self attention-注意力评分函数
上节使用了高斯核来对查询和键之间的关系建模。高斯核指数部分可以视为注意力评分函数(attention scoring function),简称评分函数(scoring function),然后把这个函数的输出结果输入到softmax函数中进行运算。通过上述步骤,将得到与键对应的值的概率分布(即注意力权重)。最后,注意力汇聚的输出就是基于这些注意力权重的值的加权和。
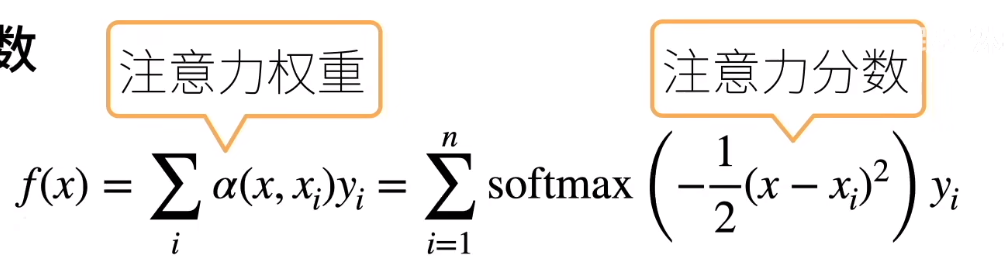
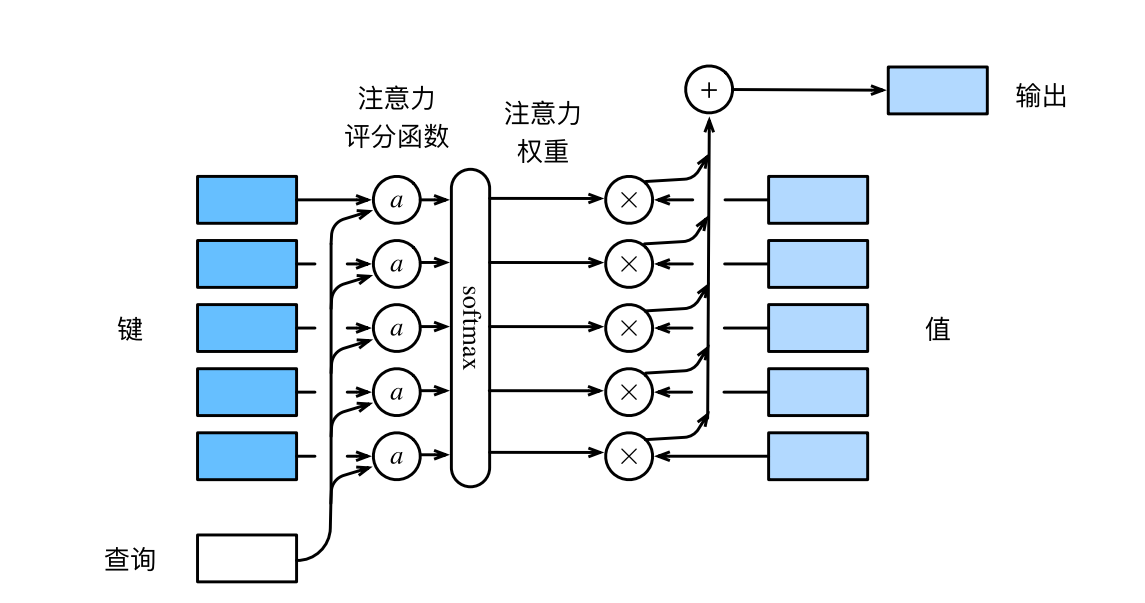
下图说明了如何将注意力汇聚的输出计算成为值的加权和,其中a表示注意力评分函数。由于注意力权重是概率分布,因此加权和其本质上是加权平均值。
用数学语言描述,假设有一个查询和个“键-值”对,其中。
注意力汇聚函数f就被表示成值的加权和:
其中查询q和键ki的注意力权重(标量)是通过注意力评分函数a将两个向量映射成标量,再经过softmax运算得到的:
正如上图所示,选择不同的注意力评分函数会导致不同的注意力汇聚操作。本文将介绍两个流行的评分函数,稍后将用他们来实现更复杂的注意力机制。
self-attention(李宏毅)
我们知道self-attention的运作方式是会考虑一整个sequence的信息,输入几个vector(向量)就输出几个vector。用这种方法,全连接层就不是只考虑一个非常小的范围或者一个小的window,而是考虑一整个sequence的信息,再来决定现在应该要输出什么样的结果,这就是self attention。
