KMean聚类算法
1.可以向KMeans传入的参数:
sklearn官网所提供的参数说明有9个,我们使用时,如无特别需要,一般只有第一个参数(n_cluster)需要设置,其他参数直接采用默认值即可。
一种示例:
klearn.cluster.KMeans(n_clusters=8, init='k-means++', n_init=10, max_iter=300, tol=0.0001, verbose=0, random_state=None, copy_x=True, algorithm='auto')
对于我们来说,常常只需要:
sklearn.cluster.KMeans(n_clusters=K)
1. n_cluster:聚类个数(即K),默认值是8。
2. init:初始化类中心的方法(即选择初始中心点的根据),默认“K-means++”,其他可选参数包括“random”。
3. n_init:使用不同类中心运行的次数,默认值是10,即算法会初始化10次簇中心,然后返回最好的一次聚类结果。
4. max_iter:单次运行KMeans算法的最大迭代次数,默认值是300。
5. tol:浮点型,两次迭代之间簇内平方和下降的容忍阈值,默认为0.0001,如果两次迭代之间下降的值小于tol所设定的值,迭代就会停下。
6. verbose:是否输出详细信息,参数类型为整型,默认值为0,1表示每隔一段时间打印一次日志信息。
7. random_state:控制每次类中心随机初始化的随机种子,作用相当于能够锁定和复现同一次随机结果,默认为none,也可以随机设置数字。
8. copy_x:在预先计算距离时,首先将数据居中在数值上更准确。如果 copy_x 为 True(默认),则不修改原始数据。如果为 False,则修改原始数据,并在函数返回之前放回,但通过减去再添加数据均值可能会引入小的数值差异。请注意,如果原始数据不是C-contiguous,即使copy_x 为False,也会进行复制。如果原始数据是稀疏的,但不是 CSR 格式,即使 copy_x 为 False,也会进行复制。
