redis中hash和解决哈希冲突和rehash
哈希表实际上是一个数组,数组里多每一个元素就是一个哈希桶。
当一个键值对的键经过 Hash 函数计算后得到哈希值,再将(哈希值 % 哈希表大小)取模计算,得到的结果值就是该 key-value 对应的数组元素位置,也就是第几个哈希桶。
下面是重点:
什么是哈希冲突呢?
举个例子,有一个可以存放8个哈希桶的哈希表。key1 经过哈希函数计算后,再将「哈希值%8」进行取模计算,结果值为 1,那么就对应哈希桶1,类似的,key9 和 key10 分别对应哈希桶1和桶 6.
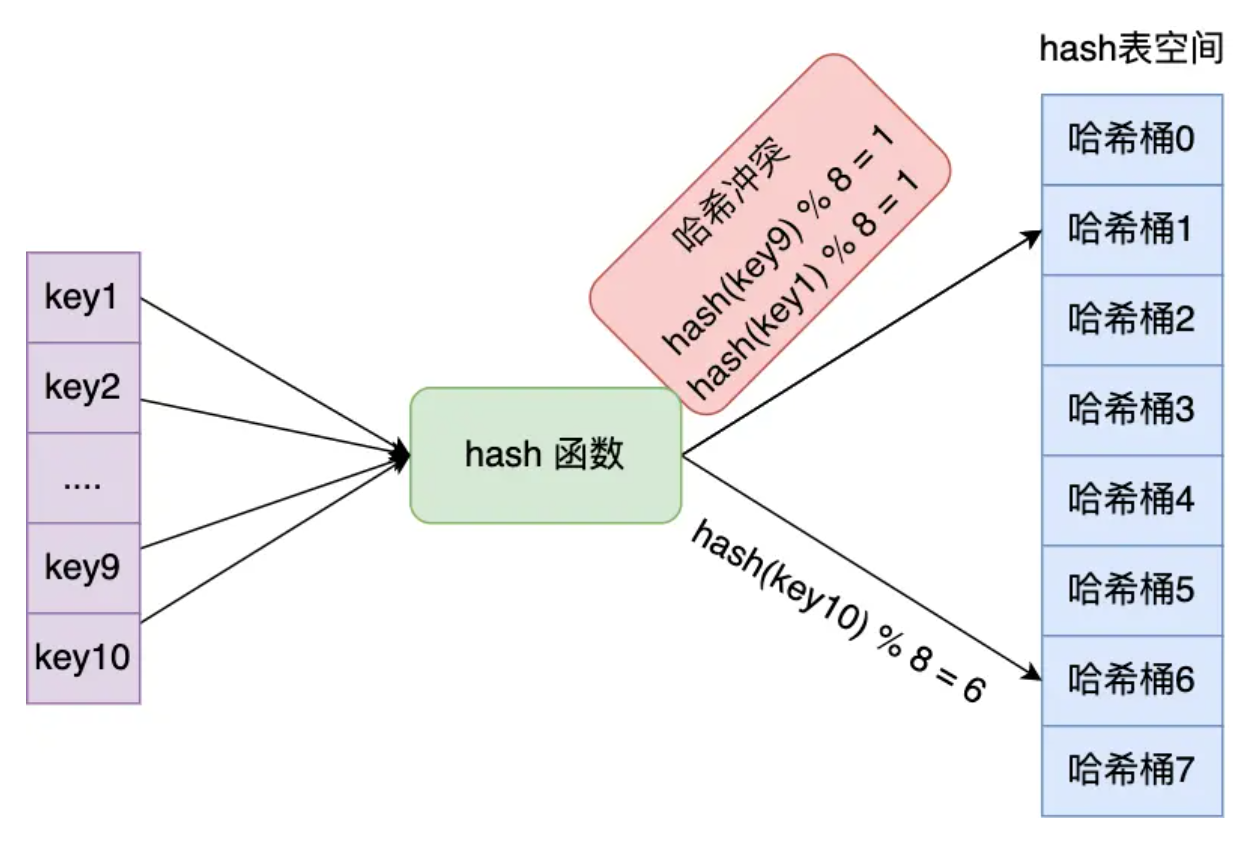
此时,key1 和 key9 对应到了相同的哈希桶中,这就发生了哈希冲突。
因此,当有两个以上数量的 kay 被分配到了哈希表中同一个哈希桶上时,此时称这些 key 发生了冲突。
链式哈希
Redis 采用了「链式哈希」的方法来解决哈希冲突。
链式哈希是怎么实现的?