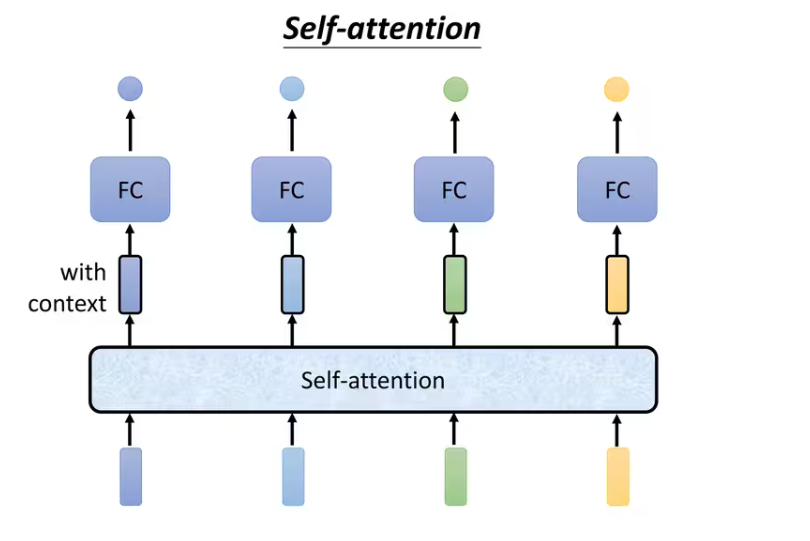
并且self attention不是只能用一次,可以叠加很多次:
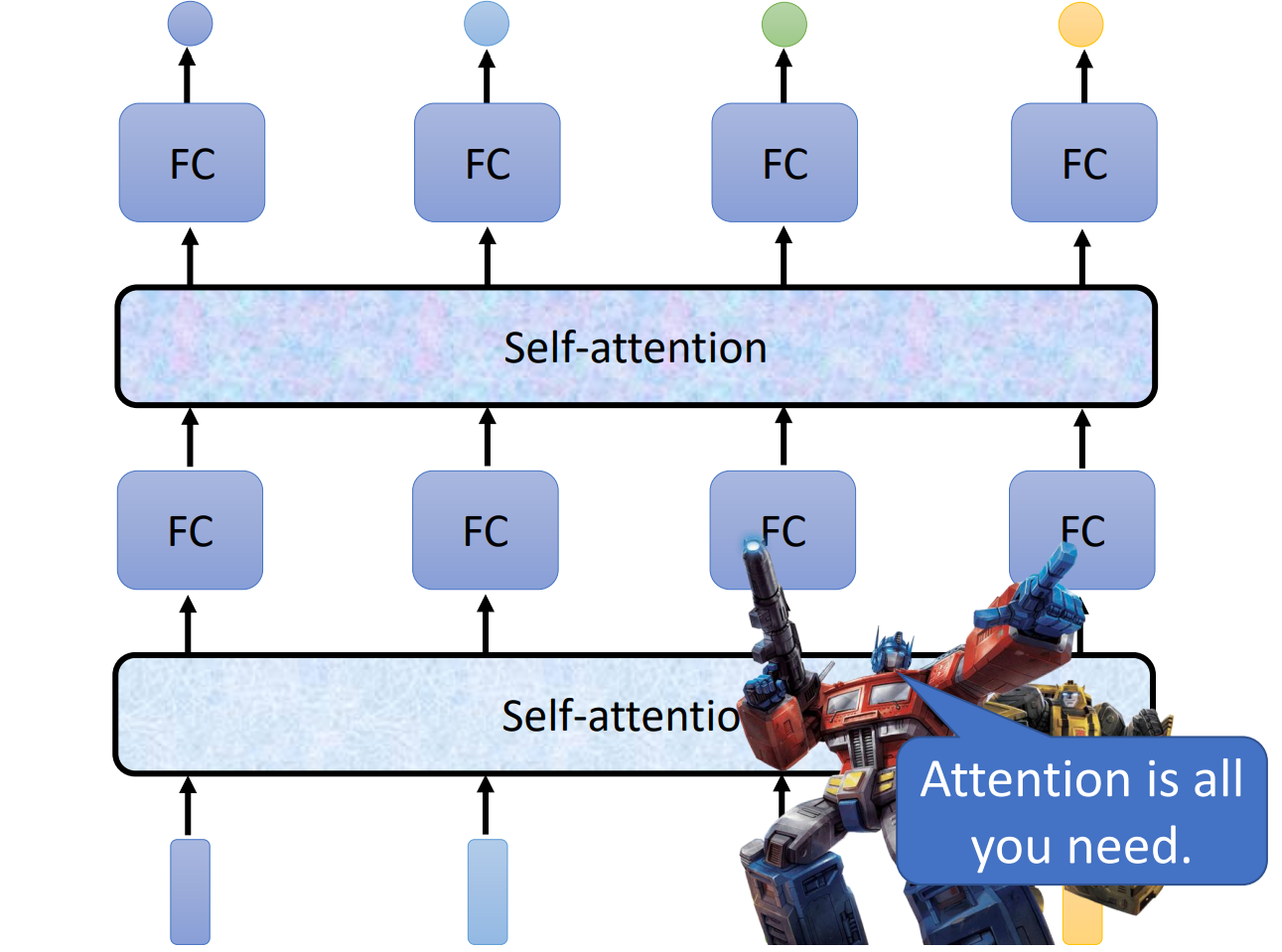
关于self attention最知名的文章就是《attention is all you need》,在文章中提出了transformer这样的network架构,transformer就是变形金刚,transformer里面最重要的module就是self attention,就是变形金刚的火种源。

self attention的输入就是一串vector,这个向量可能是整个网络的输入,也可能是hidden layer的输出,这里没用x而是用a表示,代表它有可能是前面已经做过一些处理,即隐藏层的输出。每个b都是考虑了所有a以后才生产出来的。
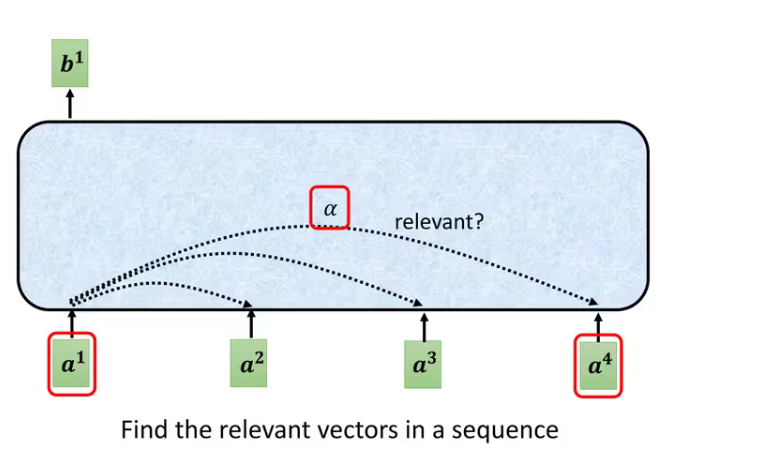
说明怎么产生向量:
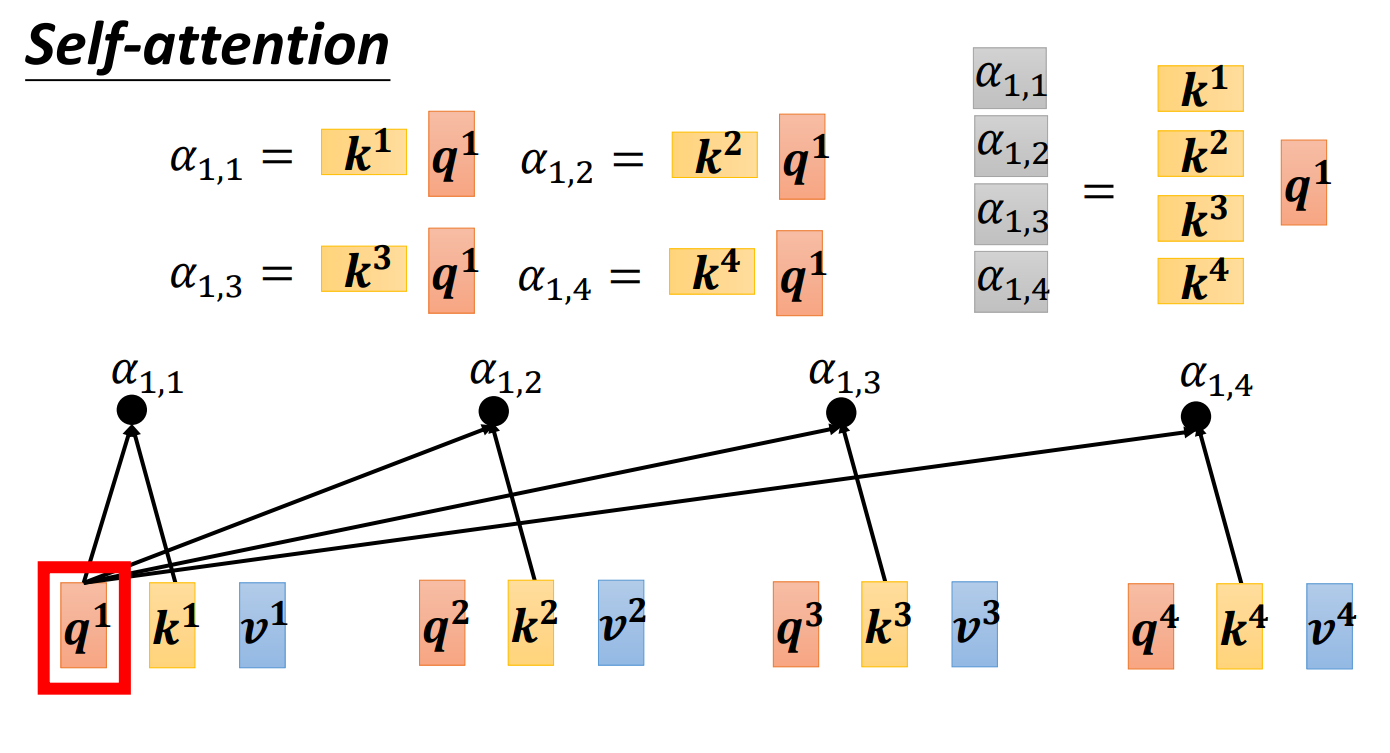
1、根据找出这个sequence里面相关的其他向量。
例如:每一个向量跟的关联程度用数值来表示,那么self attention module怎么自动决定两个向量之间的关联性呢?那么就需要一个计算attention的模组拿两个向量作为输入,直接输入α的数值。那怎么计算α的数值呢?有很多做法,比较常见的做法有两种