9. algorithm:有三种参数可选:auto”, “full”, “elkan”,默认为auto。K-means 算法使用。经典的EM-style算法是“full”。通过使用三角不等式,“elkan” 变体对具有明确定义的集群的数据更有效。然而,由于分配了一个额外的形状数组(n_samples,n_clusters),它更加占用内存。
2.可以输出的属性:
通过调用这些属性,就可以输出我们所关注的一些聚类结果:
1. cluster_centers_:最终聚类中心的坐标;
2. labels_:每个样本点对应的类别标签;
3. inertia_:每个样本点到距离它们最近的类中心的距离平方和,即SSE;
4. n_iter:实际的迭代次数;
5. n_features_in_:参与聚类的特征个数;
6. feature_names_in_:参与聚类的特征名称。
例如:
我们使用sklearn中自带的鸢尾花数据集
import warnings #屏蔽警告
warnings.filterwarnings("ignore")
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris #调用数据
iris = load_iris() #导入sklearn自带的鸢尾花数据集
X = pd.DataFrame(iris.data, columns=iris.feature_names)
print(X.head(10))
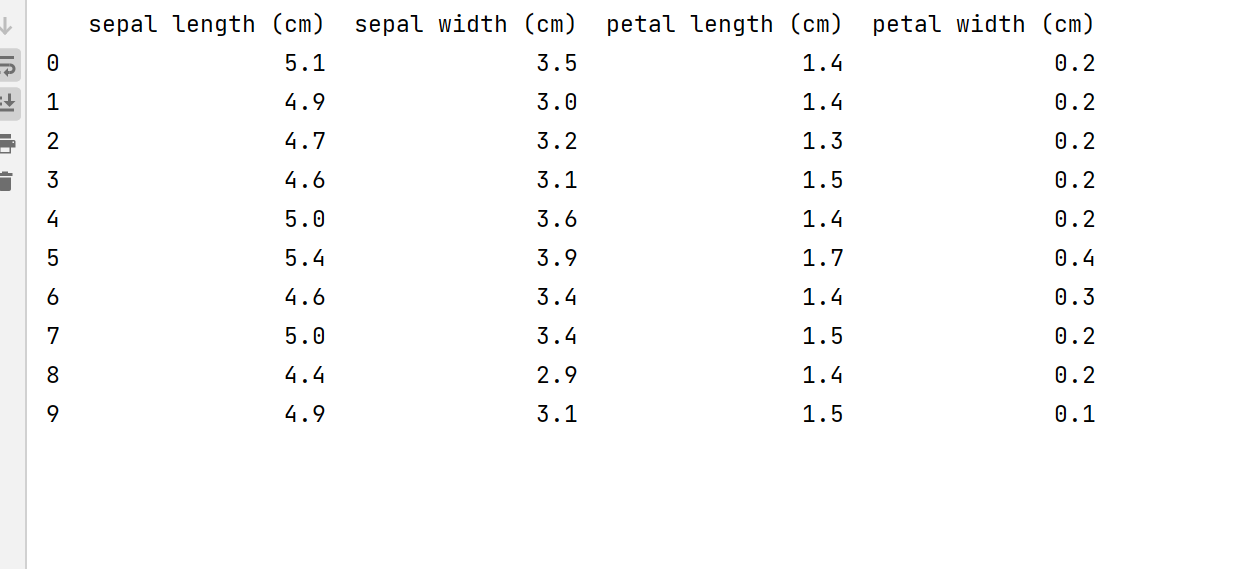
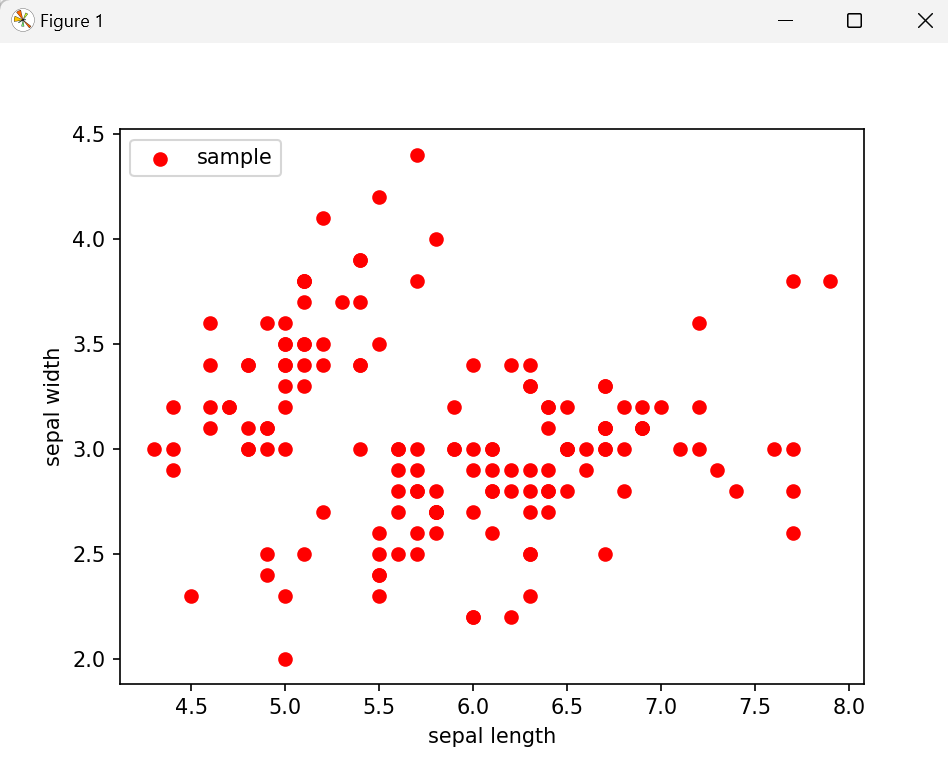
以萼片长度和萼片宽度为例,看看原始数据集在该二维空间的散点分布图
#取其中两个维度,绘制原始数据散点分布图
#x, y为散点坐标,c是散点颜色,marker是散点样式(如'o'为实心圆)