实现的方式就是每个哈希表节点都有一个 next 指针,用于指向下一个哈希表节点,因此多个哈希表节点可以用 next 指针构成一个单项链表,被分配到同一个哈希桶上的多个节点可以用这个单项链表连接起来,这样就解决了哈希冲突。还是用前面的哈希冲突例子,key1和 key9 经过哈希计算后,都落在同一个哈希桶,链式哈希的话,key1就会通过 next 指针指向 key9,形成一个单向链表。
不过,链式哈希局限性也很明显,随着链表长度的增加,在査询这一位置上的数据的耗时就会增加,毕竟链表的査询的时间复杂度是 O(n)。
要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。
接下来,看看 Redis 是如何实现的 rehash 的。
rehash
不过,链式哈希局限性也很明显,随着链表长度的增加,在査询这一位置上的数据的耗时就会增加,毕竟链表的査询的时间复杂度是 O(n)。
要想解决这一问题,就需要进行 rehash,也就是对哈希表的大小进行扩展。
接下来,看看 Redis 是如何实现的 rehash 的。
之所以定义了 2 个哈希表,是因为进行 rehash 的时候,需要用上 2 个哈希表了。
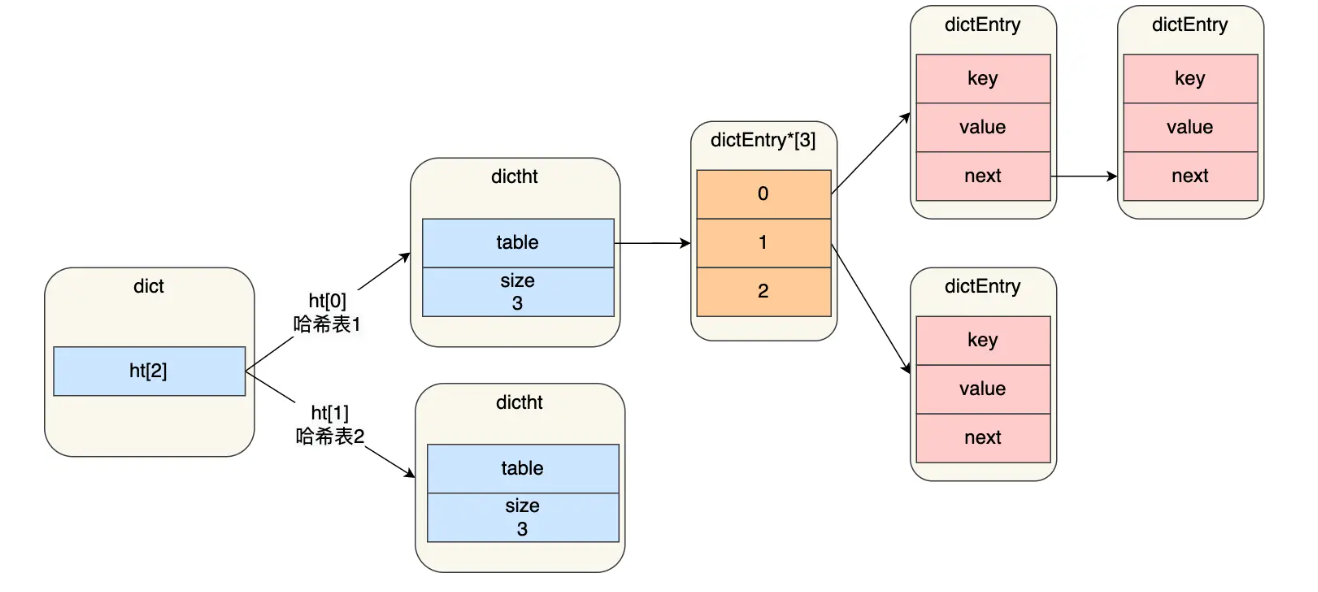
在正常服务请求阶段,插入的数据,都会写入到「哈希表1」,此时的「哈希表2」 并没有被分配空间。