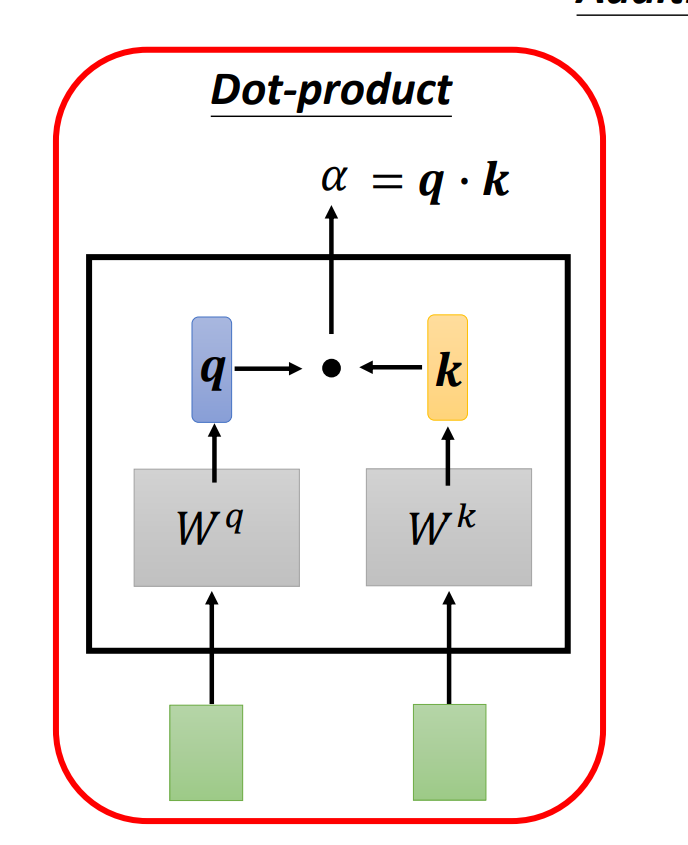
(1) Dot-product(点积)︰最常用的方法,且后续讨论中使用的方法,也是用在transformer里面的方法。
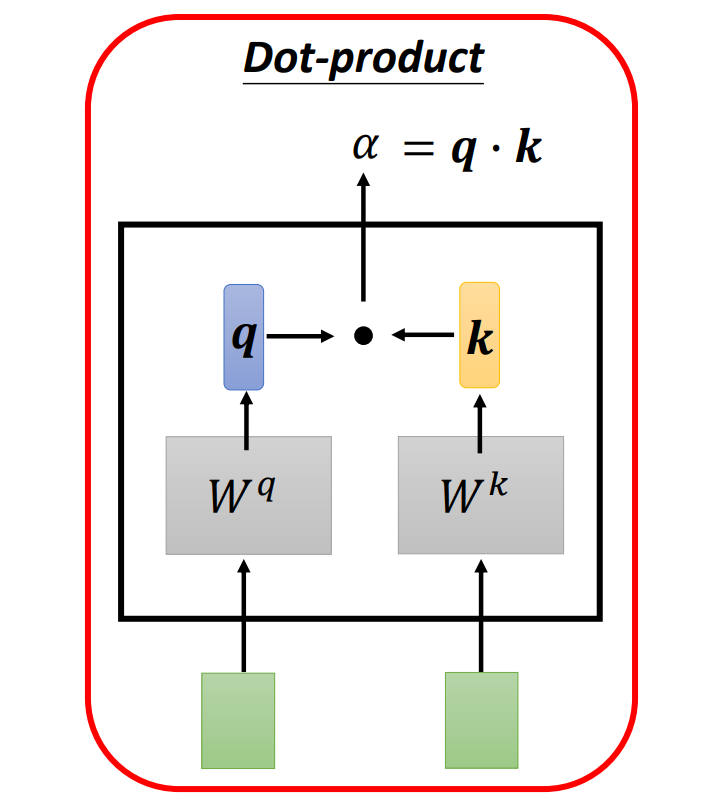
把输入的两个向量分别乘上两个不同的矩阵,得到、两个向量,再把和做点积,得到。
(2) Additive(加性模型)
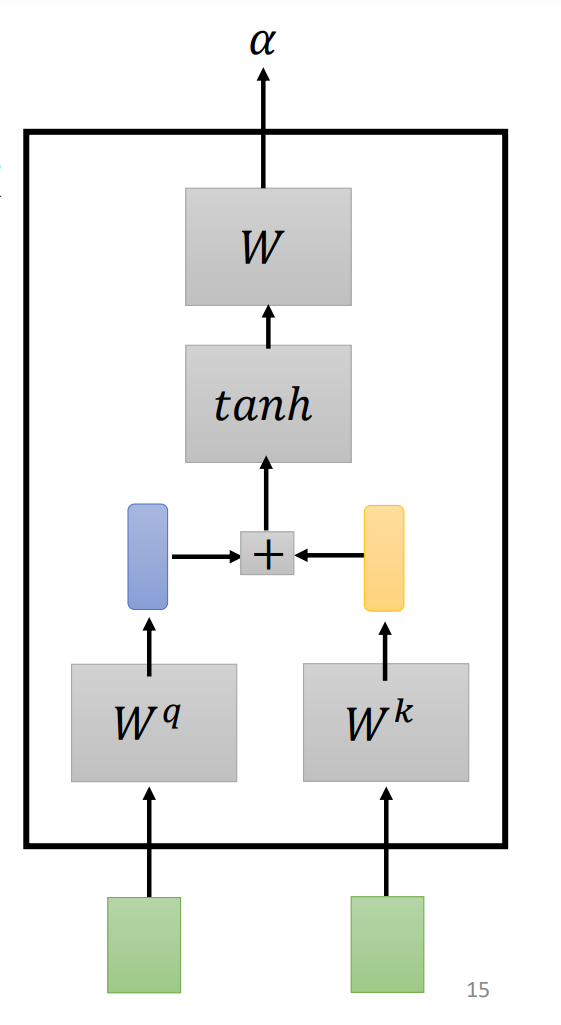
把输入的两个向量分别乘上两个不同的矩阵,得到、两个向量,再把和串起来,丢到activation function中,再通过一个transform得到。
(3) 缩放点积模型
2、怎么把上面生成的套用在self attention里面
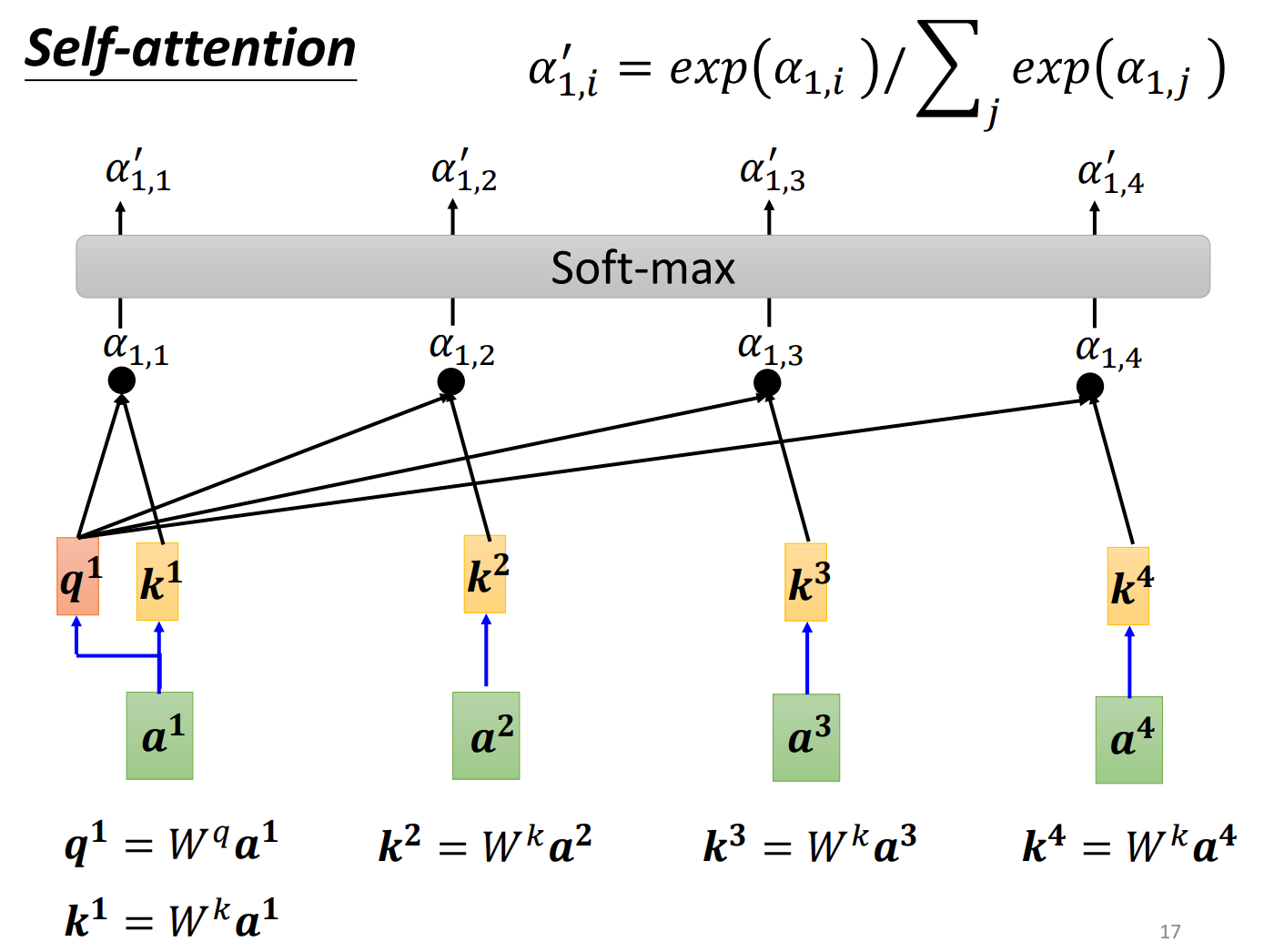
a也叫做attention score(分数)。
计算出与每一个向量的关联性以后,会做一个softmax,这里的softmax与分类的softmax是一样的,把全部乘上exp,然后再把exp的值全部加起来做normalize,得到。这里不一定要用softmax,用其他的也可以,有人试过用relu比softmax效果还好,softmax是最常见的了。
3、根据上面生成的,去抽取出这个sequence里面重要的资讯,即怎么生成b?
