子词嵌入-FastText介绍
我们之前学了很多词语言模型:
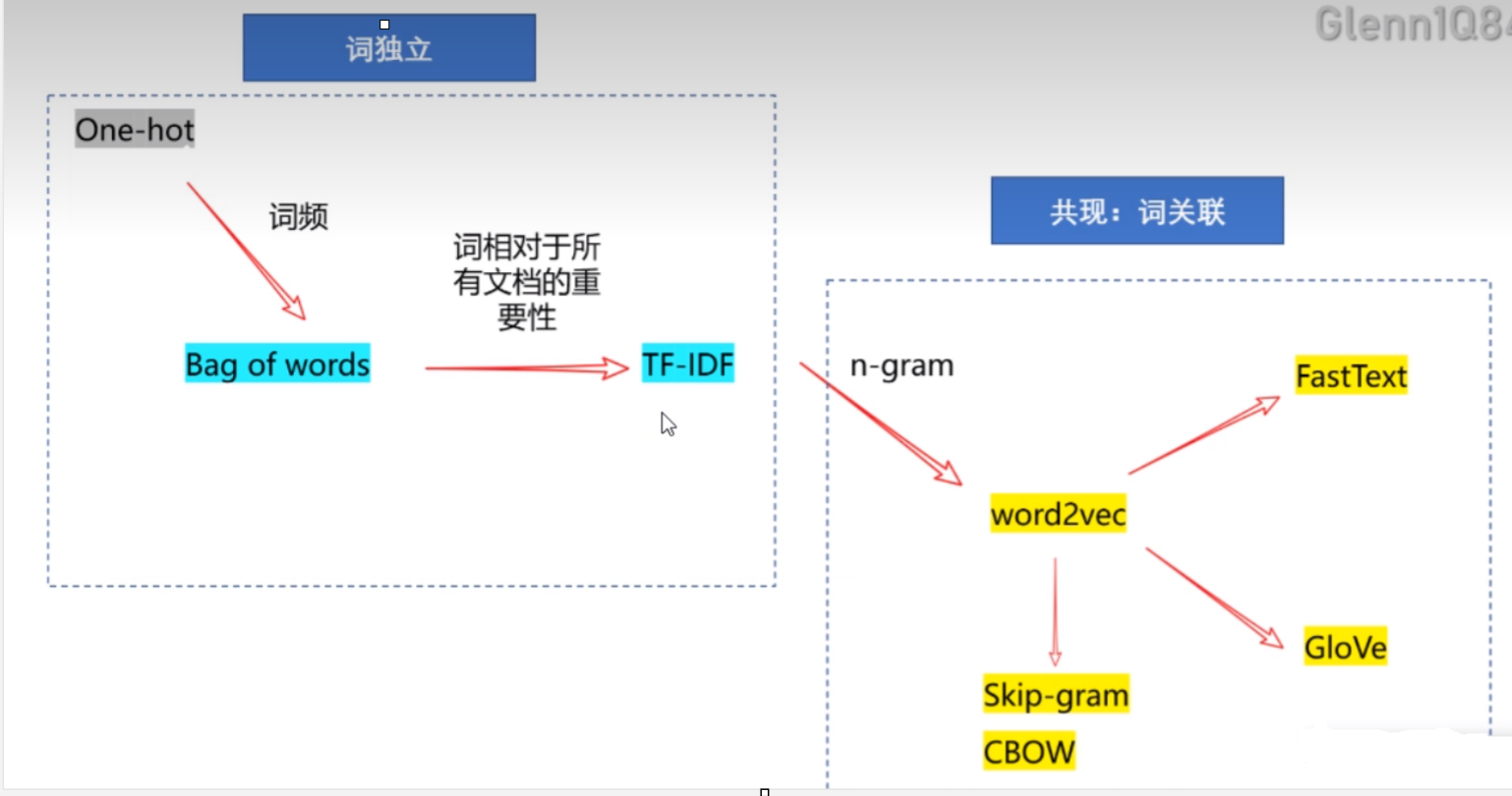
如果我们词独立的话有方法:One-hot、Bag of words、IF-IDF。
然后如果我们假设词与词之间是相互关联的话有方法:word2vec,FastText和Glove。
在英语中,“helps”“helped”和“helping”等单词都是同⼀个词“help”的变形形式。“dog”和“dogs”之间的关系与“cat”和“cats”之间的关系相同,“boy”和“boyfriend”之间的关系与“girl”和“girlfriend”之间的关系相同。在法语和西班⽛语等其他语⾔中,许多动词有40多种变形形式,⽽在芬兰语中,名词最多可能有15种变形。在语⾔学中,形态学研究单词形成和词汇关系。但是,word2vec和GloVe都没有对词的内部结构进⾏探讨。
fastText模型
结构
FastText在模型结构上采用了模型的结构,结构如下:
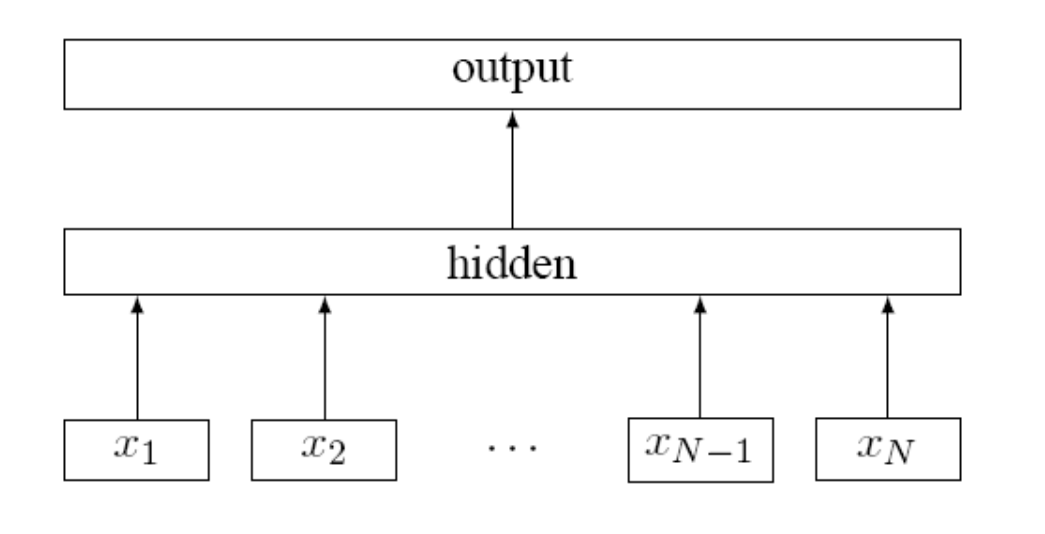
其中这里的是输入的词,整个网络与都一样,不同之处主要有以下方面:
- 预测的是中心词,FastText最后输出的是各个标签的概率;
- FastText 由于面向的是超多分类以及大量数据的情况,所以FastText 最后的输出采用了层级Softmax,大大优化了模型的运行速度
n-gram
首先要声明,在原论文中,n-gram并不是FastText必要的步骤,仅仅是一个锦上添花的步骤而已,没有n-gram它还是FastText。
