计算机视觉-SSD(Single Shot MultiBox Detector)
首先我们来看看Faster RCNN存在的问题:
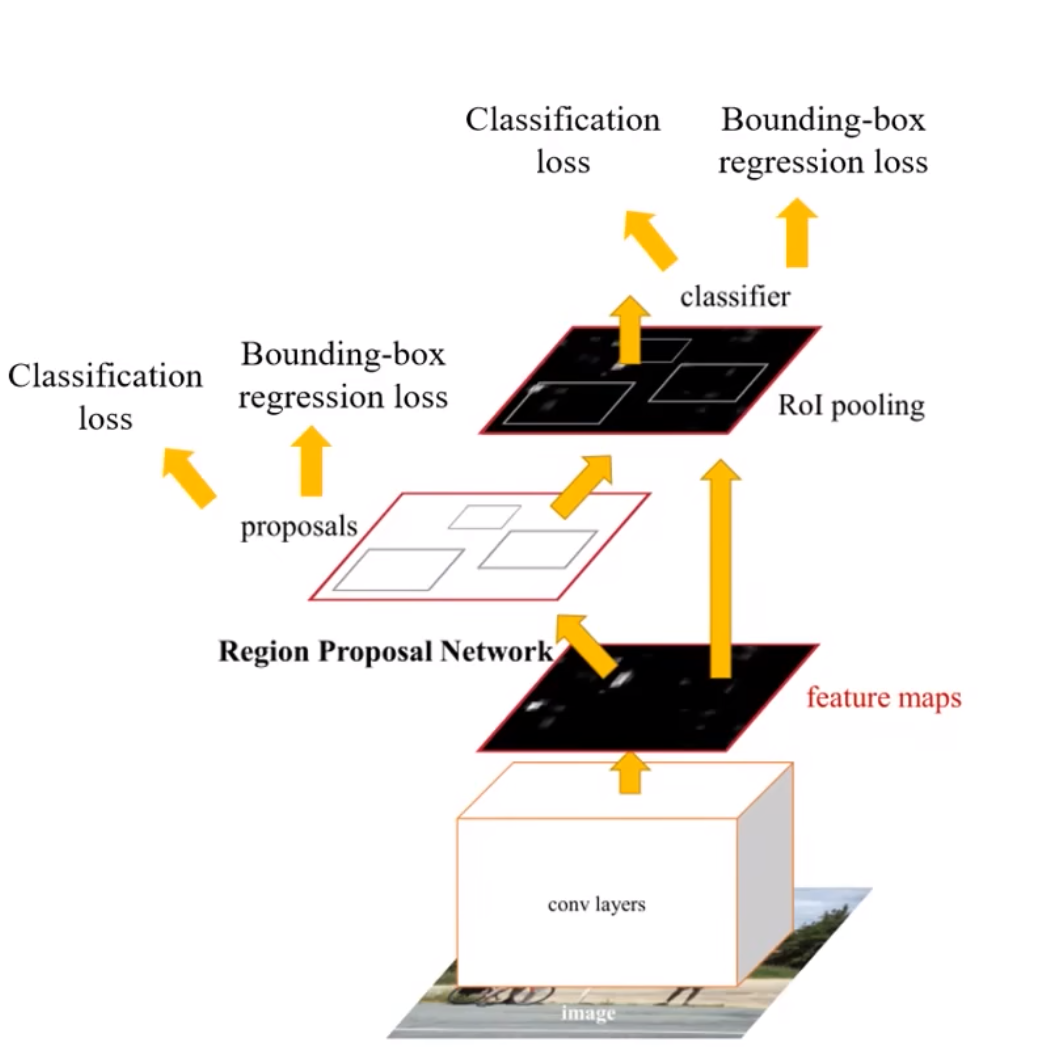
- 对小目标检测效果比较差:
个人感觉是因为它对整个的图像进行feature map,我们是对他卷积后的图像进行处理的,这样这个图像抽象的层次比较高,小的物体的特征很容易丢失。 - 模型大,检测速度较慢
简介
SSD算法源于2016年发表的算法论文,论文网址:https://arxiv.org/abs/1512.02325
SSD的特点在于:
-
SSD结合了YOLO中的回归思想和Faster-RCNN中的Anchor机制,使用全图各个位置的多尺度区域进行回归,既保持了YOLO速度快的特性,也保证了窗口预测的跟Faster-RCNN一样比较精准。
-
SSD的核心是在不同尺度的特征特征图上采用卷积核来预测一系列Default Bounding Boxes的类别、坐标偏移。
结构
