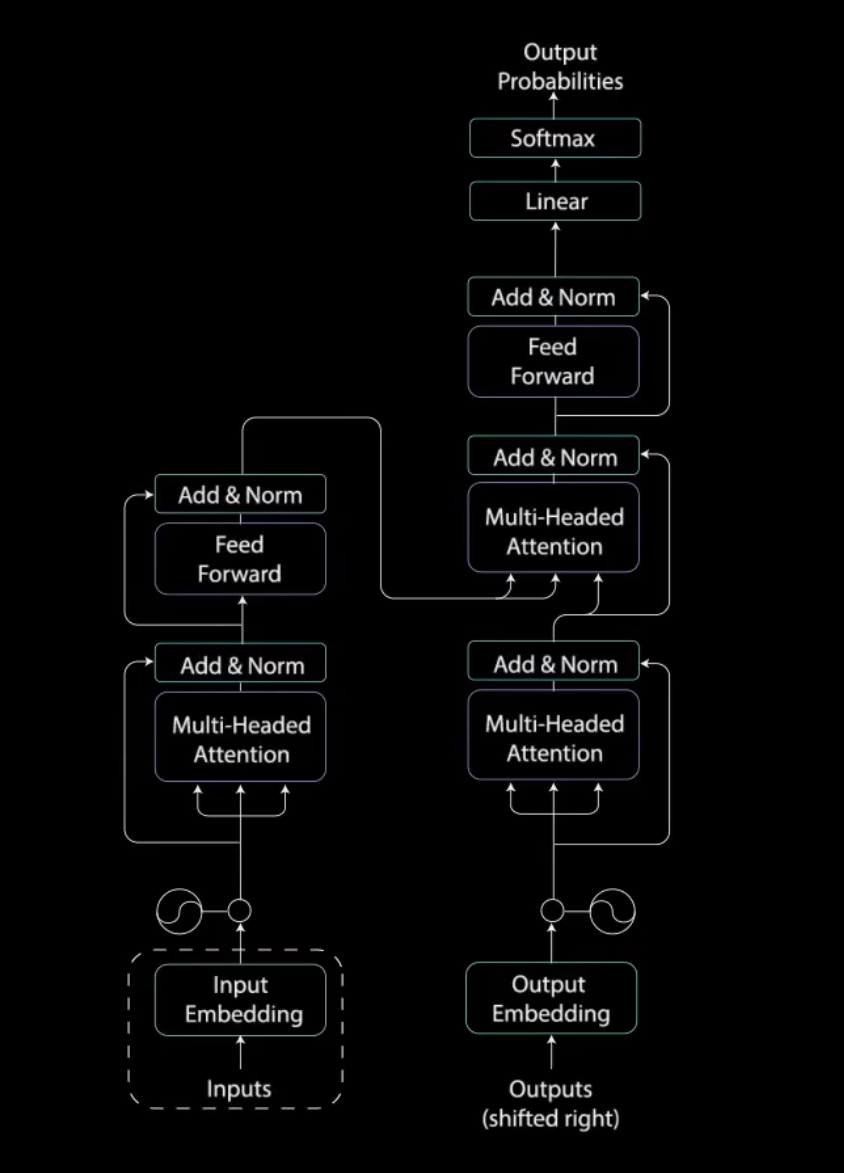
一步一步深入浅出解释Transformer原理
1.Input Embedding
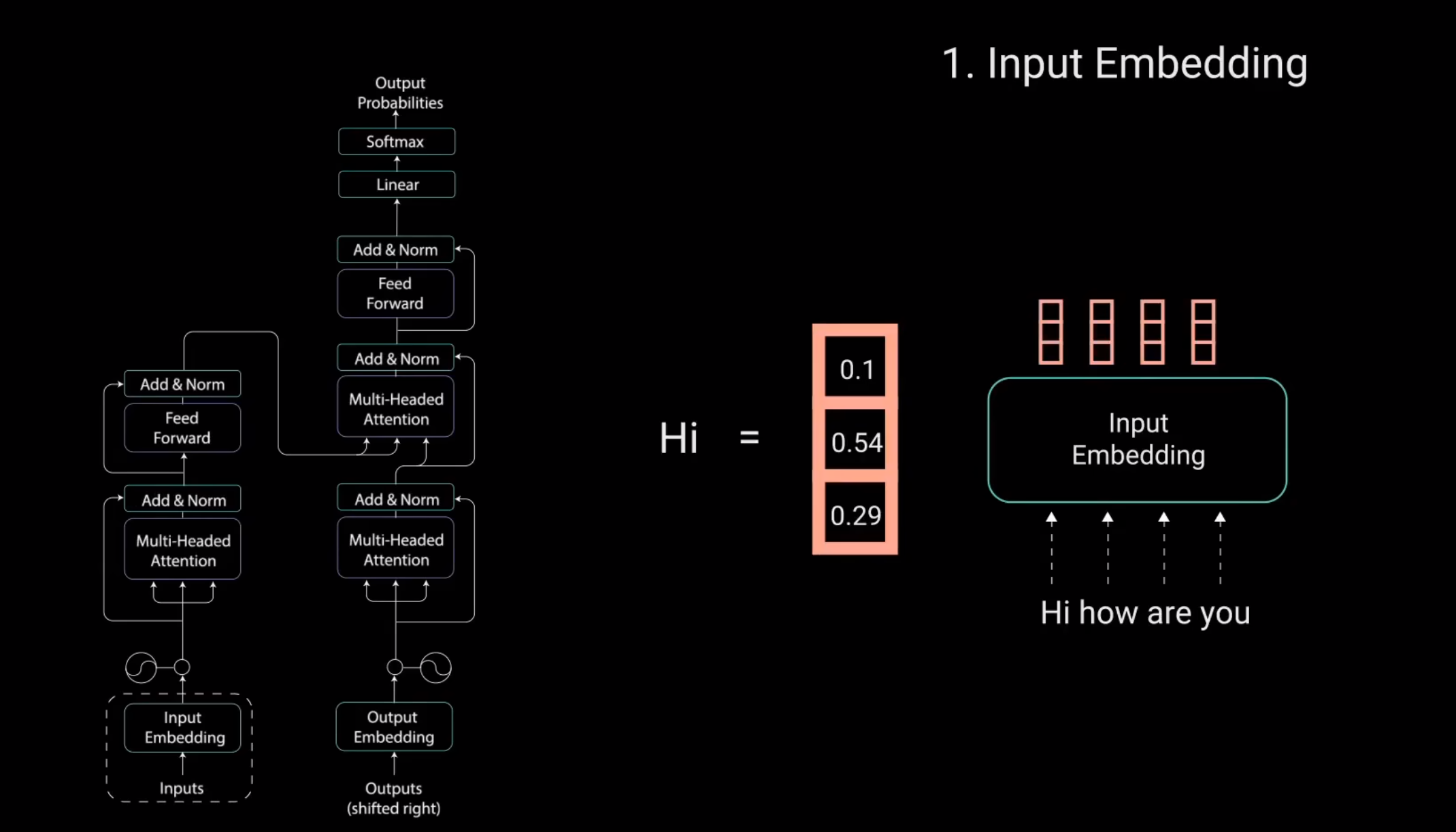
就是将输入的句子给映射成向量。
2.加入位置编码
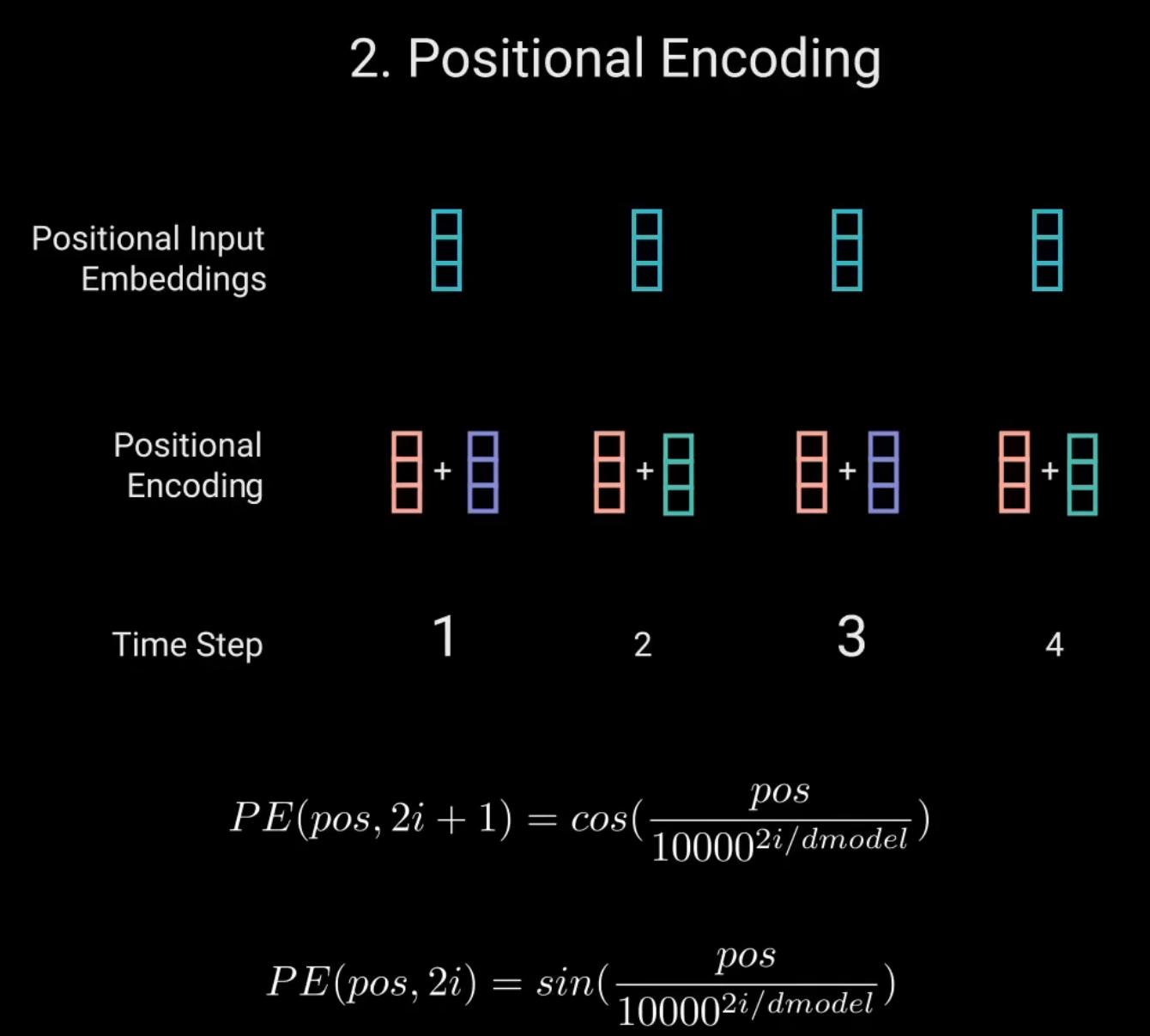
对于每个奇数时间步,使用余弦函数创建一个向量。对于每个偶数时间步,使用正弦函数创建一个向量。然后将这些向量添加到相应的嵌入向量。
因为Transformer没有像RNN一样的递归,所以我们必须将位置信息添加到输入嵌入中。这是通过位置编码来实现的。
3-4 Encoder Layer
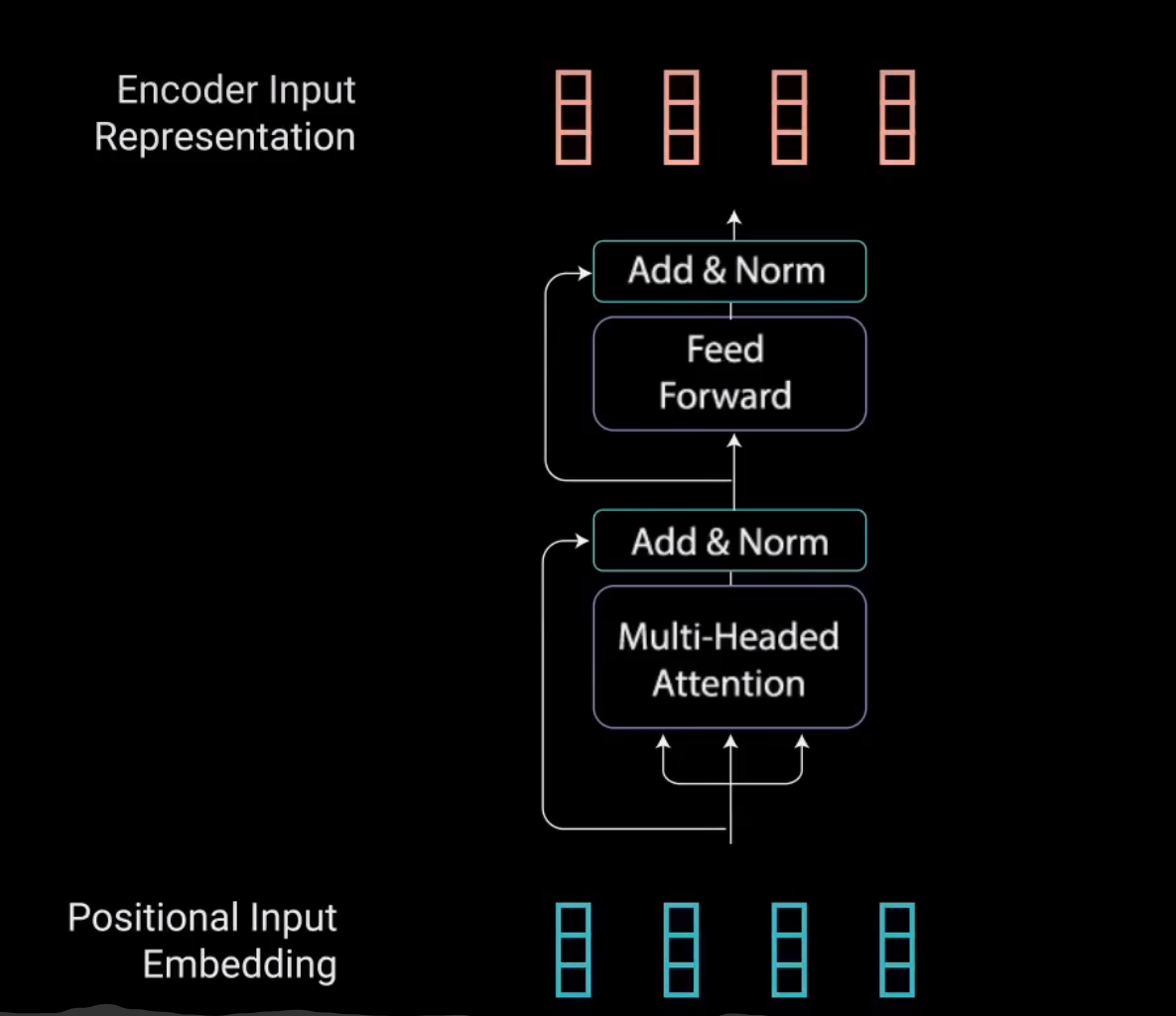
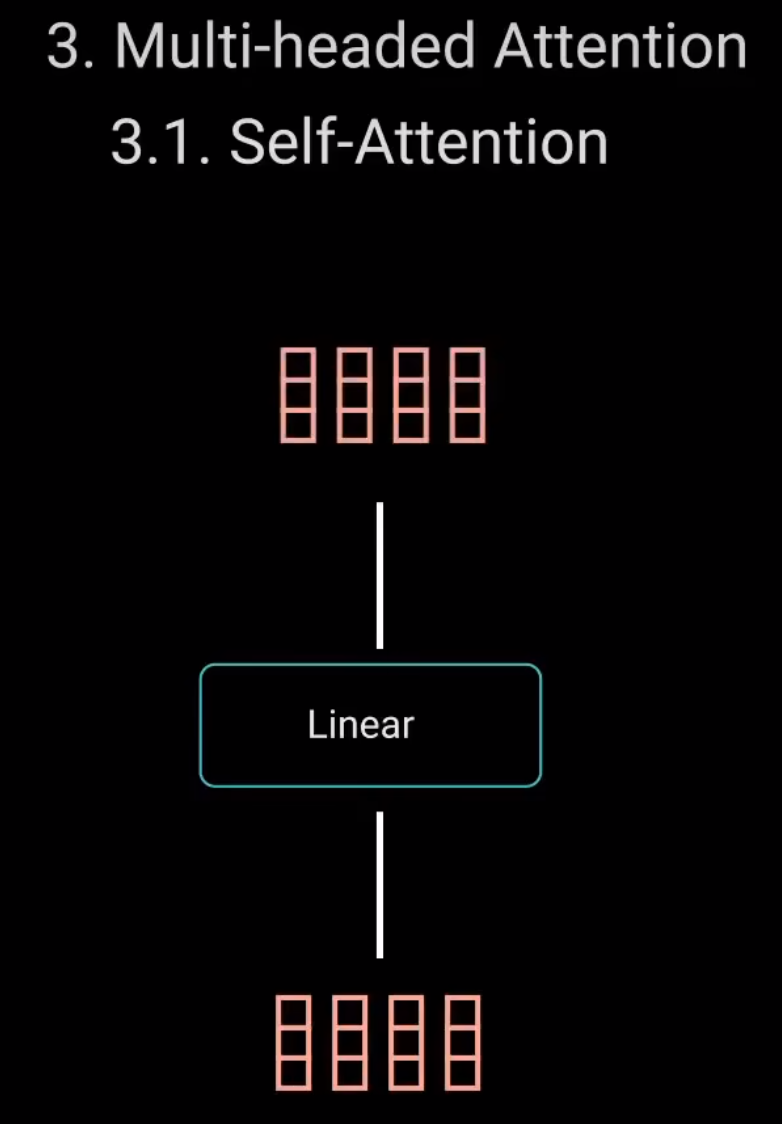
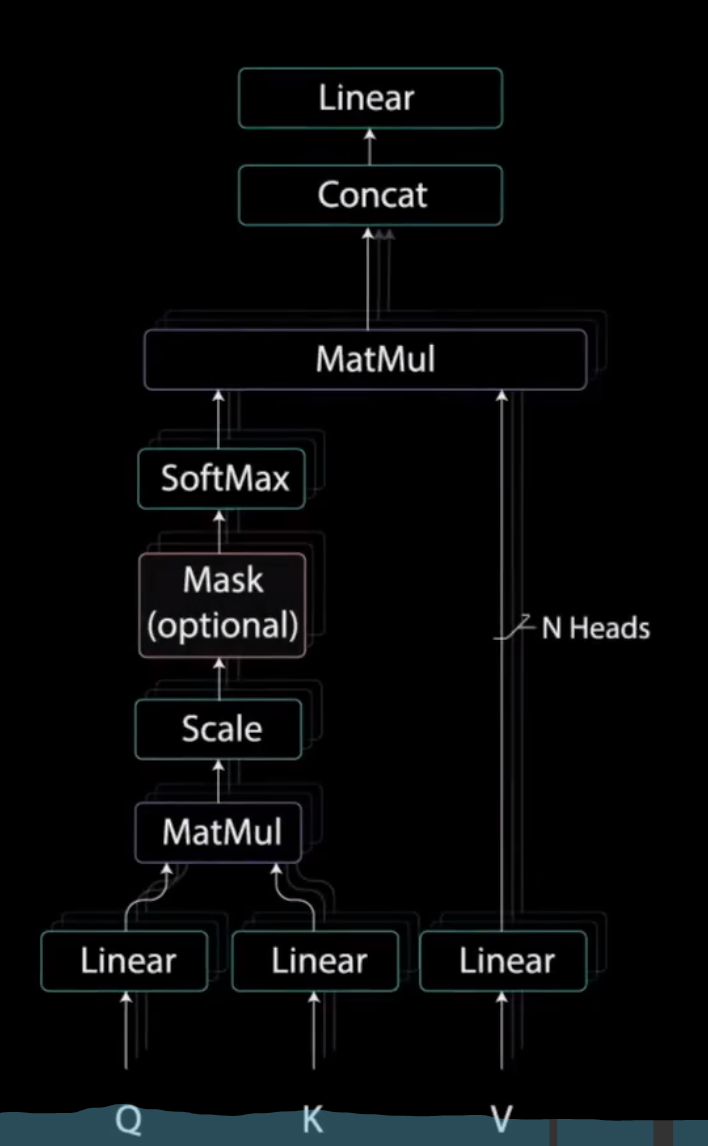
3 Multi-headed Attention
3.1 Self-Attention
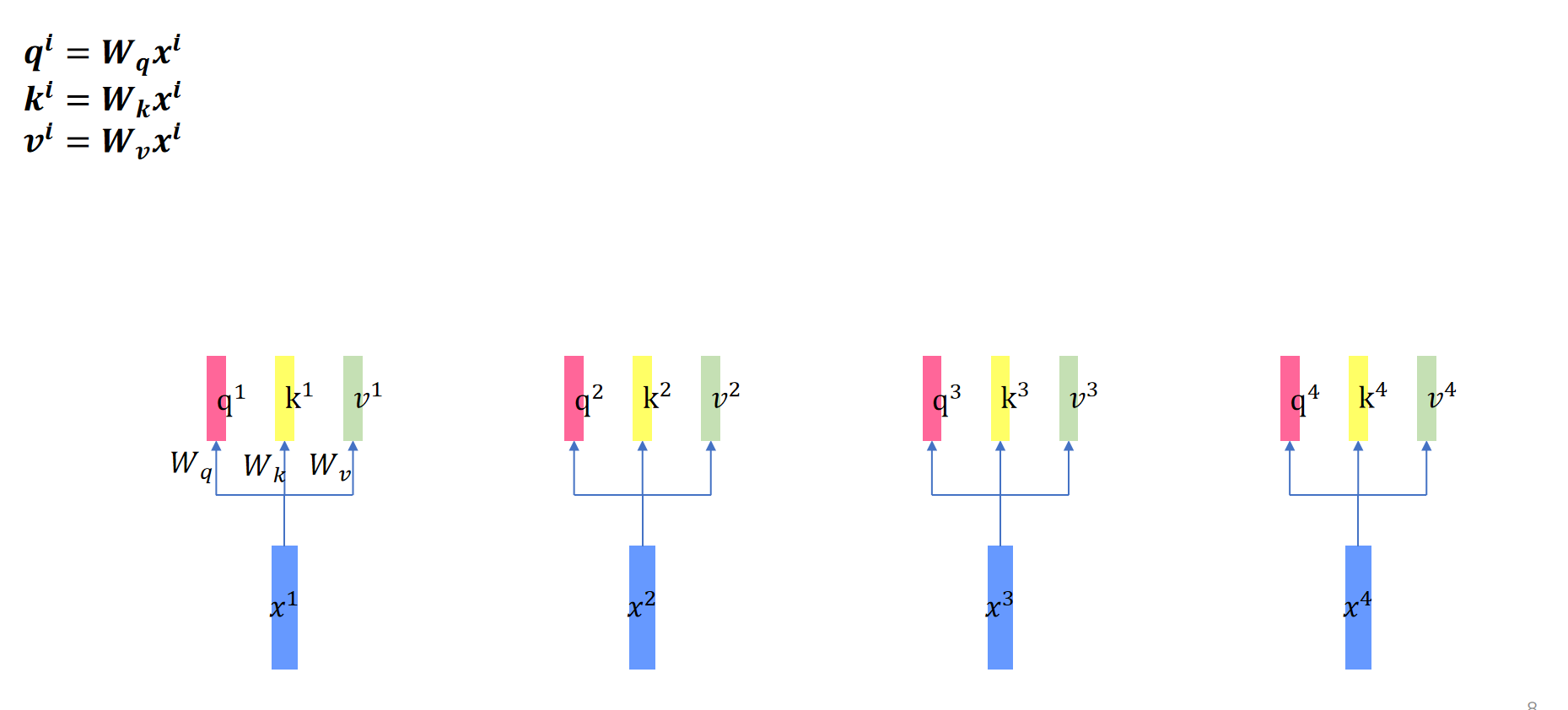
首先我们先将将输入分别送入三个不同的全连接层,以创建查询向量(query)键向量(key)和值向量(value)。这些向量究竟是什么?
