,python人性化的给我们提供了一个上下文管理器。
- 就是每次帮我们自动关闭。
- 用法是:
-
f = open("bb/a.txt", mode="rt", encoding="GBK") res = f.read() print(res) # 上下文的写法 with open("bb/a.txt", mode="rt", encoding="GBK") as f: res = f.read() print(res)
-
30.从文件中读取账号密码判断用户输入的正确与否?
- 代码
-
View Code
1 name = input("请输入用户名") 2 password = input("请输入密码") 3 with open("bb/a.txt", mode="rt", encoding="utf-8") as f: 4 for line in f: 5 param = line.strip().split(":") 6 if param[0] == name and param[1] == password: 7 print("登录成功!") 8 break 9 else: 10 print("登录失败")
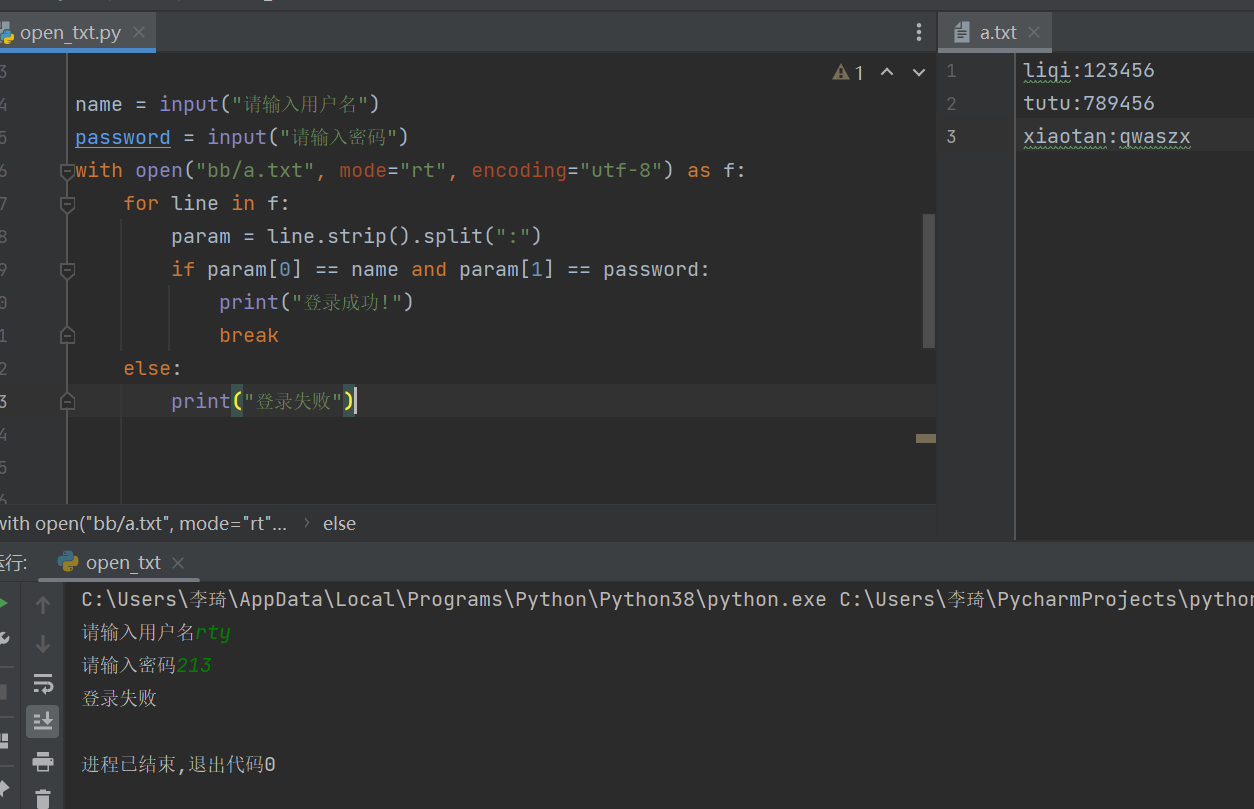
31.文件读写中b模式和t模式区别?