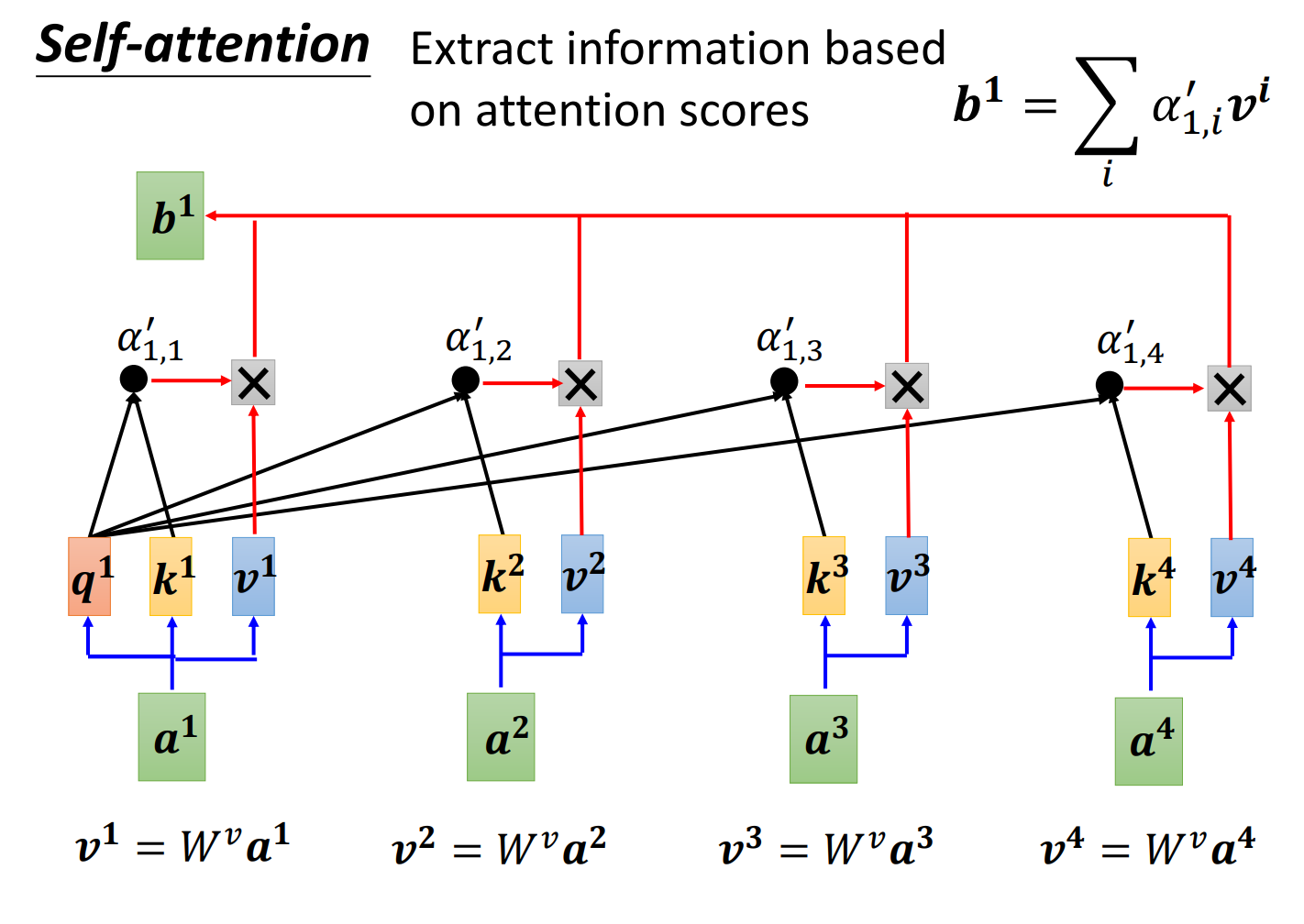
把每一个向量乘以,得到新的向量,把乘上attention的分数,然后再把所有相乘后的结果加起来,得到。
矩阵乘法角度讲self-attention怎么运作:
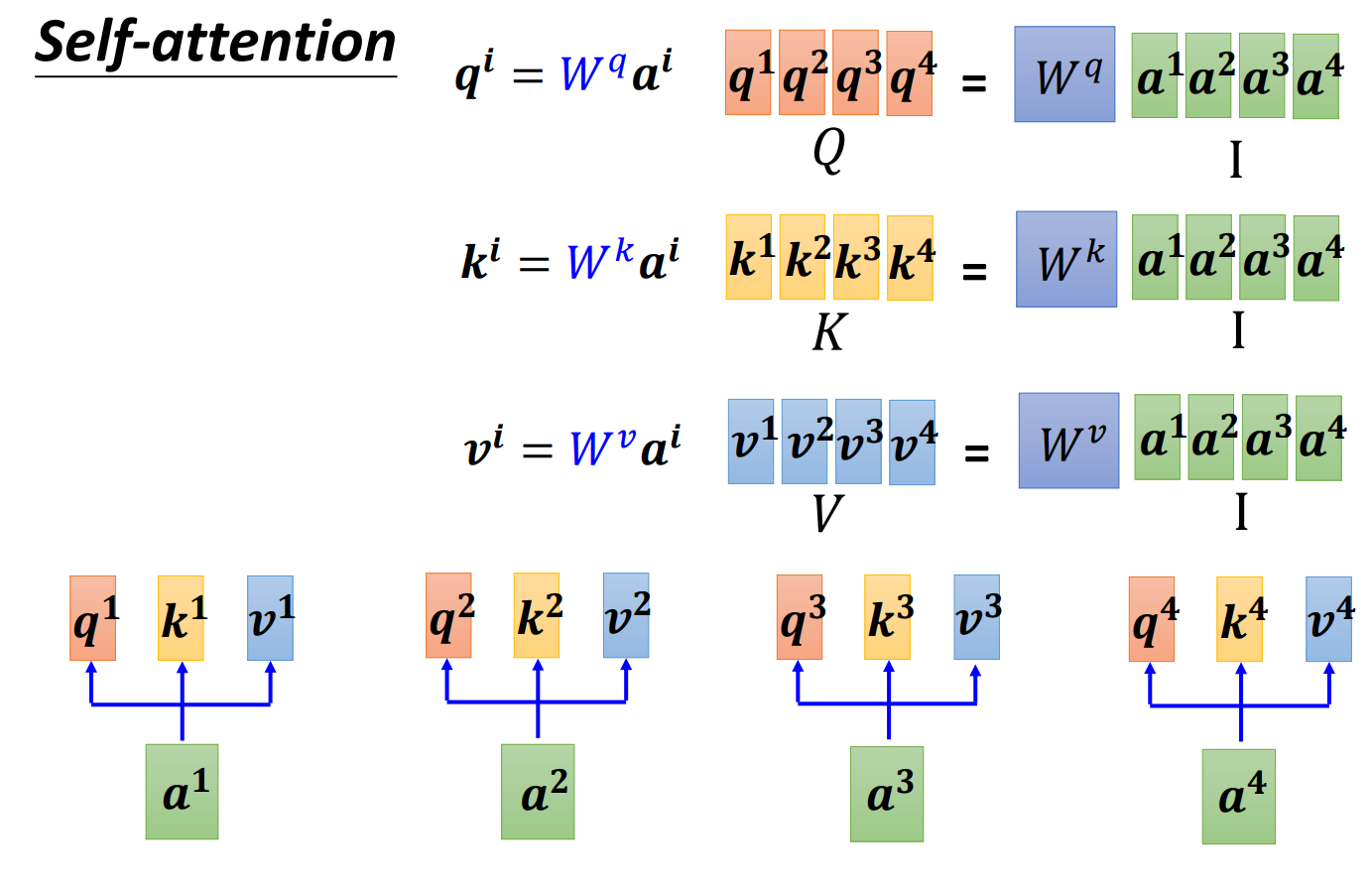
将矩阵拼起来看成矩阵I。
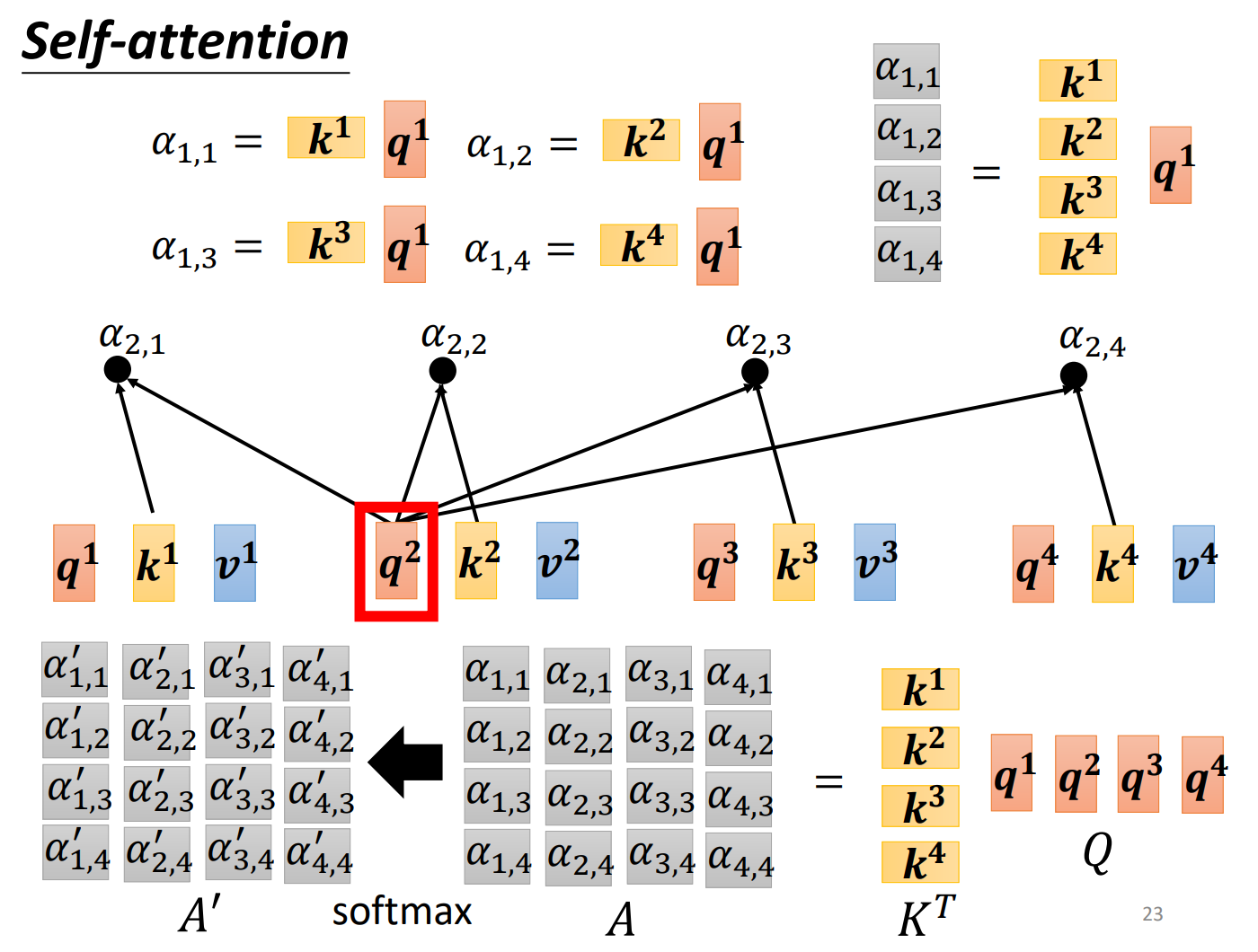
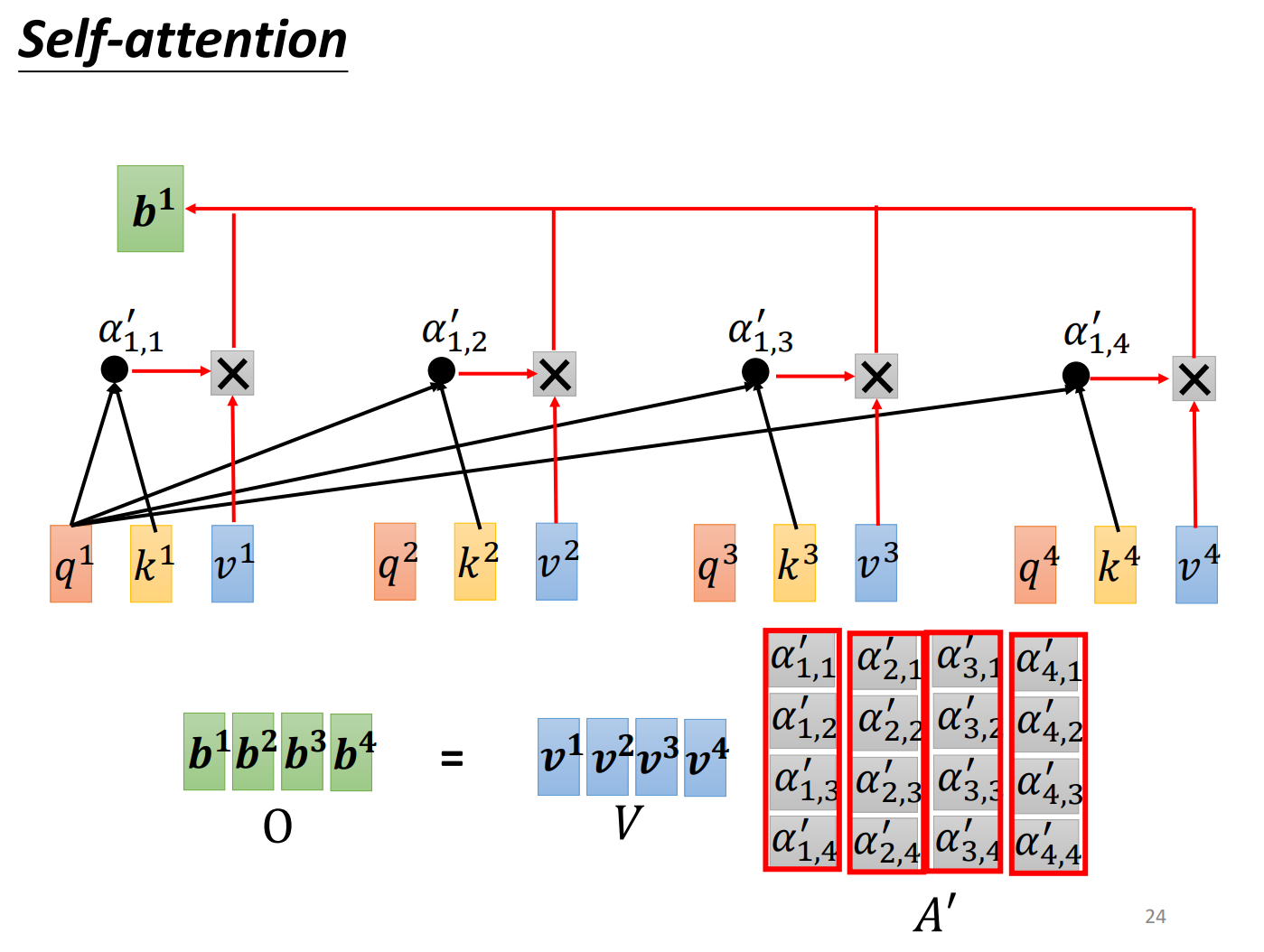
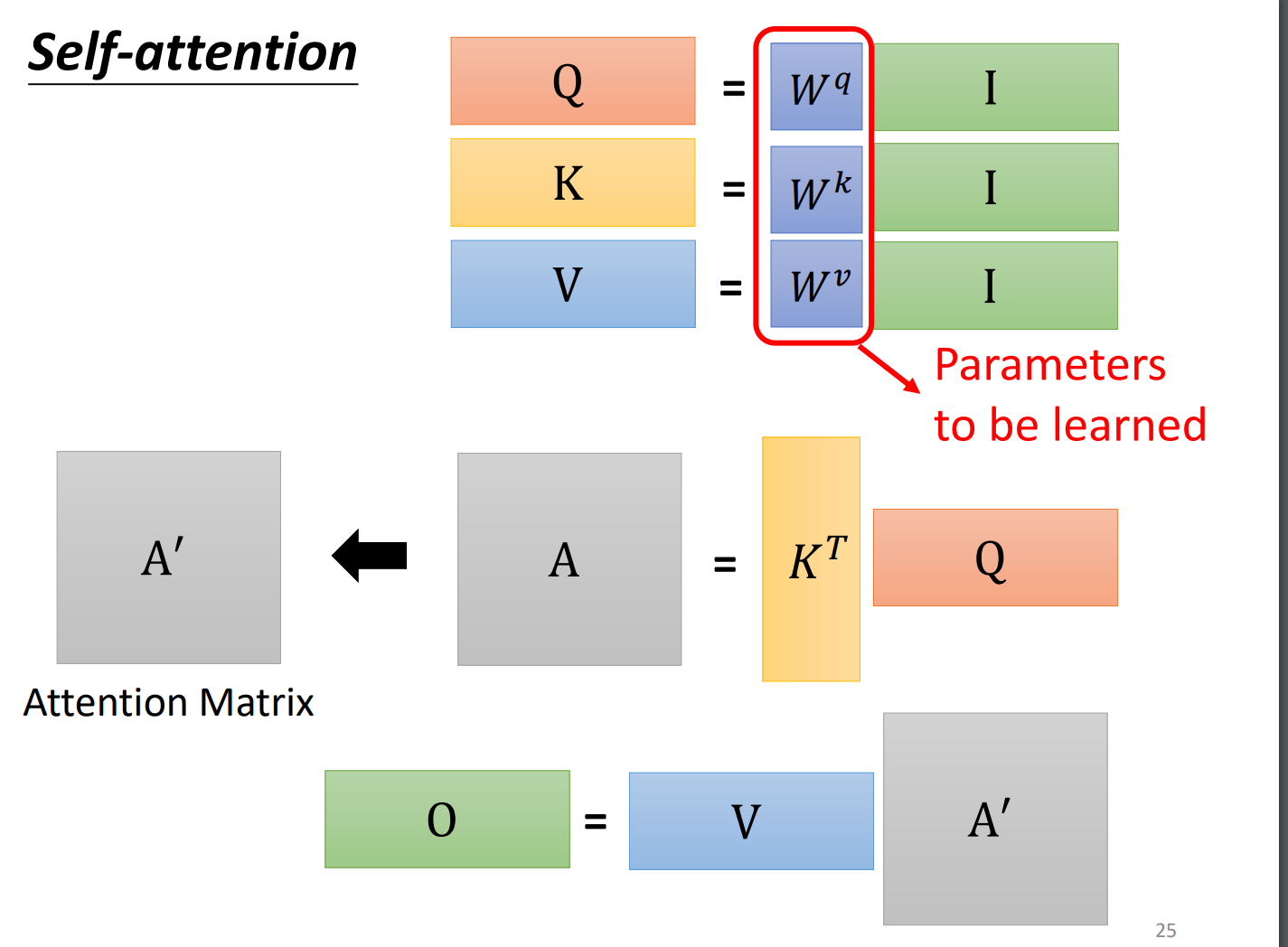
这里只有是未知的,是需要我们的训练资料计算出来。
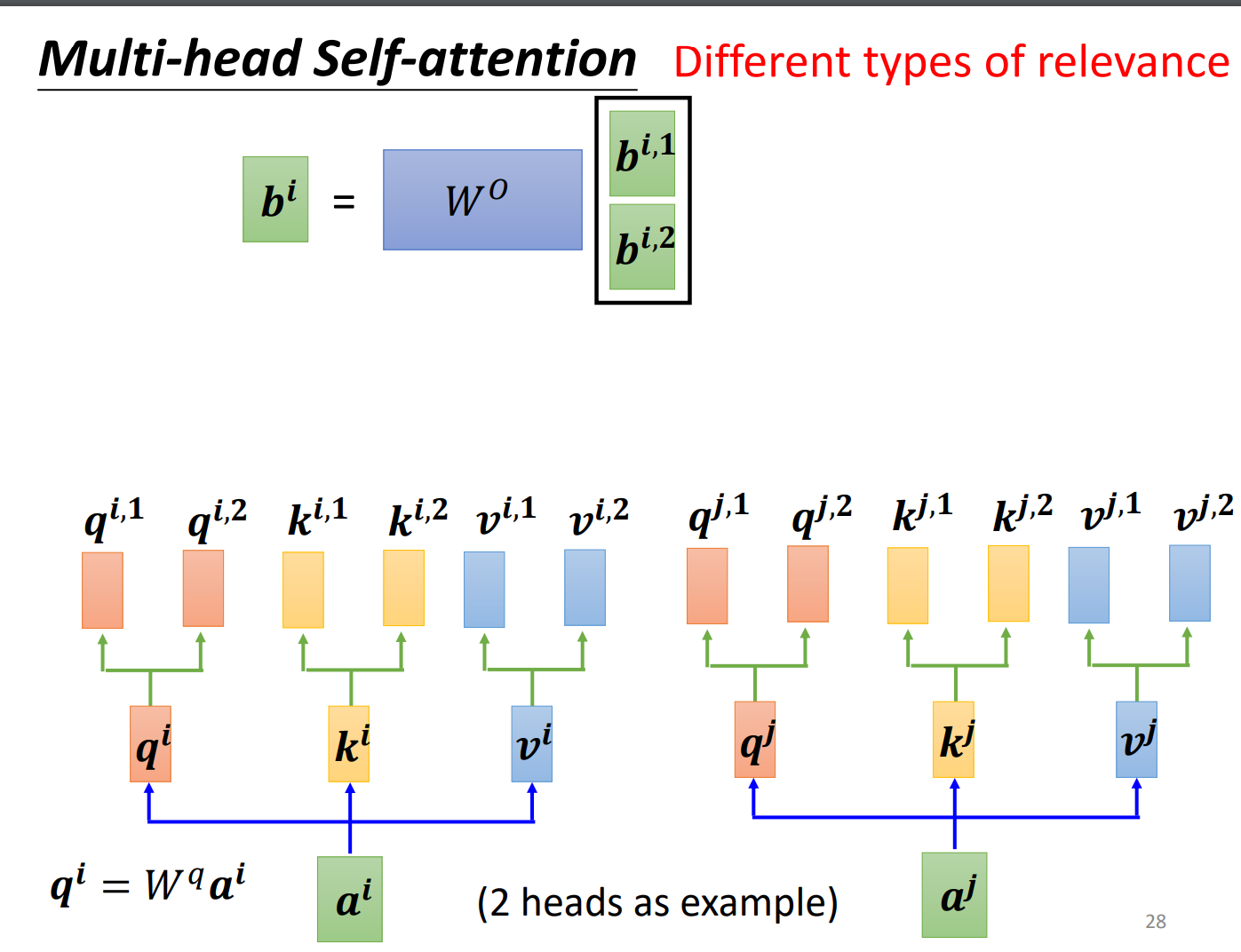
进阶版本Multi-head Self-attention
其现在的使用是非常广泛的。为什么需要比较多的head呢?可以想成相关这件事情在做Self-attention的时候,就是用q去找相关的k,但是相关这件事情有很多种不同的形式,有很多种不同的定义,所以我们不能只有一个q,应该要有多个q,不同的q负责不同种类的相关性。
用第一个head:
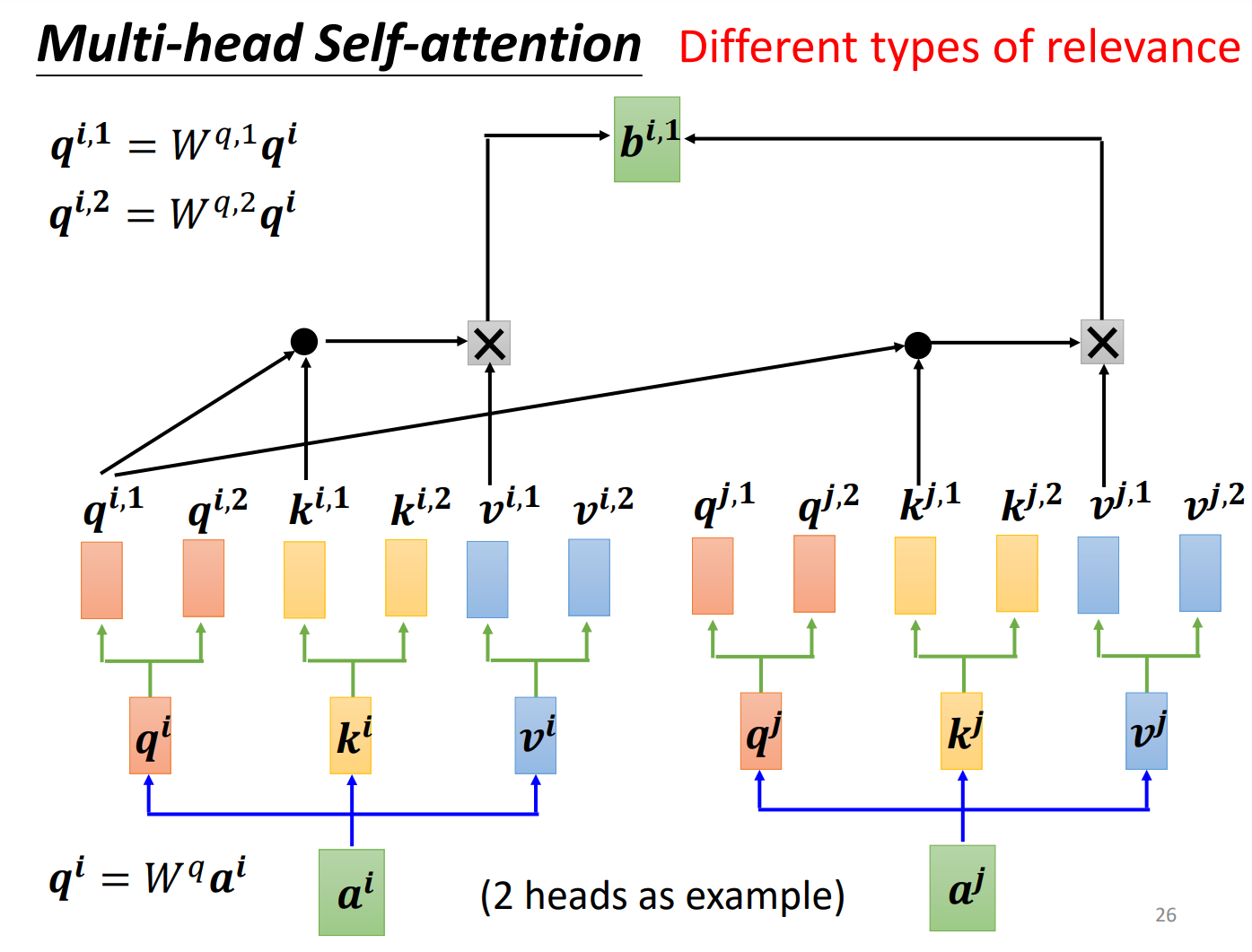
用第二个head:
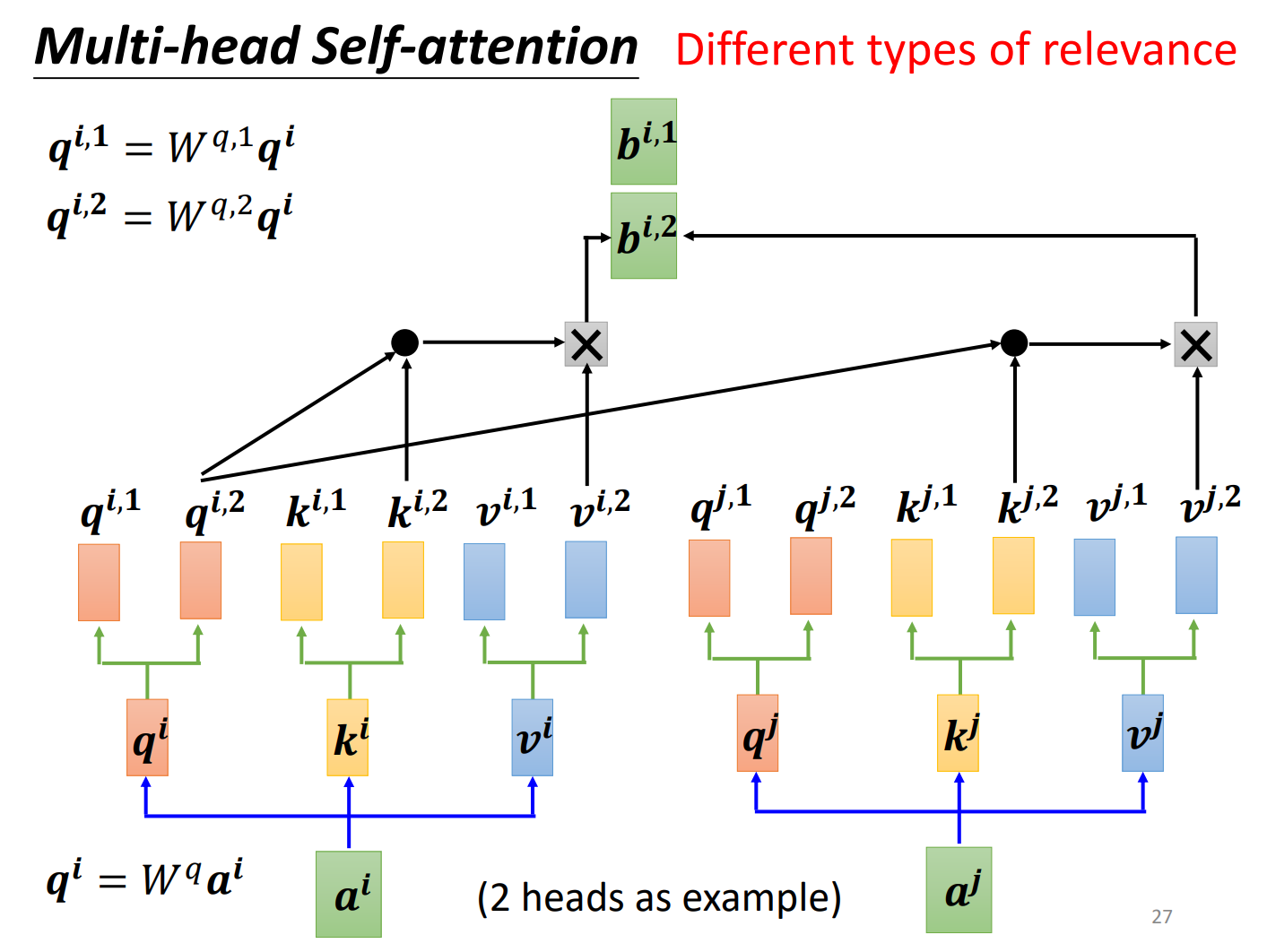
再把和接起来,再通过一个transform,也就是乘上一个矩阵,得到,送到下一层。
Self-attention V.S. RNN
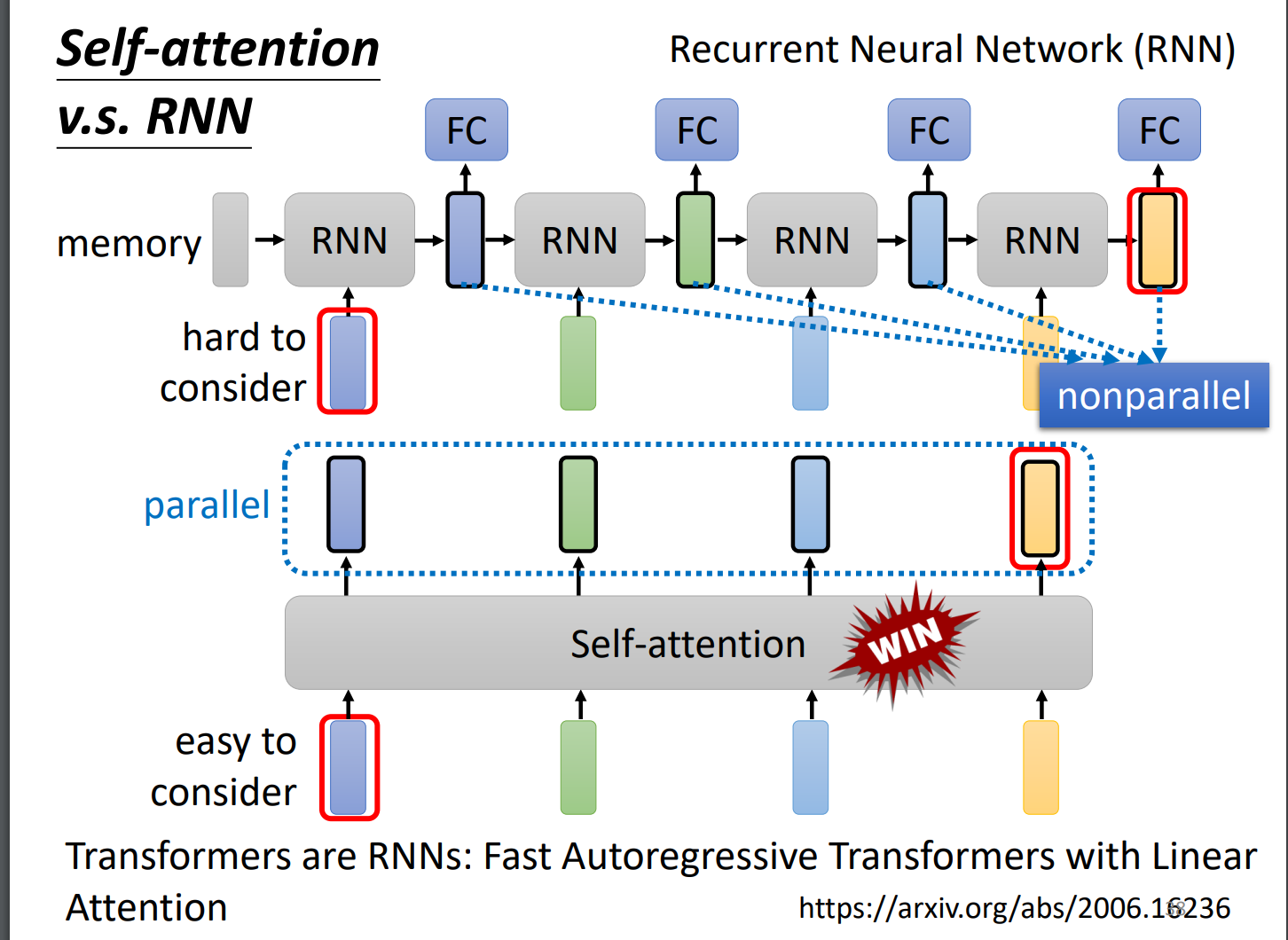
RNN是不能平行化的。
两种注意力评分函数
掩蔽softmax操作
正如上面提到的,softmax操作用于输出一个概率分布作为注意力权重。在某些情况下,并非所有的值都应该被纳入到注意力汇聚中。某些文本序列被填充了没有意义的特殊词元。为了仅将有意义的词元作为值来获取注意力汇聚,可以指定一个有效序列长度(即词元的个数),
以便在计算softmax时过滤掉超出指定范围的位置。下面的masked_softmax函数实现了这样的掩蔽softmax操作(masked softmax operation),其中任何超出有效长度的位置都被掩蔽并置为0。
