pytorch-残差网络(ResNet)
我们在堆叠更多层的时候一定会有一个更好的结果吗?
如图所示我们堆积更多层的时候,可能会有一个更差的结果。但是如果你的更多层的时候包含你的前一层的时候一定比你的前一层好。

实际上在实验中也是这样的。

这是为什么呢?
因为我们在堆叠更多层的时候,层数越多,求梯度的时候乘的项数就越多,这时候如果我们梯度很小或者很大的话很容易造成梯度消失或者梯度爆炸。
residual模块

即

左图是34层网络,右图是50、101、152层网络。左图使用[3x3]的卷积,通道维度不发生变化。右图使用[1x1]的卷积进行通道降维度,再使用[3x3]进行卷积,最后使用[1x1]再升高维度,升高为降低维度的4倍。在通道和高宽相同的情况下,左图改为右图可以减少参数,我们知道1*1的卷积层可以减少参数。
整体结构

我们发现18层、34层、50层、101层、152层的结构都是差不多的,输入图像[3x224x224],用conv1得到[64x112x112],在通过[3x3]步长为2的池化,得到[64x56x56]的特征图,之后都是通过一系列residual模块。

对于layer34:正好符合conv2_x有3个残差结构,conv3_x有4个残差结构,conv4_x有6个残差结构,conv5_x有3个残差结构。
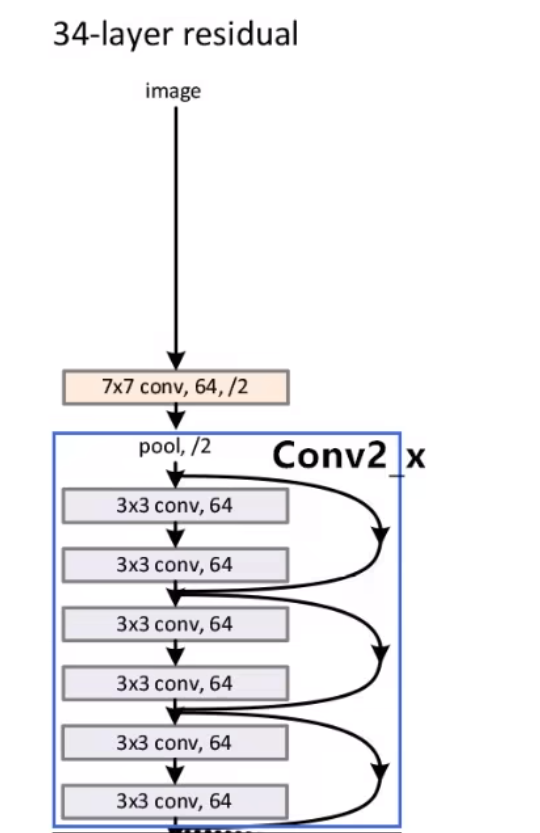



这里我们会发现他有实线的残差结构、也有虚线的残差结构。
我们来看看实线的残差结构和虚线的残差结构有什么不同?

- 实线的残差结构的输入的特征矩阵和输出特征矩阵的shape是一样的,可以之间进行相加操作。
- 虚线的残差结构的输入的特征矩阵和输出特征矩阵的shape是不一样的,不能之间进行相加操作。它的高宽减半,通道数增加成2倍
对于conv3_x的输入的特征矩阵是[56,56,64],输入矩阵是[28,28,128],因为conv3_x第一个残差块是虚线的残差块,进行高宽减半,通道数增加成2倍,然后后面的残差块都是实线的残差块。

对于更深层残差结构,下面这个是50层、101层、152层,conv3_x的残差结构。它和34层的还是不一样的,利用用了很多1 * 1卷积层进行升维和降维,来减少参数。

resnet防止梯度消失
ResNet为什么能训练出1000层的模型?
在接近data层的神经网络是比较难训练的,我们知道反向传播是反着传的,所以接近data的时候,他可能在误差比较小,使得它的梯度很小,然后如果堆叠了很多层之后很有可能使得后续的train梯度消失。
我们来看一下resnet怎么使得堆叠更多层,防止梯度消失的。
我们知道对于,求的梯度为,更新w的时候就是,l为学习率。
然后如果我们在堆叠一层g(x)的话,就是,然后我们在求梯度的时候就是:==,如果是个很小的数,后面那个也是一个很小的数,或者我们有很多层的话,会使得它的梯度消失。
这时候我们来看看这个残差网络:,求梯度就是$$
这个是个加分,所以有很多程度避免梯度消失。
也就是说我们可以通过这些红色的拿到梯度,使得它的梯度不那么小:

实现
残差块的实现如下:
class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
此代码生成两种类型的网络:⼀种是当use_1x1conv=False时,应用ReLU非线性函数之前,将输入添加到输出。另⼀种是当use_1x1conv=True时,添加通过1 × 1卷积调整通道和分辨率。也就是分别对应我们上面说的虚线和实线。

class Residual(nn.Module):
def __init__(self, input_channels, num_channels, use_1x1conv=False,
strides=1):
super().__init__()
self.conv1 = nn.Conv2d(input_channels, num_channels, kernel_size=3,
padding=1, stride=strides)
self.conv2 = nn.Conv2d(num_channels, num_channels, kernel_size=3,
padding=1)
if use_1x1conv:
self.conv3 = nn.Conv2d(input_channels, num_channels,
kernel_size=1, stride=strides)
else:
self.conv3 = None
self.bn1 = nn.BatchNorm2d(num_channels)
self.bn2 = nn.BatchNorm2d(num_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, X):
Y = F.relu(self.bn1(self.conv1(X)))
Y = self.bn2(self.conv2(Y))
if self.conv3:
X = self.conv3(X)
Y += X
return F.relu(Y)
下面我们来查看输入和输出形状一致的情况。
这个就是那个实线那个:
blk = Residual(3,3)
X = torch.rand(4, 3, 6, 6)
Y = blk(X)
Y.shape
# torch.Size([4, 3, 6, 6])

我们也可以在增加输出通道数的同时,减半输出的高和宽。
下面看看虚线的那个:
blk = Residual(3,6, use_1x1conv=True, strides=2)
blk(X).shape
# torch.Size([4, 6, 3, 3])

ResNet模型
ResNet的前两层跟之前介绍的GoogLeNet中的⼀样:在输出通道数为64、步幅为2的7 × 7卷积层后,接步幅为2的3 × 3的最大汇聚层。不同之处在于ResNet每个卷积层后增加了批量规范化层。
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3),
nn.BatchNorm2d(64), nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
GoogLeNet在后⾯接了4个由Inception块组成的模块ResNet则使用4个由残差块组成的模块,每个模块使用若干个同样输出通道数的残差块。第⼀个模块的通道数同输⼊通道数⼀致。由于之前已经使用了步幅为2的最大汇聚层,所以无须减小高和宽。之后的每个模块在第⼀个残差块里将上⼀个模块的通道数翻倍,并将高和宽减半。
下面我们来实现这个模块。注意,我们对第⼀个模块做了特别处理
def resnet_block(input_channels, num_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
Residual(input_channels, num_channels, use_1x1conv=True,
strides=2))
else:
blk.append(Residual(num_channels, num_channels))
return blk
接着在ResNet加⼊所有残差块,这里每个模块使用2个残差块
b2 = nn.Sequential(*resnet_block(64, 64, 2, first_block=True))# 第一个要注意
b3 = nn.Sequential(*resnet_block(64, 128, 2))
b4 = nn.Sequential(*resnet_block(128, 256, 2))
b5 = nn.Sequential(*resnet_block(256, 512, 2))
最后,与GoogLeNet⼀样,在ResNet中加⼊全局平均汇聚层,以及全连接层输出。
net = nn.Sequential(b1, b2, b3, b4, b5, nn.AdaptiveAvgPool2d((1, 1)),
nn.Flatten(), nn.Linear(512, 10))
每个模块有4个卷积层(不包括恒等映射的1 × 1卷积层)。加上第⼀个7 × 7卷积层和最后⼀个全连接层,共有18层。因此,这种模型通常被称为ResNet-18。通过配置不同的通道数和模块⾥的残差块数可以得到不同的ResNet模型,例如更深的含152层的ResNet-152。
下面是ResNet-18的架构。

X = torch.rand(size=(1, 1, 224, 224))
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 64, 56, 56])
Sequential output shape: torch.Size([1, 128, 28, 28])
Sequential output shape: torch.Size([1, 256, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
AdaptiveAvgPool2d output shape: torch.Size([1, 512, 1, 1])
Flatten output shape: torch.Size([1, 512])
Linear output shape: torch.Size([1, 10])
lr, num_epochs, batch_size = 0.05, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=96)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.013, train acc 0.997, test acc 0.876
2234.2 examples/sec on cuda:0



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律