优化算法-2.凸性
凸性(convexity)在优化算法的设计中起到至关重要的作用, 这主要是由于在这种情况下对算法进行分析和测试要容易。 换言之,如果算法在凸性条件设定下的效果很差, 那通常我们很难在其他条件下看到好的结果。 此外,即使深度学习中的优化问题通常是非凸的, 它们也经常在局部极小值附近表现出一些凸性。 这可能会产生一些像 (Izmailov et al., 2018)这样比较有意思的新优化变体。
%matplotlib inline
import numpy as np
import torch
from mpl_toolkits import mplot3d
from d2l import torch as d2l
定义
在进行凸分析之前,我们需要定义凸集(convex sets)和凸函数(convex functions)。
凸集
凸集(convex set)是凸性的基础。 简单地说,如果对于任何\(a,b \in \mathcal{X}\),连接\(a\)和的线段\(b\)也位于\(\mathcal{X}\)中,则向量空间中的一个集合\(\mathcal{X}\)是凸(convex)的。 在数学术语上,这意味着对于所有\(\lambda \in [0, 1]\),我们得到
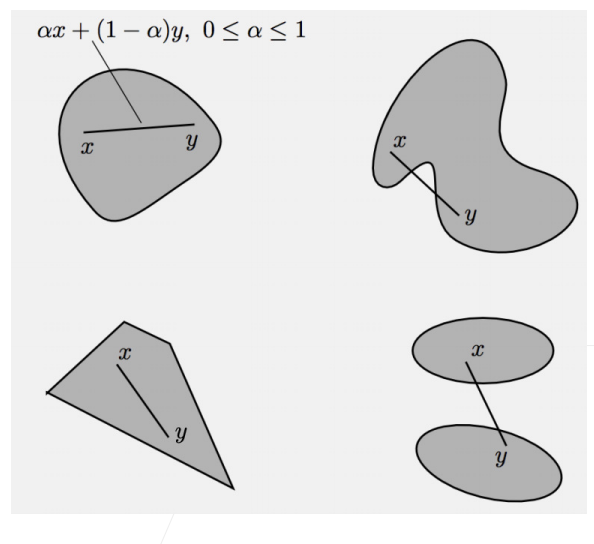
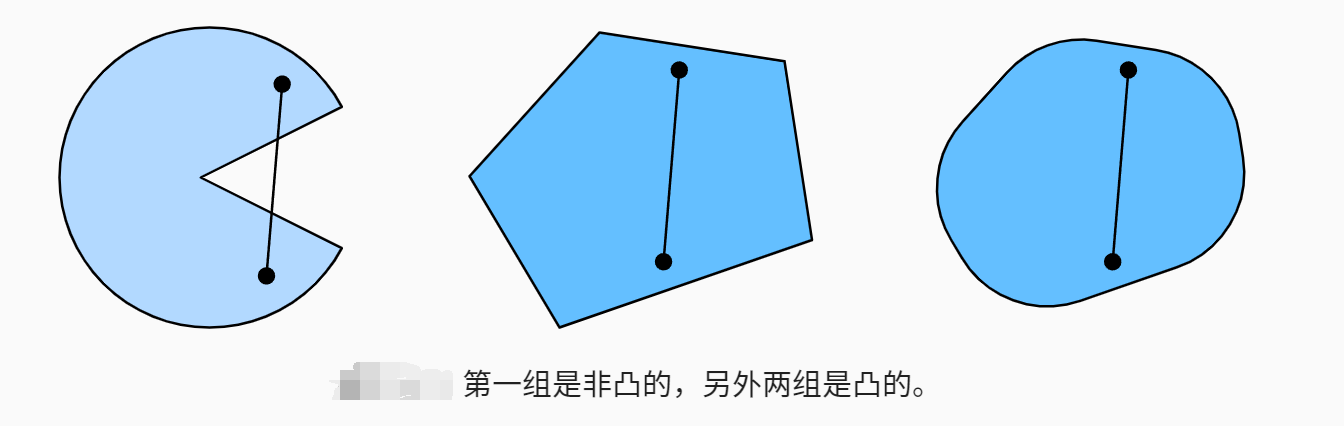
这听起来有点抽象,那我们来看一下下图里的例子。 第一组存在不包含在集合内部的线段,所以该集合是非凸的,而另外两组则没有这样的问题。
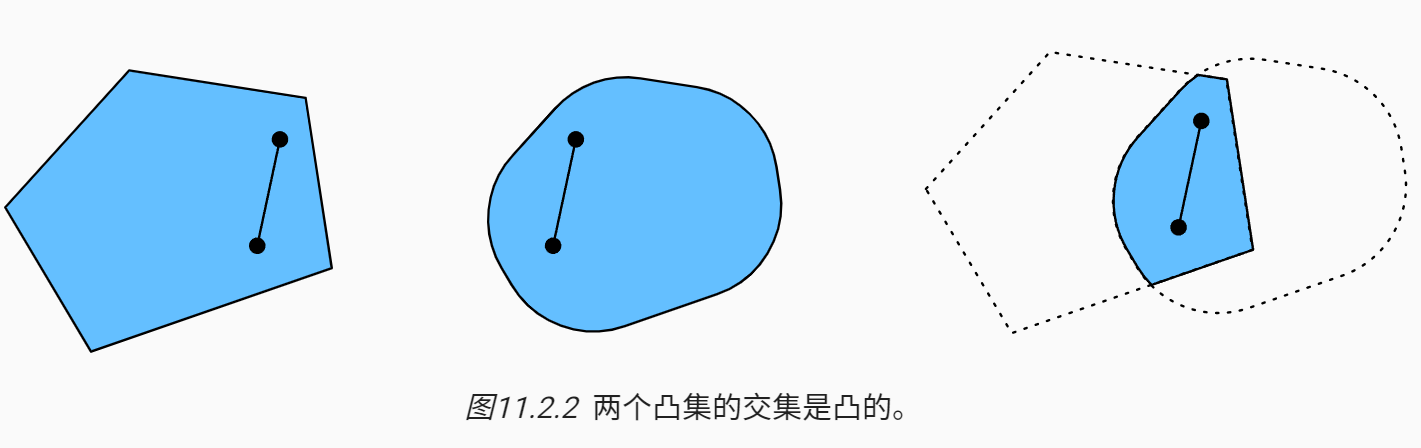
接下来来看一下交集图11.2.2。 假设\(\mathcal {X}\)和\(\mathcal {y}\)是凸集,那么也是\(\mathcal {X} \cap \mathcal{Y}\)凸集的。 现在考虑任意\(a, b \in \mathcal{X} \cap \mathcal{Y}\), 因为\(\mathcal {X}\)和\(\mathcal {y}\)是凸集, 所以连接\(a\)和\(b\)的线段包含在\(\mathcal {X}\)和\(\mathcal {y}\)中。 鉴于此,它们也需要包含在\(\mathcal {X} \cap \mathcal{Y}\)中,从而证明我们的定理。