plt.scatter(X["sepal length (cm)"], X["sepal width (cm)"],c = "red", marker='o', label='sample')
#横坐标轴标签
plt.xlabel('sepal length')
#纵坐标轴标签
plt.ylabel('sepal width')
#plt.legend设置图例的位置
plt.legend(loc=2)
plt.show()
正式建模前,我们先尝试用手肘法确定最佳的K值。
from scipy.spatial.distance import cdist
#先对图像样式做一些设计
plt.plot()
colors = ['b','g','r']
markers = ['o','v','s']
#生成一个字典保存每次的代价函数
distortions = []
K = range(1,10)
for k in K:
#分别构建各种K值下的聚类器
Model = KMeans(n_clusters=k).fit(X)
#计算各个样本到其所在簇类中心欧式距离(保存到各簇类中心的距离的最小值)
distortions.append(sum(np.min(cdist(X, Model.cluster_centers_, 'euclidean'), axis=1)) / X.shape[0])
#绘制各个K值对应的簇内平方总和,即代价函数SSE
#可以看出当K=3时,出现了“肘部”,即最佳的K值。
plt.plot(K,distortions,'bx-')
#设置坐标名称
plt.xlabel('optimal K')
plt.ylabel('SSE')
plt.show()
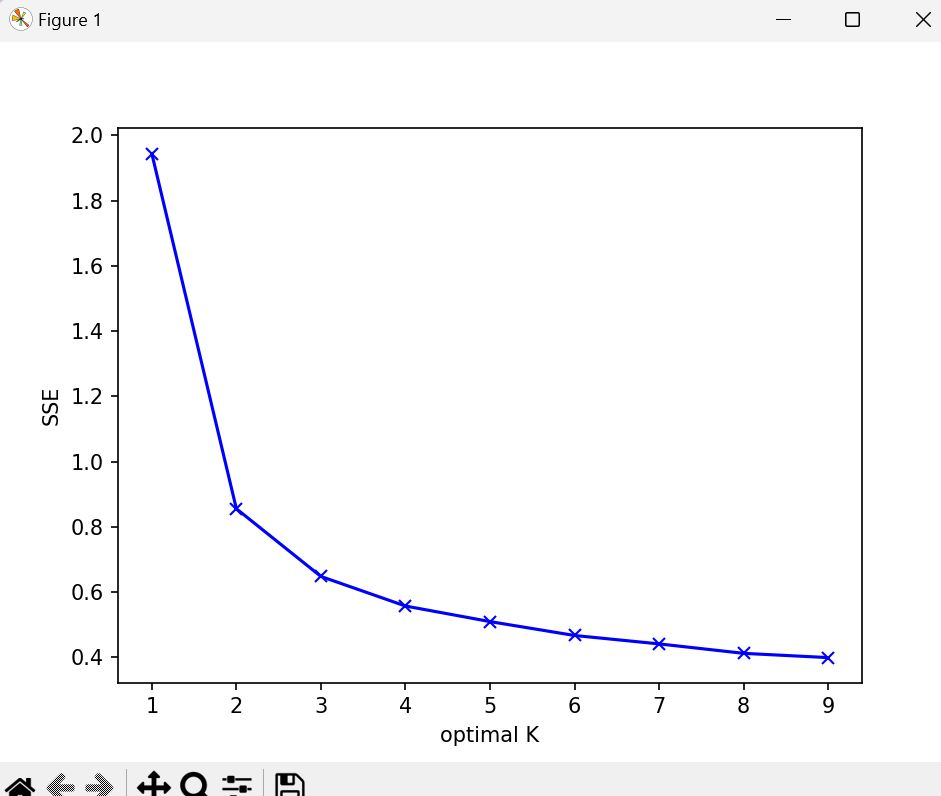
可以看出当K=3时,出现了“肘部”,即最佳的K值。
model = KMeans(n_clusters=3) #构造聚类器
model.fit(X) #拟合我们的聚类模型
获取聚类后的标签
label_pred = model.labels_ #获取聚类标签
