循环神经网络-双向循环神经网络
在序列学习中,我们以往假设的目标是:在给定观测的情况下(例如,在时间序列的上下文中或在语言模型的上下文中),对下一个输出进行建模。虽然这是⼀个典型情景,但不是唯一的。还可能发生什么其它的情况呢?我们考虑以下三个在文本序列中填空的任务。

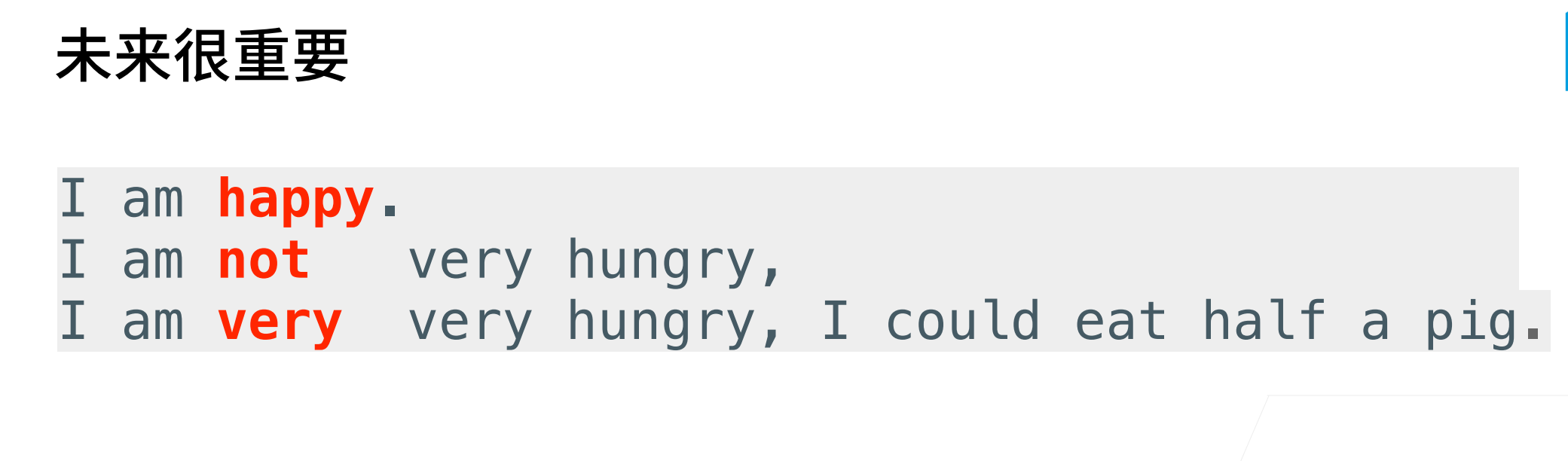

很明显对于第二个和第三个,如果第二个没有后面的内容的话,填"not"和"very"都是可以的。但是第三个有了后文之后,在填"not"显然就不可以了。
双向模型
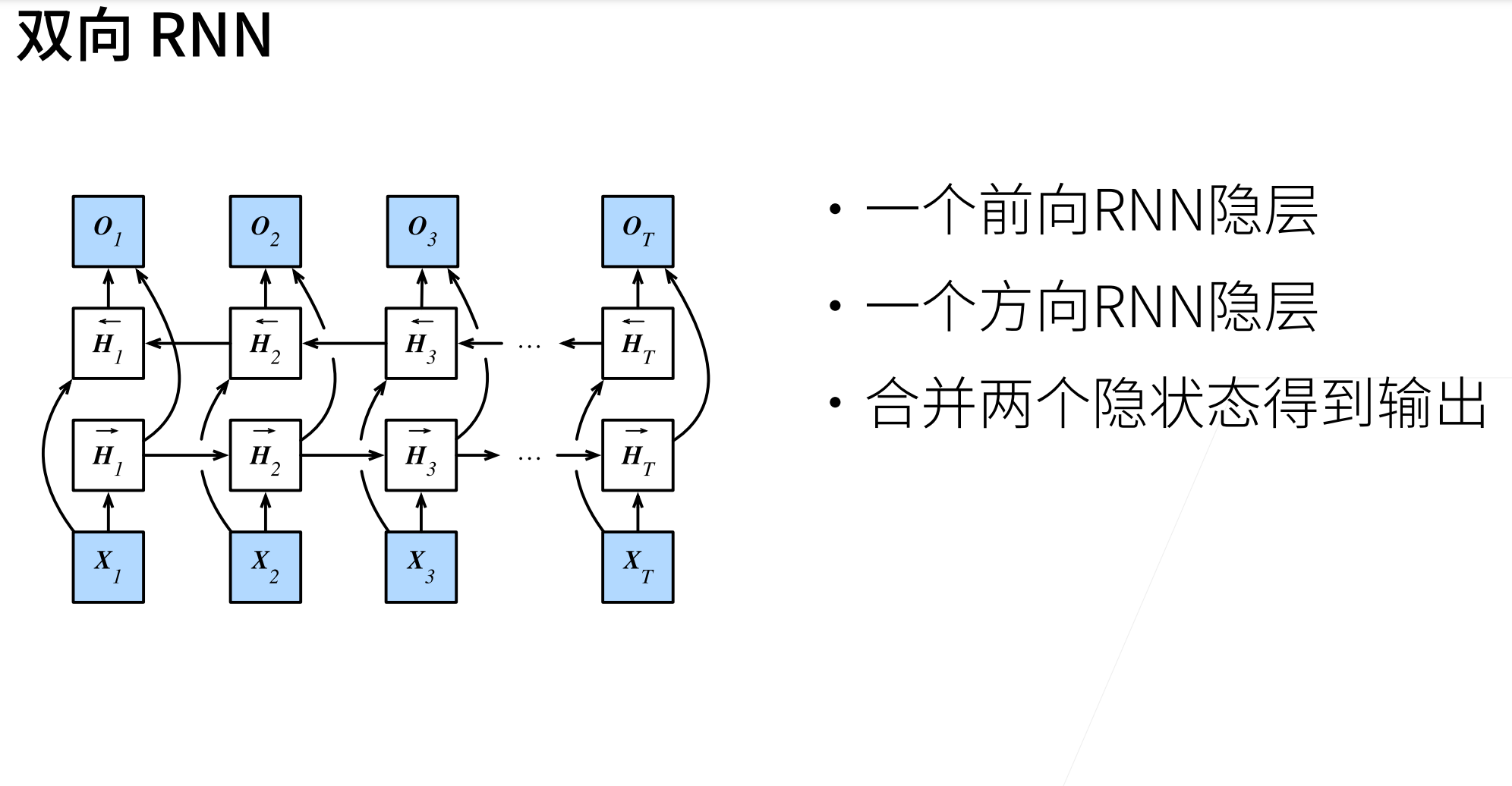
在循环神经网络中,只有一个在前向模式下“从第一个次元开始运行”的循环神经网络。如果想要循环网络获得与隐马尔可夫模型类似的前瞻能力,只需要增加一个“从最后一个词元开始从后向前运行”的循环神经网络。
双向循环神经网络的隐藏层中有两个隐状态(前向隐状态和反向隐状态,通过添加反向传递信息的隐藏层来更灵活地处理反向传递的信息)︰以输入\(X_1\)为例,当输入\(X_1\)进入到模型之后,当前的隐藏状态(右箭头,前向隐状态)放入下一个时间步的状态中去;\(X_2\)更新完隐藏状态之后,将更新后的隐藏状态传递给\(X_1\)的隐藏状态(左箭头,反向隐状态),将两个隐藏状态(前向隐状态和反向隐状态)合并在一起,就得到了需要送入输出层的隐状态\(H_t\)(在具有多个隐藏层的深度双向循环神经网络中,则前向隐状态和反向隐状态这两个隐状态会作为输入继续传递到下一个双向层(具有多个隐藏层的深度双向循环神经网络其实就是多个双向隐藏层的叠,最后输出层计算得到输出\(O_t\)。
定义
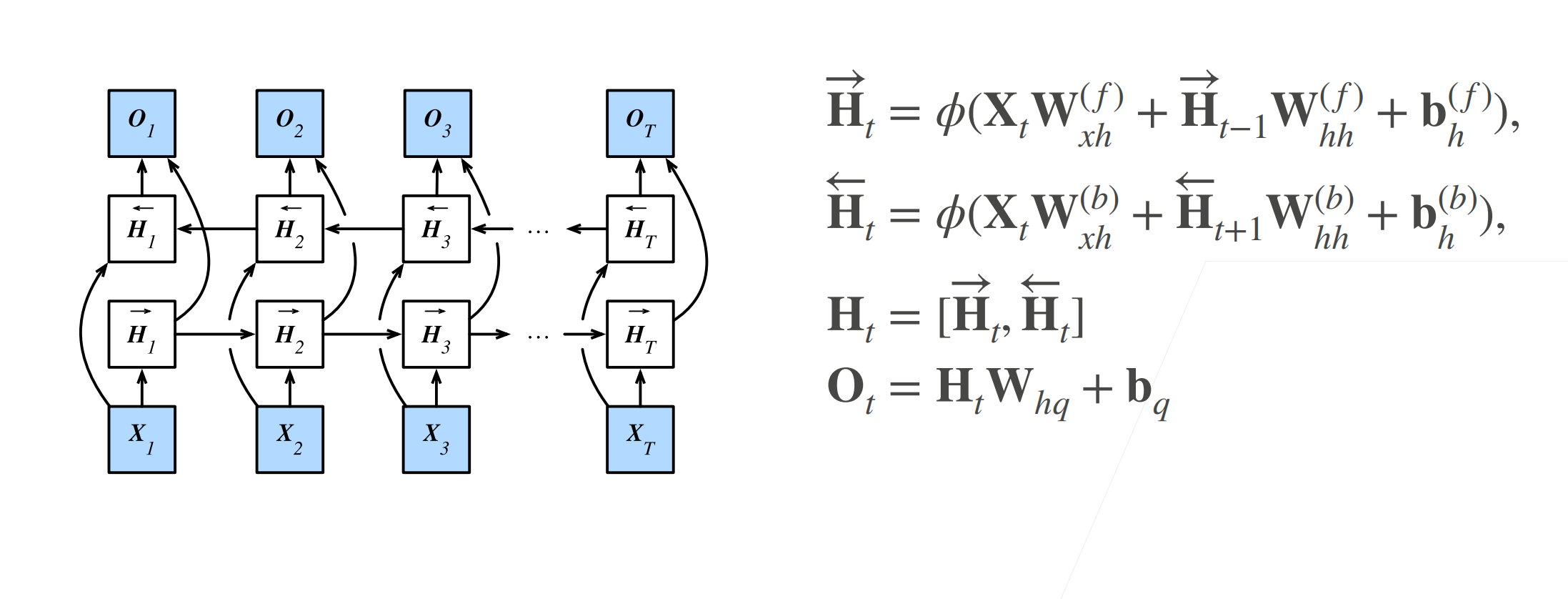
