摘要:
# 1.认识决策树 >**决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法 怎么理解这句话?通过一个对话例子**   交叉验证:将拿到的训练数据,分为训练和验证集。以下图为例:将数据分成5份,其中一份作为验证集。然后经过5次(组)的测试,每次都更换不同的验证集。即得到5组模型的结果,取平均值作为最终结果。又称5折交叉验证。 我们之前知道数据分为训练集和测试 阅读全文
摘要:
# 1.来源 **fit和transform没有任何关系,仅仅是数据处理的两个不同环节,之所以出来fit_transform这个函数名,仅仅是为了写代码方便,会高效一点。 sklearn里的封装好的各种算法使用前都要fit,fit相对于整个代码而言,为后续API服务。fit之后,然后调用各种API方 阅读全文
摘要:
# 1.什么是k-近邻算法 例如: 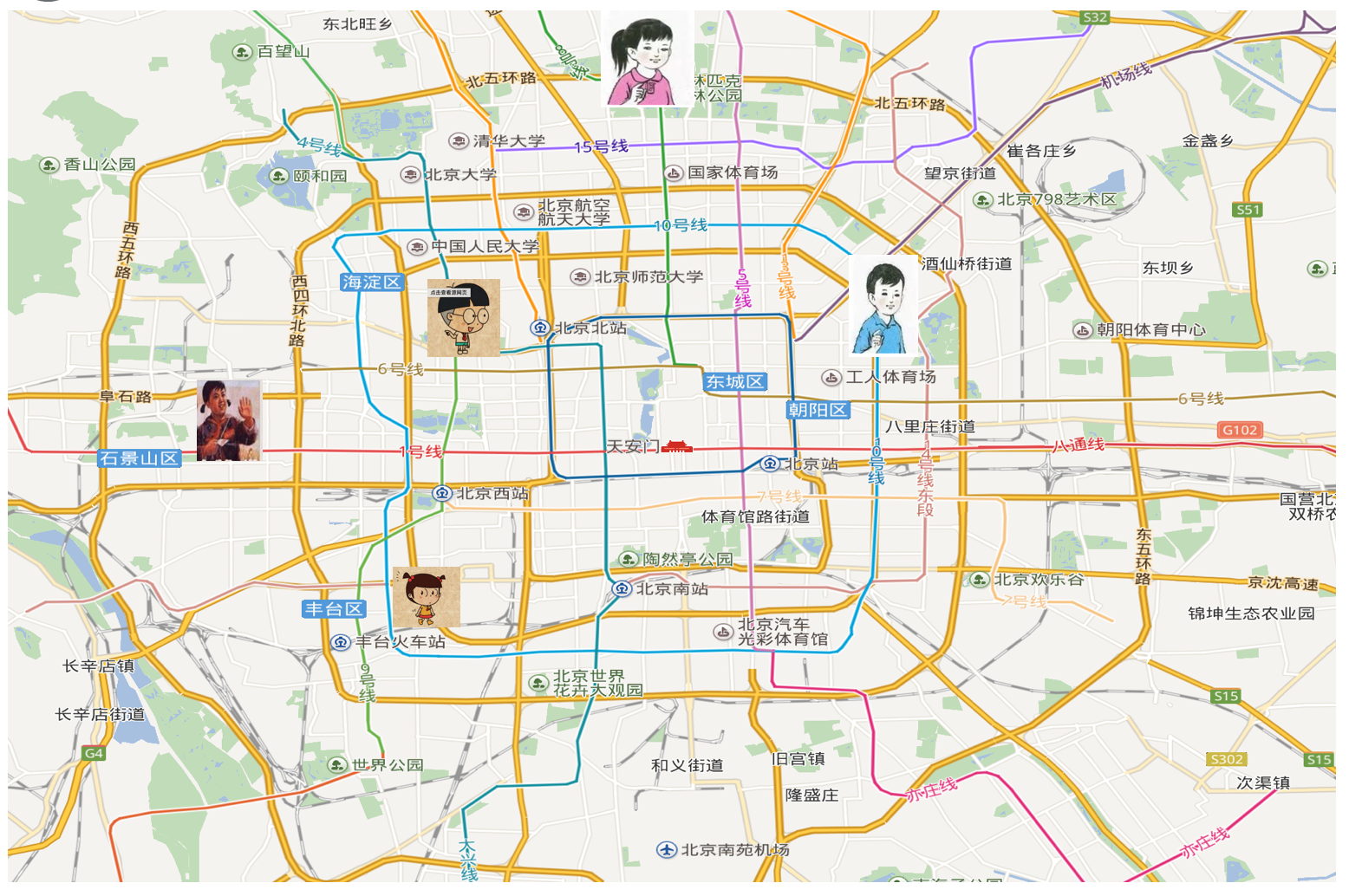 >**如果你不知道你现在在哪,你可以通过你和你的邻居的距离推算出你的 阅读全文
摘要:
# 1.转换器 **想一下之前做的特征工程的步骤? 1、实例化 (实例化的是一个转换器类(Transformer)) 2、调用fit_transform(对于文档建立分类词频矩阵,不能同时调用) ** ``` 标准化: (x-mean)/std fit_transform() fit() 计算每一列 阅读全文
摘要:
阅读全文
摘要:
# 1.什么是特征降维 >降低的对象为二维数组 此处的降维为**降低特征**的个数 **降维是指在某些限定条件下,降低随机变量(特征)个数,得到一组“不相关”主变量的过程** ![image](https://img2023.cnblogs.com/blog/1914163/202306/19141 阅读全文