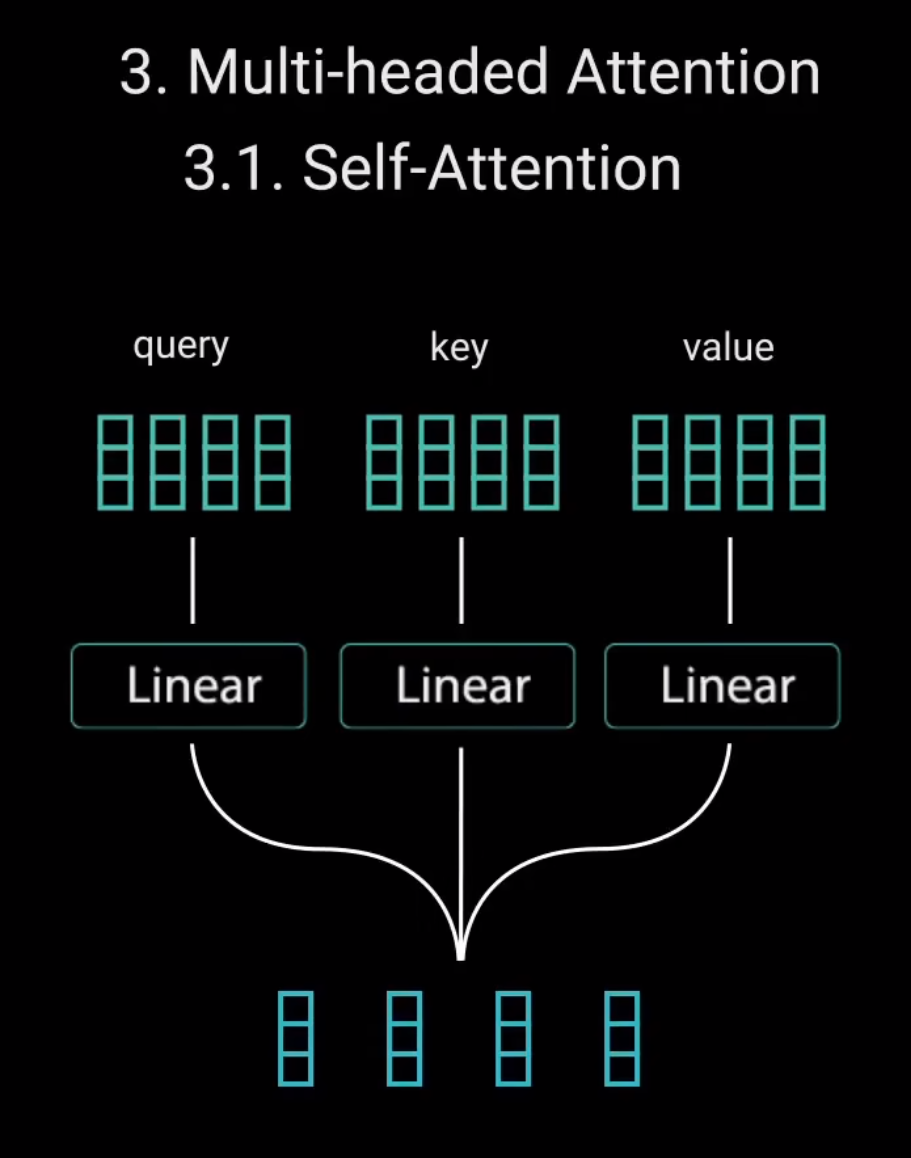
然后查询和键经过点积矩阵乘法产生一个分数矩阵。分数矩阵确定了一个单词应该如何关注其他单词。
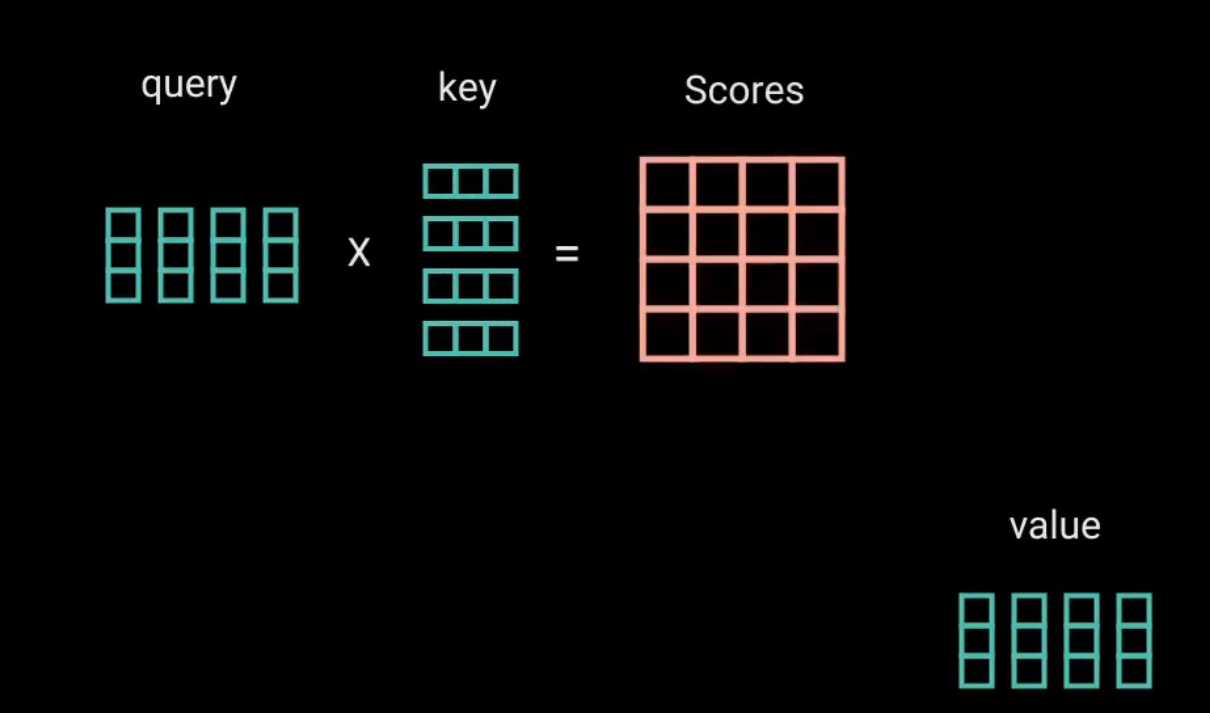
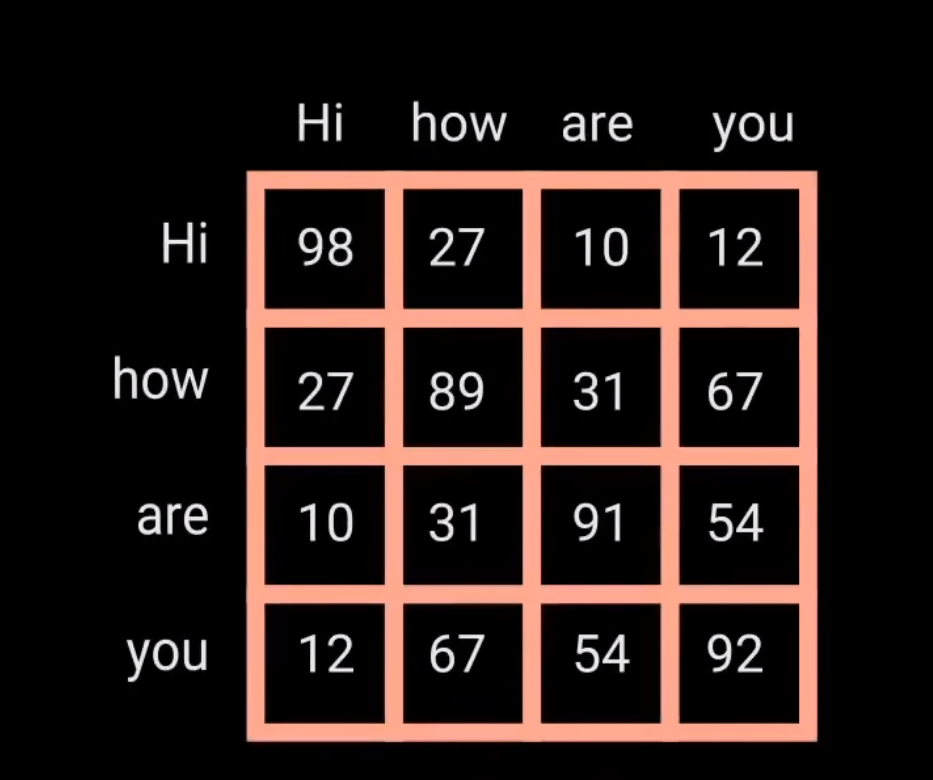
因此,每个单词都会有一个与时间步长中的其他单词相对应的分数。分数越高,关注度越高。这就是查询如何映射到键的
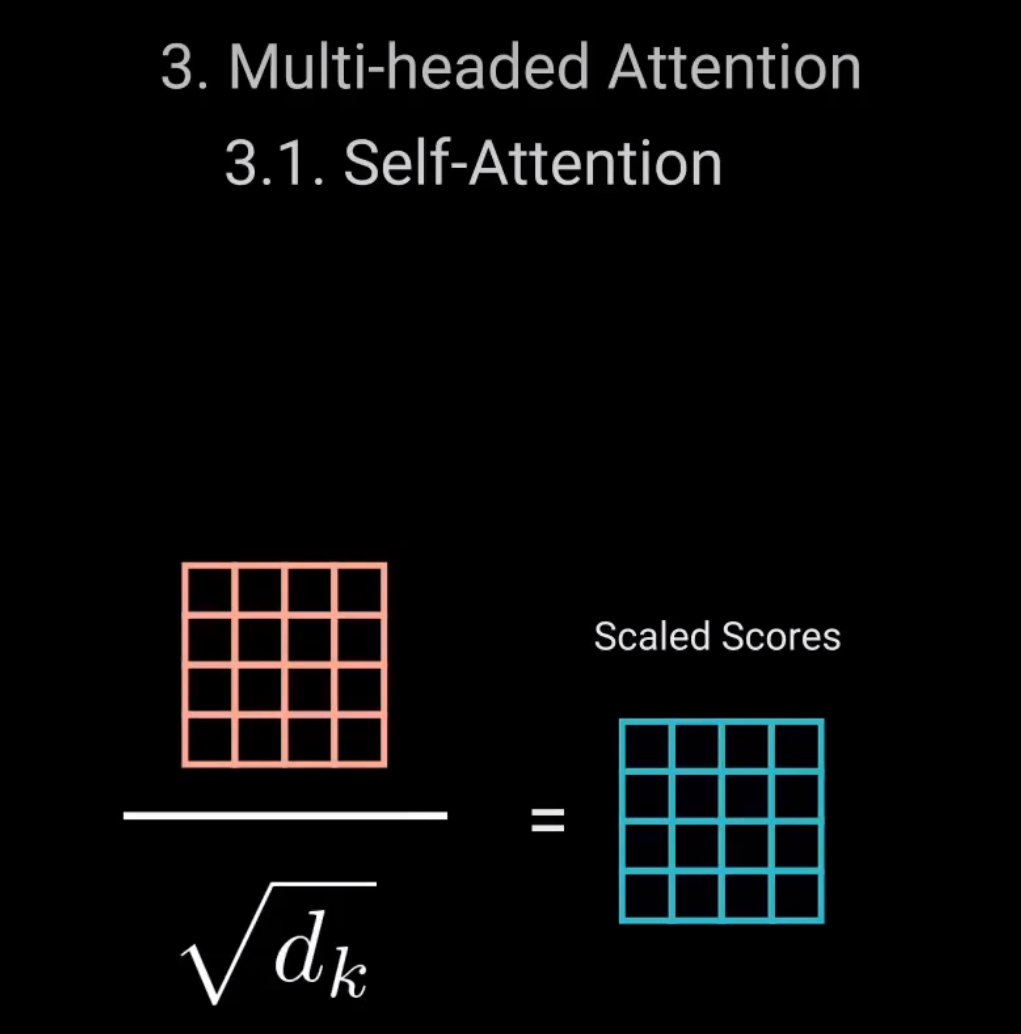
接下来。通过将查询和键的维度开平方来将得分缩放。这样可以让梯度更稳定,因为乘法可能会产生爆炸效果。
之后,对缩放后的得分进行softmax计算,得到注意力权重,从而获得0到1之间的概率值。进行softmax计算后,较高的得分会得到增强,而较低的得分抑制。

这让模型在关注哪个词时更有信心。接着,将注意力权重与值向量相乘,得到输出向量。较高的softmax得分会保留模型认为更重要的词的值。

之后,将输出向量输入线性层进行处理。
3 Multi-headed Attention
为了使这个计算成为多头注意力计算,需要在应用自注意力之前将查询、键和值分成n个向量。分割后的向量然后分别经过相同的自注意力过程。每个自注意力过程称为一个头。每个头都会产生一个输出向量,这些向量在经过最后的线性层之前被拼接成一个向量
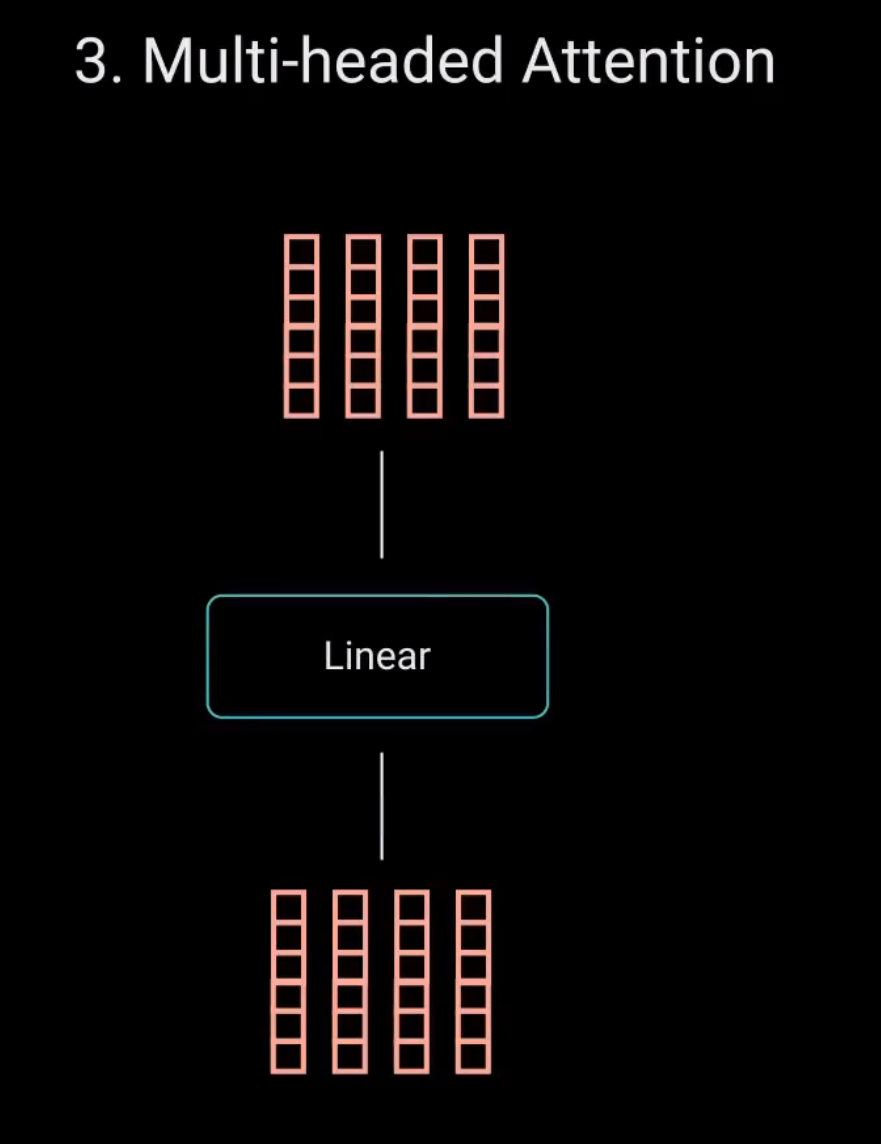
理论上,每个头都会学到不同的东西。从而为编码器模型提供更多的表达能力。这就是多头注意力。总之,多头注意力是一个模块,用于计算输入的注意力权重。并生成一个带有编码信息的输出向量,指示序列中的每个词如何关注其他所有词。
