自注意力与位置编码
在深度学习中,经常使用卷积神经网络(CNN)或循环神经网络(RNN)对序列进行编码。想象一下,有了注意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个查询都会关注所有的键-值对并生成一个注意力输出。由于查询、键和值来自同一组输入,因此被称为 自注意力(self‐attention)。本节将使用自注意力进行序列编码,以及如何使用序列的顺序作为补充信息。
自注意力
给定一个由词元组成的输入序列,其中任意。该序列的自注意力输出为一个长度相同的序列,其中:
下面的代码片段是基于多头注意力对一个张量完成自注意力的计算,张量的形状为(批量大小,时间步的数目或词元序列的长度,d)。输出与输入的张量形状相同。
import math
import torch
from torch import nn
from d2l import torch as d2l
num_hiddens, num_heads = 100, 5
attention = d2l.MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
batch_size, num_queries, valid_lens = 2, 4, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
attention(X, X, X, valid_lens).shape
torch.Size([2, 4, 100])
这里输出就是.也就是
比较卷积神经网络、循环神经网络和自注意力
接下来比较下面几个架构,目标都是将由n个词元组成的序列映射到另一个长度相等的序列,其中的每个输入词元或输出词元都由d维向量表示。具体来说,将比较的是卷积神经网络、循环神经网络和自注意力这几个架构的计算复杂性、顺序操作和最大路径长度。请注意,顺序操作会妨碍并行计算,而任意的序列位置组合之间的路径越短,则能更轻松地学习序列中的远距离依赖关系.