def masked_softmax(X, valid_lens):
"""通过在最后一个轴上掩蔽元素来执行softmax操作"""
# X:3D张量,valid_lens:1D或2D张量
if valid_lens is None:
return nn.functional.softmax(X, dim=-1)
else:
shape = X.shape
if valid_lens.dim() == 1:
valid_lens = torch.repeat_interleave(valid_lens, shape[1])
else:
valid_lens = valid_lens.reshape(-1)
# 最后一轴上被掩蔽的元素使用一个非常大的负值替换,从而其softmax输出为0
X = d2l.sequence_mask(X.reshape(-1, shape[-1]), valid_lens,
value=-1e6)
return nn.functional.softmax(X.reshape(shape), dim=-1)
为了演示此函数是如何工作的,考虑由两个2 × 4矩阵表示的样本,这两个样本的有效长度分别为2和3。经过掩蔽softmax操作,超出有效长度的值都被掩蔽为0。
masked_softmax(torch.rand(2, 2, 4), torch.tensor([2, 3]))

同样,也可以使用二维张量,为矩阵样本中的每一行指定有效长度
masked_softmax(torch.rand(2, 2, 4), torch.tensor([[1, 3], [2, 4]]))

加性注意力
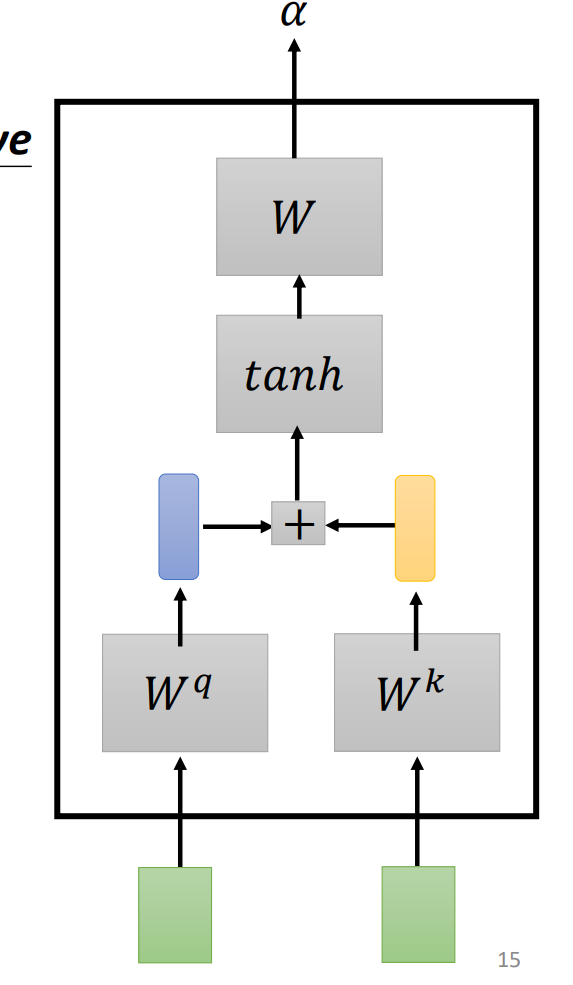
一般来说,当查询和键是不同长度的矢量时,可以使用加性注意力作为评分函数。给定查询和键,加性注意力(additive attention)的评分函数为
其中可学习的参数是、和。,将查询和键连结起来后输入到一个多层感知机(MLP)中,感知机包含一个隐藏层,其隐藏单元数是一个超参数h。通过使用tanh作为激活函数,并且禁用偏置项。
class AdditiveAttention(nn.Module):
"""加性注意力"""
def __init__(self, key_size, query_size, num_hiddens, dropout, **kwargs):