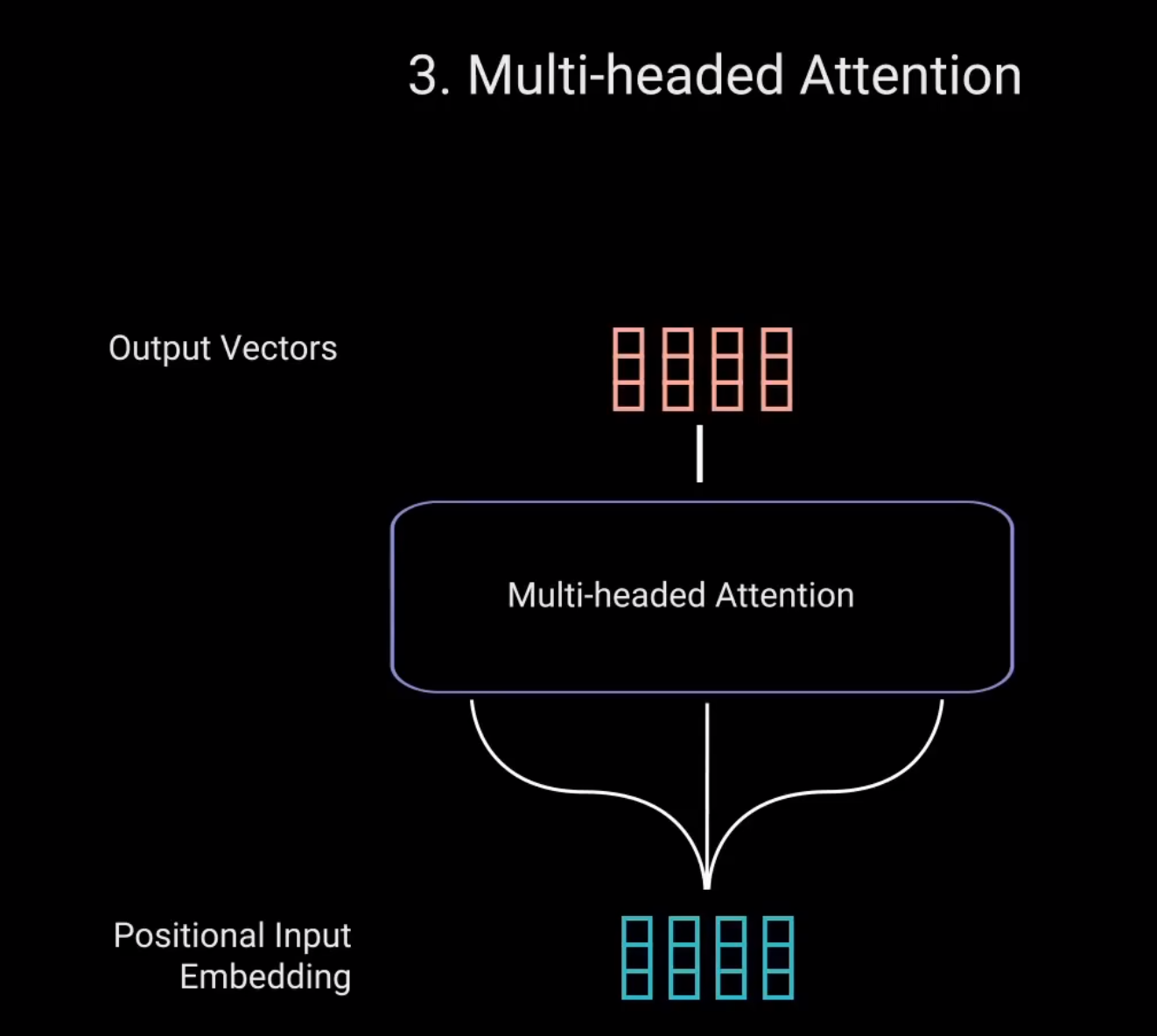
4.Residual Connection,Layer Normalization & Pointwise Feed Forward
接下来,将多头注意力输出向量加到原始输入上。这叫做残差连接。残差连接的输出经过层归一化。
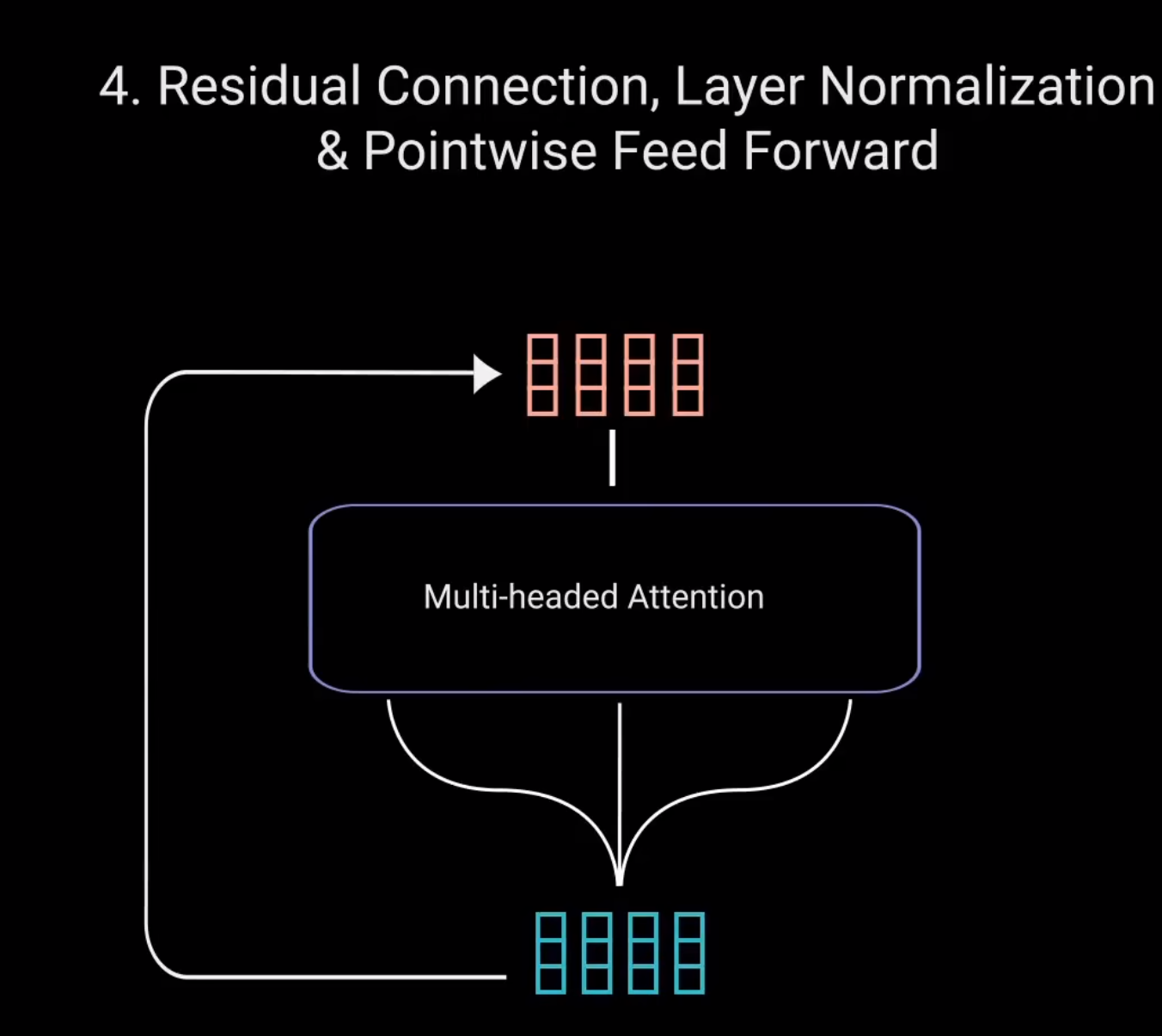
归一化后的残差输出被送入点对点前馈网络进行进一步处理。点对点前馈网络是几个线性层。中间有ReLU激活函数。
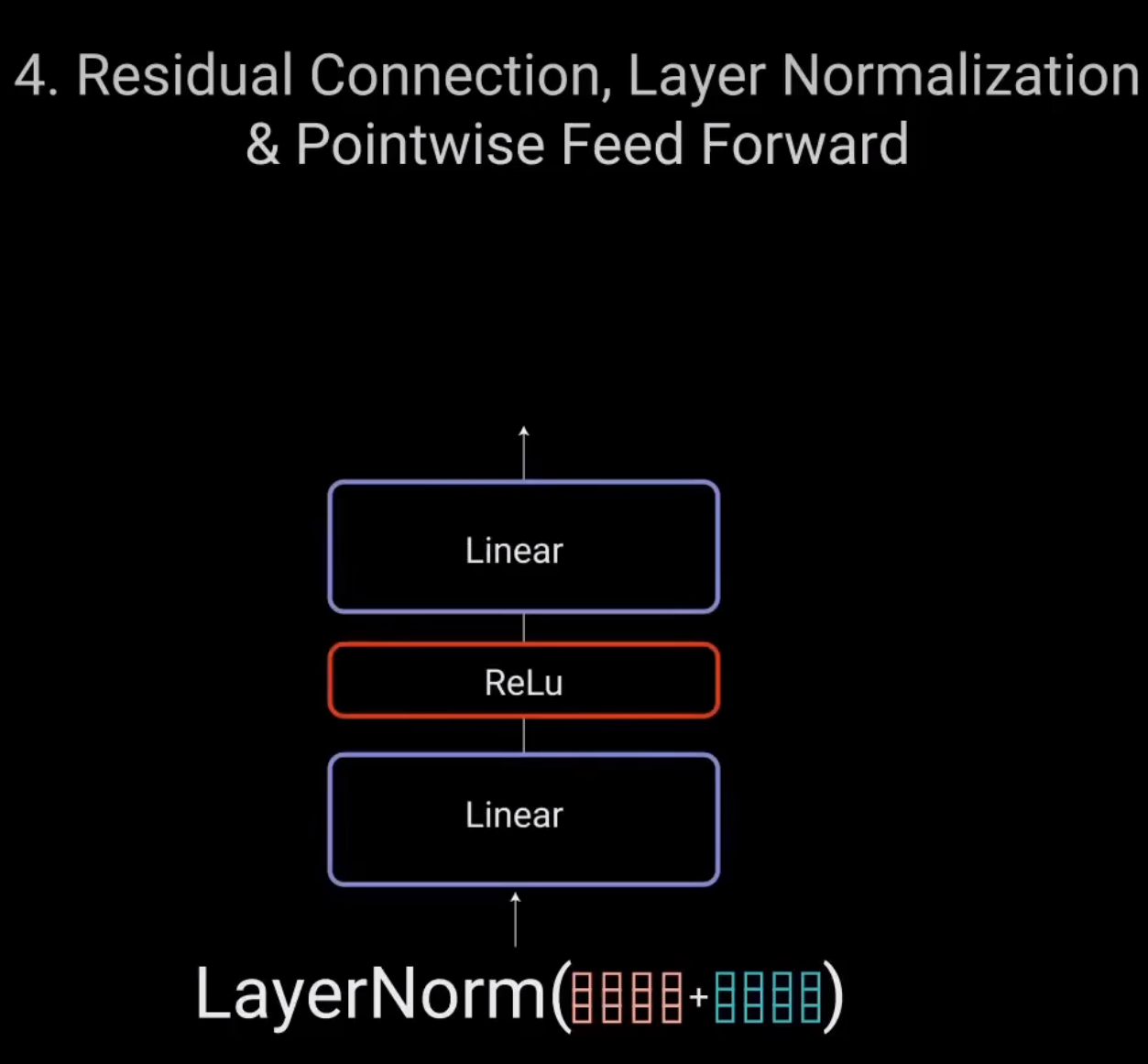
再次将该输出与点对点前馈网络的输入相加并进一步归一化。残差连接有助于网络训练,因为它允许梯度直接流过网络。
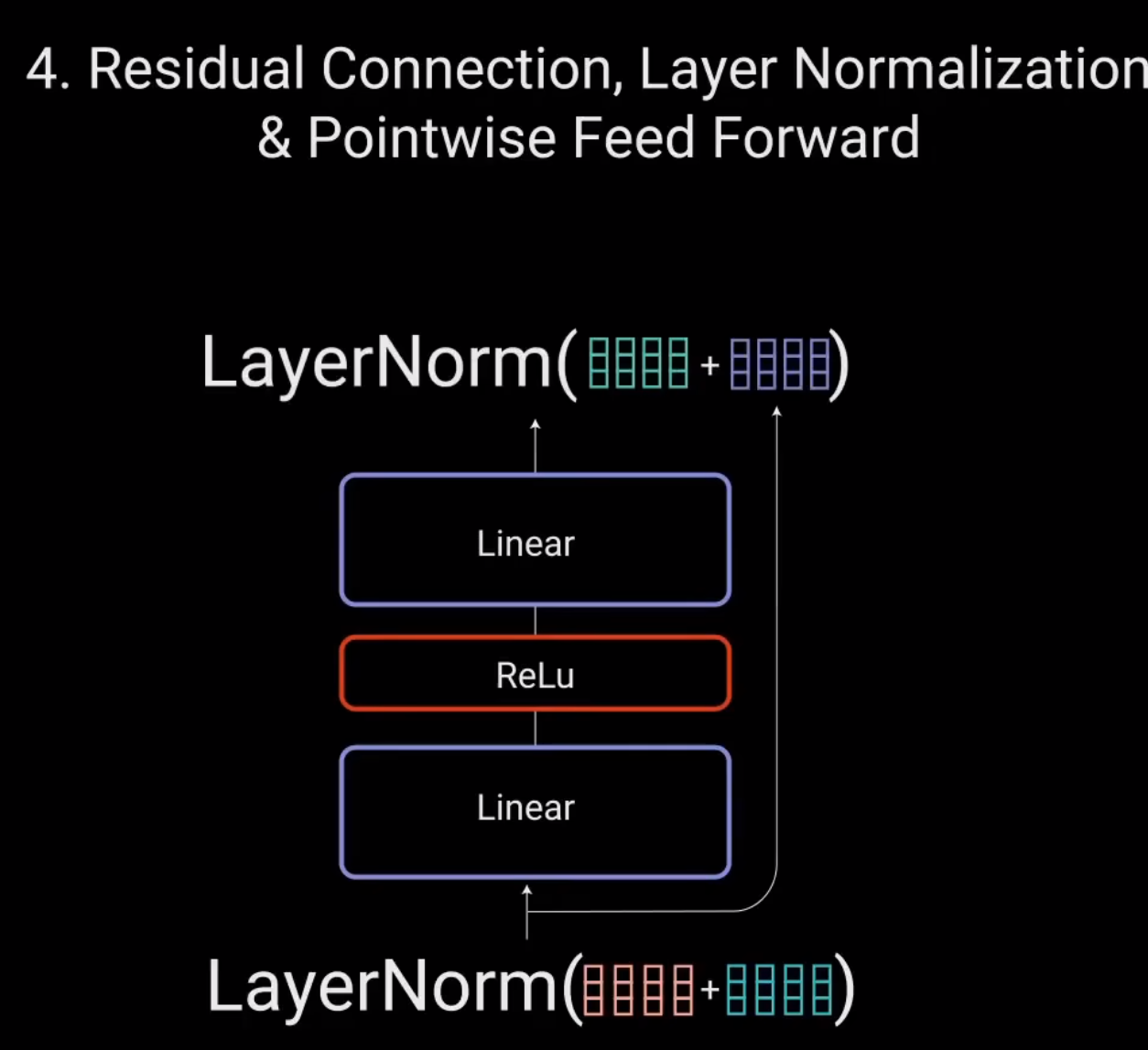
使用层归一化来稳定网络、从而显著减少所需的训练时间。点对点前馈层用于进一步处理注意力输出,可能使其具有更丰富的表达。
这就总结了编码层。所有这些操作都是为了将输入编码为连续表示,带有注意力信息。这将帮助解码器在解码过程中关注输入中的适当词汇。
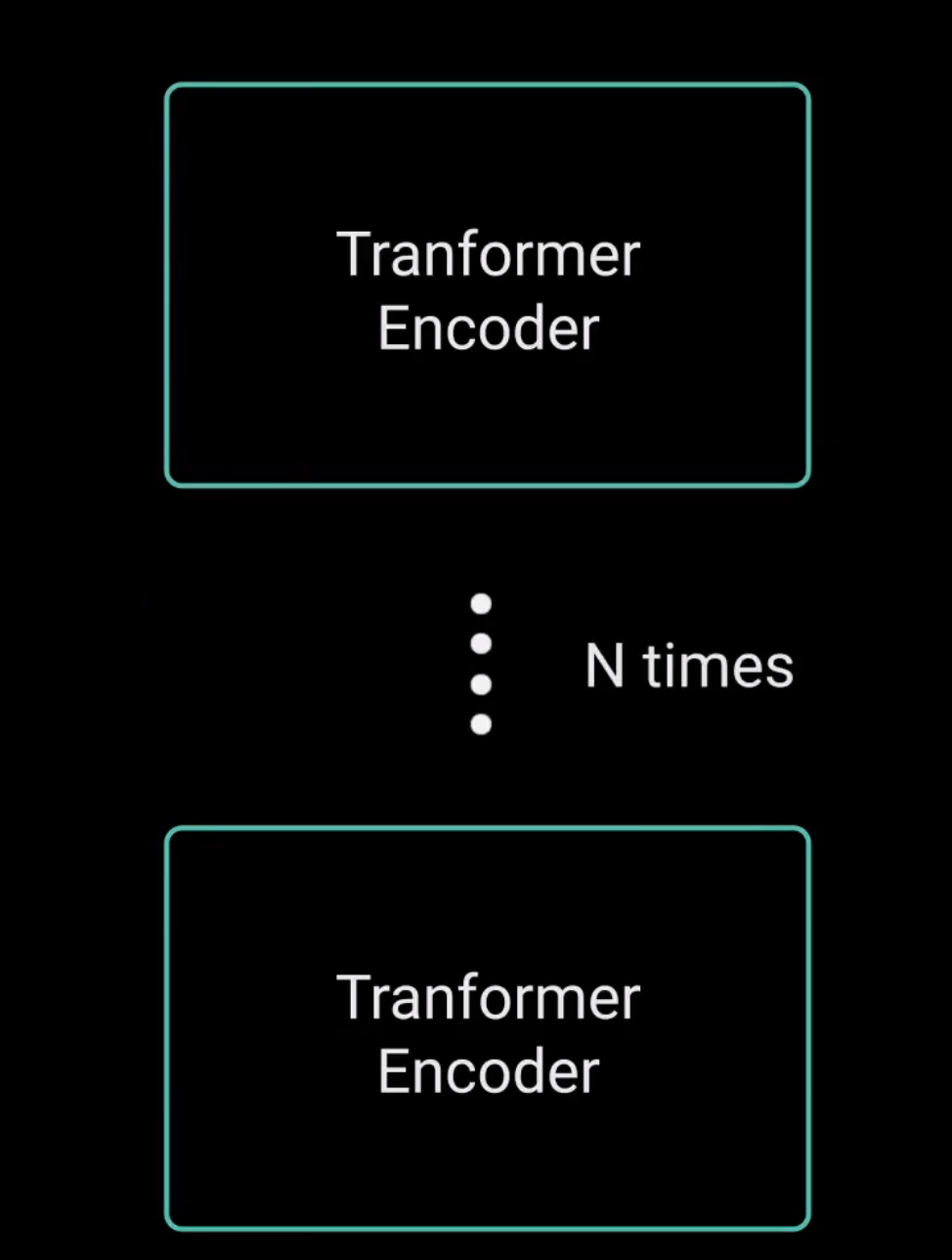
可以将编码器堆叠n次以进一步编码信息,其中每一层都有机会学习不同的注意力表示,从而有可能提高ITransformer网络的预测能力。
解码器
现在我们转向解码器的任务是生成文本序列。解码器具有与编码器相似的子层。
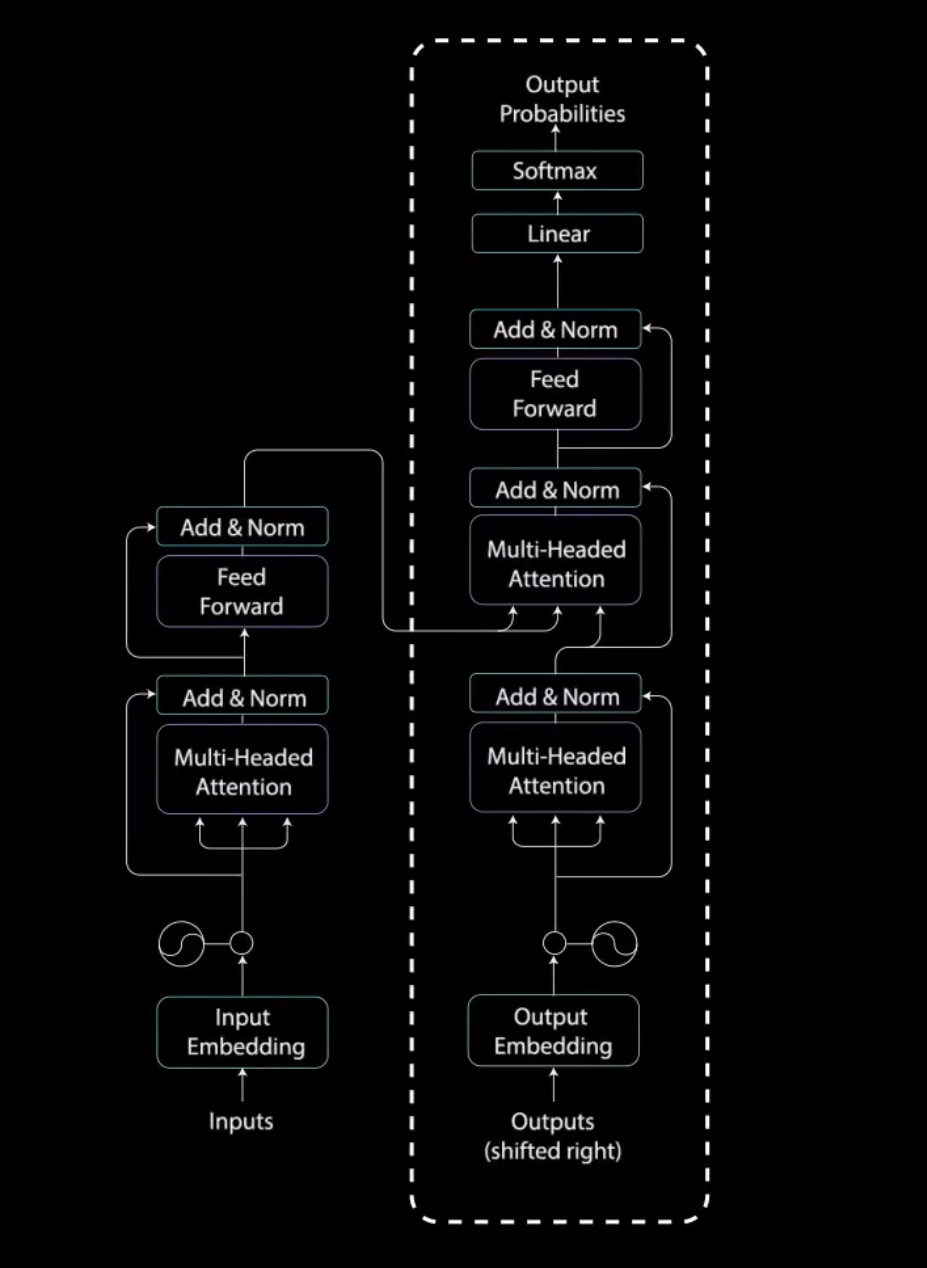