- b模式是原生模式,bit模式,以2进制读写。(针对视频,音频,适用范围更广)
- t模式是文本模式,类似txt模式,以文本文件打开。(专门针对文本文件)
32.改变编码是指什么?
- 内存的编码都是默认UTF-8
- 我们能改变的是硬盘读/写的编码。
33. 文件乱码怎么办?
- 90%以上的乱码是存硬盘的时候,没有用uft-8。而打开用utf-8导致的。
- 解决这个问题,需要用当初存的时候的编码来读取。
- 比如,存的时候用的是GBK,读的时候,就要用GBK。
- 存的时候用的是shift-jis格式,读的时候,就要用shift-jis
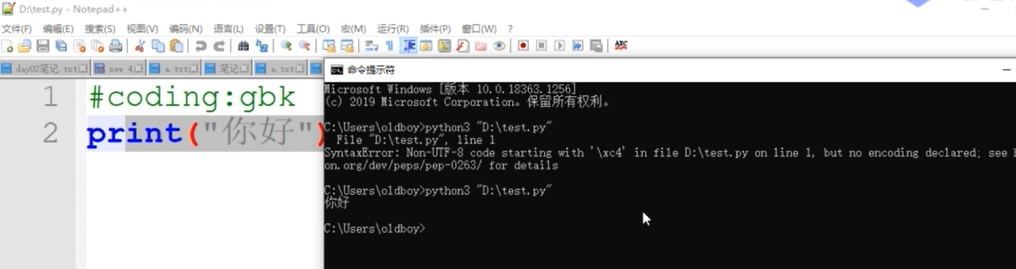
34.遇到python执行test.py报错SyntaxError:Non-UTF-8 code starting with '\xc4' ....如何解决?
- 这是读取test.py文件时,遇到的编码问题。
- 原因是:python默认用utf-8去读这个文件,但这个文件是用GBK存的。
- 解决方式是:在test.py文件的第一行增加编码格式内容
-
#coding:gbk
35.python2字符串以GBK存进去,读取的时候乱码怎么办?
- 解决方式:
- 1.在字符串前面加u
- 2.用Python3 去执行
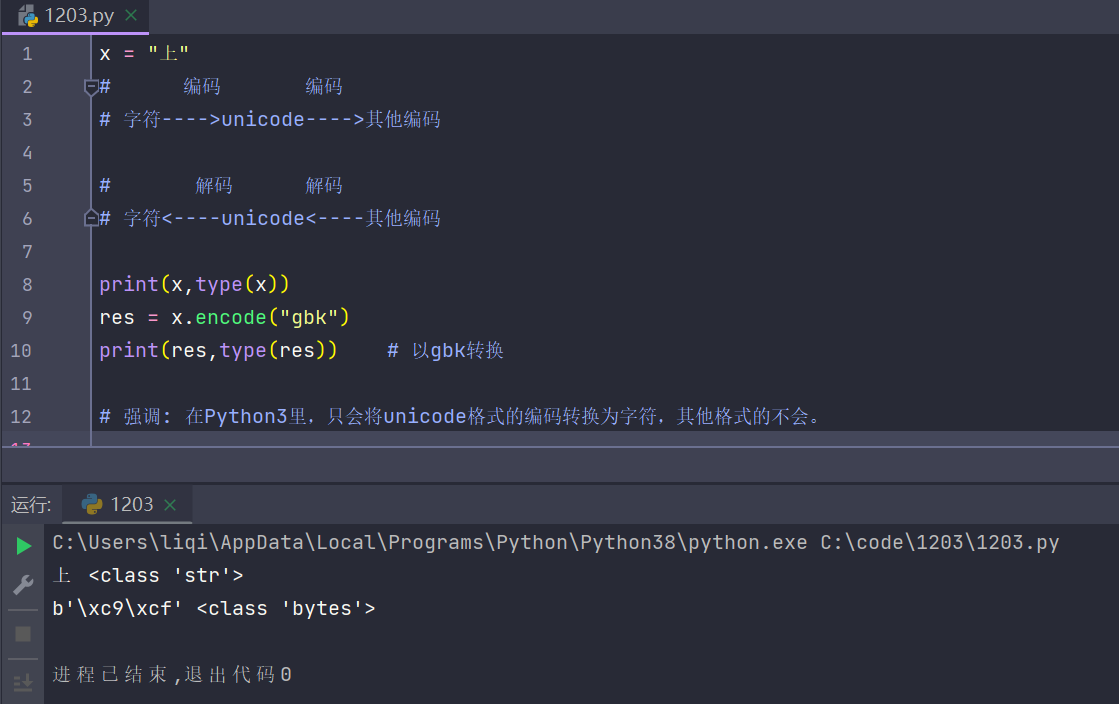
36.在Python3里,只会将unicode格式的编码转换为字符?