super(AdditiveAttention, self).__init__(**kwargs)
self.W_k = nn.Linear(key_size, num_hiddens, bias=False)
self.W_q = nn.Linear(query_size, num_hiddens, bias=False)
self.w_v = nn.Linear(num_hiddens, 1, bias=False)
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens):
queries, keys = self.W_q(queries), self.W_k(keys)
# 在维度扩展后,
# queries的形状:(batch_size,查询的个数,1,num_hidden)
# key的形状:(batch_size,1,“键-值”对的个数,num_hiddens)
# 使用广播方式进行求和
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
# self.w_v仅有一个输出,因此从形状中移除最后那个维度。
# scores的形状:(batch_size,查询的个数,“键-值”对的个数)
scores = self.w_v(features).squeeze(-1)
self.attention_weights = masked_softmax(scores, valid_lens)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
return torch.bmm(self.dropout(self.attention_weights), values)
用一个小例子来演示上面的AdditiveAttention类,其中查询、键和值的形状为(批量大小,步数或词元序列长度,特征大小),实际输出为(2, 1, 20)、(2, 10, 2)和(2,10, 4)。注意力汇聚输出的形状为(批量大小,查询的步数,值的维度)。
queries, keys = torch.normal(0, 1, (2, 1, 20)), torch.ones((2, 10, 2))