引入n-gram首先是为了解决word2vec中的词序问题,比如两个句子"你礼貌吗"和"礼貌你吗"这两个句子仅仅词序不同,但是意思却天差地别,这种情况word2vec是检测不到词序的不同的,由此提出了n-gram。
注意,词分类模型的n-gram的是word级别的,并不是字符级别的,比如,有如下的句子
如果n-gram中的时,那么输入其中的句子经过n-gram后被分为以下部分 I 三个部分,输入也是这三个部分。
尽管如此,还是需要注意一下几个方面:
- 分类模型的n-gram是word级别的,并非字符级别
- n-gram并不是FastText模型中必须的,仅仅是锦上添花
- 和 FastText都是用求和平均值来预测的
- 词向量初始化都是随机的,FastText 并没有在 word2vec 预训练词嵌入的基础上再训练
why 要提出FastText: Word2Vec的局限
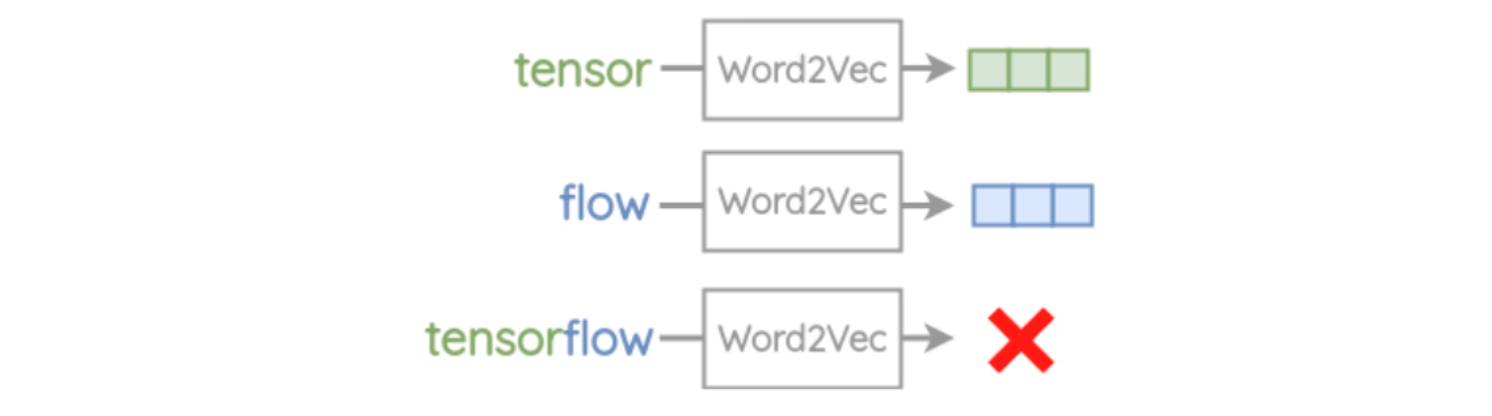
1.不能处理训练中未出现的词(Out of Vocabulary, OOV)
例如: tensor,flow已在Word2Vec的词典出现过,但tensorflow未出现过->OOV error
2.无法处理形态相同的词(morphology),即词根相同的词
对于具有相同词根(eat)的词,eaten,eating,eats,他们之间较难同时出现,不能实现参数共享,即语义类似。因为实际中把他们都当作独一无二的词进行训练