对于任意时间步\(t\),给定一个小批量的输入数据\(X_t \in R^{n×d}\)(样本数n,每个示例中的输入数\(d\)),并且令隐藏层激活函数为\(\phi\)。在双向架构中,我们设该时间步的前向和反向隐状态分别为\(\vec{H}_t \in R^{n×h}\)和\({\mathop{H}\limits ^{\leftarrow}}_t \in R^{n×h}\),其中h是隐藏单元的数⽬。前向和反向隐状态的更新如下:
其中,权重\(W^{(f)}_{xh} \in R^{d×h}\),\(W^{(f)}_{hh} \in R^{h×h}\),\(W^{(b)}_{xh} \in R^{d×h}\),\(W^{(b)}_{hh} \in R^{h×h}\)和偏置\(b^{(f)}_h \in R^{1×h}\),\(b^{(b)}_h \in R^{1×h}\)都是模型参数。
接下来,将前向隐状态\(\vec{H}_t\)和反向隐状态\({\mathop{H}\limits ^{\leftarrow}}_t\)连接起来,获得需要送入输出层的隐状态\(H_t \in R^{n×2h}\)。在具有多个隐藏层的深度双向循环神经网络中,该信息作为输入传递到下⼀个双向层。最后,输出层计算得到的输出为\(O_t \in R^{n×q}\)(\(q\)是输出单元的数目):
这里,权重矩阵\(W_{hq} \in R^{2h×q}\)和偏置\(b_q \in R^{1×q}\)是输出层的模型参数。事实上,这两个方向可以拥有不同数量的隐藏单元。
模型的计算代价及其应用