values = torch.arange(40, dtype=torch.float32).reshape(1, 10,
4).repeat(2, 1, 1)
print(queries.shape,keys.shape,values.shape)
valid_lens = torch.tensor([2, 6])
attention = AdditiveAttention(key_size=2, query_size=20, num_hiddens=8,
dropout=0.1)
attention.eval()
attention(queries, keys, values, valid_lens)
torch.Size([2, 1, 20]) torch.Size([2, 10, 2]) torch.Size([2, 10, 4])
tensor([[[ 2.0000, 3.0000, 4.0000, 5.0000]],
[[10.0000, 11.0000, 12.0000, 13.0000]]], grad_fn=<BmmBackward0>)

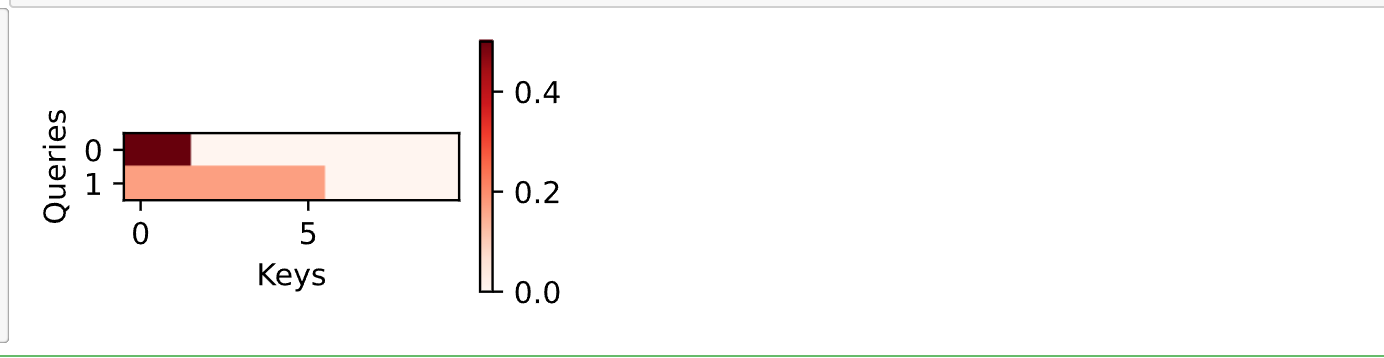
尽管加性注意力包含了可学习的参数,但由于本例子中每个键都是相同的,所以注意力权重是均匀的,由指定的有效长度决定。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
缩放点积注意力
使用点积可以得到计算效率更高的评分函数,但是点积操作要求查询和键具有相同的长度d。假设查询和键的所有元素都是独立的随机变量,并且都满足零均值和单位方差,那么两个向量的点积的均值为0,方差为d。为确保无论向量长度如何,点积的方差在不考虑向量长度的情况下仍然是1,我们再将点积除以,则缩放点积注意力(scaled dot‐product attention)评分函数为:
在实践中,我们通常从小批量的角度来考虑提高效率,例如基于n个查询和m个键-值对计算注意力,其中查
询和键的长度为d,值的长度为v。查询、键和值$V \in R^{m×v}的缩放点积注意力是:
下面的缩放点积注意力的实现使用了暂退法进行模型正则化。
class DotProductAttention(nn.Module):
"""缩放点积注意力"""
def __init__(self, dropout, **kwargs):