它有两个多头注意力层、一个点对点前馈层,以及在每个子层之后的残差连接和层归一化。这些子层的行为类似于编码器中的层,但每个多头注意力层的任务不同。最后,它由一个类似于分类器的线性层和一个softmax来得到单词概率。解码器是自回归的。他将先前输出的列表作为输入。以及包含来自输入的注意力信息的编码器输出。当解码器生成一个结束标记作为输出时,解码停止。
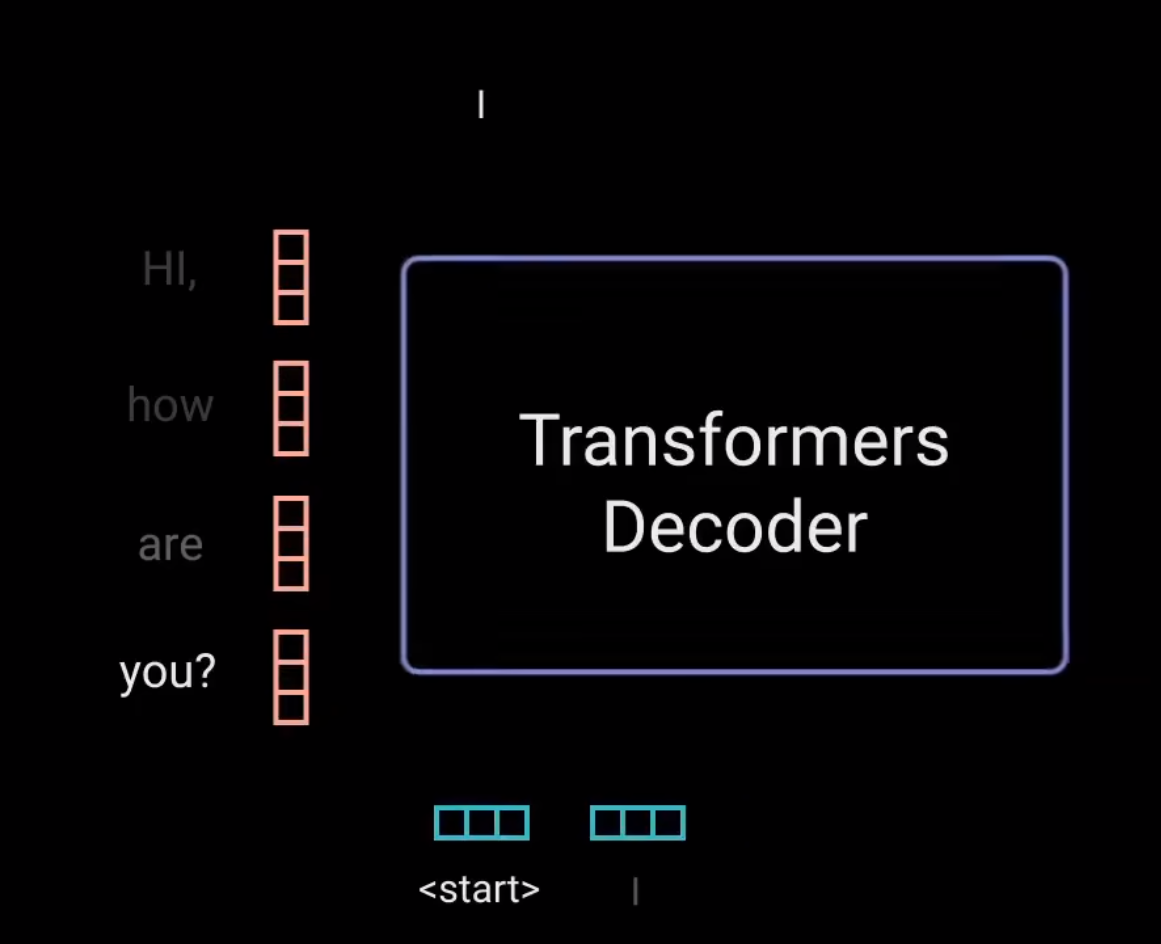
第一个预测的结果"I",会被添加成为下一次的输出。
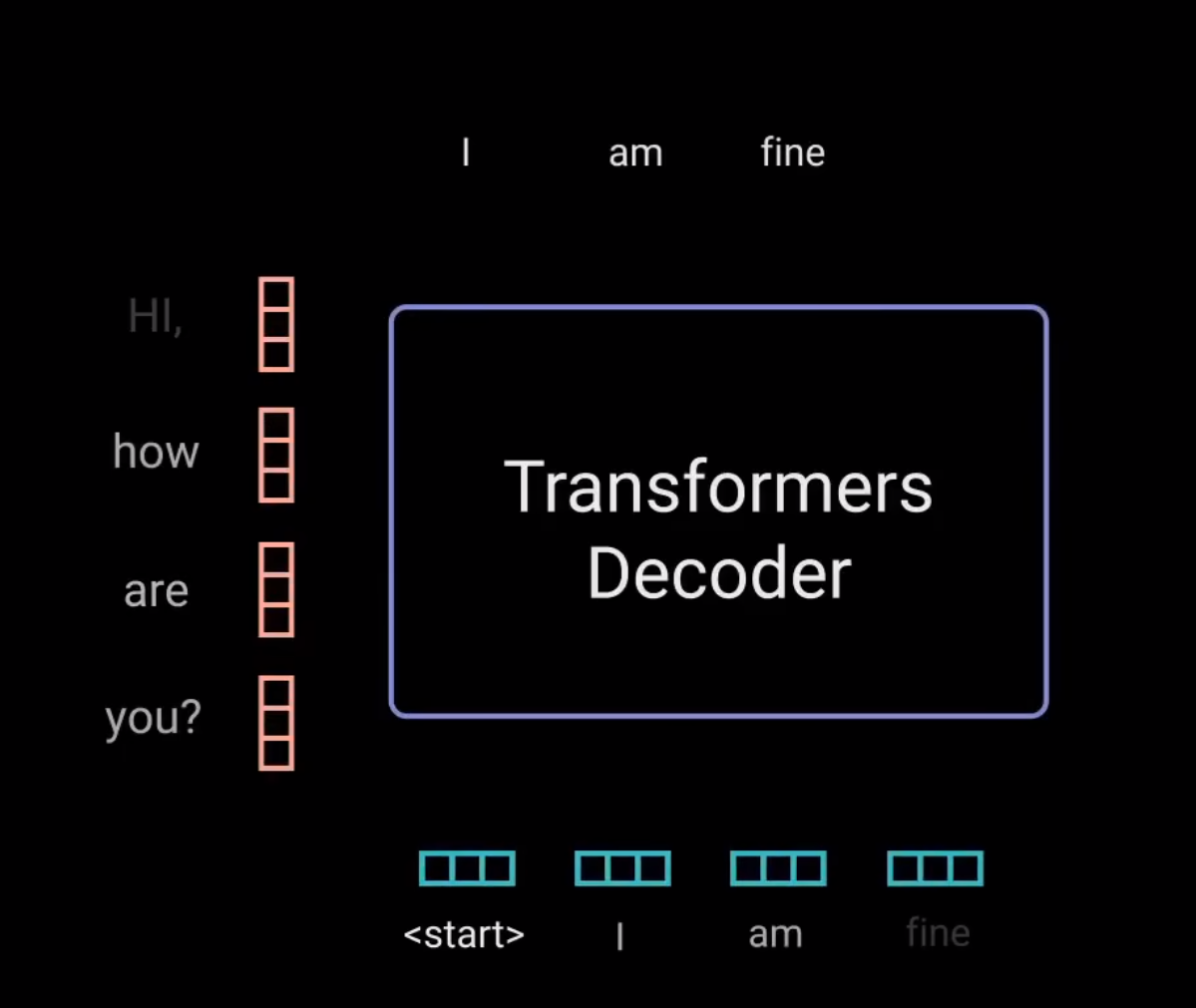
让我们来看看解码过程:
5.Output Embedding & Positional Encoding
输入通过嵌入层和位置编码层,得到位置嵌入。
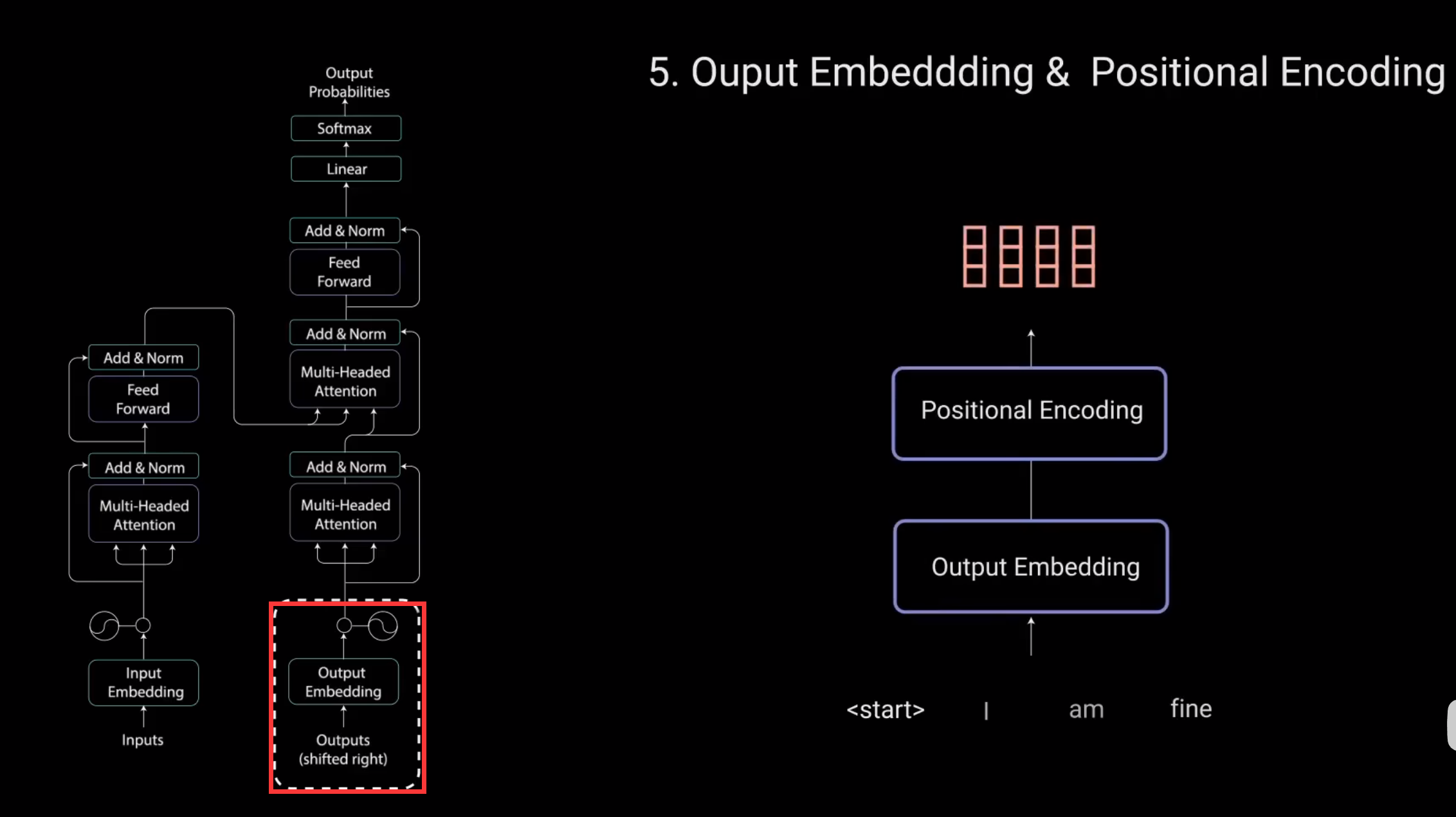
位置嵌入被送入第一个多头注意力层。计算解码器输入的注意力得分。
这个多头注意力层的工作方式稍有不同。因为解码器是自回归的,并且逐词生成序列,你需要防止它对未来的标记进行条件处理。对于自回归就是,解码器是一个一个预测的,解码器预测完一个会被最为下一层预测的输入。
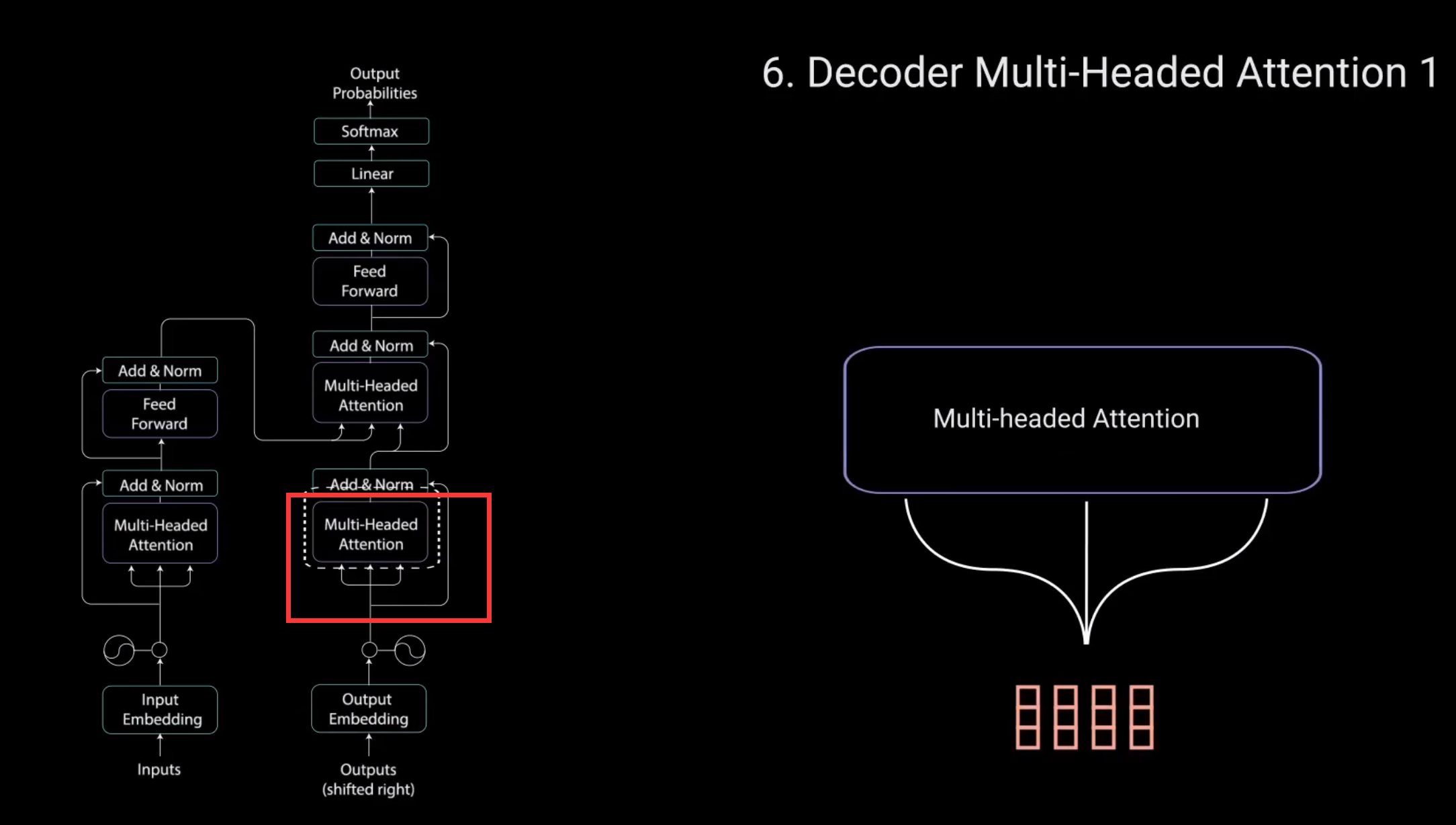
例如.在计算单词"am"的注意力得分时,不应该访问单词"fine"因为那个词是在之后生成的未来词。
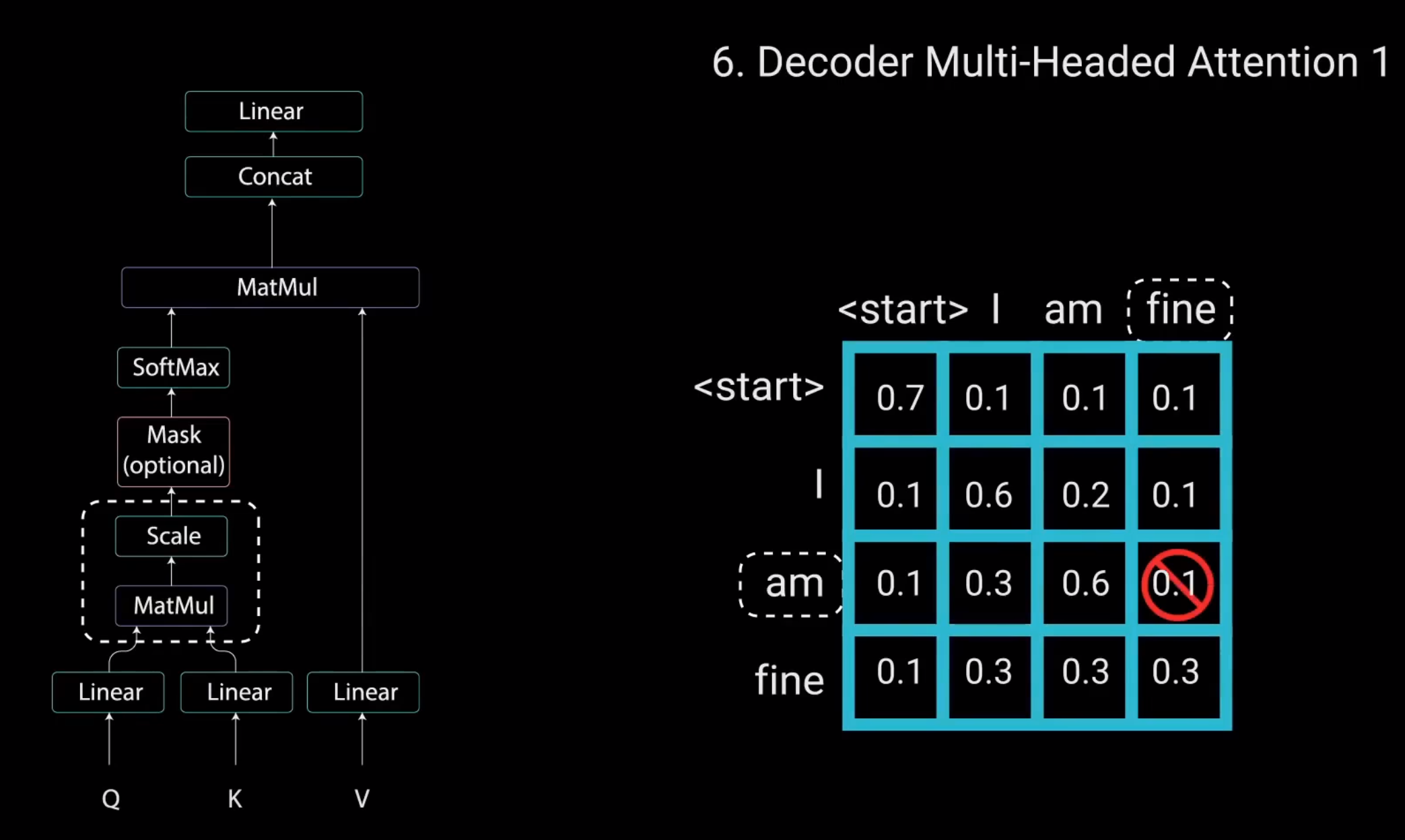
所以单词"am"应该只访问它自己和它之前的单词。对于所有其他单词,它们只能关注之前的单词。我们需要一种方法来防止计算未来单词的注意力得分。这种方法称为Mask。
Look-Ahead Mask
为了防止解码器查看未来的标记,您需要应用一个前瞻性Mask。在计算softmax和缩放得分之后.Mask被添加。让我们看看这是如何工作的。
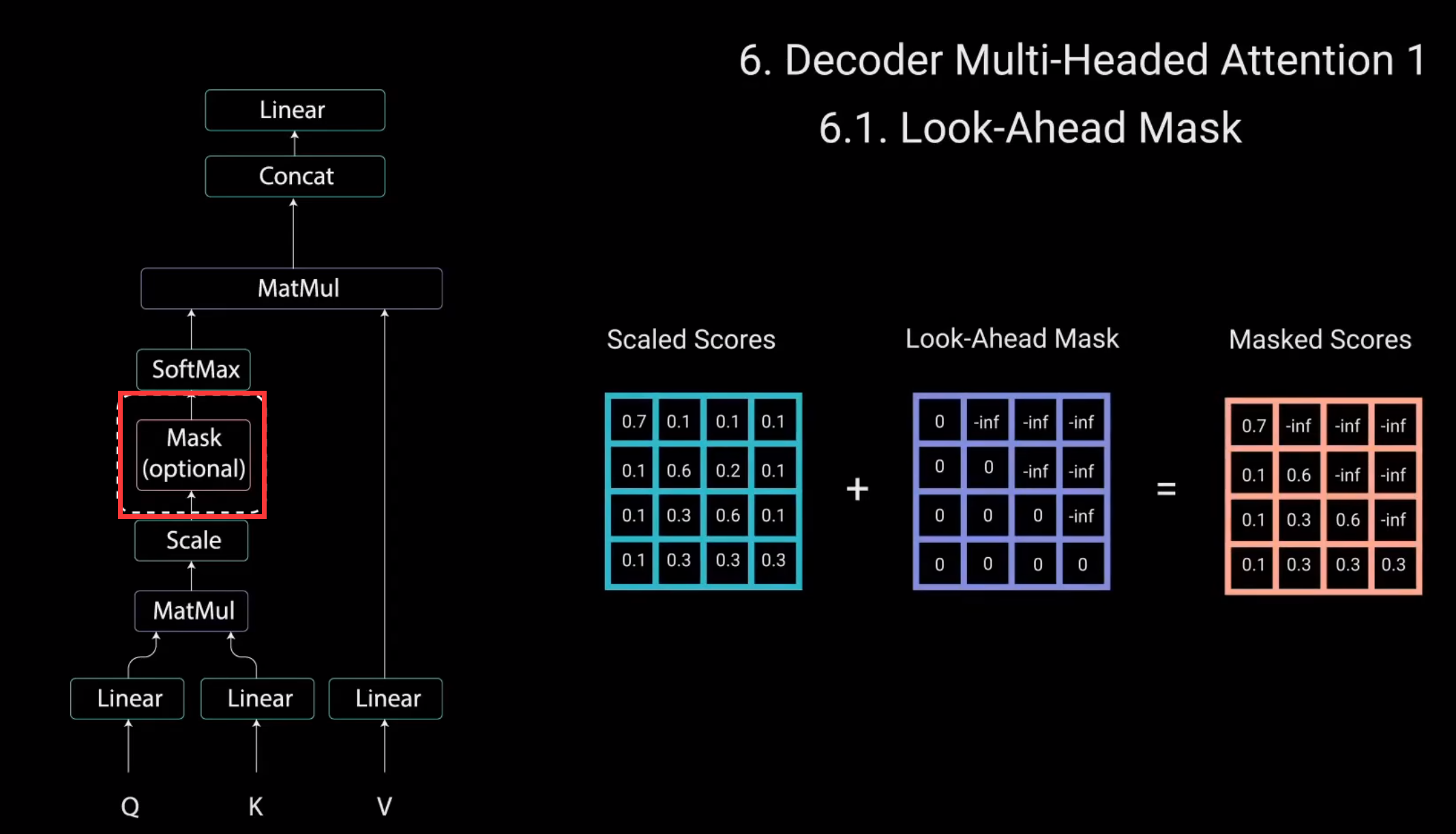
