pytorch-多头注意力(维度分析)重要
多头注意力
在实践中,当给定相同的查询、键和值的集合时,我们希望模型可以基于相同的注意力机制学习到不同的行为,然后将不同的行为作为知识组合起来,捕获序列内各种范围的依赖关系(例如,短距离依赖和长距离依
赖关系)。因此,允许注意力机制组合使用查询、键和值的不同子空间表示(representation subspaces)可能是有益的。为此,与其只使用单独一个注意力汇聚,我们可以用独立学习得到的h组不同的线性投影(linear projections)来变换查询、键和值。然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。最后,将这h个注意力汇聚的输出拼接在一起,并且通过另一个可以学习的线性投影进行变换,以产生最终输出。这种设计被称为多头注意力(multihead attention)(Vaswani et al., 2017)。对于h个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。下图展示了使用全连接层来实现可学习的线性变换的多头注意力。

模型
在实现多头注意力之前,让我们用数学语言将这个模型形式化地描述出来。给定查询、键和值,每个注意力头的计算方法为:
其中,可学习的参数包括、和,以及代表注意力汇聚的函数f。f可以的加性注意力和缩放点积注意力。多头注意力的输出需要经过另一个线性转换,它对应着h个头连结后的结果,因此其可学习参数是 :

总结
多头注意力机制现在的使用是非常广泛的。为什么需要比较多的head呢?可以想成相关这件事情在做Self-attention的时候,就是用q去找相关的k,但是相关这件事情有很多种不同的形式,有很多种不同的定义,所以我们不能只有一个q,应该要有多个q,不同的q负责不同种类的相关性。
我们应在怎么做呢?首先对于这个我们分别乘两个矩阵变成和。这个可以理解为两种不同的相关性。之后q,k,v都要有两个:

用第一个head:

用第二个head:

将这两个接起来,然后通过一个trannsform,也就是乘上一个矩阵,得到传到下一层去。

Attention、Self-attention、Multi-headed Self-attenion

如上图所示,最底层的输入,表示输入的序列数据,比如,可以代表某个句子的第一个词所对应的向量。首先,通过嵌入层(可选)将它们进行初步的embedding,得到。然后,使用三个矩阵分别与之相乘,得到。上图显示了与输入所对应的输出是如何得到的。即:
- 利用分别与计算向量点积,得到(从数值上看,还不一定是0-1之间的数,还需经过softmax处理);
- 将输入softmax层,从而得到均在0-1之间的注意力权重值:。分别于对应位置上的相乘。然后求和,这样便得到了与输入的所对应的输出。
同样地,与输入的所对应的输出,也根据类似过程获得,只是此时是利用与对应的分别与计算向量点积,主要过程如下图所示:

其他输入的计算过程以此类推,如下图所示:


对于输入的序列来说,与RNN/LSTM的处理过程不同,Self-attention机制能够并行对进行计算,这大大提高了对特征进行提取(即获得)的速度。结合上述Self-attention的计算过程,并行计算的原理如下图所示:

由上图可以看到,通过对输入分别乘以矩阵,我们便得到了三个矩阵,然后通过后续计算得到注意力矩阵,进而得到输出。
对于在Transformer及BERT模型中用到的Multi-headed Self-attention结构与之略有差异,具体体现在:如果将前文中得到的整体看做一个“头”,则“多头”即指对于特定的 来说,需要用多组与之相乘,进而得到多组。如下图所示:
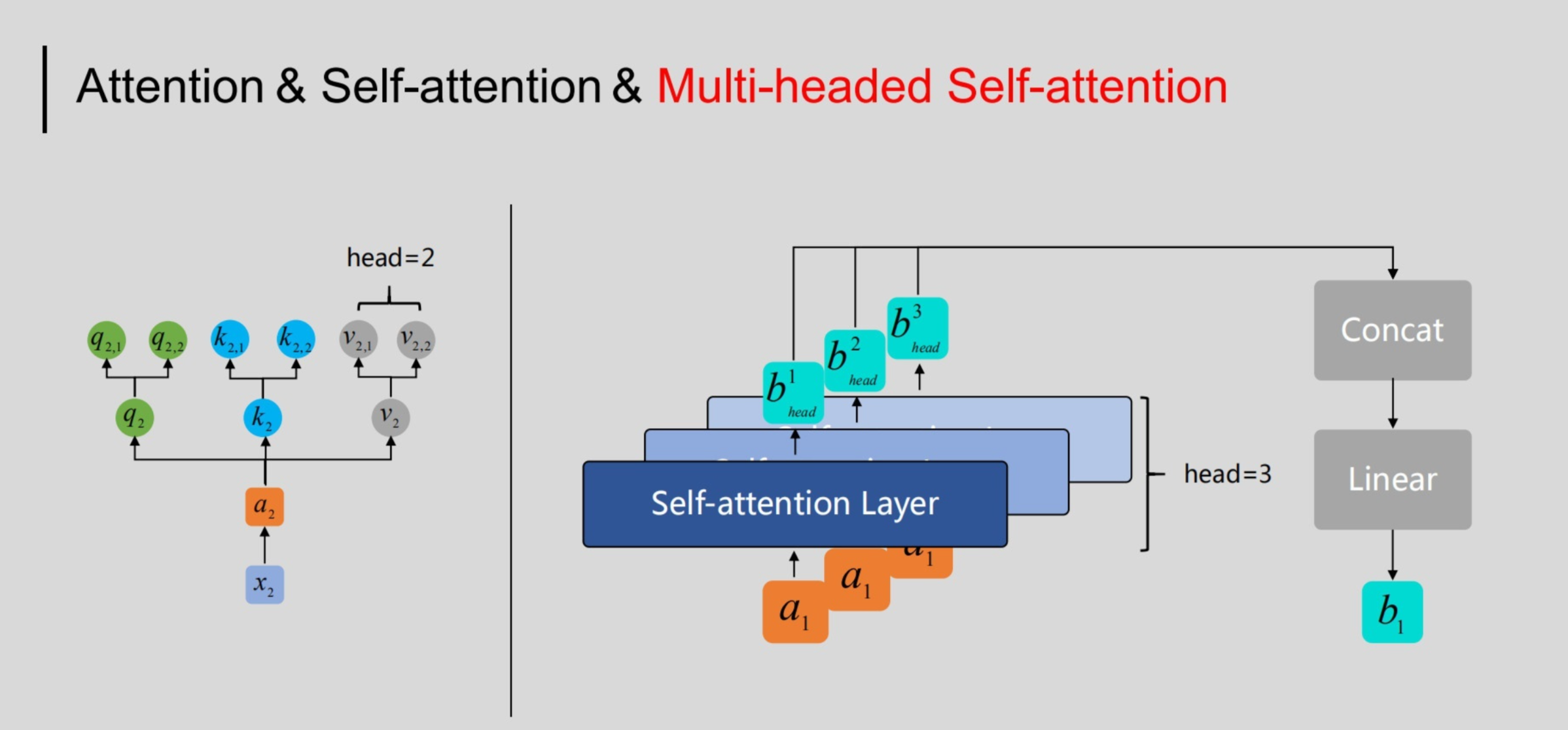
如上图所示,以右侧示意图中输入的为例,通过多头(这里取head=3)机制得到了三个输出,为了获得与对应的输出,在Multi-headed Self-attention中,我们会将这里得到的进行拼接(向量首尾相连),然后通过线性转换(即不含非线性激活层的单层全连接神经网络)得到。对于序列中的其他输入也是同样的处理过程,且它们共享这些网络的参数。
注意其中是可以学习的参数。
实现
在实现过程中通常选择缩放点积注意力作为每一个注意力头。为了避免计算代价和参数代价的大幅增长,我
们设定。值得注意的是,如果将查询、键和值的线性变换的输出数量设置为,则可以并行计算h个头。在下面的实现中,是通过参数num_hiddens指定的。
import math
import torch
from torch import nn
from d2l import torch as d2l
注意这里的维度变化是为了增加并行性。
#@save
class MultiHeadAttention(nn.Module):
"""多头注意力"""
def __init__(self, key_size, query_size, value_size, num_hiddens,
num_heads, dropout, bias=False, **kwargs):
super(MultiHeadAttention, self).__init__(**kwargs)
self.num_heads = num_heads
self.attention = d2l.DotProductAttention(dropout)
self.W_q = nn.Linear(query_size, num_hiddens, bias=bias)
self.W_k = nn.Linear(key_size, num_hiddens, bias=bias)
self.W_v = nn.Linear(value_size, num_hiddens, bias=bias)
self.W_o = nn.Linear(num_hiddens, num_hiddens, bias=bias)
def forward(self, queries, keys, values, valid_lens):
# queries,keys,values的形状:
# (batch_size,查询或者“键-值”对的个数,num_hiddens)
# valid_lens 的形状:
# (batch_size,)或(batch_size,查询的个数)
# 经过变换后,输出的queries,keys,values 的形状:
# (batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
# print(queries.shape,keys.shape,values.shape)
queries = transpose_qkv(self.W_q(queries), self.num_heads)
keys = transpose_qkv(self.W_k(keys), self.num_heads)
values = transpose_qkv(self.W_v(values), self.num_heads)
# print(queries.shape,keys.shape,values.shape)
if valid_lens is not None:
# 在轴0,将第一项(标量或者矢量)复制num_heads次,
# 然后如此复制第二项,然后诸如此类。
valid_lens = torch.repeat_interleave(
valid_lens, repeats=self.num_heads, dim=0)
# output的形状:(batch_size*num_heads,查询的个数,
# num_hiddens/num_heads)
output = self.attention(queries, keys, values, valid_lens)
# output_concat的形状:(batch_size,查询的个数,num_hiddens)
output_concat = transpose_output(output, self.num_heads)
return self.W_o(output_concat)
为了能够使多个头并行计算,上面的MultiHeadAttention类将使用下面定义的两个转置函数。具体来说,transpose_output函数反转了transpose_qkv函数的操作。
#@save
def transpose_qkv(X, num_heads):
"""为了多注意力头的并行计算而变换形状"""
# 输入X的形状:(batch_size,查询或者“键-值”对的个数,num_hiddens)
# 输出X的形状:(batch_size,查询或者“键-值”对的个数,num_heads,num_hiddens/num_heads)
X = X.reshape(X.shape[0], X.shape[1], num_heads, -1)
# 输出X的形状:(batch_size,num_heads,查询或者“键-值”对的个数,num_hiddens/num_heads)
X = X.permute(0, 2, 1, 3)
# 最终输出的形状:(batch_size*num_heads,查询或者“键-值”对的个数,
# num_hiddens/num_heads)
return X.reshape(-1, X.shape[2], X.shape[3])
#@save
def transpose_output(X, num_heads):
"""逆转transpose_qkv函数的操作"""
X = X.reshape(-1, num_heads, X.shape[1], X.shape[2])
X = X.permute(0, 2, 1, 3)
return X.reshape(X.shape[0], X.shape[1], -1)
下面使用键和值相同的小例子来测试我们编写的MultiHeadAttention类。多头注意力输出的形状是(batch_size,num_queries,num_hiddens)。
num_hiddens, num_heads = 100, 5
attention = MultiHeadAttention(num_hiddens, num_hiddens, num_hiddens,
num_hiddens, num_heads, 0.5)
attention.eval()
MultiHeadAttention(
(attention): DotProductAttention(
(dropout): Dropout(p=0.5, inplace=False)
)
(W_q): Linear(in_features=100, out_features=100, bias=False)
(W_k): Linear(in_features=100, out_features=100, bias=False)
(W_v): Linear(in_features=100, out_features=100, bias=False)
(W_o): Linear(in_features=100, out_features=100, bias=False)
)
batch_size, num_queries = 2, 4
num_kvpairs, valid_lens = 6, torch.tensor([3, 2])
X = torch.ones((batch_size, num_queries, num_hiddens))
Y = torch.ones((batch_size, num_kvpairs, num_hiddens))
attention(X, Y, Y, valid_lens).shape
queries,keys,values的维度
torch.Size([2, 4, 100]) torch.Size([2, 6, 100]) torch.Size([2, 6, 100])
queries,keys,values的维度
torch.Size([10, 4, 20]) torch.Size([10, 6, 20]) torch.Size([10, 6, 20])
torch.Size([2, 4, 100])
这个最后输出的维度为
• 多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
• 基于适当的张量操作,可以实现多头注意力的并行计算。
Multihead Attention中维度变化分析