双向循环神经网络的⼀个关键特性是:使用来自序列两端的信息来估计输出。也就是说,我们使用来自过去和未来的观测信息来预测当前的观测。但是在对下⼀个词元进行预测的情况中,这样的模型并不是我们所需的。因为在预测下⼀个词元时,我们终究无法知道下⼀个词元的下文是什么,所以将不会得到很好的精度。具体地说,在训练期间,我们能够利用过去和未来的数据来估计现在空缺的词;而在测试期间,我们只有过去的数据,因此精度将会很差。 下面的实验将说明这⼀点。
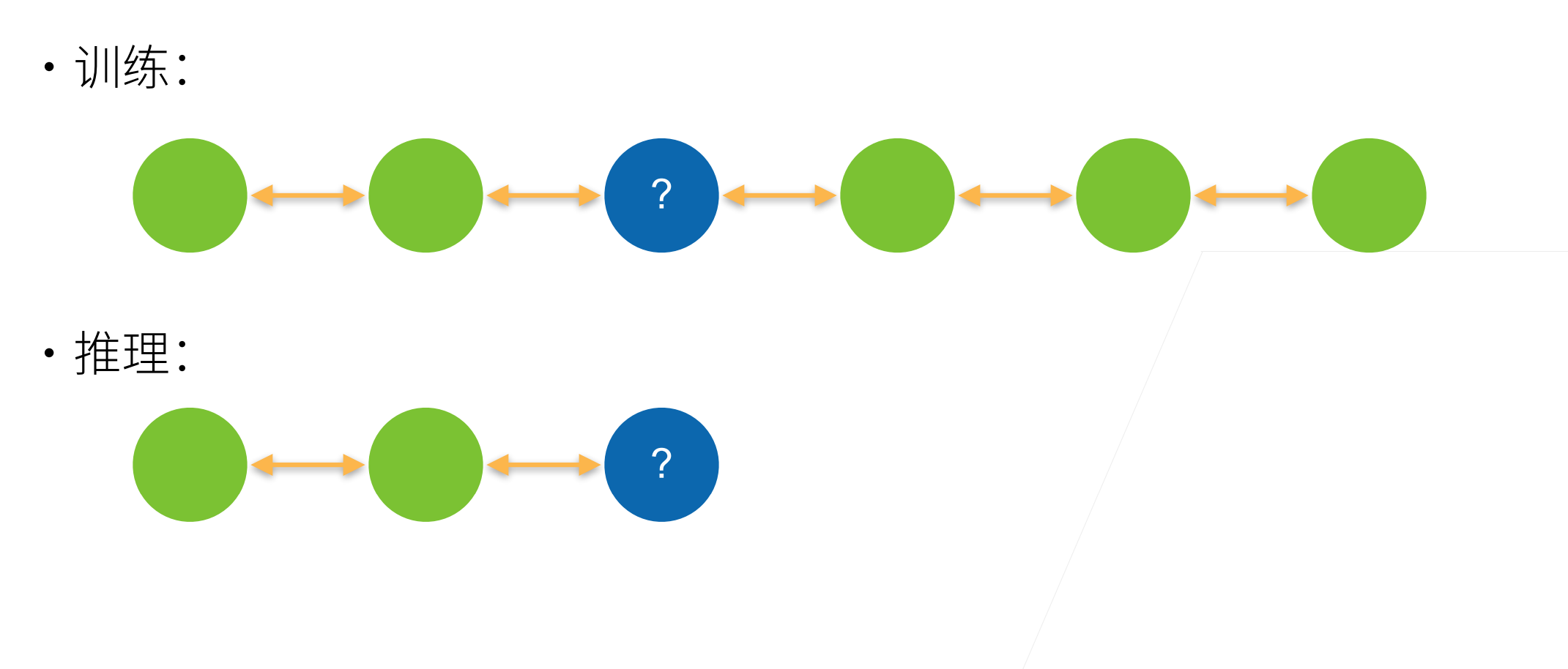
另⼀个严重问题是,双向循环神经网络的计算速度非常慢。其主要原因是网络的前向传播需要在双向层中进行前向和后向递归,并且网络的反向传播还依赖于前向传播的结果。因此,梯度求解将有⼀个非常长的链。双向层的使用在实践中非常少,并且仅仅应用于部分场合。例如,填充缺失的单词、词元注释(例如,用于命名实体识别)以及作为序列处理流水线中的⼀个步骤对序列进行编码(例如,用于机器翻译)。基本上都应用再我们已经知道整个句子,然后进行测试的时候。
双向循环神经网络的错误应用
至于这个代码很简单,我们再做反向的时候,只需要将句子反过来进行训练即可
由于双向循环神经网络使用了过去的和未来的数据,所以我们不能盲目地将这一语言模型应用于任何预测任务。尽管模型产出的困惑度是合理的,该模型预测未来词元的能力却可能存在严重缺陷。我们用下面的示例代码引以为戒,以防在错误的环境中使⽤它们。
import torch
from torch import nn
from d2l import torch as d2l
# 加载数据
batch_size, num_steps, device = 32, 35, d2l.try_gpu()
train_iter, vocab = d2l.load_data_time_machine(batch_size, num_steps)
# 通过设置“bidirective=True”来定义双向LSTM模型
vocab_size, num_hiddens, num_layers = len(vocab), 256, 2
num_inputs = vocab_size
lstm_layer = nn.LSTM(num_inputs, num_hiddens, num_layers, bidirectional=True)
model = d2l.RNNModel(lstm_layer, len(vocab))
model = model.to(device)
# 训练模型
num_epochs, lr = 500, 1
d2l.train_ch8(model, train_iter, vocab, lr, num_epochs, device)
perplexity 1.1, 68207.2 tokens/sec on cuda:0
time travellerererererererererererererererererererererererererer
travellerererererererererererererererererererererererererer
总结:
- 在双向循环神经网络中,每个时间步的隐状态由当前时间步的前后数据同时决定。
- 双向循环神经网络与概率图模型中的“前向-后向”算法具有相似性。
- 双向循环神经网络主要用于序列编码和给定双向上下文的观测估计。
- 由于梯度链更长,因此双向循环神经网络的训练代价非常⾼。
- 至于这个代码很简单,我们再做反向的时候,只需要将句子反过来进行训练即可

 浙公网安备 33010602011771号
浙公网安备 33010602011771号