Mask是一个与注意力得分大小相同的矩阵,填充零和负无穷大的值。将Mask添加到缩放后的注意力得分后。会得到一个带有右上角三角形负无穷大值的得分。
这样做的原因是,一旦对Mask得分进行softmax计算,负无穷大值就会变为零,从而为未来的标记留下零注意力得分。
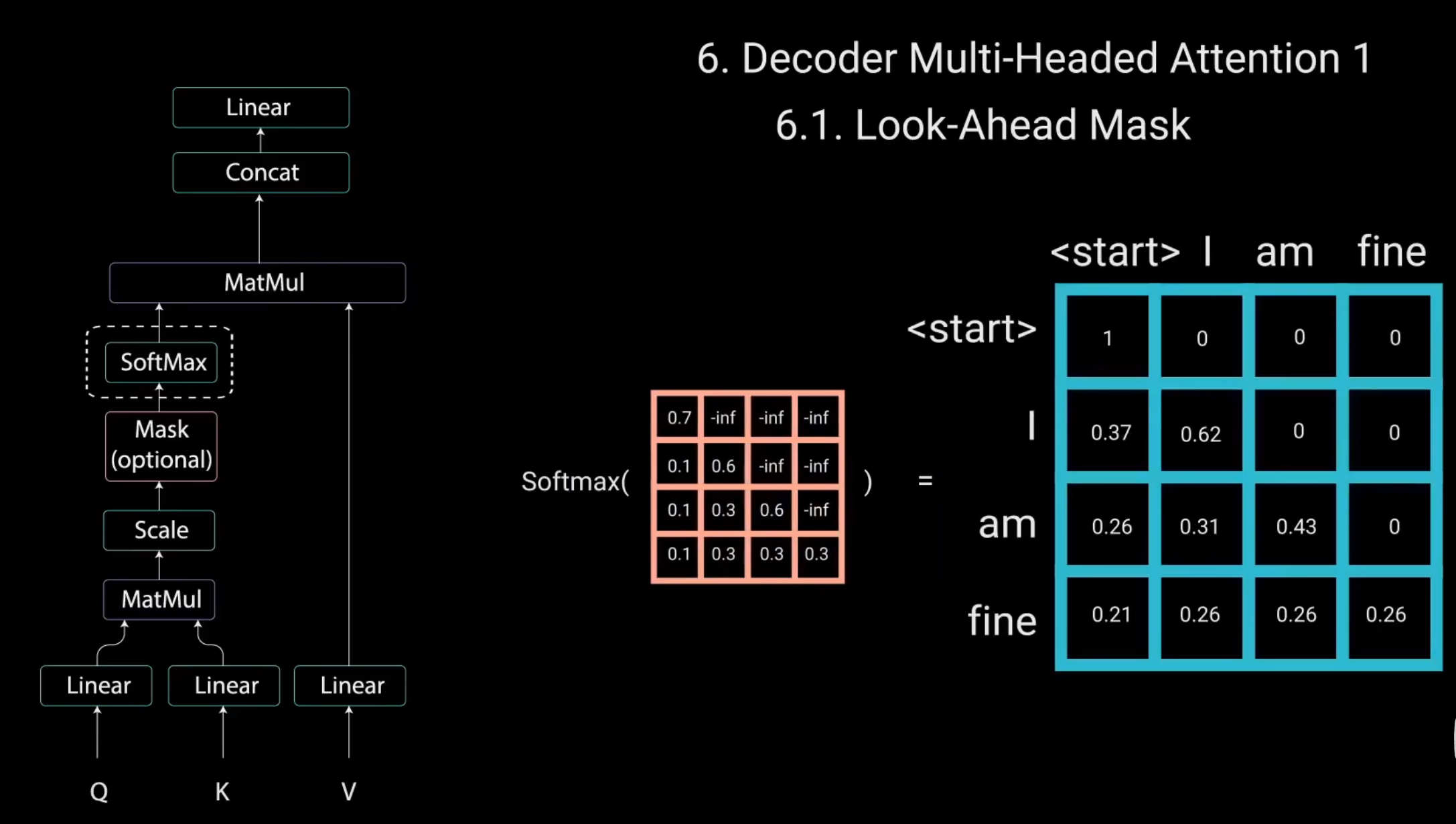
如您所见。单词“am”的注意力得分对于它自己和它之前的所有其他单词有值,但对于单词“find”则为零。这实质上告诉模型不要关注这些单词。Mask是第一个多头注意力层计算注意力得分的唯一不同之处。这一层仍然有多个头。Mask在被拼接并通过线性层进行进一步处理之前被应用到每个头。
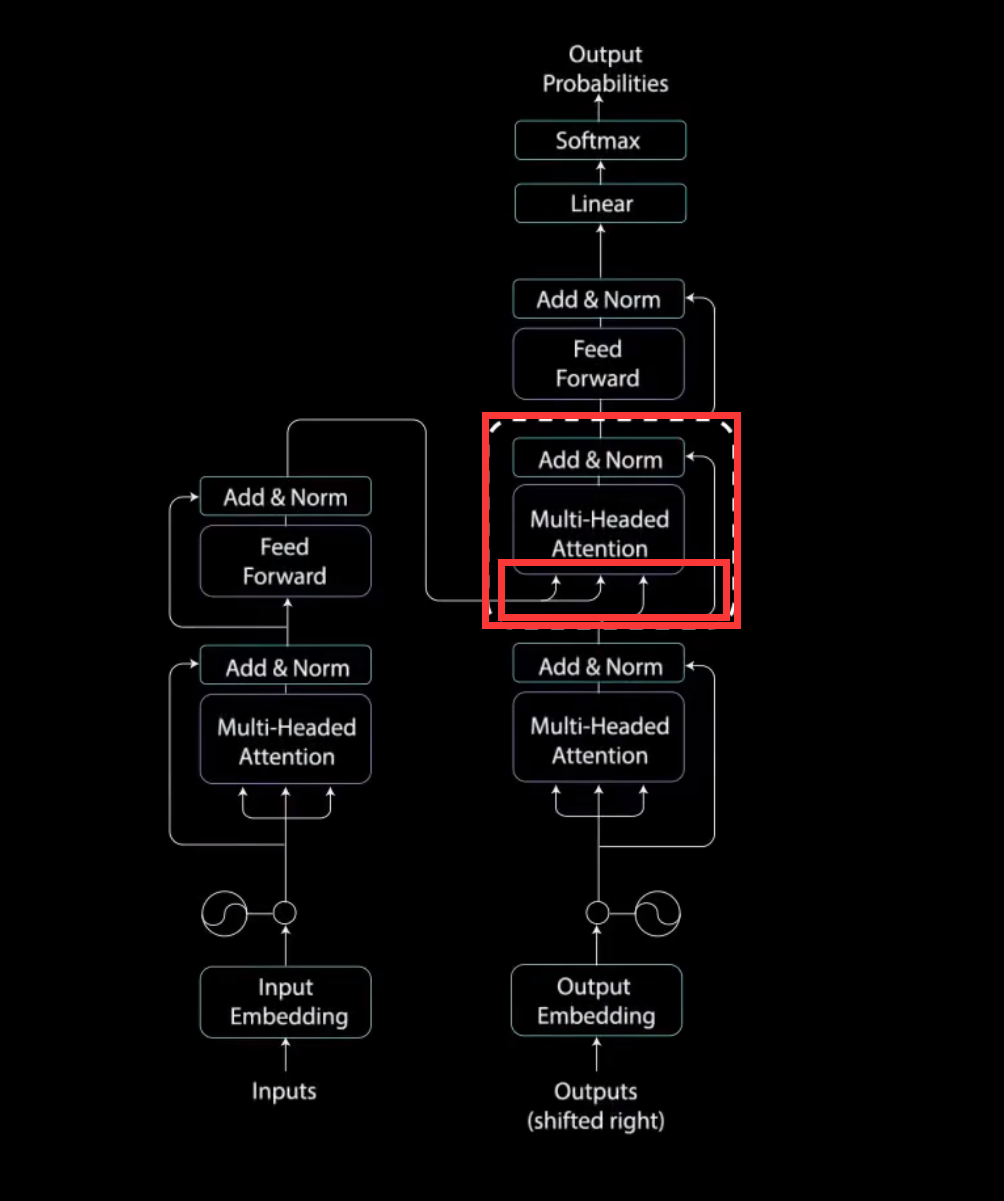
第一个多头注意力层的输出是一个带有掩码的输出向量.其中包含有关模型如何关注解码器输入的信息。现在.我们来看第二个多头注意力层。
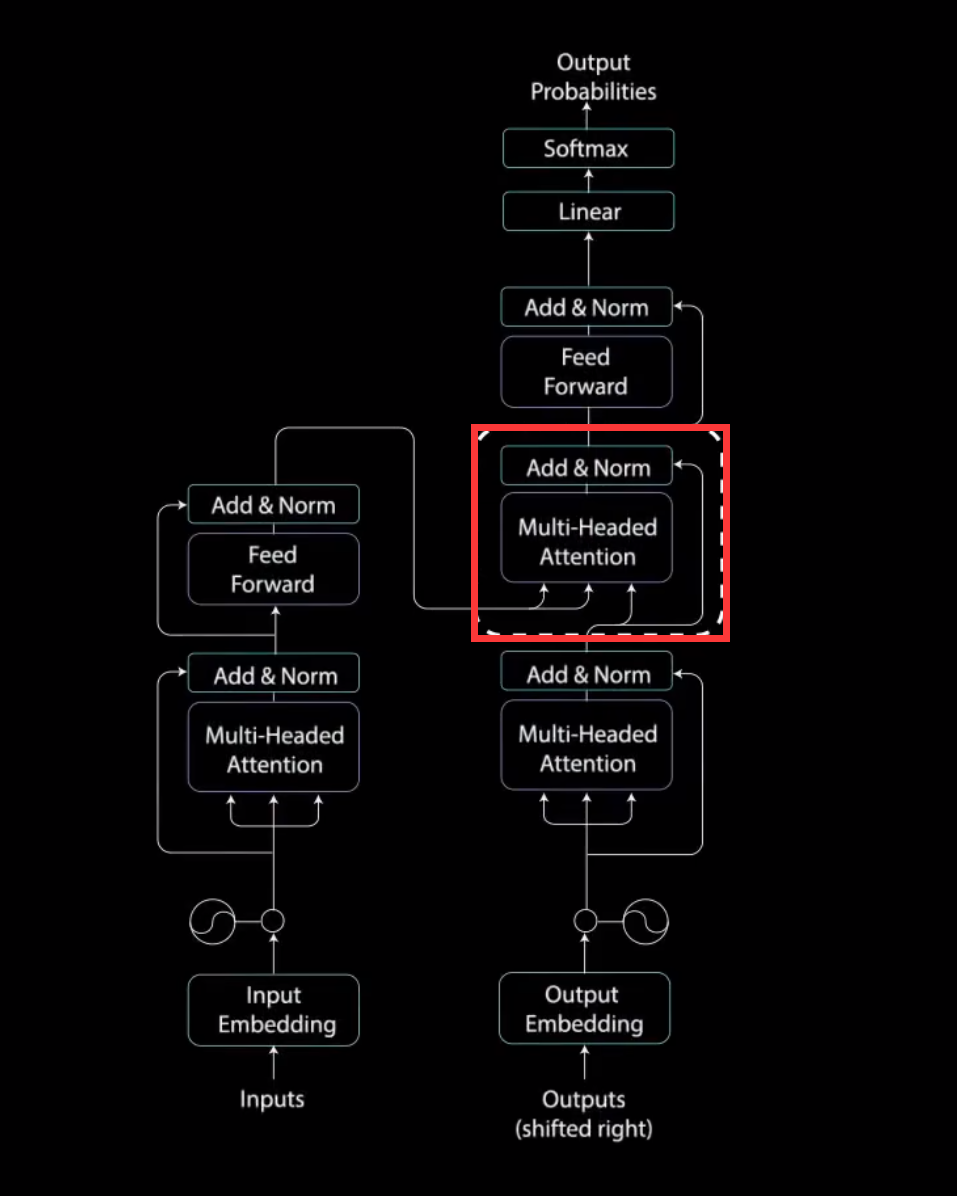
对于这一层,编码器的输出是查询和键,而第一个多头注意力层的输出是值。这个过程将编码器输入与解码器输入进行匹配,允许解码器决定那个编码器输入是相关的焦点。
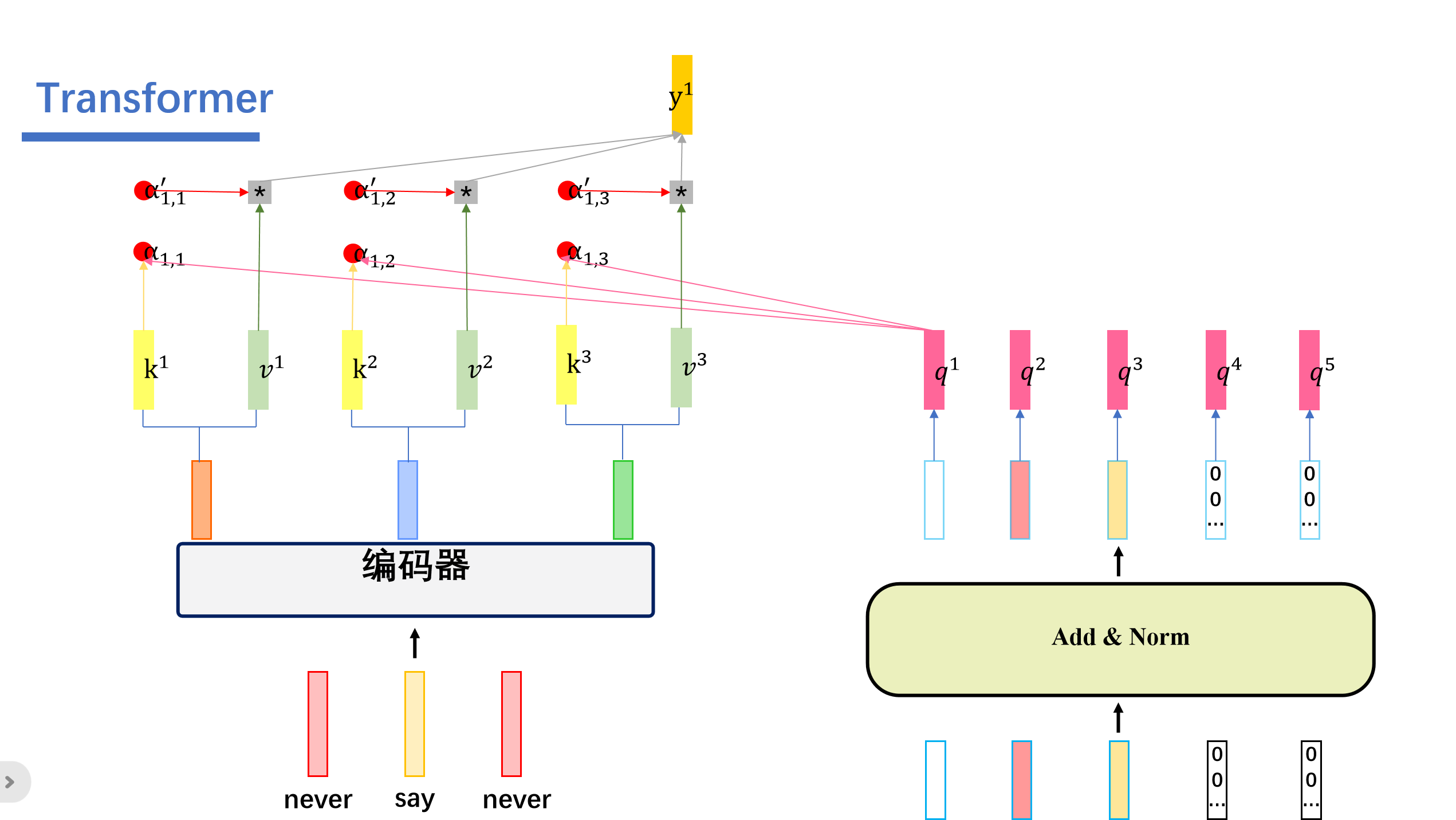
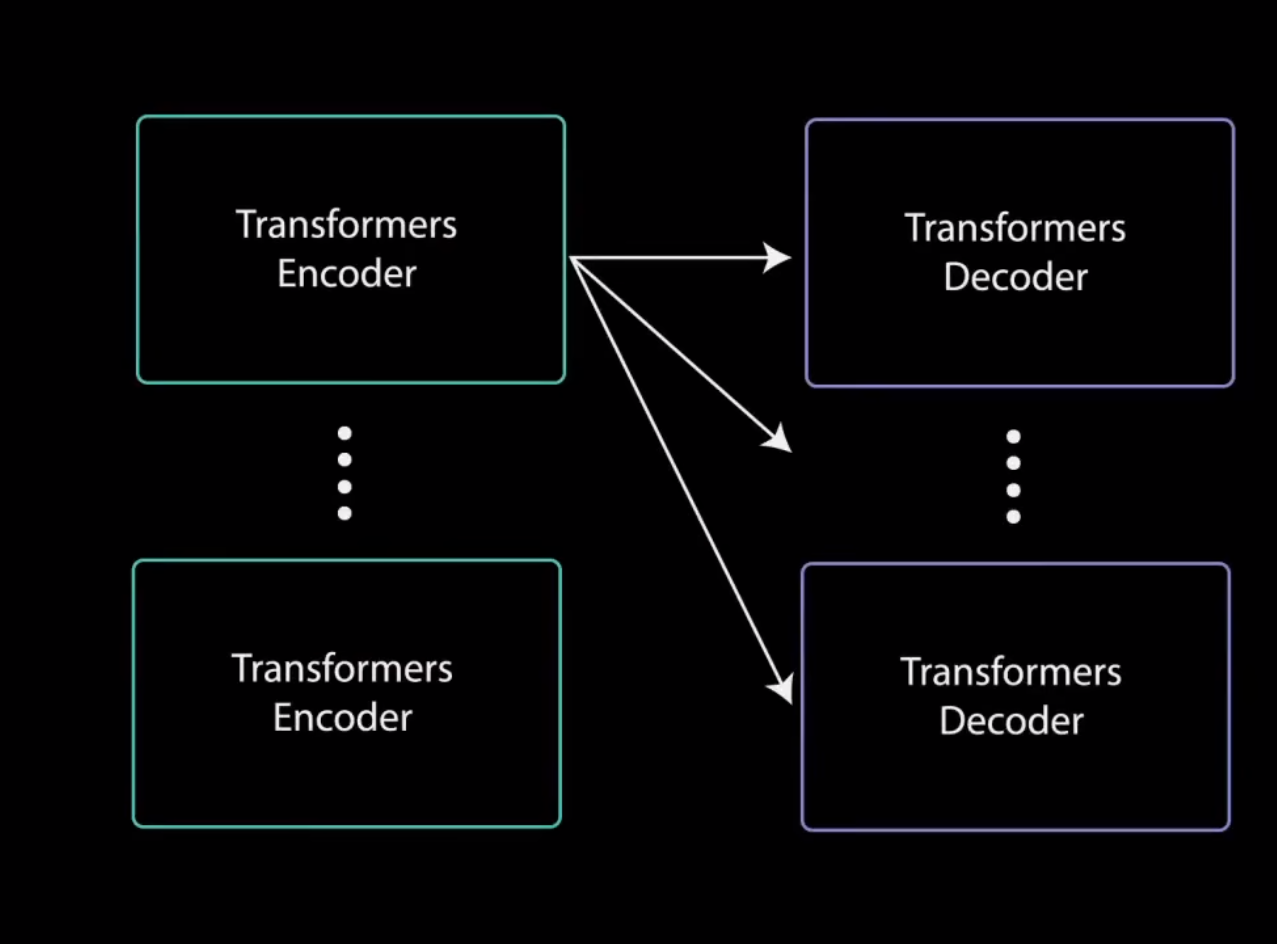
也就是这样的:(首先我们看左边的是编码器的输入,其中编码器并不改变其输入的维度,然后右边是解码器对输入mask之后的输出)
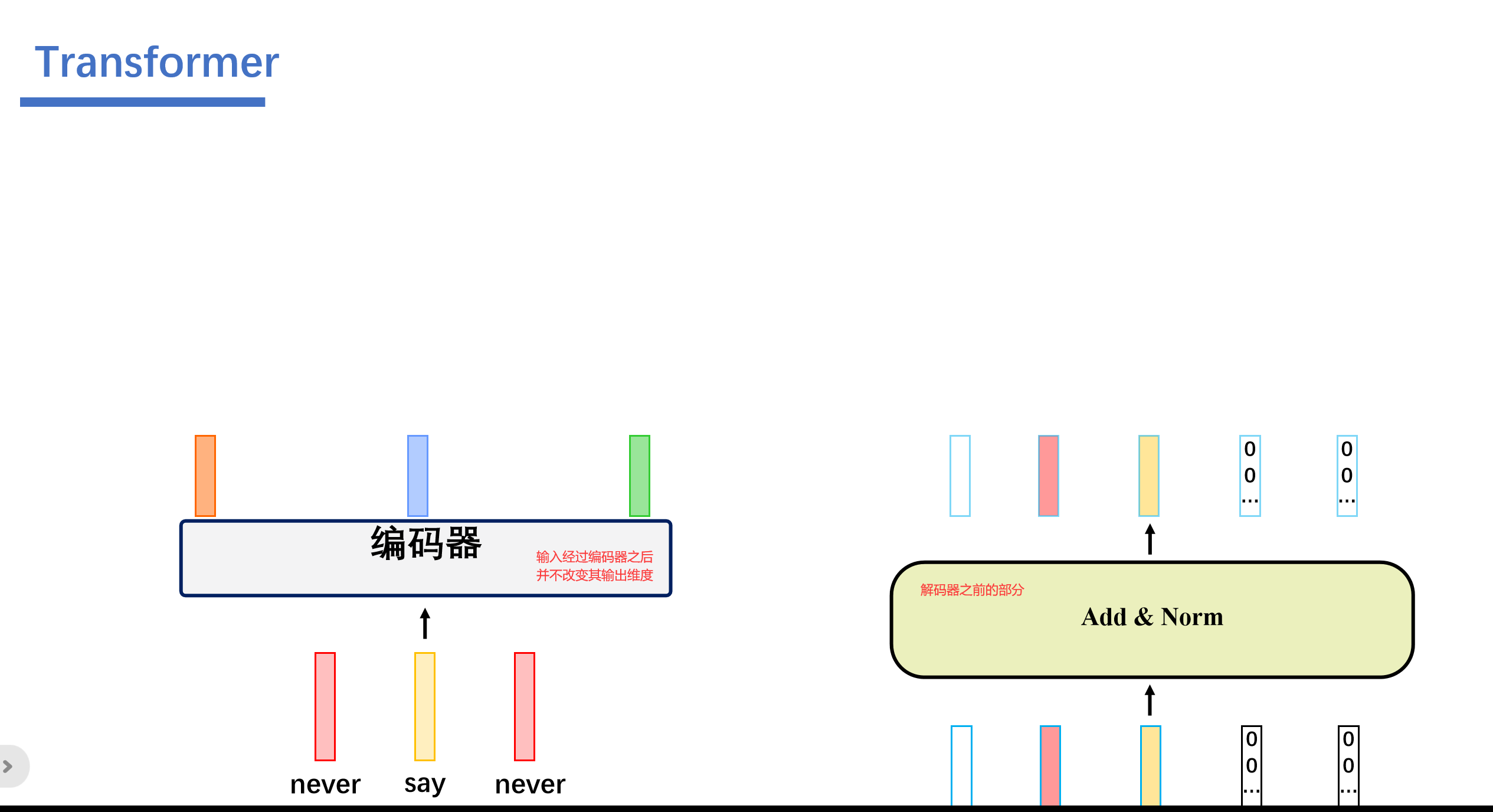
然后我们将编码器的输出看成key和value,然后将第一个多头注意力层输出的值看成query.