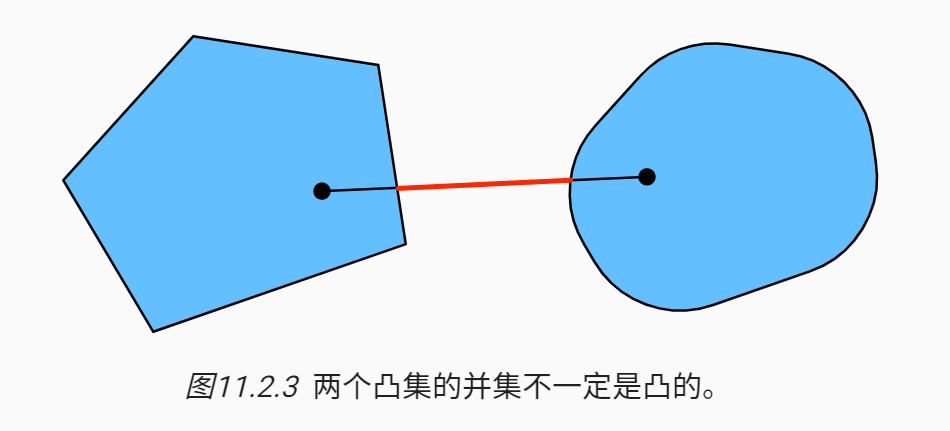
我们可以毫不费力地进一步得到这样的结果: 给定凸集\(\mathcal{X}_i\),它们的交集\(\cap_{i} \mathcal{X}_i\)是凸的。 但是反向是不正确的,考虑两个不相交的集合\(\mathcal{X} \cap \mathcal{Y} = \emptyset\), 取\(a \in \mathcal{X}\)和\(b \in \mathcal{y}\)。 因为我们假设\(\mathcal{X} \cap \mathcal{Y} = \emptyset\), 在 图11.2.3中连接\(a\)和\(b\)的线段需要包含一部分既不在\(\mathcal{X}\)也不在\(\mathcal{y}\)中。 因此线段也不在\(\mathcal{X} \cup \mathcal{Y}\)中,因此证明了凸集的并集不一定是凸的,即非凸(nonconvex)的。
通常,深度学习中的问题是在凸集上定义的。 例如\(\mathbb{R}^d\),,即实数的\(d\)-维向量的集合是凸集(毕竟\(\mathbb{R}^d\)中任意两点之间的线存在\(\mathbb{R}^d\))中。 在某些情况下,我们使用有界长度的变量,例如球的半径定义为\(\{\mathbf{x} | \mathbf{x} \in \mathbb{R}^d \text{ 且 } \| \mathbf{x} \| \leq r\}\)。
凸函数
现在我们有了凸集,我们可以引入凸函数(convex function)\(f\)。 给定一个凸集\(\mathcal{X}\),如果对于所有\(x, x' \in \mathcal{X}\)和所有\(\lambda \in [0, 1]\),函数\(f: \mathcal{X} \to \mathbb{R}\)是凸的,我们可以得到
为了说明这一点,让我们绘制一些函数并检查哪些函数满足要求。 下面我们定义一些函数,包括凸函数和非凸函数。