随着数据逐步增多,触发了 rehash 操作,这个过程分为三步:
- 给「哈希表 2」 分配空间,一般会比「哈希表 1」大一倍(两倍的意思);。
- 将「哈希表1」的数据迁移到「哈希表 2」 中;
- 迁移完成后,「哈希表1」的空间会被释放,并把「哈希表 2」设置为「哈希表1」,然后在「哈希表2」 新创建一个空白的哈希表,为下次 rehash 做准备。
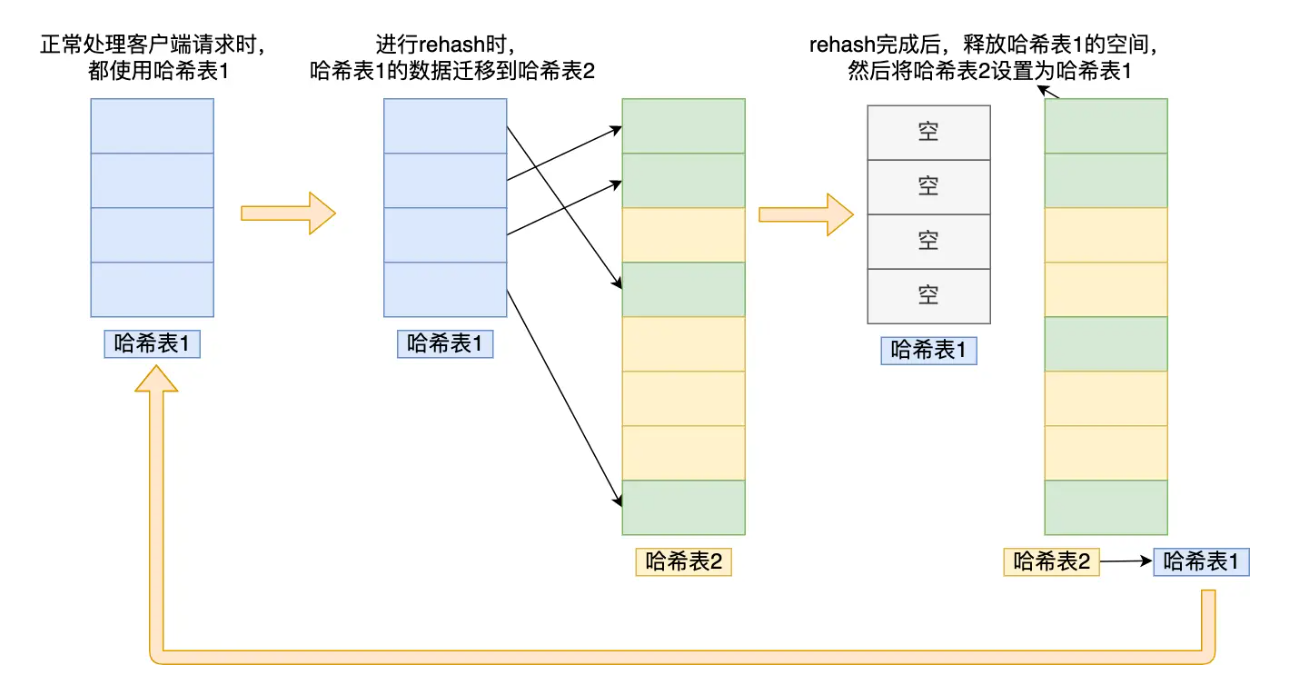
这个过程看起来简单,但是其实第二步很有问题,如果「哈希表1」的数据量非常大,那么在迁移至「哈希表2」的时候,因为会涉及大量的数据拷贝,此时可能会对Redis 造成阻塞,无法服务其他请求。
rehash 触发条件
介绍了 rehash 那么多,还没说什么时情况下会触发 rehash 操作呢?rehash 的触发条件跟负载因子(load factor) 有关系。负载因子可以通过下面这个公式计算:

触发 rehash 操作的条件,主要有两个:
- 当负载因子大于等于1,并且 Redis 没有在执行 bgsave 命令或者 bgrewiteaof 命令,也就是没有执行RDB 快照或没有进行 AOF 重写的时候,就会进行 rehash 操作。
- 当负载因子大于等于5时,此时说明哈希冲突非常严重了,不管有没有有在执行 RDB 快照或 AOF 重写,都会强制进行 rehash 操作。
在解决哈希冲突的时候,通常用链表法,如果这个某一个桶中链表太长怎么办?