super(DotProductAttention, self).__init__(**kwargs)
self.dropout = nn.Dropout(dropout)
# queries的形状:(batch_size,查询的个数,d)
# keys的形状:(batch_size,“键-值”对的个数,d)
# values的形状:(batch_size,“键-值”对的个数,值的维度)
# valid_lens的形状:(batch_size,)或者(batch_size,查询的个数)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
self.attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(self.attention_weights), values)
演示上述的DotProductAttention类
queries = torch.normal(0, 1, (2, 1, 2))
attention = DotProductAttention(dropout=0.5)
attention.eval()
attention(queries, keys, values, valid_lens)

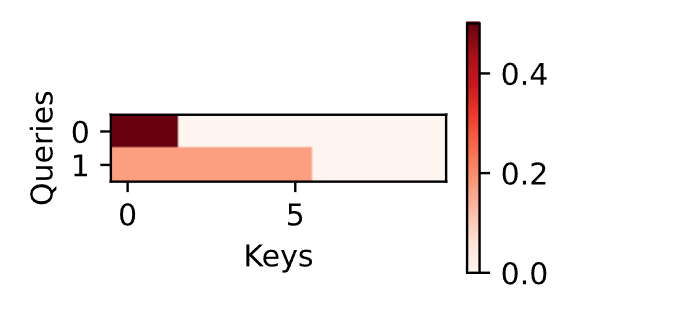
与加性注意力演示相同,由于键包含的是相同的元素,而这些元素无法通过任何查询进行区分,因此获得了均匀的注意力权重。
d2l.show_heatmaps(attention.attention_weights.reshape((1, 1, 2, 10)),
xlabel='Keys', ylabel='Queries')
• 将注意力汇聚的输出计算可以作为值的加权平均,选择不同的注意力评分函数会带来不同的注意力汇聚操作。
• 当查询和键是不同长度的矢量时,可以使用可加性注意力评分函数。当它们的长度相同时,使用缩放的“点-积”注意力评分函数的计算效率更高。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具
2020-09-12 (二进制枚举+bitset)
2020-09-12 队列+排序(送礼物)
2020-09-12 转01串
2020-09-12 BFS+螺旋矩阵