FastText 词嵌入模型
FastText 模型中也引入了n-gram,n-gram的引入其实是为了解决word2vec忽略词型的问题。比如单词其实就是一个单词的不同时态,但是,在不同语境下,其词向量可能会相差特别大,而引入n-gram就是为了能够很好的解决词的形态学方面的问题。
例如一个单词,如果使用n-gram,当时,可以将其分为四个部分,在使用n-gram时一般会用一个尖括号将单词括起来,表示这个单词的开始和结束,如变为,相应的n-gram也就分为 六个部分,其中每个部分又称为子词。
引入了n-gram后,接下来需要做的就是将n-gram后的部分输入模型,这里因为是根据word2vec改进的,所以依旧使用的是模型,而这里输入的时候,因为我们有子词以及词,就又会有不同的选择了。
词
子词
词+子词
对于word2vec而言,其训练的有中心词以及周围词矩阵,设为中心词矩阵,为周围词矩阵,那么搭配就有很多种,这里FastText选择的是,即对中心词使用子词+词的输入来预测周围词。
其实就是:
- step1:给定一个词,在词的首尾加上
<>表示开始与结束

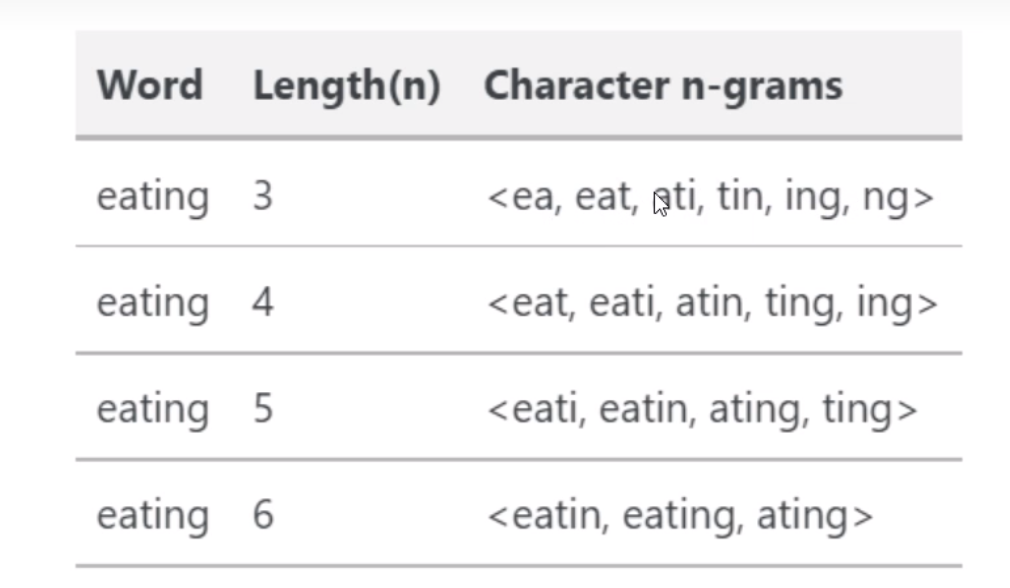
- step2:设定n-gram的滑动窗口大小h=3(可以为其它大小),对该词进行滑动