- 是的。
37.文件的w模式会清空文件吗?
- 会的。w模式会新建一个文件,如果已有会清空。
- 慎重使用!
38.文件a模式,会清空文件吗?
- 不会 。
39.文件a+模式是什么?
- a模式本身是追加写的操作
- a+就是加了新功能读的操作。
40.文件模式t模式一定要配置编码,b模式一定不要配置编码?
- 对的。
- t模式要配置编码格式
- b模式不配置编码格式
41.如何用Python写一个复制的工具?
- 利用文件的rb模式读取,wb模式写入。
-
with open(r"C:\Users\liqi\Videos\MOT16-09.mp4",mode="rb") as f1,open(r"C:\Users\liqi\Videos\1203_2.mp4",mode="wb") as f2: for line in f1: f2.write(line)
- 效果
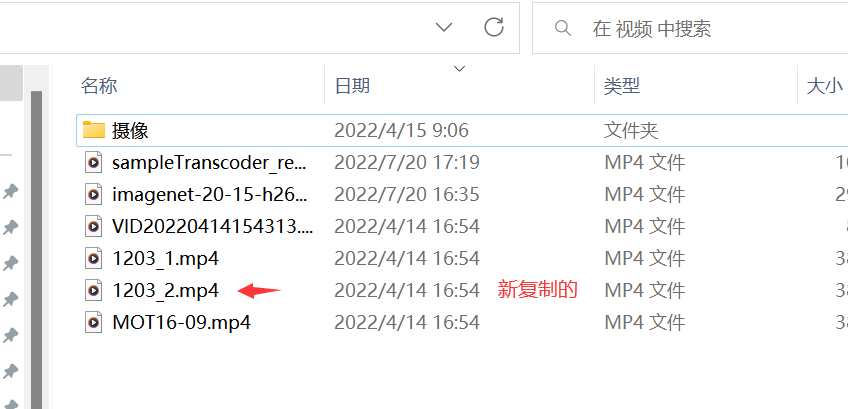
42.文件的指针怎么移动?
- f.seek()
- seek需要两个参数,第一个参数是移动的字节数量,第二个参数是模式。
- 模式分为3中:
- 0模式,永远参考文件开头。
- 1模式,参考指针当前位置。
- 2模式,永远参考文件末尾。
- 代码
43. 如何跟踪监控一个文件?
44.修改文件的两种方式?