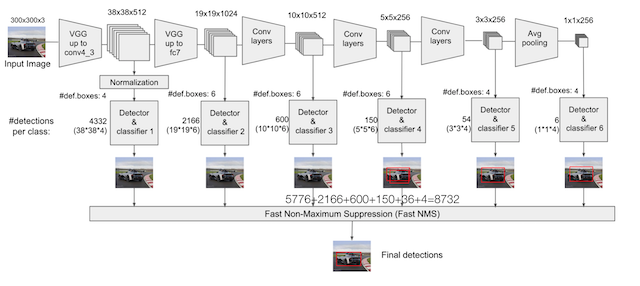
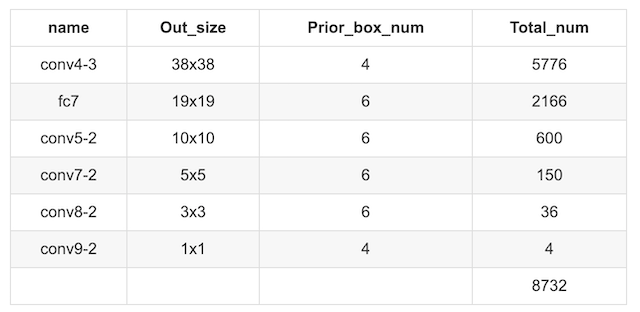
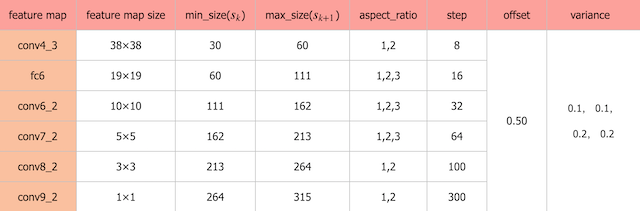
以VGG-16为基础,使用VGG的前五个卷积,后面增加从CONV6开始的5个卷积结构,输入图片要求。
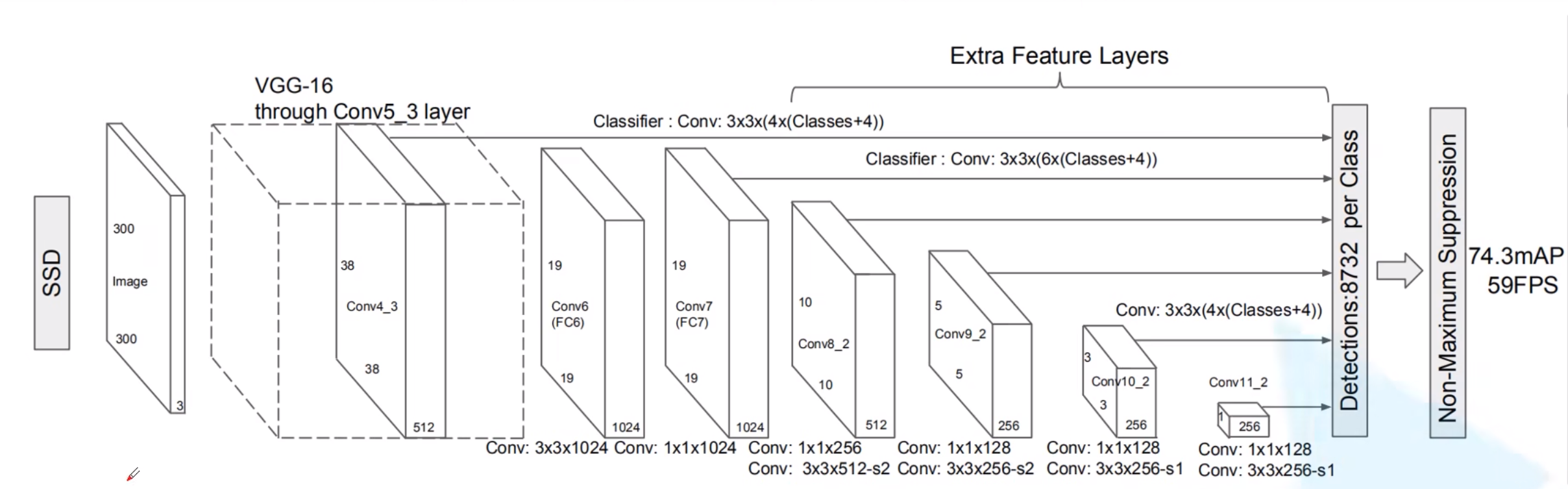
越往前的feature map层(越大的feature map)我们让他检测越小的物体,越靠后的层(越小的feature map)特征提取的比较很,然后检测比较大的物体。
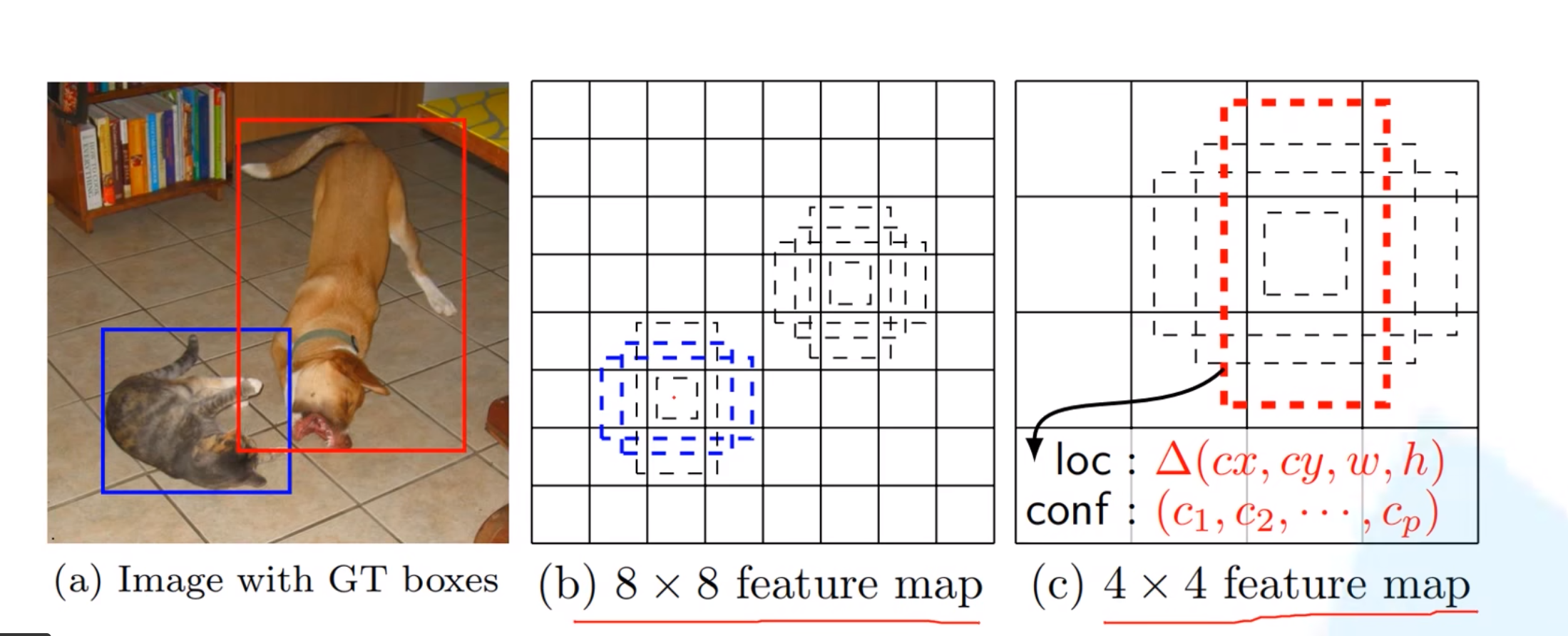
比如说这个较小的猫,就适合在比较大的feature map层进行检测,然后这个狗比较大,所以它就适合在比较小的层进行检测。
流程
SSD中引入了Defalut Box,实际上与Faster R-CNN的anchor box机制类似,就是预设一些目标预选框,不同的是在不同尺度feature map所有特征点上使用PriorBox层