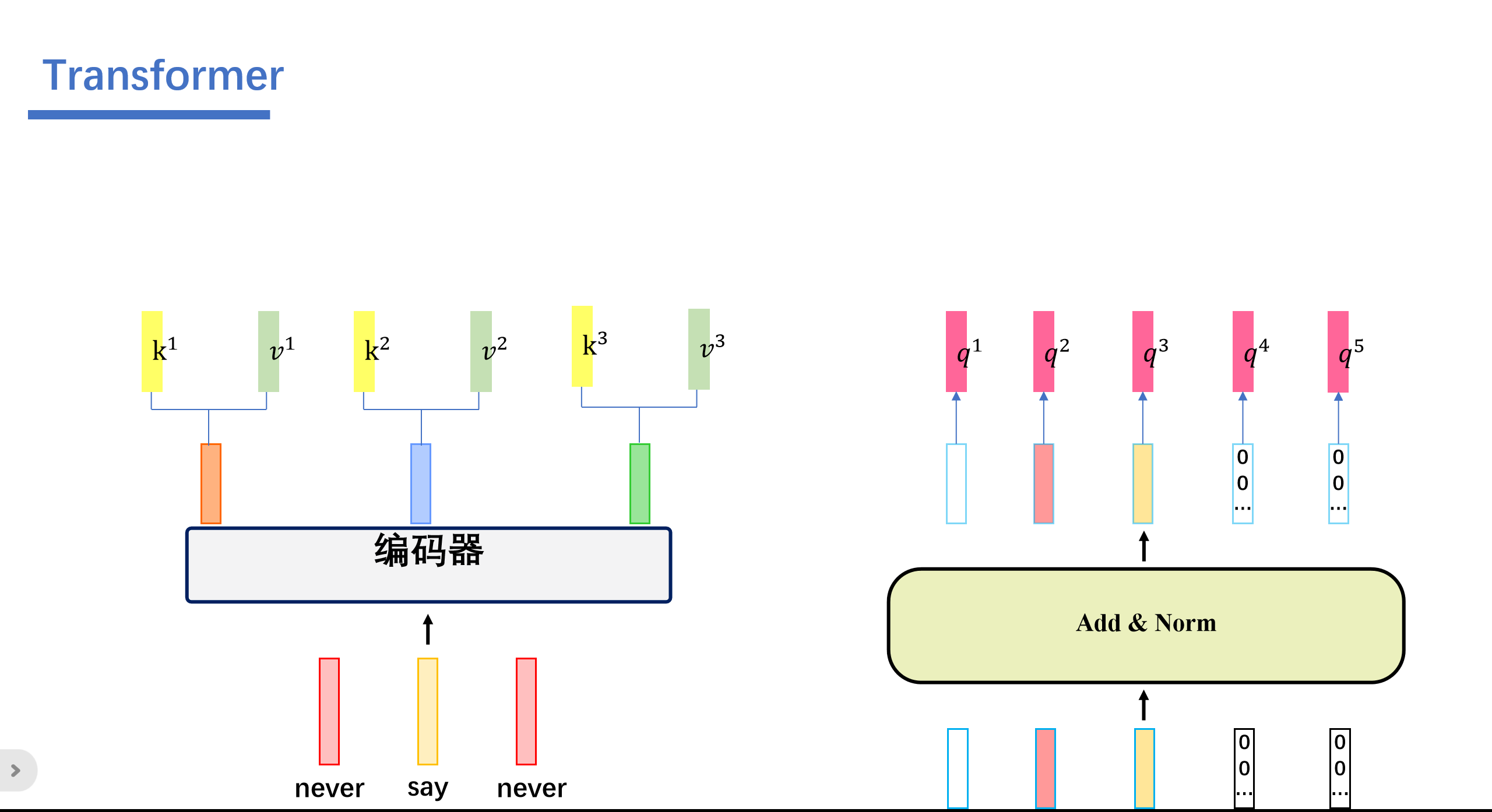
然后再进行Cross Attention计算:
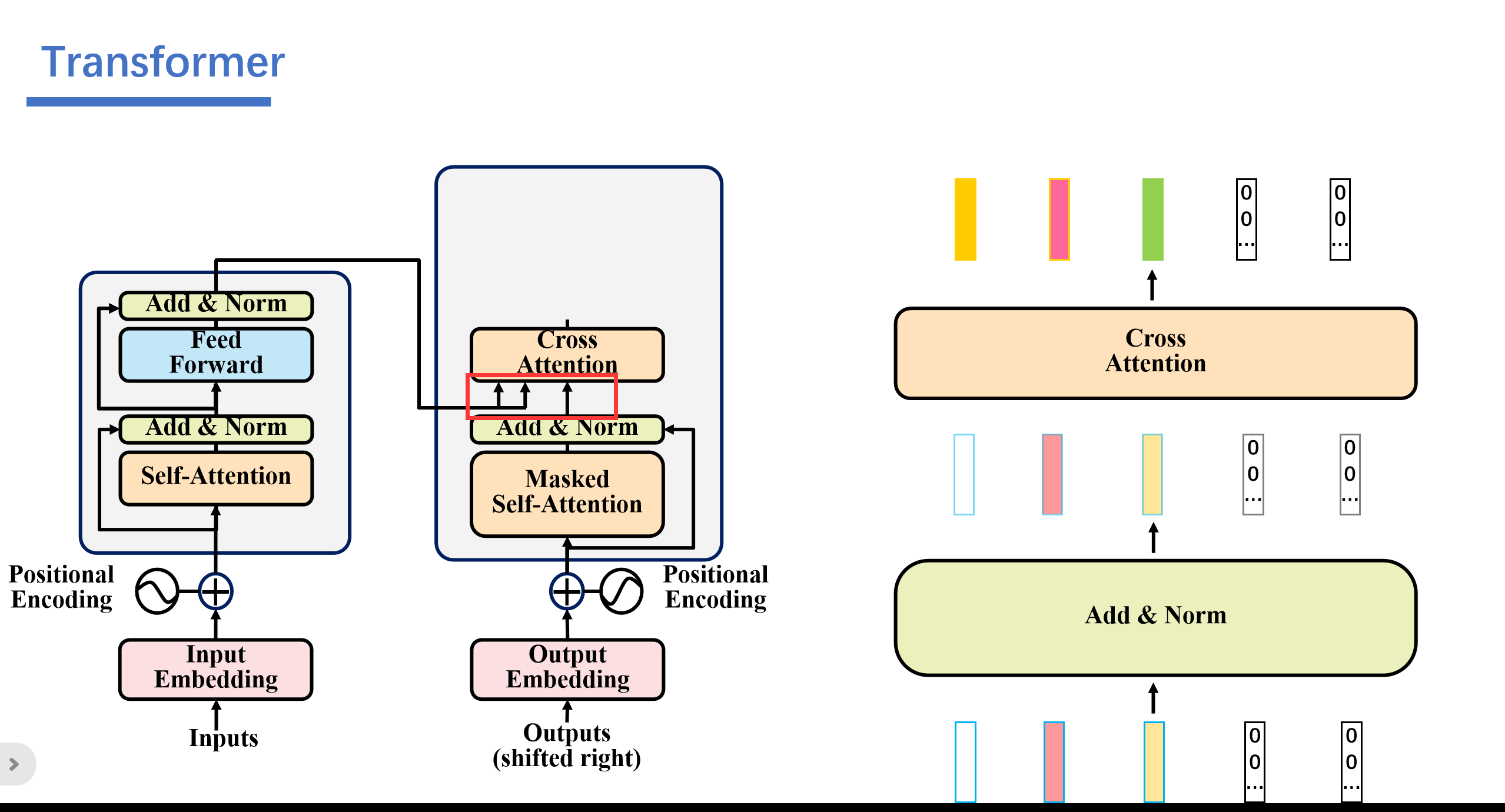
然后这就是这里三个箭头的奥秘:
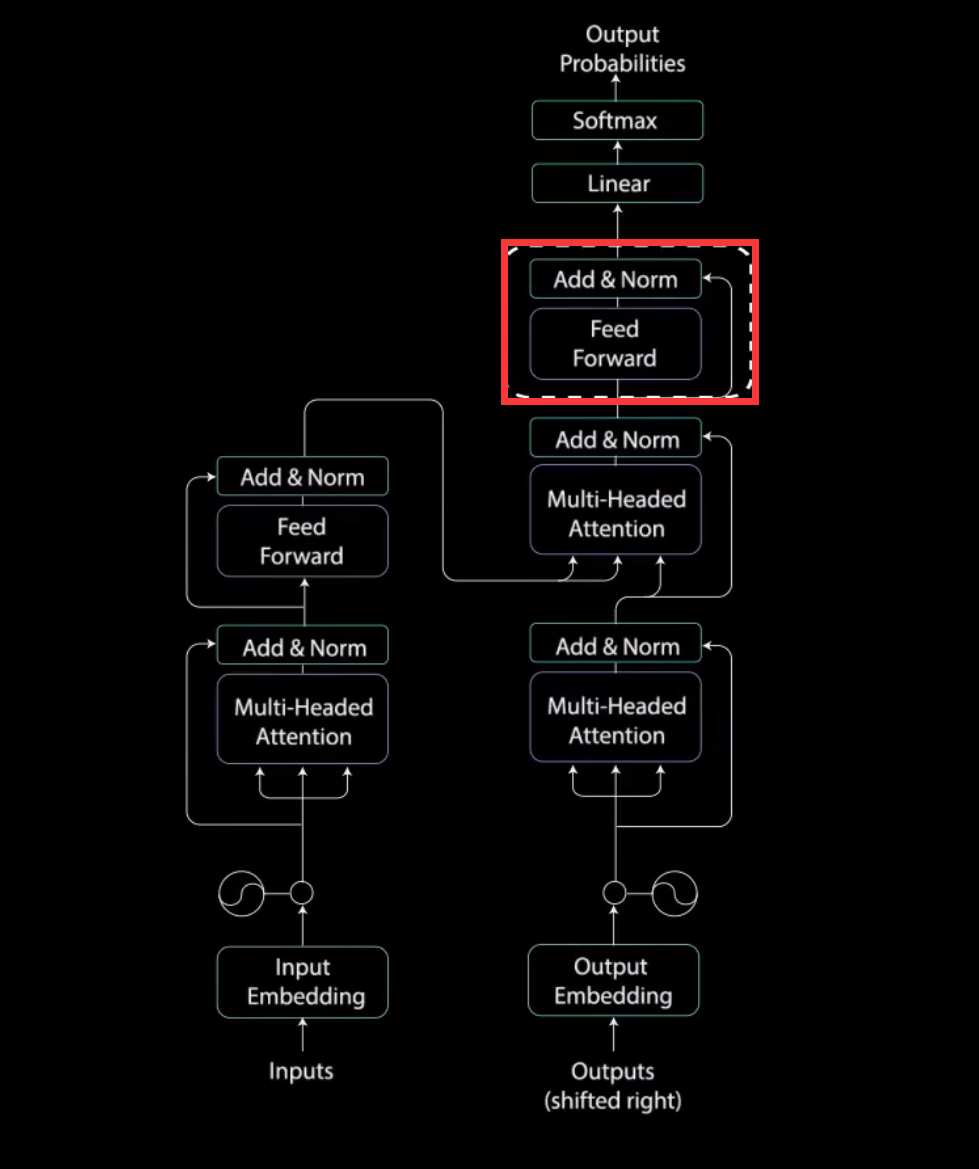
第二个多头注意力层的输出通过一个点对点前馈层进行进一步处理。
最后一个点对点前馈层的输出经过一个最后的线性层。该层充当分类器。分类器的大小与你拥有的类别数相同。
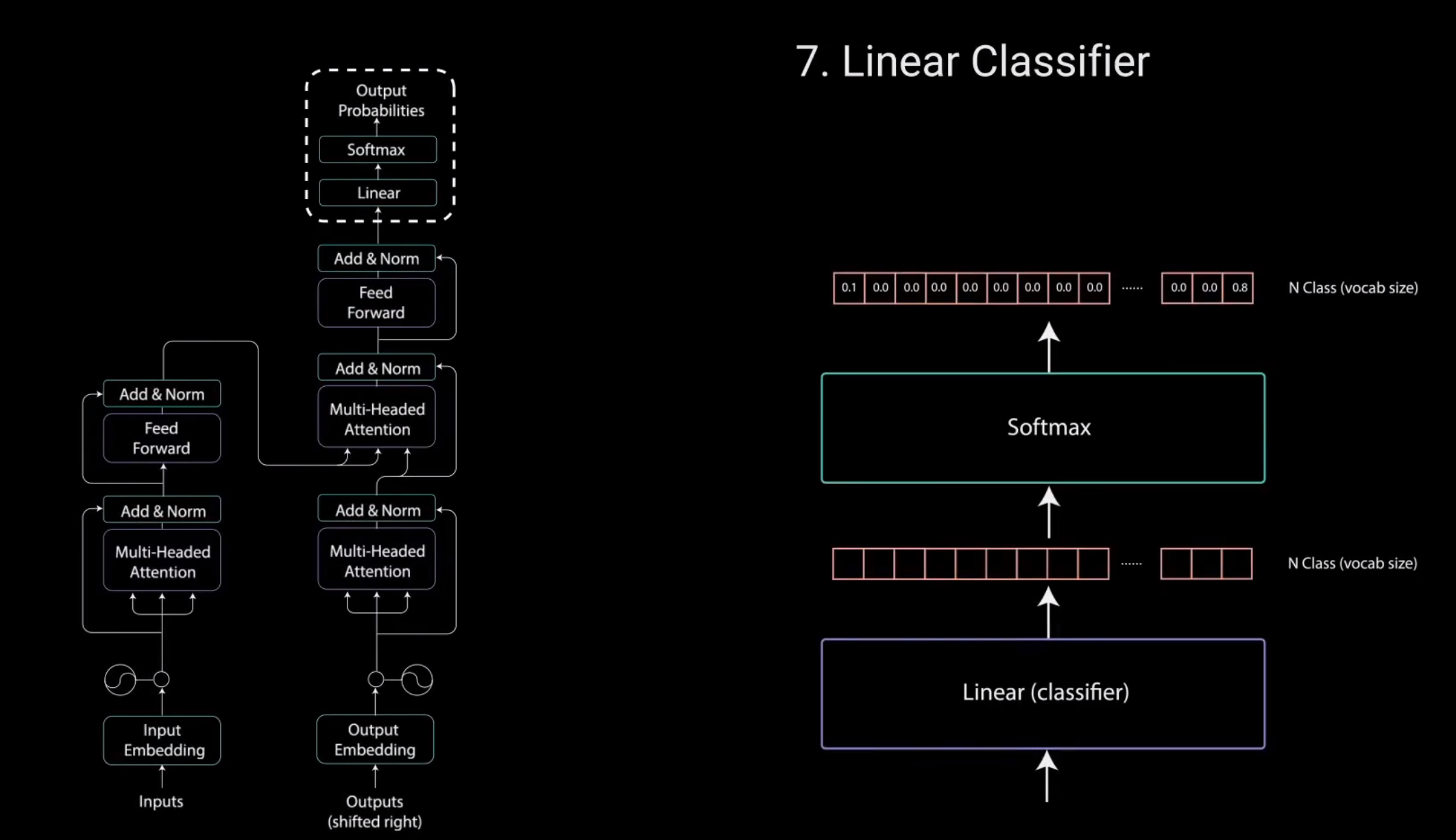
例如.如果你有10000个类别。表示10000个单词。那么分类器的输出大小将为10000。分类器的输出然后被送入一个softmax层。softmax层为每个类别生成0到1之间的概率得分。我们取概率得分最高的索引,等于我们预测的单词。然后,解码器将输出添加到解码器输入列表中。并继续解码直到预测出结束标记。在我们的例子中,最高概率预测是分配给结束标记的最终类。这就是解码器生成输出的方式。解码器可以堆叠n层高。每层从编码器和其前面的层中获取输入。
通过堆叠层.模型可以学会从注意力头中提取并关注不同的注意力组合,从而有可能提高预测能力。那就是全部了。这就是Transformer的原理。
这里有两个问题:
1. 第一个就是这个地方,我们将编码器的输出看成key和value,然后将第一个多头注意力层输出的值看成query.其实这里可以看成Cross Attention,而不是self Attention。Cross Attention会用解码器生成的q来查询编码器生成的k和v。一起计算attention score之后,softmax之后,将编码器的向量v按权相加。