- step3: 得到该单词一系列n-grams

- step4:当n=3,4,5,6时所得到的n-grams列表
案例理解FastText
以一个案例来理解训练过程,假设有这样一句话: eating是中心词,am与food是周围词,给定中心词预测周围词

- step1: 获取中心词的embedding:将中心词与其产生的sub-words向量相加(其它合并方式会不会好一点?)获得中心词的向量

- step2:step2获取实际周围词的嵌入(没有做sub-words生成)向量, 与。

- step3:获取negative samples词:随机采样,对于一个中心词,采样5个nagatie samples,比如这里其中两个词为pairs,earth,即,

- step4:根据loss更新参数:,与做内积运算并sigmoid,使得NEG词与center词距离越来越远,POS与center距离越来越近。

FastText的实现
实现FastText的过程与word2vec相差不大,唯一的差距就是word2vec使用的是一个单词来预测上下文,而FastText使用的是word+gram后的结果来进行上下文的预测,由于二者的相似性,这里就不再一步步的给大家进行实现了,如果要训练FastText模型,可以安装fasttext库或者使用gensim.models中的Fasttext模型,gensim中的函数是生词词向量,fasttext中既含有词向量的生成,也含有文本分类,具体使用方法如下。
gensim
训练模型
训练模型直接调用构造函数即可,该构造函数的参数如下:
| 参数 | 描述 | 可选值 |
|---|---|---|
| vector_size | 词向量维度 | 整数 |
| window | 词向量窗口大小 | 整数 |
| epochs | 训练轮次 | 整数 |
| negative | 负采样个数 | 整数 |
| sg | 是否使用skipgram,1是使用,0是用cbow | 0,1 |
| hs | 是否使用层化softmax,1是使用,0是不使用 | 0,1 |
| alpha | 学习率 | 0-1 |
from gensim.models import FastText
from gensim.models.word2vec import LineSentence
model=FastText(LineSentence(open(r'../GloVe/data/test.txt', 'r', encoding='utf8')),
vector_size=150, window=5, min_count=5, epochs=10, min_n=3, max_n=6, word_ngrams=1,workers=4)
常用API
| API | 描述 |
|---|---|
| model.wv[word] | 得到 word 的词向量 |
| "nights" in model.wv.vocab | 判断词是否在词向量中 |
| model.similarity("night", "nights") | 计算两个词的相似度 |
| model.most_similar(word, topn=n) | 查找最相关的两个词 |
| model.similarity("night", "nights") | 计算两个词的相似度 |
保存模型
| API | 描述 |
|---|---|
| model.wv.save_word2vec_format('fasttext.vector', binary=False) | 保存词向量 |
| model.save('fasttext_test.model') | 保存模型 |
| model = FastText.load('fasttext_test.model') | 载入模型 |
fasttext
词向量训练
训练模型
这里我们以前面的预处理的文本做示例,文本处理如下。