print("聚类标签",label_pred)

获取聚类中心
ctr = model.cluster_centers_ #获取聚类中心
print("聚类中心",ctr)

聚类平方误差总和
inertia = model.inertia_ #获取SSE
print("计算得到聚类平方误差总和为",inertia)

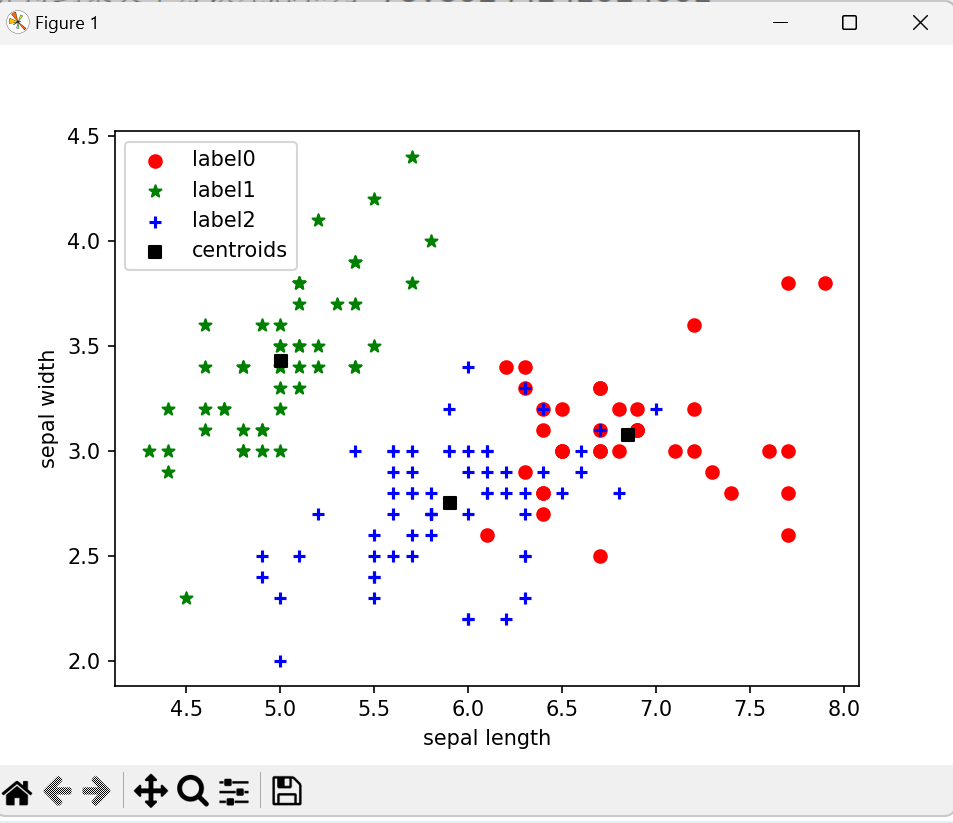
#最后再看一下我们的样本聚类后的效果吧:
#绘制K-Means结果
#取出每个簇的样本
x0 = X[label_pred == 0]
x1 = X[label_pred == 1]
x2 = X[label_pred == 2]
#分别绘出各个簇的样本
plt.scatter(x0["sepal length (cm)"], x0["sepal width (cm)"],
c = "red", marker='o', label='label0')
plt.scatter(x1["sepal length (cm)"], x1["sepal width (cm)"],
c = "green", marker='*', label='label1')
plt.scatter(x2["sepal length (cm)"], x2["sepal width (cm)"],
c = "blue", marker='+', label='label2')
plt.scatter(model.cluster_centers_[:,0],model.cluster_centers_[:,1],
c = "black", marker='s',label='centroids')
plt.xlabel('sepal length')
plt.ylabel('sepal width')
plt.legend(loc=2)
plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