Detector & classifier
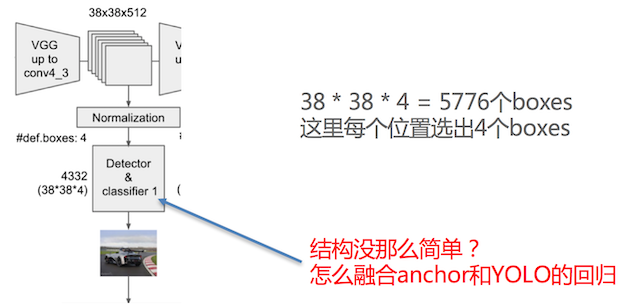
这里每个位置生成4个boxes。
Detector & classifier的三个部分:
-
PriorBox层:生成default boxes,默认候选框
-
Conv3 x 3:生成localization, 4个位置偏移
-
Conv3 x 3:confidence,21个类别置信度(要区分出背景,也就是20个分类+1个背景)
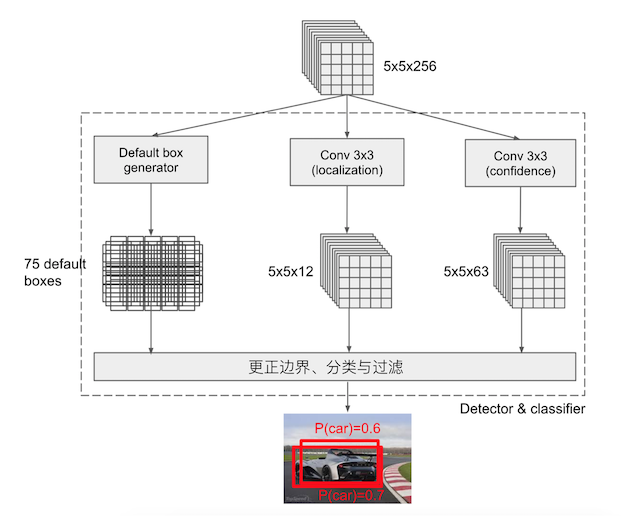
PriorBox层-default boxes
default box类似于RPN当中的滑动窗口生成的候选框,SSD中也是对特征图中的每一个像素生成若干个框。

- 特点分析:
- priorbox:相当于faster rcnn里的anchors,预设一些box,网络根据box,通过分类和回归给出被检测到物体的类别和位置。每个window都会被分类,并回归到一个更准的位置和尺寸上