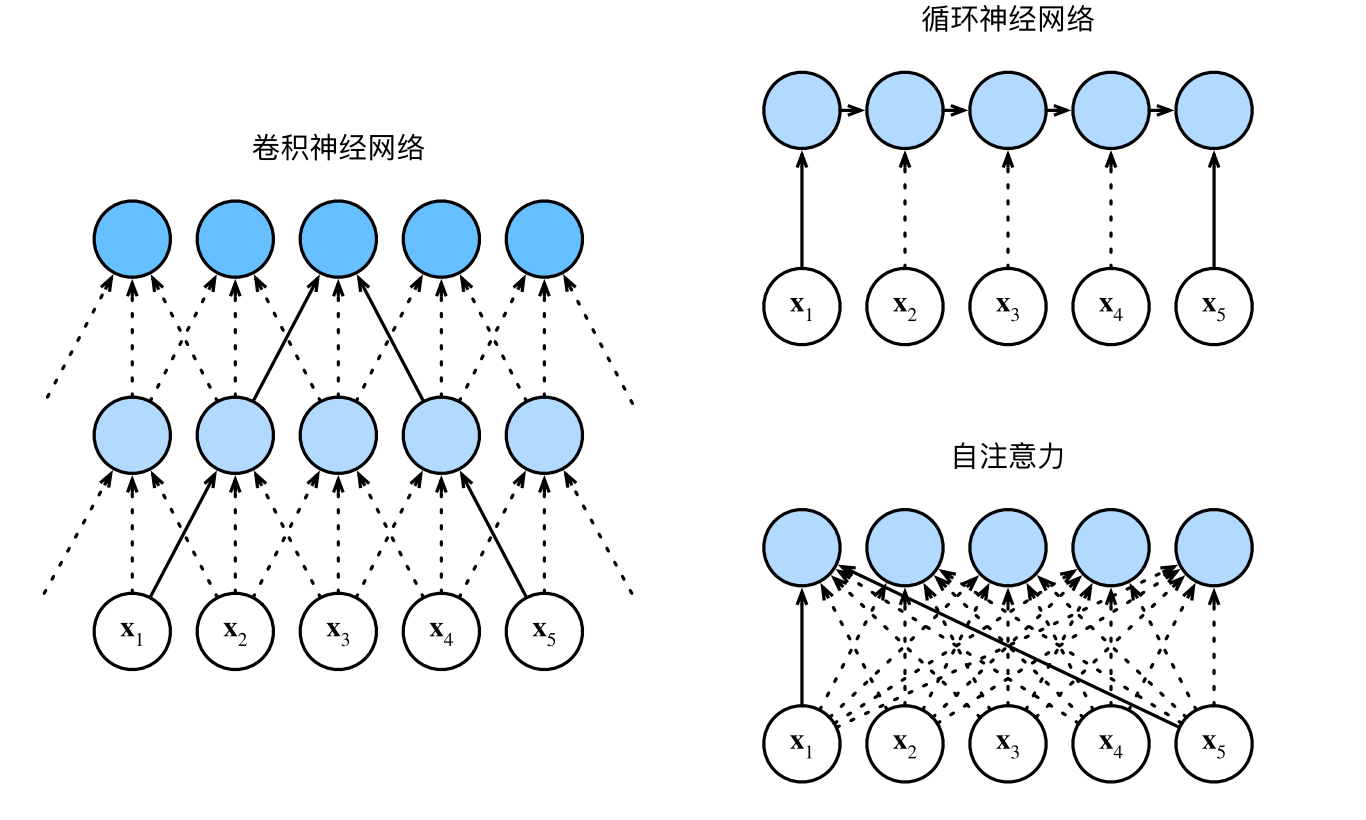
考虑一个卷积核大小为k的卷积层。在后面的章节将提供关于使用卷积神经网络处理序列的更多详细信息。目前只需要知道的是,由于序列长度是n,输入和输出的通道数量都是d,所以卷积层的计算复杂度为。卷积神经网络是分层的,因此为有O(1)个顺序操作,最大路径长度为。例如,和处于图中卷积核大小为3的双层卷积神经网络的感受内。
当更新循环神经网络的隐状态时,权重矩阵和维隐状态的乘法计算复杂度为。由于序列长度为n,因此循环神经网络层的计算复杂度为。有O(n)个顺序操作无法并行化,最大路径长度
也是。在自注意力中,查询、键和值都是矩阵。考虑 缩放的"点-积"注意力,其中矩阵乘以矩阵。之后输出的矩阵乘以矩阵。因此,自注意力具有计算复杂性。所讲,每个词元都通过自注意力直接连接到任何其他词元。因此,有O(1)个顺序操作可以并行计算,最大路径长度也是O(1)。
总而言之,卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
位置编码
在处理词元序列时,循环神经网络是逐个的重复地处理词元的,而自注意力则因为并行计算而放弃了顺序操作。为了使用序列的顺序信息,通过在输入表示中添加 位置编码(positional encoding)来注入绝对的或相对的位置信息。位置编码可以通过学习得到也可以直接固定得到。接下来描述的是基于正弦函数和余弦函数的固定位置编码。
假设输入表示包含一个序列中个词元的维嵌入表示。位置编码使用相同形状的位置嵌入矩阵输出,矩阵第行、第列和列上的元素为:
乍一看,这种基于三角函数的设计看起来很奇怪。在解释这个设计之前,让我们先在下面的PositionalEncoding类中实现它。
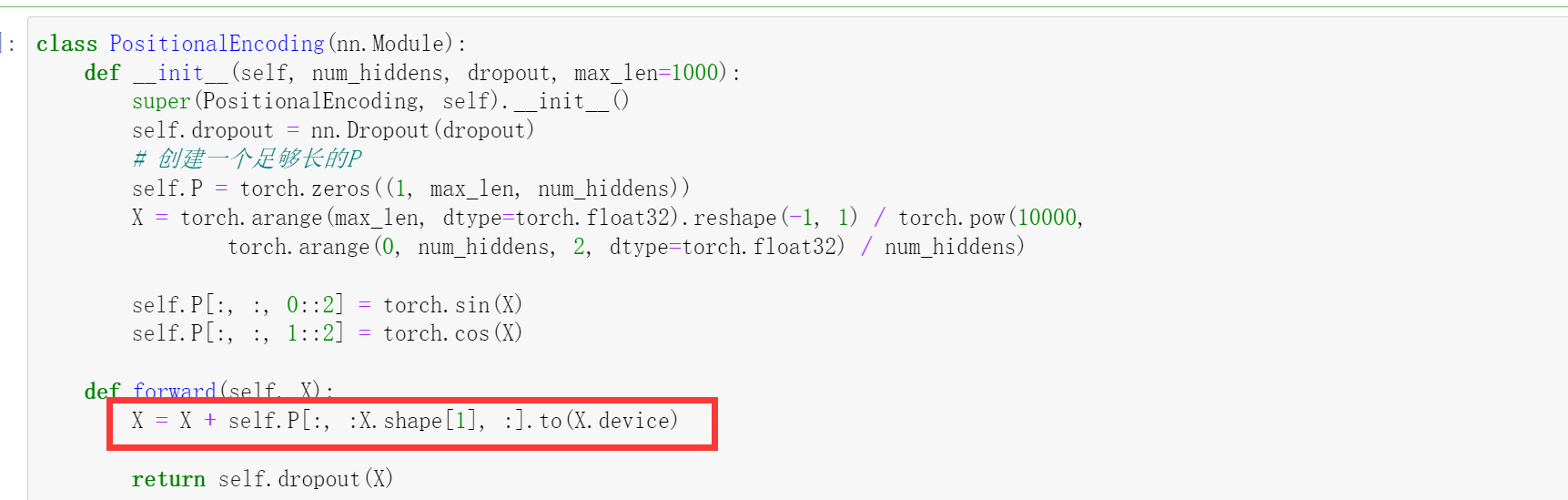
class PositionalEncoding(nn.Module):
def __init__(self, num_hiddens, dropout, max_len=1000):