f = lambda x: 0.5 * x**2 # 凸函数
g = lambda x: torch.cos(np.pi * x) # 非凸函数
h = lambda x: torch.exp(0.5 * x) # 凸函数
x, segment = torch.arange(-2, 2, 0.01), torch.tensor([-1.5, 1])
d2l.use_svg_display()
_, axes = d2l.plt.subplots(1, 3, figsize=(9, 3))
for ax, func in zip(axes, [f, g, h]):
d2l.plot([x, segment], [func(x), func(segment)], axes=ax)
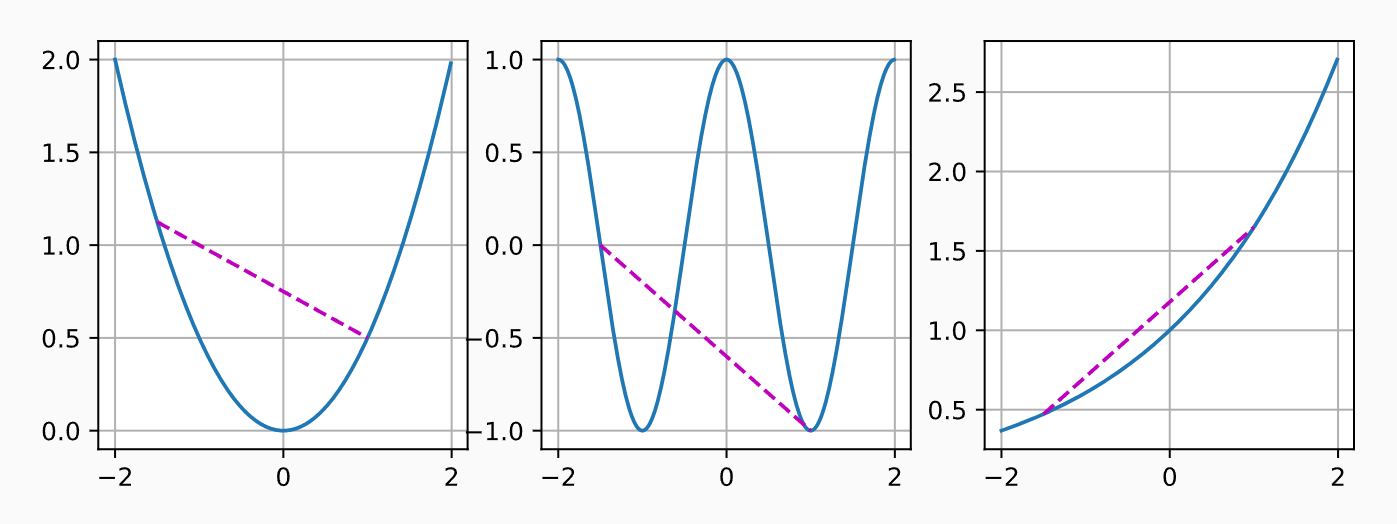
不出所料,余弦函数为非凸的,而抛物线函数和指数函数为凸的。 请注意,为使该条件有意义,\(\mathcal{X}\)是凸集的要求是必要的。 否则可能无法很好地界定\(f(\lambda x + (1-\lambda) x')\)的结果。
詹森不等式
给定一个凸函数\(f\),最有用的数学工具之一就是詹森不等式(Jensen’s inequality)。 它是凸性定义的一种推广:
其中\(\alpha_i\)是满足\(\sum_i \alpha_i = 1\)的非负实数,\(X\)是随机变量。 换句话说,凸函数的期望不小于期望的凸函数,其中后者通常是一个更简单的表达式。 为了证明第一个不等式,我们多次将凸性的定义应用于一次求和中的一项。
詹森不等式的一个常见应用:用一个较简单的表达式约束一个较复杂的表达式。 例如,它可以应用于部分观察到的随机变量的对数似然。 具体地说,由于\(\int P(Y) P(X \mid Y) dY = P(X)\)所以
这里,\(Y\)是典型的未观察到的随机变量,\(P(Y)\)是它可能如何分布的最佳猜测,\(P(Y)\)是将\(Y\)积分后的分布。 例如,在聚类中\(Y\)可能是簇标签,而在应用簇标签时,\(P(X \mid Y)\)是生成模型。
性质
局部极小值是全局极小值
首先凸函数的局部极小值也是全局极小值。 下面我们用反证法给出证明。