-
扩容哈希表(Rehashing)
- 原理:
当链表长度超过阈值(如负载因子 ≥0.75)时,增大桶的数量并重新哈希所有元素,分散长链表。 - 实现:
新桶数量通常为原大小的 2 倍。
遍历旧表,将元素重新哈希到新桶中。 - 优点:
直接降低负载因子,均匀分布数据。 - 缺点:
扩容时需一次性迁移所有数据,可能引发短暂性能抖动。 - 适用场景:
通用场景,如 Java HashMap、Redis 哈希表(渐进式扩容)。
- 原理:
-
链表转树化(Treeify)
- 原理:
当链表长度超过阈值(如 ≥8),将其转换为 红黑树 或 跳表,将查询复杂度优化至 O(log n)。 - 实现:
树化阈值可配置(如 Java HashMap 的 TREEIFY_THRESHOLD=8)。
树节点需额外存储指针,内存开销略高。 - 优点:
显著提升长链表的查询效率。 - 缺点:
树结构维护复杂,插入/删除成本略高。 - 适用场景:
读多写少的长链表场景,如 Java HashMap。
- 原理:
-
动态哈希(Dynamic Hashing)
- 原理:
按需对特定桶进行 局部扩容(如可扩展哈希),避免全局扩容。 - 实现:
使用目录(Directory)指向桶,桶满时分裂并更新目录。
仅重组局部数据,降低迁移成本。 - 优点:
扩容粒度细,适合超大哈希表。 - 缺点:
目录维护复杂,内存碎片可能增加。 - 适用场景:
数据库索引、文件系统(如 Ext4 目录哈希)。
- 原理:
-
多级哈希(Multi-level Hashing)
- 原理:
对冲突严重的桶使用 第二层哈希函数,将数据分散到子桶中。 - 实现:
主哈希确定一级桶,二级哈希解决冲突。
子桶可以是链表、开放寻址或更小哈希表。 - 优点:
减少长链表概率,空间利用率高。 - 缺点:
多级哈希函数设计复杂,可能引入额外计算开销。 - 适用场景:
内存敏感型应用(如嵌入式系统)。
- 原理:
-
开放寻址法混合策略
- 原理:
当链表长度超过阈值后,切换为 开放寻址法(如线性探测)处理后续冲突。 - 实现:
链表存储旧冲突元素,新冲突元素通过开放寻址插入。
需记录每个桶的冲突处理策略(链表或开放寻址)。 - 优点:
避免链表无限增长,内存局部性更好。 - 缺点:
混合策略实现复杂,可能加剧哈希聚集。 - 适用场景:
对内存连续性敏感的场景(如 GPU 哈希表)。
- 原理:
-
一致性哈希(Consistent Hashing)
- 原理:
将哈希环虚拟化,数据分布在环上,桶节点动态增减时仅影响局部数据。 - 实现:
虚拟节点技术平衡分布。
长链表问题转化为相邻虚拟节点分配。 - 优点:
扩容缩容平滑,适合分布式系统。 - 缺点:
逻辑复杂,需维护哈希环状态。 - 适用场景:
分布式缓存(如 Redis Cluster)、负载均衡。
- 原理:
-
优化哈希函数
- 原理:
设计 高质量哈希函数,减少冲突概率(如 MurmurHash、SHA-1)。 - 实现:
引入随机种子(如 Java HashMap 的 hashSeed)。
使用更复杂的位混合运算。 - 优点:
从源头降低长链表概率。 - 缺点:
无法完全避免哈希碰撞。 - 适用场景:
所有哈希表实现的基础优化。
- 原理:
双哈希
就是当一个哈希表节点太多之后哈希就选到另一个节点


但是当链表很长也会影响性能,所以这个长链表可以简化成


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· AI 智能体引爆开源社区「GitHub 热点速览」
· 写一个简单的SQL生成工具
· Manus的开源复刻OpenManus初探