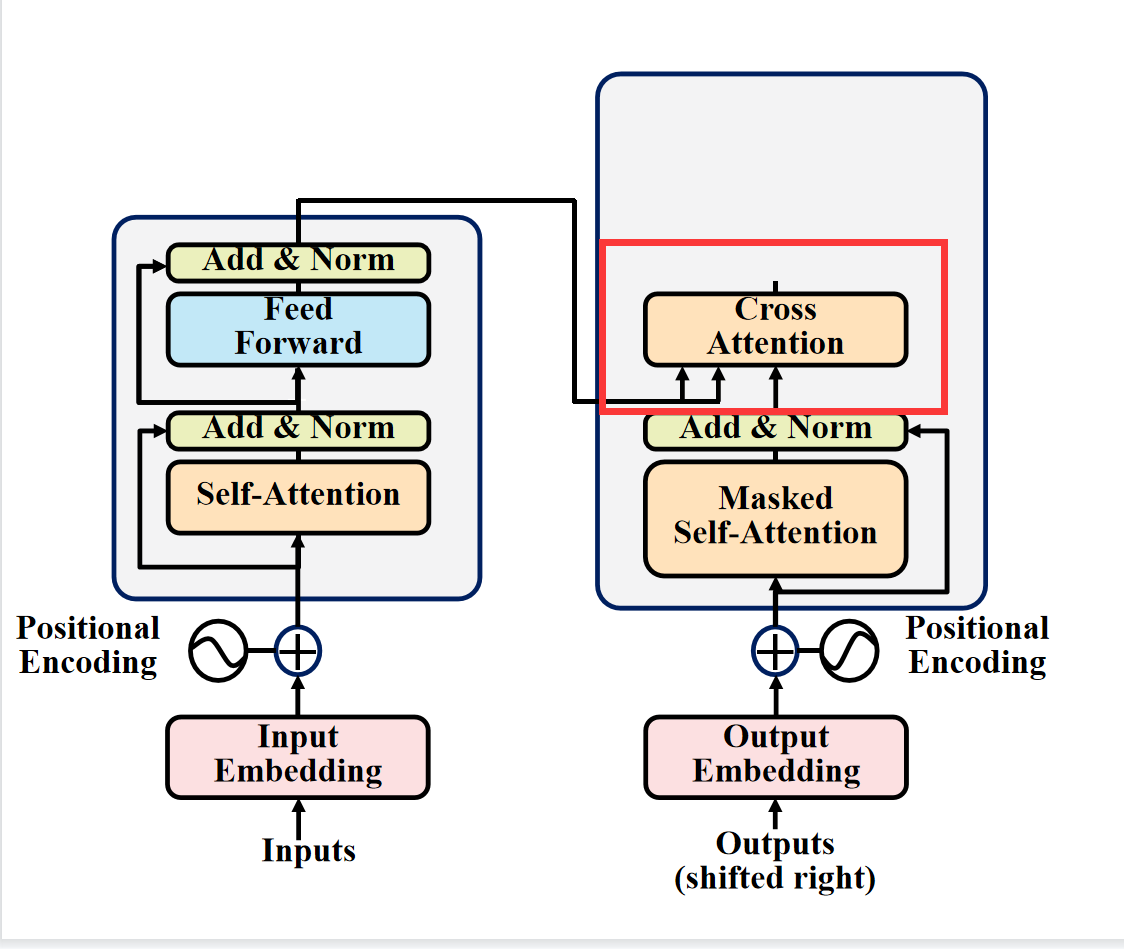
具体操作是这样的。
cross attention会用解码器生成q,然后Cross Attention会用解码器生成的q来查询编码器生成的k和v。一起计算attention score之后,softmax之后,将编码器的向量v按权相加。我们假设"never say never"通过编码器生成三个向量,接着解码器这边的5个向量,生成对应的q向量。然后编码器这边的三个向量会生成对应的k,v向量。
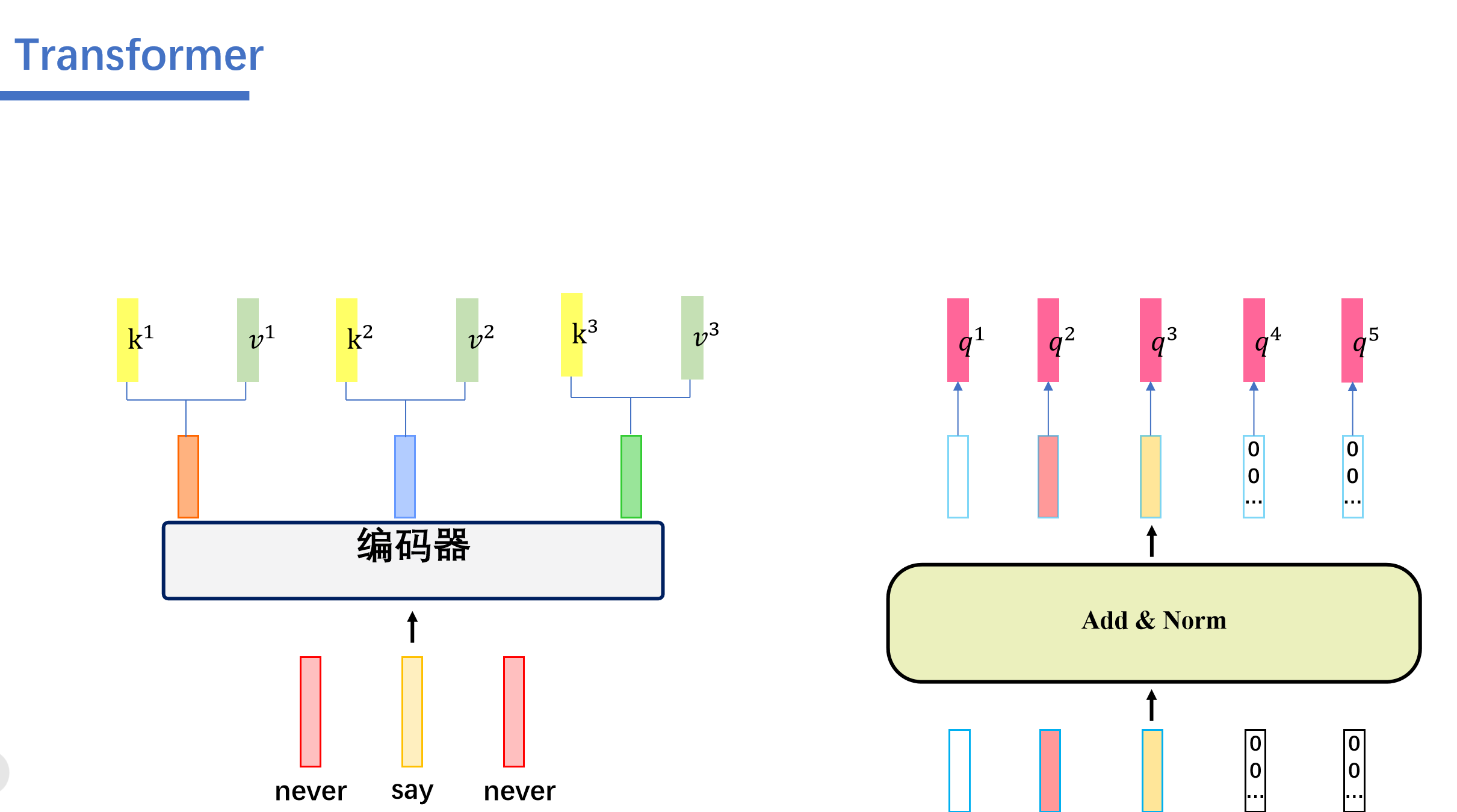
然后我们用解码器这个的q去查询编码器这边的k,也就是做一个内积的操作。得到attention score ,之后这些再softmax得到对应的。与对应的v相乘后相加。即可得到我们的输出。
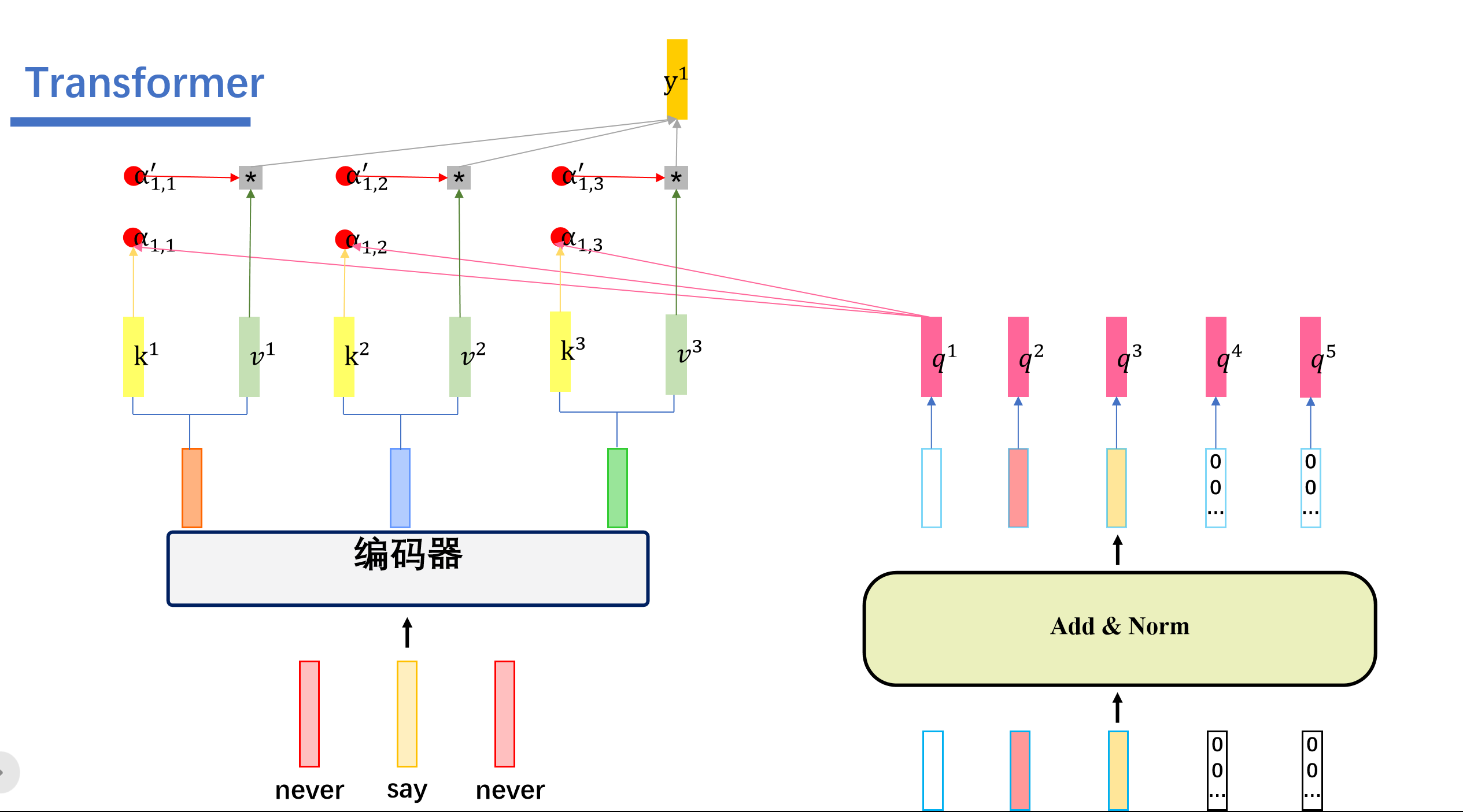
我们这里举的例子是用查询得到的,然后我们用查询会得到,用查询会得到.....用查询会得到。
与传统的self attention一样,这里的cross attention也是输入多少矩阵输出多少矩阵。
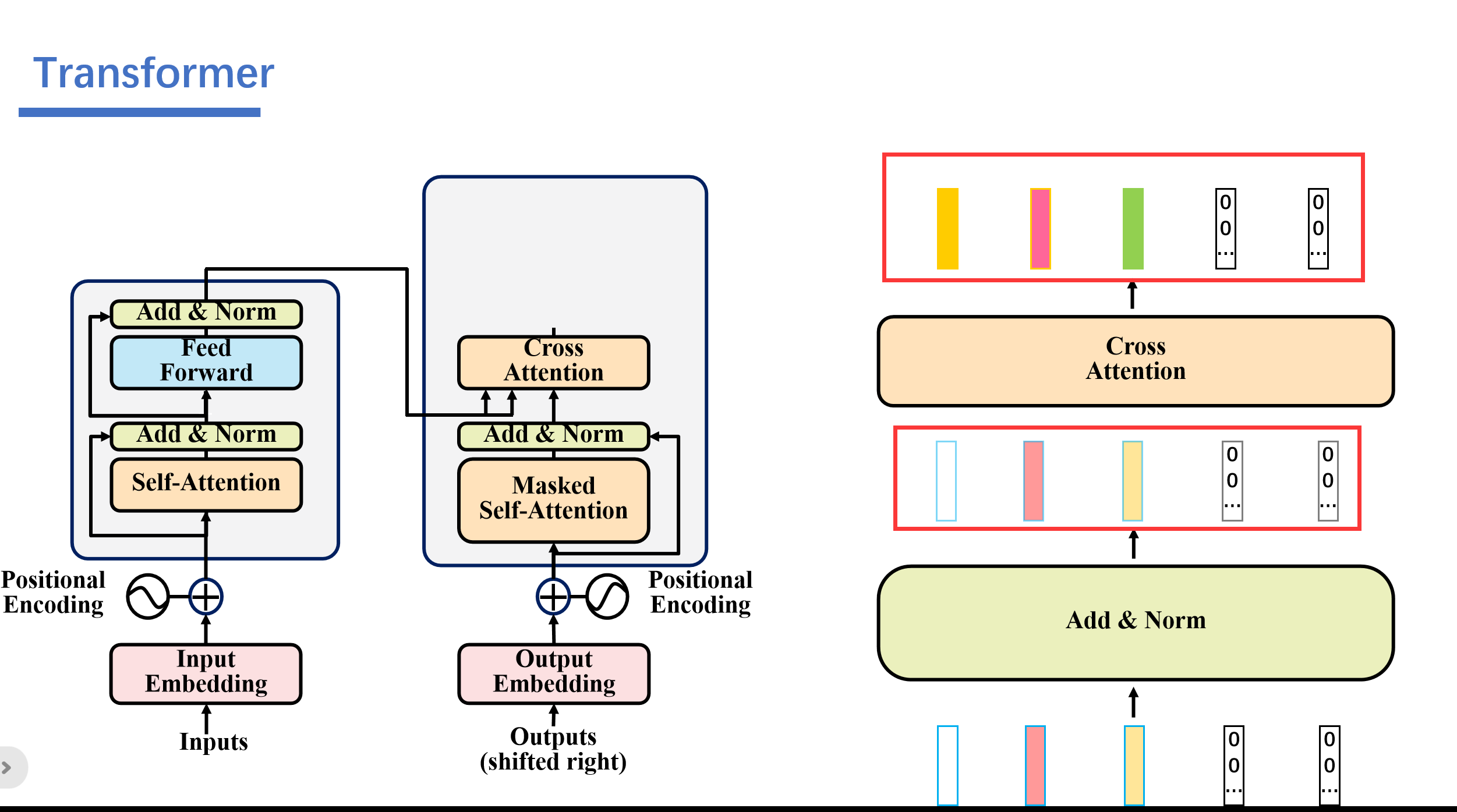
之后再经过Add&Norm和,Feed Forward,Add&Norm。
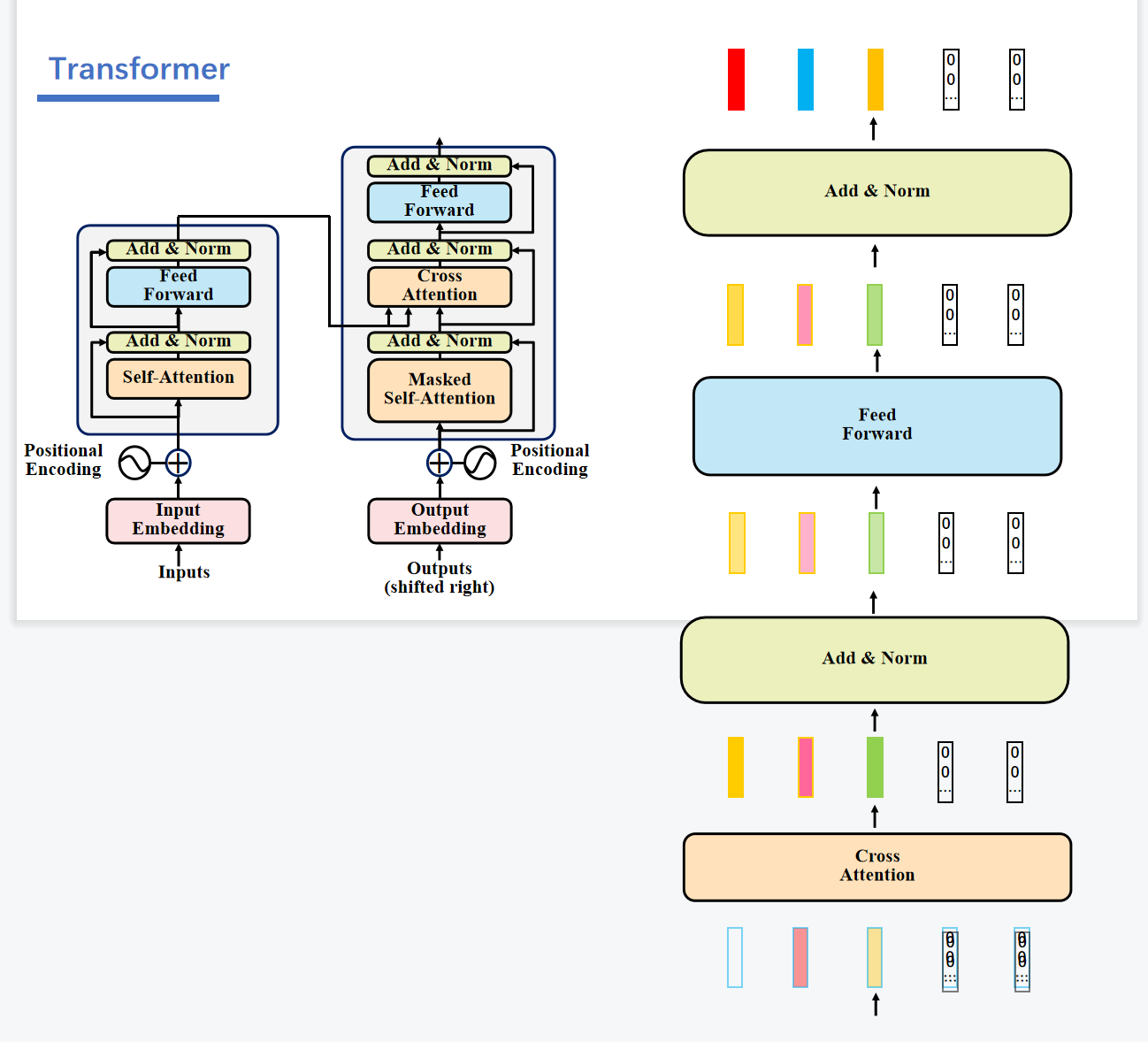
之后再经过线性层进行输出。
2. 再算self attention的时候是共享权重的。
例如再算这里的时候用的同一组参数。
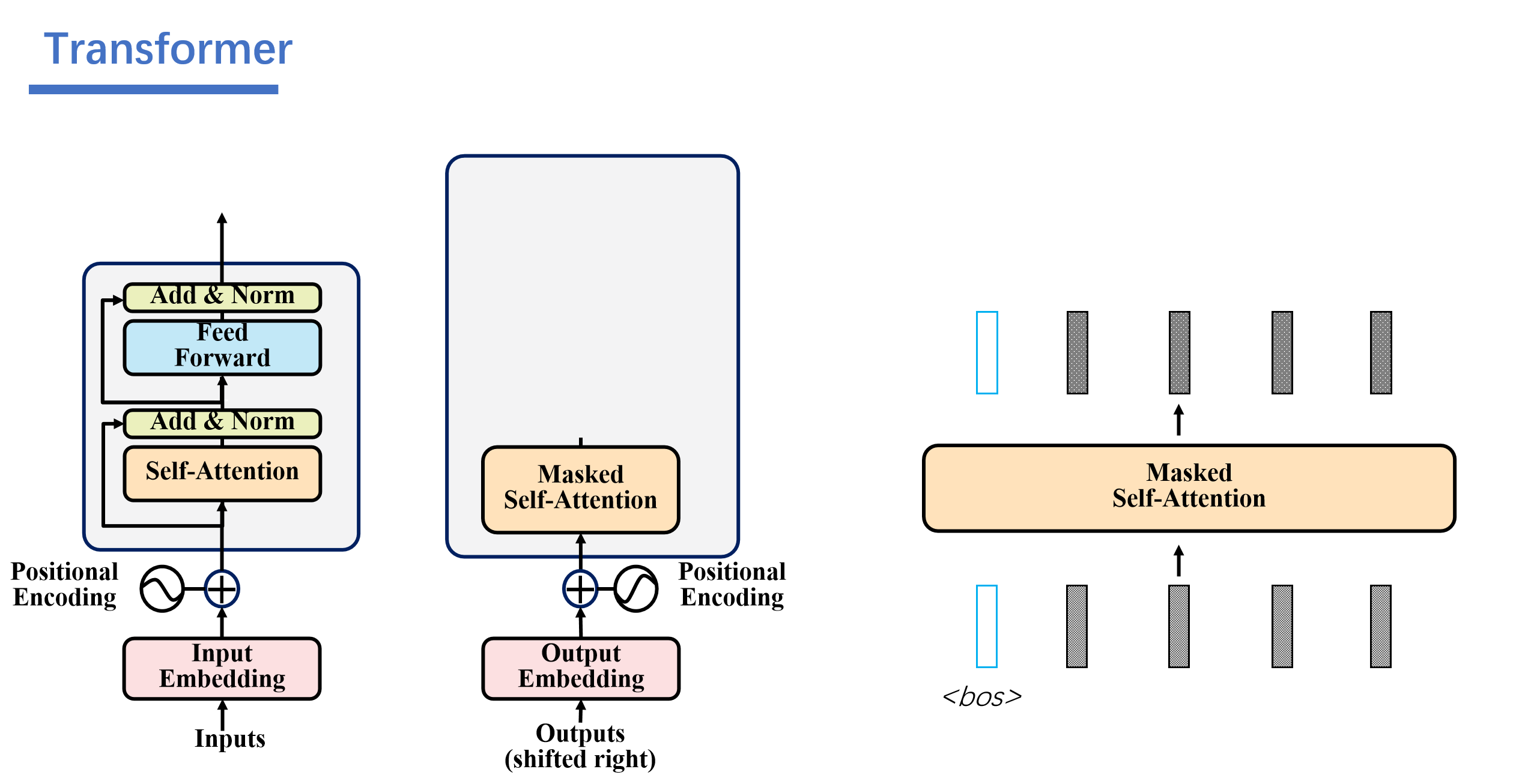
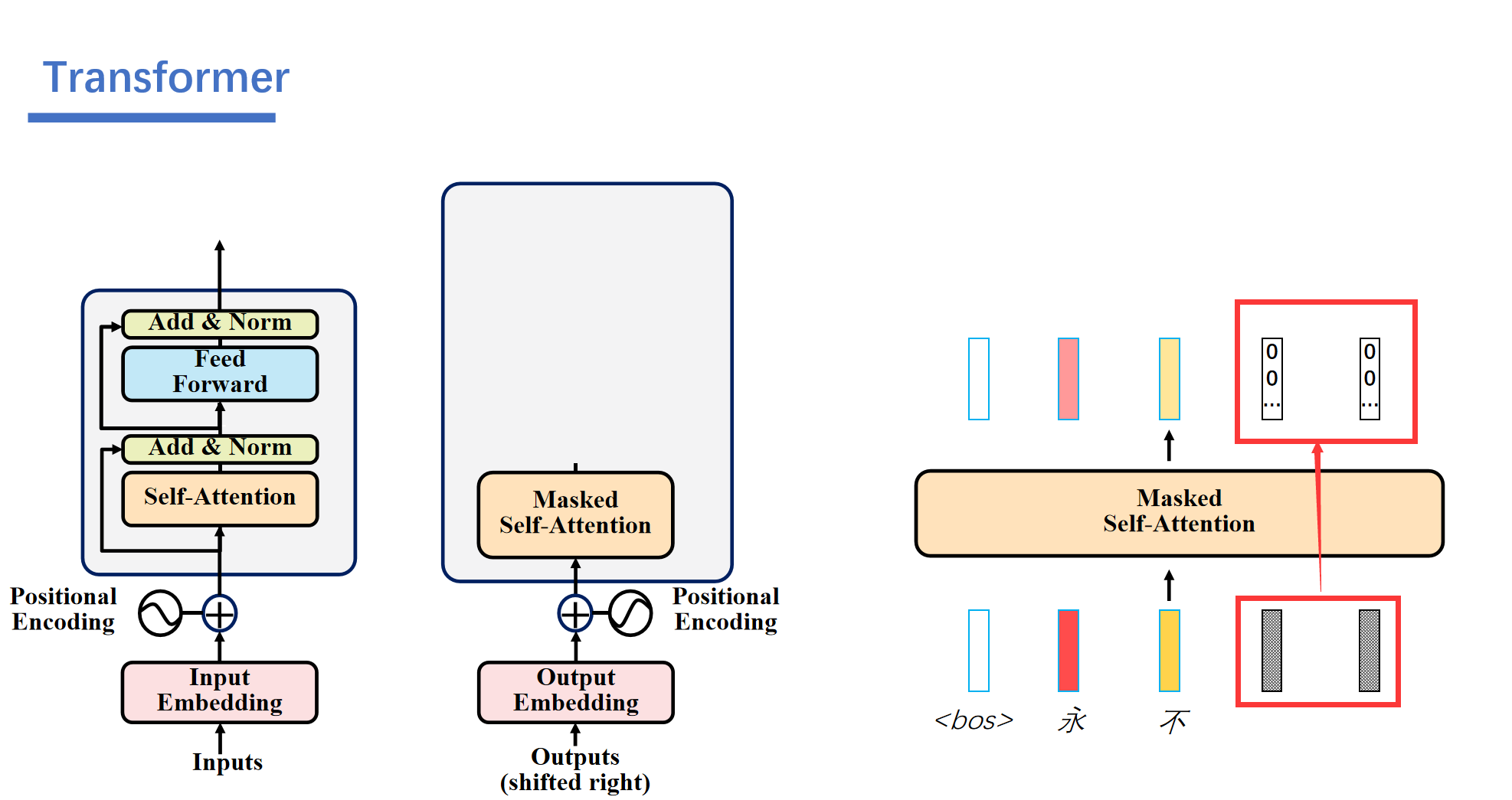