super(PositionalEncoding, self).__init__()
self.dropout = nn.Dropout(dropout)
# 创建一个足够长的P
self.P = torch.zeros((1, max_len, num_hiddens))
X = torch.arange(max_len, dtype=torch.float32).reshape(
-1, 1) / torch.pow(
10000,
torch.arange(0, num_hiddens, 2, dtype=torch.float32) /
num_hiddens)
self.P[:, :, 0::2] = torch.sin(X)
self.P[:, :, 1::2] = torch.cos(X)
def forward(self, X):
X = X + self.P[:, :X.shape[1], :].to(X.device)
return self.dropout(X)
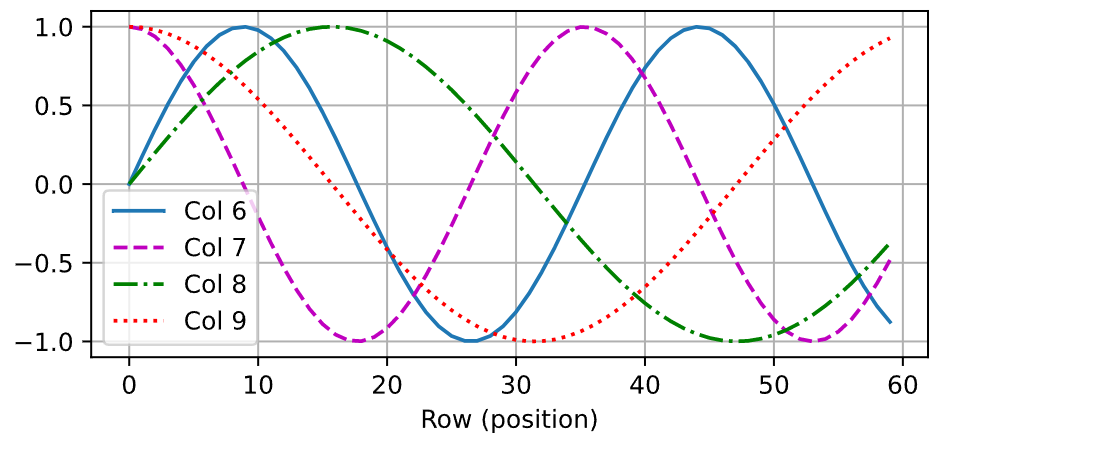
在位置嵌入矩阵P中,行代表词元在序列中的位置,列代表位置编码的不同维度。从下面的例子中可以看到位置嵌入矩阵的第6列和第7列的频率高于第8列和第9列。第6列和第7列之间的偏移量(第8列和第9列相同)是由于正弦函数和余弦函数的交替。
encoding_dim, num_steps = 32, 60
pos_encoding = PositionalEncoding(encoding_dim, 0)
pos_encoding.eval()
X = pos_encoding(torch.zeros((1, num_steps, encoding_dim)))
P = pos_encoding.P[:, :X.shape[1], :]
d2l.plot(torch.arange(num_steps), P[0, :, 6:10].T, xlabel='Row (position)',