- 第一种:
- 将文件内容全部读取到内存
- 在内存中修改
- 修改后覆盖源文件
- 第二种:
- 以读的方式打开原文件,写到另一个临时文件
- 读取文件的一行内容到内存,在内存中修改内容,写到另一个文件。循环往复直到全部内容修改完成
- 删除原文件,将临时文件,重命名为原文件的名字。
- 代码
-
# 方式1: # 特点: 费内存,省硬盘 # with open("e.txt", mode="rt", encoding="utf-8") as f: # data = f.read() # 全部读取到内存 # # with open("e.txt",mode="wt",encoding="utf-8") as fw: # fw.write(data.replace("liqi","LIQI")) # 方式2: # 特点: 省内存,费硬盘 # 实际应用多,原因是内存贵 with open("e.txt",mode="rt",encoding="utf-8") as f,open(".e.txt.swp",mode="wt",encoding="utf-8") as fw: for line in f.readlines():# 或者写成 for line in f: fw.write(line.replace("liqi","tutu")) import os os.remove("e.txt") os.rename(".e.txt.swp","e.txt")
(练习1)用for改下以下内容:
- 示例代码:(考察循环跟else的搭配使用)
-
View Code
1 # username = "liqi" 2 # password = "123" 3 # count = 0 4 # while count < 3: 5 # inp_name = input("请输入您的账号") 6 # inp_pwd = input("请输入您的密码") 7 # 8 # if inp_name == username and inp_pwd == password: 9 # print("登录成功!") 10 # while True: 11 # cmd = input("请输入命令>: ") 12 # if cmd == 'q': # 退出程序 13 # break 14 # else: 15 # print(f'命令{cmd}正在运行') 16 # break 17 # else: 18 # print('账号名或密码错误') 19 # count += 1 20 # else: # 【注意】这个else,是跟while一起的。若正常退出,执行else下面; 若是break出来的,就不执行。 21 # print("输错3次,退出")
- 答案:
-
View Code
1 """ 2 1.请用for循环改下以下代码: 3 4 """ 5 6 # username = "liqi" 7 # password = "123" 8 # count = 0 9 # while count < 3: 10 # inp_name = input("请输入您的账号") 11 # inp_pwd = input("请输入您的密码") 12 # 13 # if inp_name == username and inp_pwd == password: 14 # print("登录成功!") 15 # while True: 16 # cmd = input("请输入命令>: ") 17 # if cmd == 'q': # 退出程序 18 # break 19 # else: 20 # print(f'命令{cmd}正在运行') 21 # break 22 # else: 23 # print('账号名或密码错误') 24 # count += 1 25 # else: # 【注意】这个else,是跟while一起的。若正常退出,执行else下面; 若是break出来的,就不执行。 26 # print("输错3次,退出") 27 28 username = "tutu" 29 password = "123" 30 31 for i in range(3): 32 inp_name = input("请输入账号") 33 inp_pwd = input("请输入密码") 34 35 if inp_name == username and inp_pwd == password: 36 print("登录成功!".center(50,"=")) 37 while True: 38 cmd = input("请输入命令") 39 if cmd == 'q': 40 print("退出程序") 41 break 42 else: 43 print(f"正在执行{cmd}...") 44 break # 正常退出 程序 45 else: 46 print("账号密码错误".center(50,"=")) 47 else: 48 print("账号密码输入错误3次")
(练习2)简单的购物车
# 实现打印商品详细信息,用户输入商品和购买个数,则将商品名,价格,购买数量以三元组形式加入购物车。
- 答案:
-
View Code
1 # 简单的购物车 2 # 实现打印商品详细信息,用户输入商品和购买个数,则将商品名,价格,购买数量以三元组形式加入购物车。 3 msg_dic = { 4 'apple':7.96, 5 'tesla':298000, 6 'mac':8999, 7 'lenovo':5888, 8 'chicken':7 9 } 10 goods = [] 11 while True: 12 print(msg_dic) 13 goods_name = input("要购买的商品:").strip() 14 if goods_name not in msg_dic: 15 print("商品不存在".center(50,"=")) 16 continue 17 goods_counts = input("数量:").strip() 18 if not goods_counts.isdigit(): 19 print("数量不是整数".center(50,"=")) 20 continue 21 goods.append((goods_name,msg_dic[goods_name],goods_counts)) 22 print("目前购物车有:",goods)
(练习3)如何优化练习2,使同样的商品数量合并
- 答案
-
View Code
# 进一步优化 msg_dic = { 'apple': 7.96, 'tesla': 298000, 'mac': 8999, 'lenovo': 5888, 'chicken': 7 } goods = {} while True: print(msg_dic) goods_name = input("要购买的商品:").strip() if goods_name not in msg_dic: print("商品不存在".center(50, "=")) continue goods_counts = input("数量:").strip() if not goods_counts.isdigit(): print("数量不是整数".center(50, "=")) continue if goods_name not in goods: # 如果没有值的话 goods[goods_name] = int(goods_counts) else: # 否则就增加 goods[goods_name] += int(goods_counts) print("目前购物车有:", goods)
基本内容完结!~~
下一步进入函数、类的世界~~