3. Masked Self-Attention
解码器是自回归的,比如说一开始我们只知道<bos>的,然后后面的我们都不知道,都是一些随机的数。
接着解码器就会根据编码器的信息和我们仅有的<bos>的信息,经过一顿运算之后就能输出结果"永"。
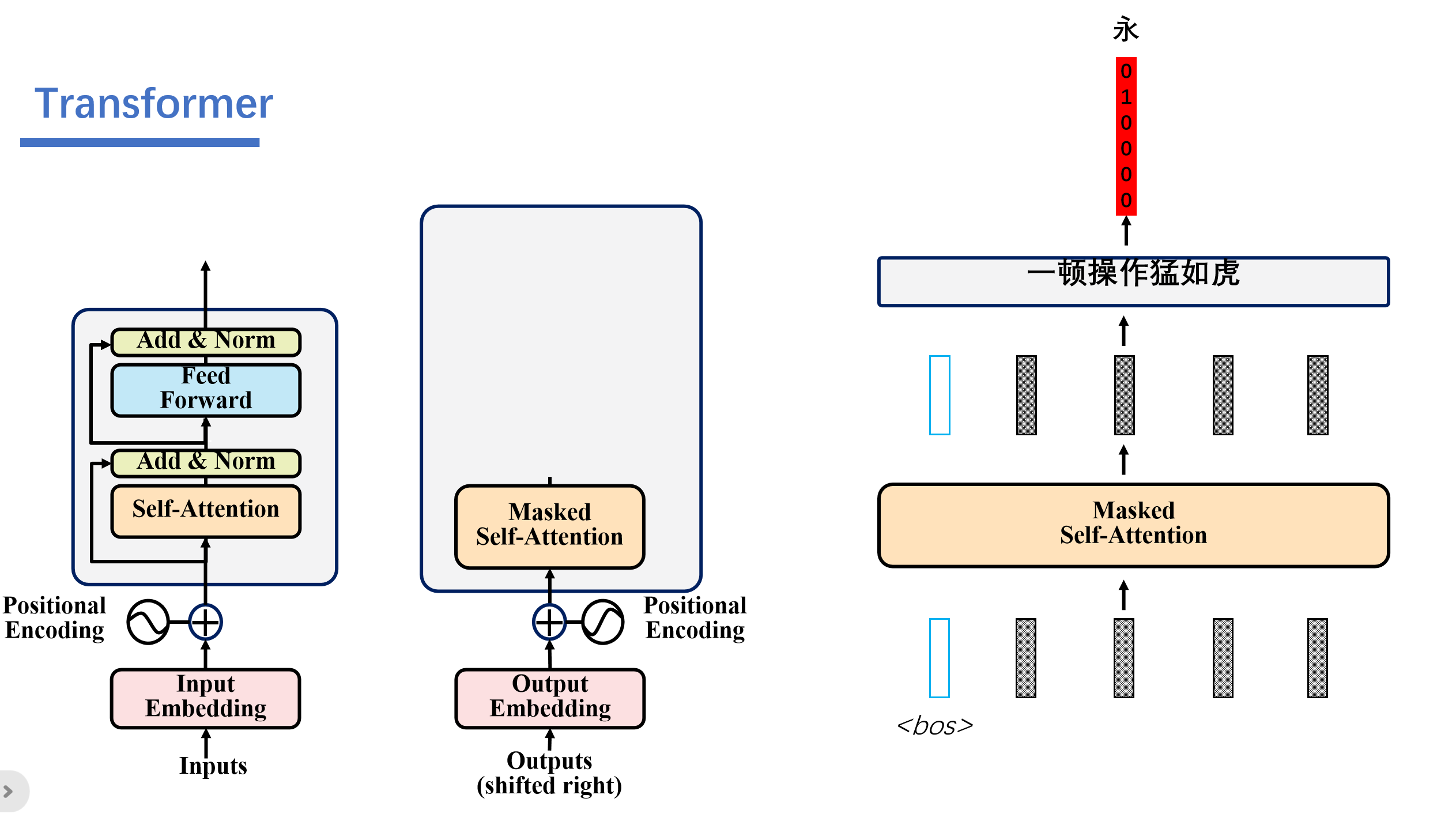
然后这个预测出来的永的信息会加入到编码器的输入中。然后解码器就可以结合编码器的信息和<bos>,永的信息,得到信息不。
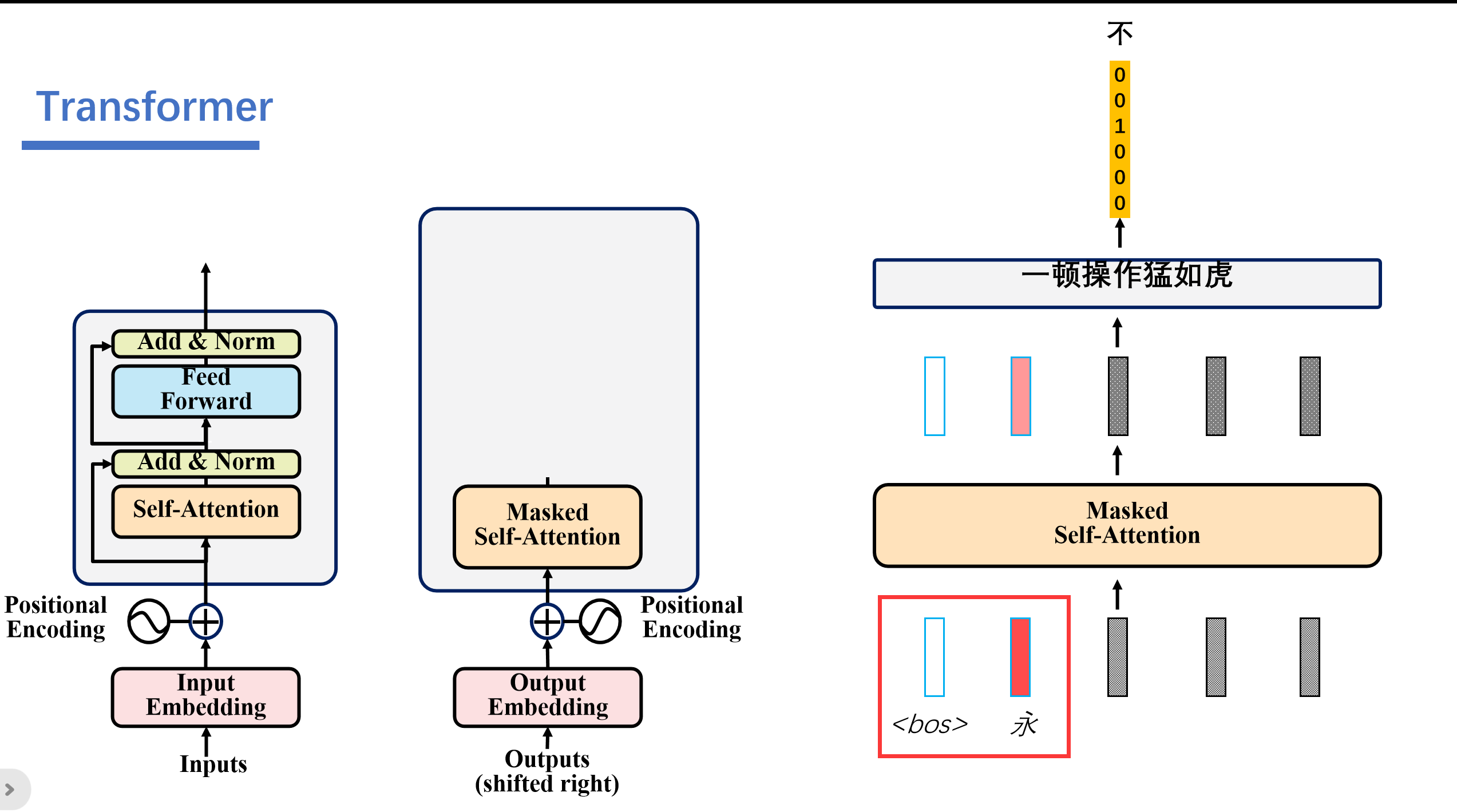
之后再根据<bos>,永,不的信息预测出来言。
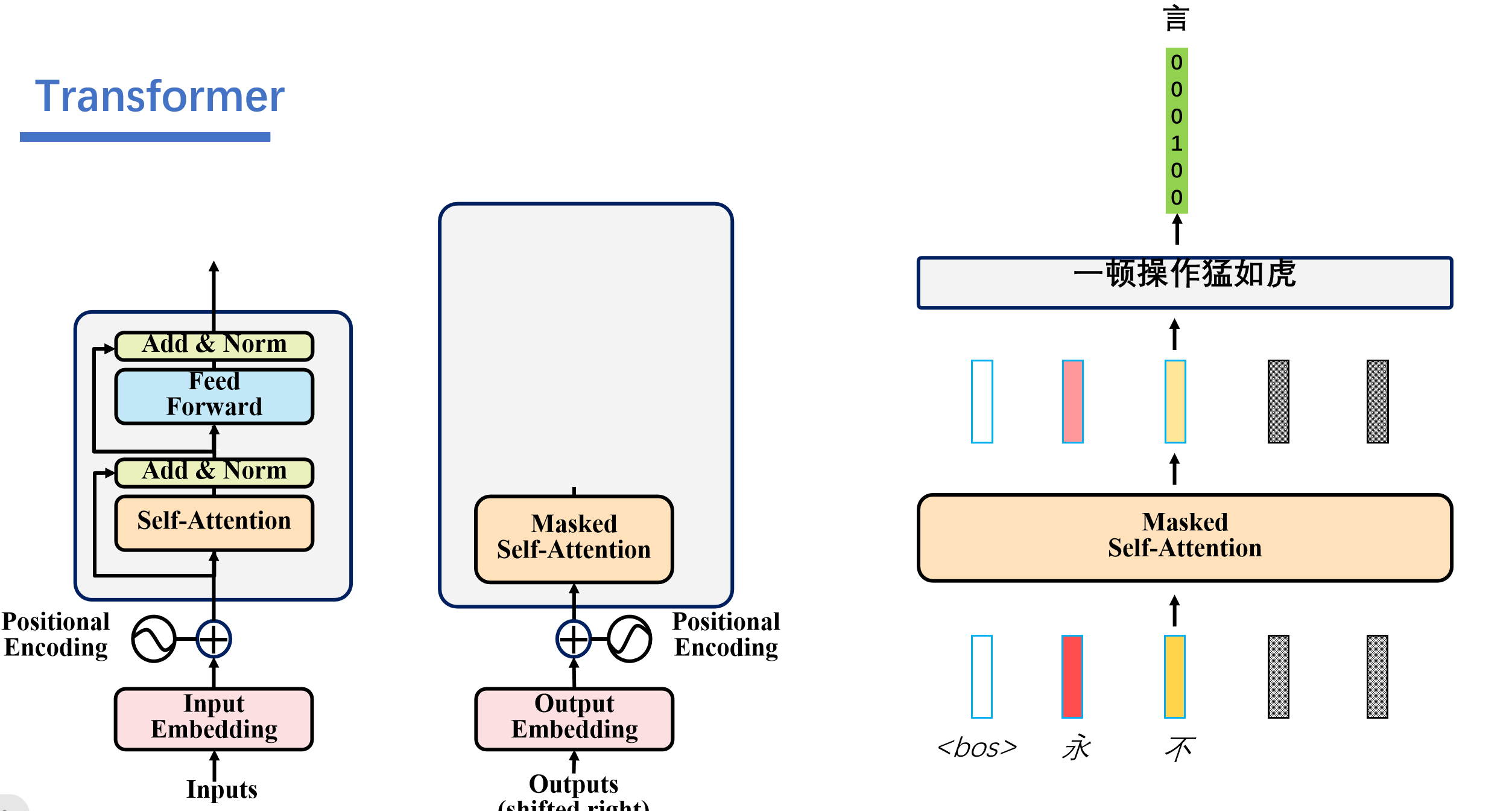
.....
最后由<bos>,永,不,言,弃预测出来<eos>,就结束了。
然后这里就会用到Masked-Attention。我们再预测前面的时候需要将后面的给遮起来。
具体操作是这样的:我们将后面的权重设为负无穷。
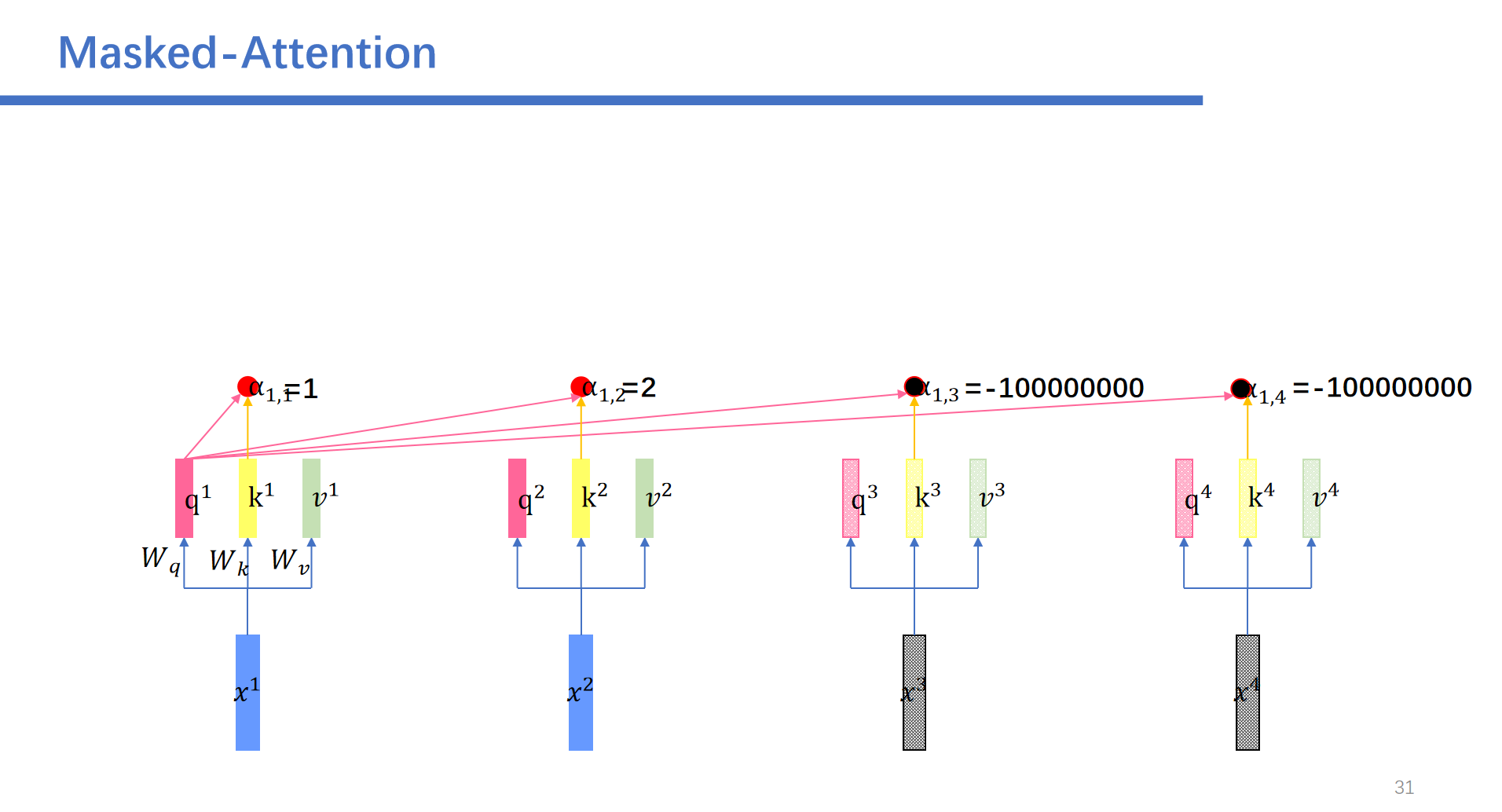
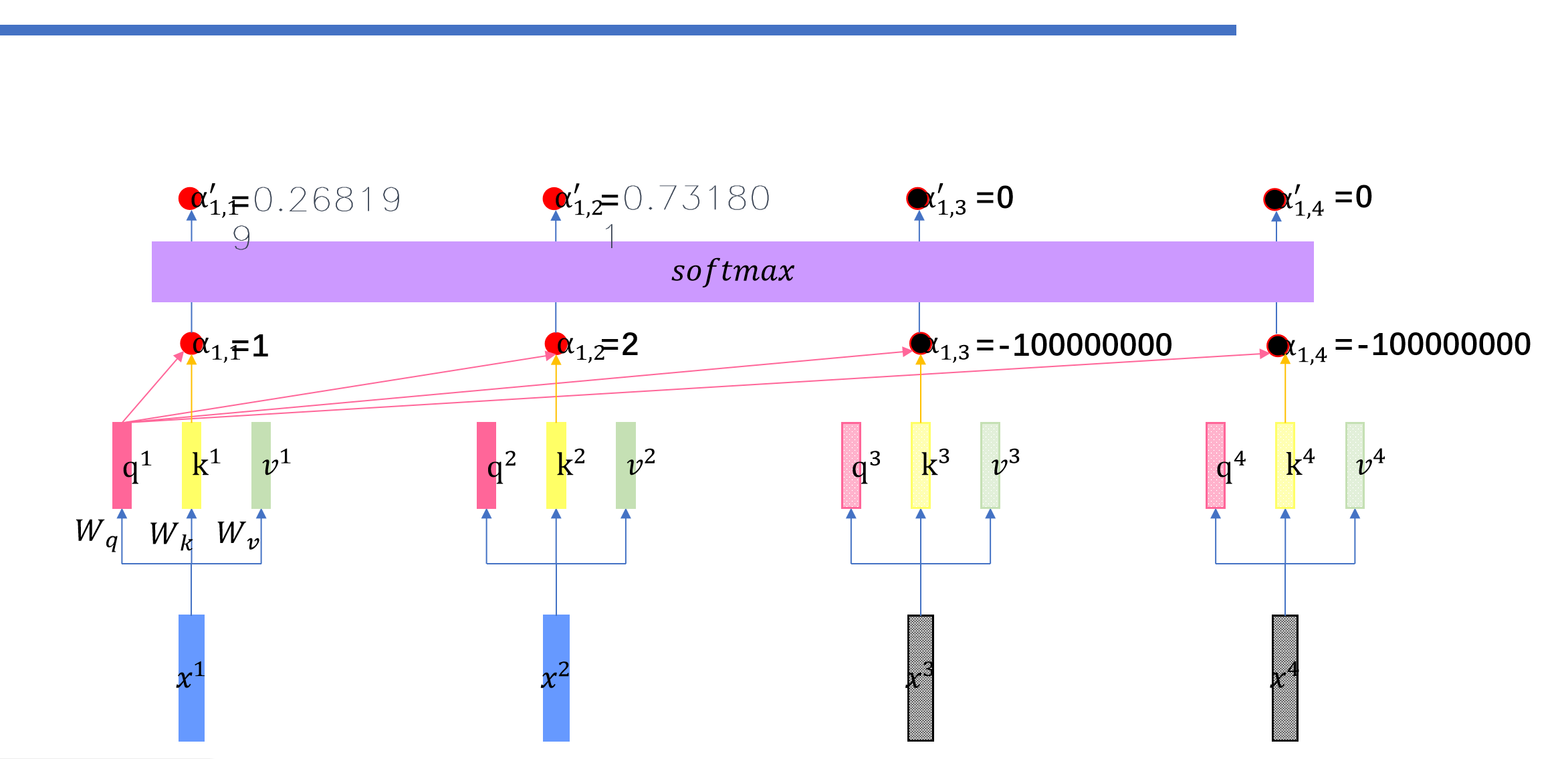
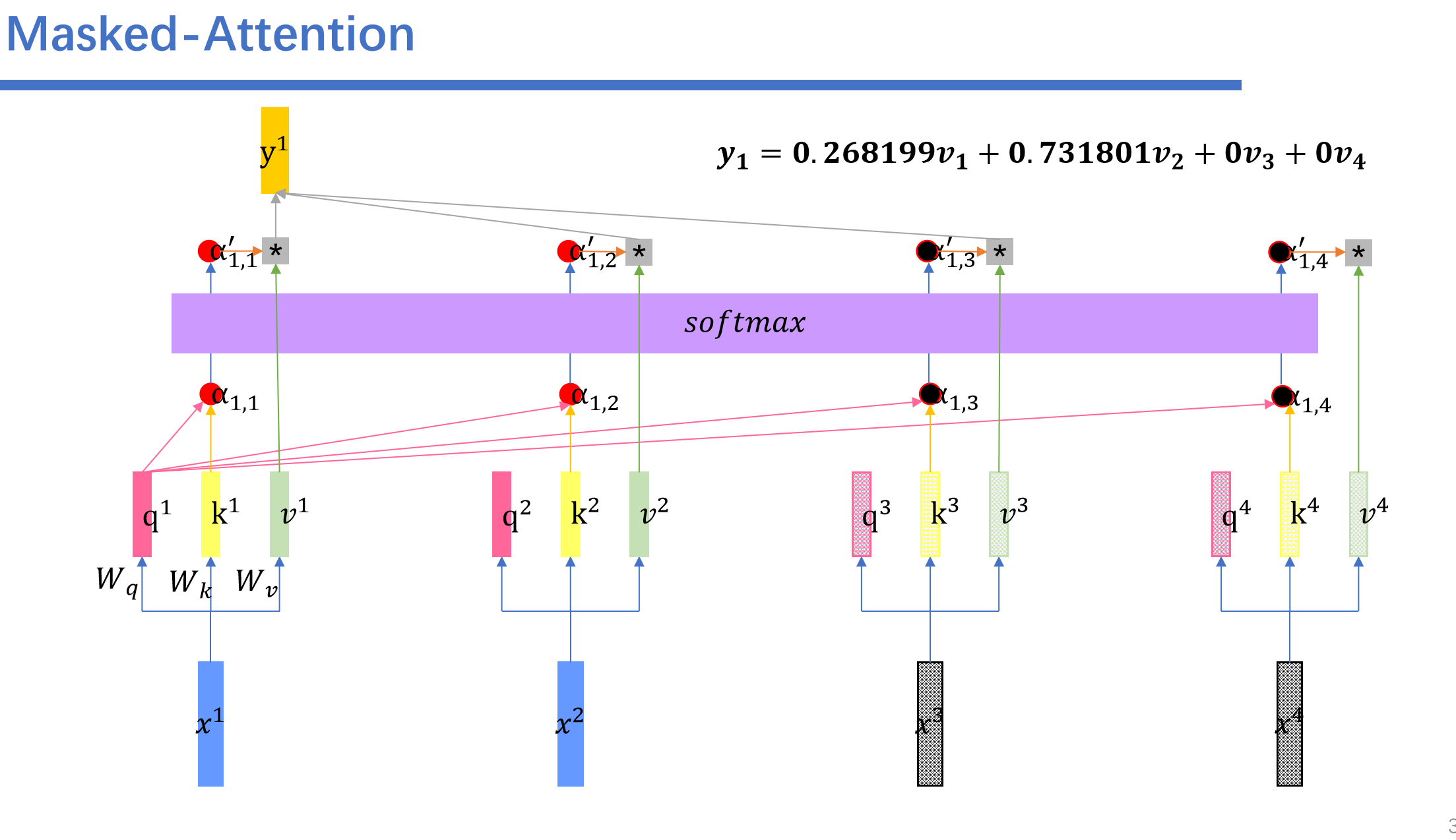
比如说我们,再预测到了永,不之后,之后的向量都是随机的数,然后我们进行masked self-attention之后,随机的数字对应的矩阵都是0.


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· winform 绘制太阳,地球,月球 运作规律
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人