- 各个feature map层经过priorBox层生成prior box
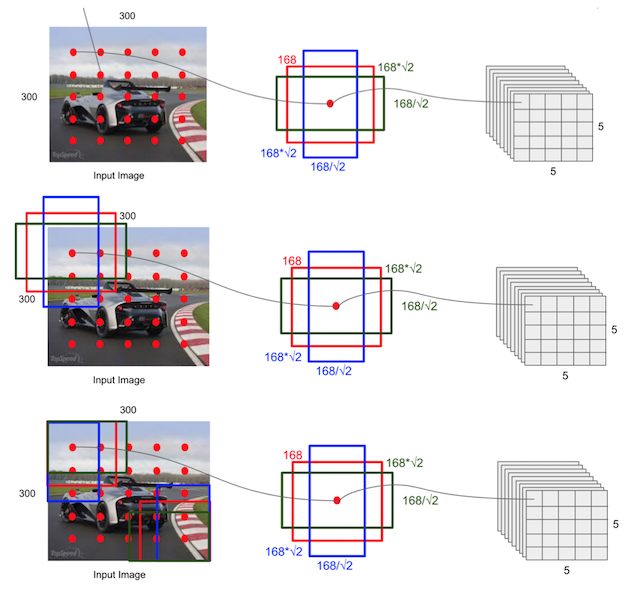
根据输入的不同aspect ratio 和 scale 以及 num_prior来返回特定的default box,
- default box 的数目是feature map的height x width x num_prior。
localization与confidence
这两者的意义如下,主要作用用来过滤,训练
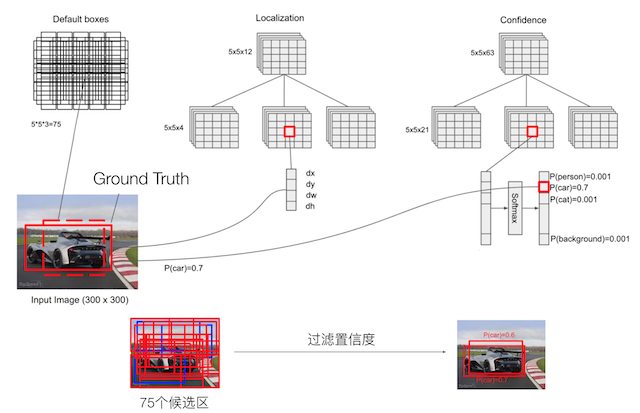
问题:SSD中的多个Detector & classifier有什么作用?
SSD的核心是在不同尺度的特征图上来进行Detector & classifier 容易使得SSD观察到更小的物体
训练与测试流程
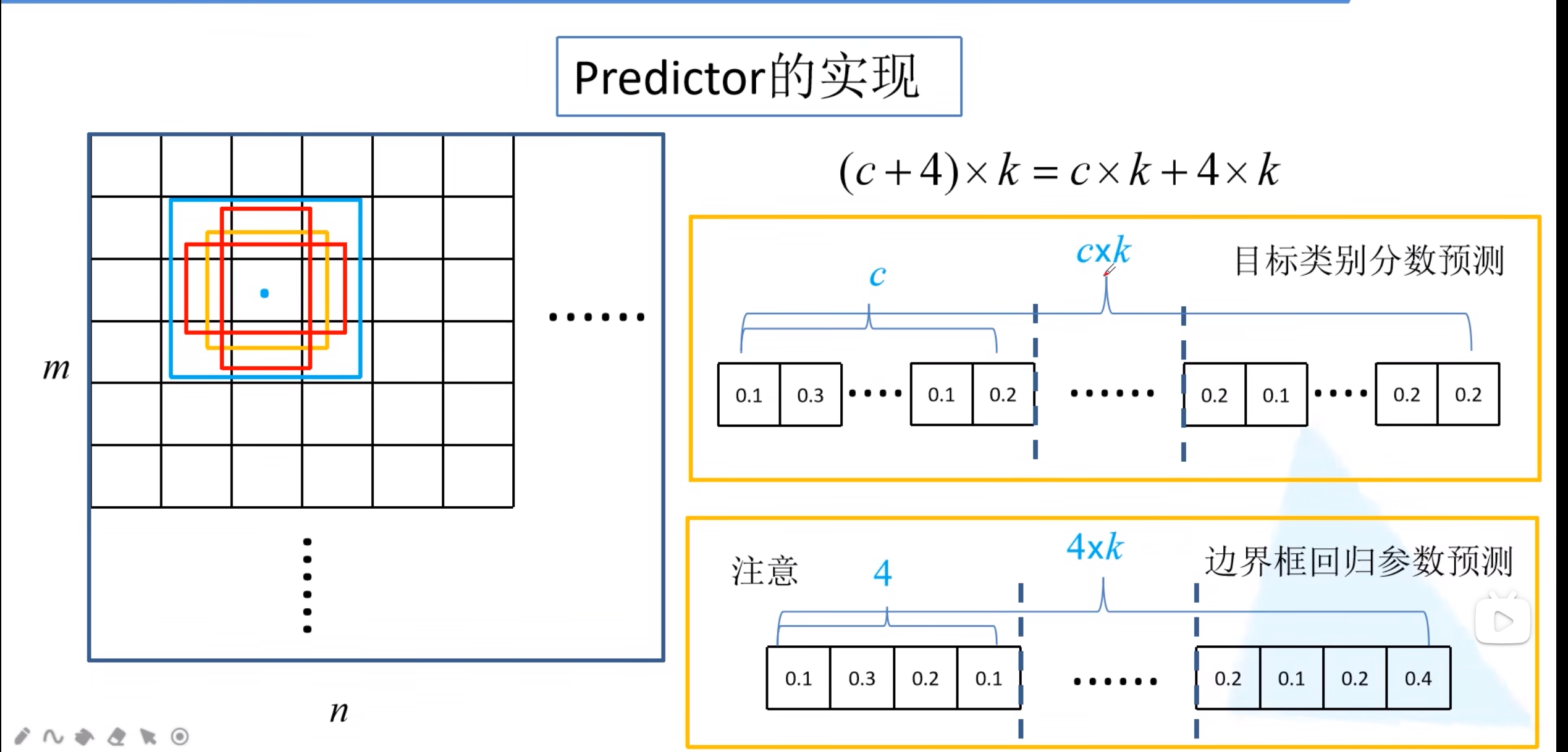