假设\(x^{\ast} \in \mathcal{X}\)是一个局部最小值,则存在一个很小的正值\(p\),使得当\(x \in \mathcal{X}\)满足\(0 < |x - x^{\ast}| \leq p\)时,有\(f(x^{\ast}) < f(x)\)。
现在假设局部极小值\(x^{\ast}\)不是\(f\)的全局极小值:存在\(x' \in \mathcal{X}\)使得\(f(x') < f(x^{\ast})\)。 则存在\(\lambda \in [0, 1)\),比如\(\lambda = 1 - \frac{p}{|x^{\ast} - x'|}\)
,使得 \(0 < |\lambda x^{\ast} + (1-\lambda) x' - x^{\ast}| \leq p\)。
然而,根据凸性的性质,有
这与\(x^{\ast}\)是局部最小值相矛盾。 因此,不存在满足。 综上所述,局部最小值也是全局最小值。
例如,对于凸函数\(f(x) = (x-1)^2\),有一个局部最小值\(x=1\),它也是全局最小值。
f = lambda x: (x - 1) ** 2
d2l.set_figsize()
d2l.plot([x, segment], [f(x), f(segment)], 'x', 'f(x)')
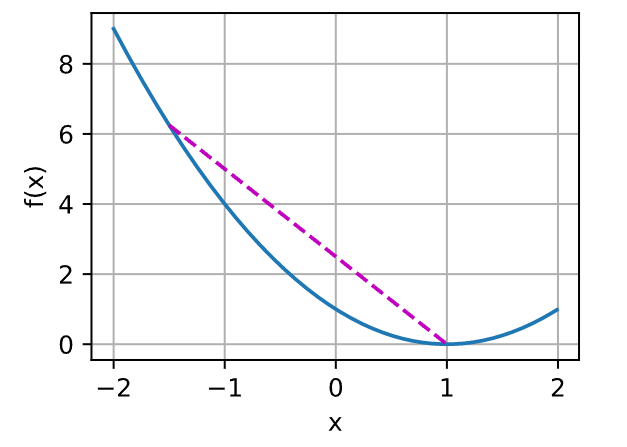
凸函数的局部极小值同时也是全局极小值这一性质是很方便的。 这意味着如果我们最小化函数,我们就不会“卡住”。 但是请注意,这并不意味着不能有多个全局最小值,或者可能不存在一个全局最小值。 例如,函数\(f(x) = \mathrm{max}(|x|-1, 0)\)在区间\([-1,1]\)上都是最小值。 相反,函数\(f(x) = \exp(x)\)在\(\mathbb{R}\)上没有取得最小值。对于\(x \to -\infty\),它趋近于,但是没有的。
凸函数的下水平集是凸的
我们可以方便地通过凸函数的下水平集(below sets)定义凸集。 具体来说,给定一个定义在凸集\(\mathcal{X}\)上的凸函数\(f\),其任意一个下水平集
是凸的.