1.Input: Encoder Multihead Attention 输入的 query, key, value 是相同的,都是经过了word embedding和pos embedding之后的source sentence,其维度为。由于有num_heads个头需要并行计算,首先query, key, value分别经过一个线性变换,再将数据split给num_heads个头分别做注意力查询,即:
query:
key:
value:
由于query, key, value 是相同的,因此有 sr_len_q = sr_len_k = sr_len_v
2.DotProductAttention: num_heads 个头的计算是并行的,即:

Encoder Multihead Attention中在计算softmax之前对 key 进行了 mask,目的是消除 padding 的影响。事实上,padding不仅对key有影响,对query也有影响,但在实际代码中mask仅针对key,而没有针对query。其实最原始代码是既有key mask,也有query mask的,但后来作者将query mask删去了,因为在最后计算 loss 的时候对 padding 位置的 loss 进行mask,也可达到相同的效果。
假设 batch_size = num_heads = 1,sr_len_q = sr_len_k = 6,source sentence 的最后两个位置是padding,那么Encoder Multihead Attention 中的 mask 为:
即只对 key 的 padding 位置进行了 mask
3.Output: 需要将上面输出的num_heads个头的结果堆叠之后,再做一个线性变换:
可以看一下这个图:



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 上周热点回顾(3.3-3.9)