训练词向量使用的函数为train_unsupervised,其常用参数如下:
| 参数 | 描述 | 可选参数 | 默认值 |
|---|---|---|---|
| input | 输入的文件 | ||
| lr | 学习率 | 0-1 | 0.1 |
| dim | 学习后词向量维度 | 整数 | 100 |
| ws | 背景词 | 整数 | 5 |
| neg | 负采样个数 | 整数 | 5 |
| epoch | 训练轮次 | 整数 | 5 |
| model | 训练的方式 skipgram,cbow | skipgram | |
| wordNgrams | n-gram的值 | 整数 | 1 |
| loss | 损失函数 | 可选ns, hs, softmax, ova,hs为层化softmax,ova用于多标签分类 | softmax |
常用API
| API | 描述 |
|---|---|
| model.get_word_vector(word) | 得到 word 的词向量 |
| model.get_nearest_neighbors(word) | 得到距离 word 最近的10个词向量 |
| model.get_analogies(a,b,c) | 类比,类比 a 和 b 的关系,得到 c 对应该关系的词 |
保存和加载模型
使用model.save_model(filename)以及model.load_model(filename) 即可。
文本分类
训练模型
Fasttext用于分类使用的函数是train_unsupervised,该函数对传入的文本数据有一定的要求,其要求传入的数据标签在前,语句在后,且标签前加上 __label__ 前缀,格式示例如下:
__label__sauce __label__cheese How much does potato starch affect a cheese sauce recipe?
__label__food-safety __label__acidity Dangerous pathogens capable of growing in acidic environments
__label__cast-iron __label__stove How do I cover up the white spots on my cast iron stove?
__label__restaurant Michelin Three Star Restaurant; but if the chef is not there
__label__knife-skills __label__dicing Without knife skills, how can I quickly and accurately dice vegetables?
__label__storage-method __label__equipment __label__bread What's the purpose of a bread box?
__label__baking __label__food-safety __label__substitutions __label__peanuts how to seperate peanut oil from roasted peanuts at home?
__label__chocolate American equivalent for British chocolate terms
比如上述的第一行,其标签就为sauce, cheese,句子为 How much does potato starch affect a cheese sauce recipe?,该函数的API如下:
| 参数 | 描述 | 可选参数 | 默认值 |
|---|---|---|---|
| input | 输入的文件 | ||
| lr | 学习率 | 0-1 | 0.1 |
| dim | 学习后词向量维度 | 整数 | 100 |
| ws | 背景词 | 整数 | 5 |
| neg | 负采样个数 | 整数 | 5 |
| epoch | 训练轮次 | 整数 | 5 |
| model | 训练的方式 | skipgram,cbow | skipgram |
| wordNgrams | n-gram的值 | 整数 | 1 |
| loss | 损失函数 | 可选ns, hs, softmax, ova,hs为层化softmax,ova用于多标签分类 | softmax |
| label | 标签的前缀 | 字符串 | label |
常用API
| API | 描述 |
|---|---|
| model.test(file) | 对文件进行测试集的测试,返回三个参数,分别是 样本数,准确率,召回率 |
| model.pridict(sentence,k=-1) | 预测句子所属的类别,返回各个标签及概率,k=-1 表示返回全部标签及其概率 |
保存和加载模型
使用model.save_model(filename)以及model.load_model(filename)即可。
参考文献:
https://blog.csdn.net/ifhuke/article/details/127944112


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列1:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话