让我们快速证明一下。 对于任何\(x, x' \in \mathcal{S}_b\),我们需要证明:当\(\lambda \in [0, 1]\)时,\(\lambda x + (1-\lambda) x' \in \mathcal{S}_b\)。 因为\(f(x) \leq b\)且\(f(x') \leq b\),所以
约束
凸优化的一个很好的特性是能够让我们有效地处理约束(constraints)。 即它使我们能够解决以下形式的约束优化(constrained optimization)问题:
这里\(f\)是目标函数,\(c_i\)是约束函数。 例如第一个约束\(c_1(\mathbf{x}) = \|\mathbf{x}\|_2 - 1\),则参数被\(\mathbf{x}\)限制为单位球。 如果第二个约束\(c_2(\mathbf{x}) = \mathbf{v}^\top \mathbf{x} + b\),那么这对应于半空间上所有的\(\mathbf{x}\)。 同时满足这两个约束等于选择一个球的切片作为约束集。
凸函数优化
如果代价函数\(f\)是凸的,且限制集合\(C\)是凸的,那么就是凸优化问题,那么局部最小一定是全局最小(也就是说优化算法找到的局部最小点一定是全局最优解)
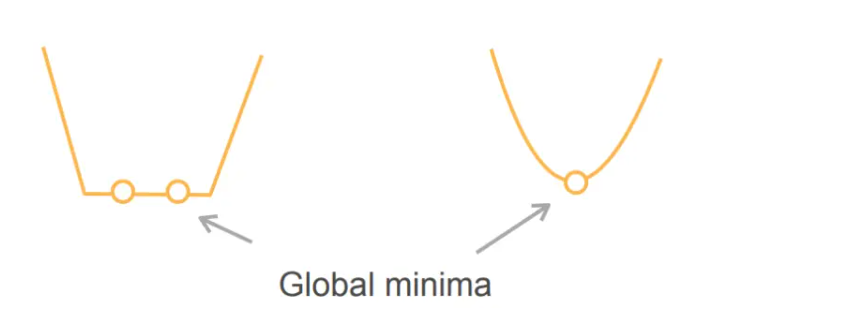
严格凸优化问题有唯一的全局最小
-
上图左侧的函数不是严格的凸函数,不满足严格凸函数的定义,函数上存在两点的连线(除端点外)与函数存在交点
-
上图右侧的函数是一个严格的凸函数,所以它只有唯一的最小值
凸和非凸例子: -
机器学习绝大部分都不是凸优化
-
目前为止只有两个是凸的:
- 线性回归\(f(x)=||Wx-b||_2^2\)
- Softmax回归
-
剩下的都是非凸的
- MLP:有一个隐藏层的 MLP,因为激活函数不是线性的,导致它是非线性的(非线性的是非凸的)
- CNN:卷积本身是线性的,但是卷积加了激活函数之后就不是线性的了
- RNN
- attetion
- 。。。。。
所有的模型都是非凸的
- 凸函数的表达能力是非常有限的
- 对于深度学习来讲,实用性是排在第一位的,理论是靠后的,如果是研究理论的话,需要从统计的角度来看待问题,从统计的角度来讲会考虑很多的凸优化问题
- 从深度学习来讲,是从计算机的角度考虑效果,而不是过于考虑理论,所导致基本上做的都是非凸的
- 优化的很多理论基本上是凸优化,最近也有研究非凸的,但是整体来讲大块是针对凸函数的优化,对于非凸的模型很难说有特别大的指导意义

 浙公网安备 33010602011771号
浙公网安备 33010602011771号