figsize=(6, 2.5), legend=["Col %d" % d for d in torch.arange(6, 10)])
绝对位置信息
为了明白沿着编码维度单调降低的频率与绝对位置信息的关系,让我们打印出0, 1, . . . , 7的二进制表示形式。正如所看到的,每个数字、每两个数字和每四个数字上的比特值在第一个最低位、第二个最低位和第三个最低位上分别交替。
for i in range(8):
print(f'{i}的二进制是:{i:>03b}')
0 in binary is 000
1 in binary is 001
2 in binary is 010
3 in binary is 011
4 in binary is 100
5 in binary is 101
6 in binary is 110
7 in binary is 111
在二进制表示中,较高比特位的交替频率低于较低比特位,与下面的热图所示相似,只是位置编码通过使用
三角函数在编码维度上降低频率。由于输出是浮点数,因此此类连续表示比二进制表示法更节省空间。
相对位置信息
除了捕获绝对位置信息之外,上述的位置编码还允许模型学习得到输入序列中相对位置信息。这是因为对于任何确定的位置偏移,位置处的位置编码可以线性投影位置处的位置编码来表示。
这种投影的数学解释是,令,对于任何确定的位置偏移,任何一对
都可以线性投影到:
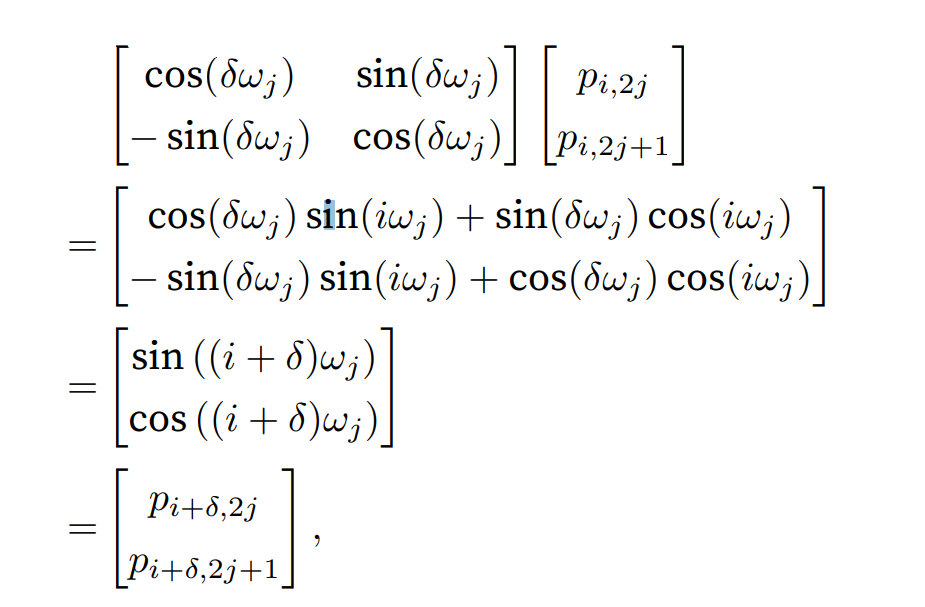
投影矩阵不依赖于任何位置的索引。
• 在自注意力中,查询、键和值都来自同一组输入。
• 卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计
算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
• 为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息
相信看完上面的还是有很多的疑惑:
QA
- 为什么需要位置编码?