- 目标类别分数预测
对于每一个default box都会预测c个回归参数 - 边界框回归参数
对于每一个default box预测4个边界
train流程
- 输入->输出->结果与ground truth标记样本回归损失计算->反向传播, 更新权值
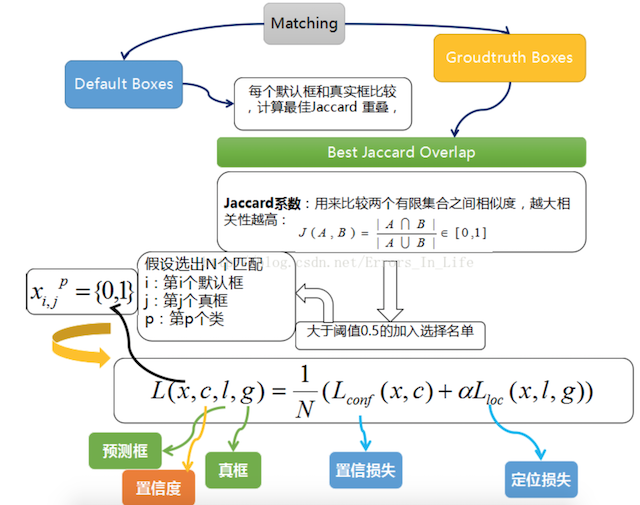
- 样本标记:
先将prior box与ground truth box做匹配进行标记正负样本,每次并不训练8732张计算好的default boxes, 先进行置信度筛选,并且训练指定的正样本和负样本, 如下规则
- 正样本
- 1.与GT重合最高的boxes, 其输出对应label设为对应物体.
- 2.物体GT与anchor iou满足大于0.5
- 负样本:其它的样本标记为负样本
在训练时, default boxes按照正负样本控制positive:negative=1:3
- 损失
网络输出预测的predict box与ground truth回归变换之间的损失计算, 置信度是采用 Softmax Loss(Faster R-CNN是log loss),位置回归则是采用 Smooth L1 loss (与Faster R-CNN一样)
test流程
输入->输出->nms->输出


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 【自荐】一款简洁、开源的在线白板工具 Drawnix
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· Docker 太简单,K8s 太复杂?w7panel 让容器管理更轻松!
2020-10-11 问题 C: Unique Values(队列+子序列)
2020-10-11 High Load Database(二分+前缀和)
2020-10-11 Managing Difficulties(mp的变形+三元组)
2020-10-11 Sum of a Function(区间筛)