因为对于transformer中的注意力机制而言,交换两个单词,并不会影响注意力的计算,也就是说这里的注意力是对单词位置不敏感的,而单词之间的位置信息往往是很重要的,因此考虑使用位置编码。 - 公式(三角函数位置编码)(转自)
transformer使用的位置编码。基本公式:
表示序列中第个单词,及是其的两个分量,也就是说,第个位置编码是由两部分构成的。假设句子长度为512,那么位置编码向量维度就是512×2。那么为什么会使用这种位置编码表示呢?首先三角函数有以下性质:
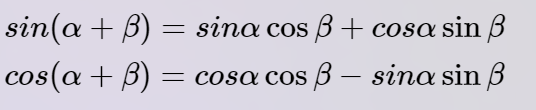
那么:
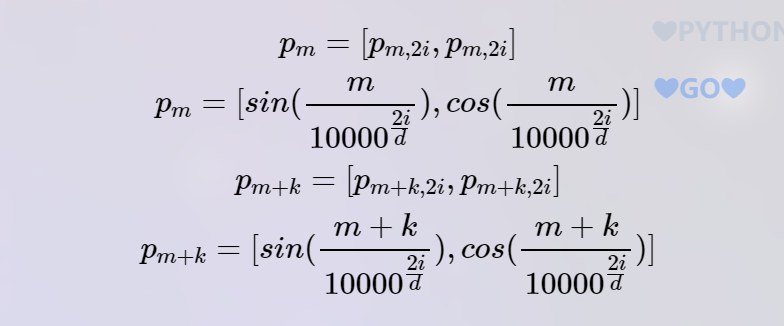
我们把记为a,则有:

也就是说第m+k个位置的位置编码可以由第m个位置表示。另有:
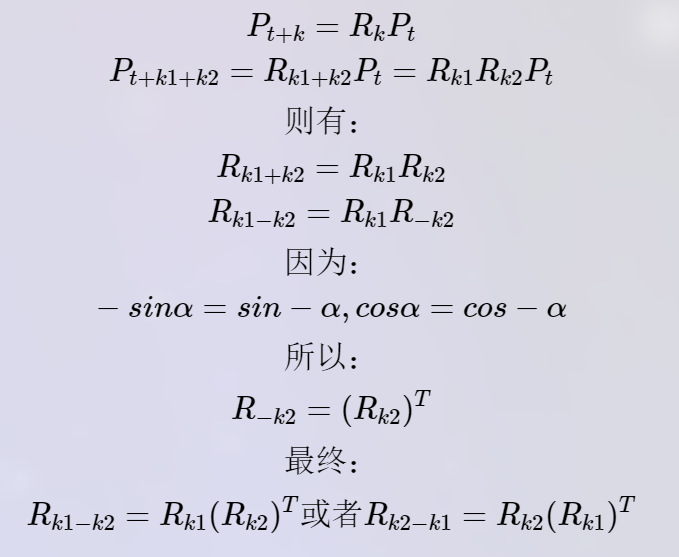
3. 为什么位置编码有效?
由于位置编码和词嵌入在相同的维度空间中,并且它们在模型的输入中被相加在一起,这使得模型可以在自注意力计算中考虑位置信息。
我们可以在这里看出来:
4. 位置编码是加上去的,为什么不拼接上去呢
拼接的话会扩大参数空间,占用内存增加,而且不易拟合,而且其实没有证据表明拼接就比加来的好
代码演示:
import numpy as np
import torch
def positional_encoding(seq_len, d_model):
# 创建一个形状为 (seq_len, 1) 的数组,其中的值为 [0, 1, 2, ... seq_len-1]
position = np.arange(seq_len)[:, np.newaxis]
# 计算除数,这里的除数将用于计算正弦和余弦的频率
div_term = np.exp(np.arange(0, d_model, 2) * -(np.log(10000.0) / d_model))
# 初始化位置编码矩阵为零
pe = np.zeros((seq_len, d_model))
# 对矩阵的偶数列(0,2,4...)进行正弦函数编码
pe[:, 0::2] = np.sin(position * div_term)
# 对矩阵的奇数列(1,3,5...)进行余弦函数编码
pe[:, 1::2] = np.cos(position * div_term)
# 返回位置编码矩阵,转换为 PyTorch 张量
return torch.tensor(pe, dtype=torch.float32)
# 使用示例
seq_len = 50 # 定义序列长度
d_model = 512 # 定义模型的嵌入维度
pe = positional_encoding(seq_len, d_model) # 获得位置编码
pe.shape
# torch.Size([50, 512])
其中还有相对位置编码:可以看看这个博客


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)