pytorch-批量规范化(Batch Normalization)
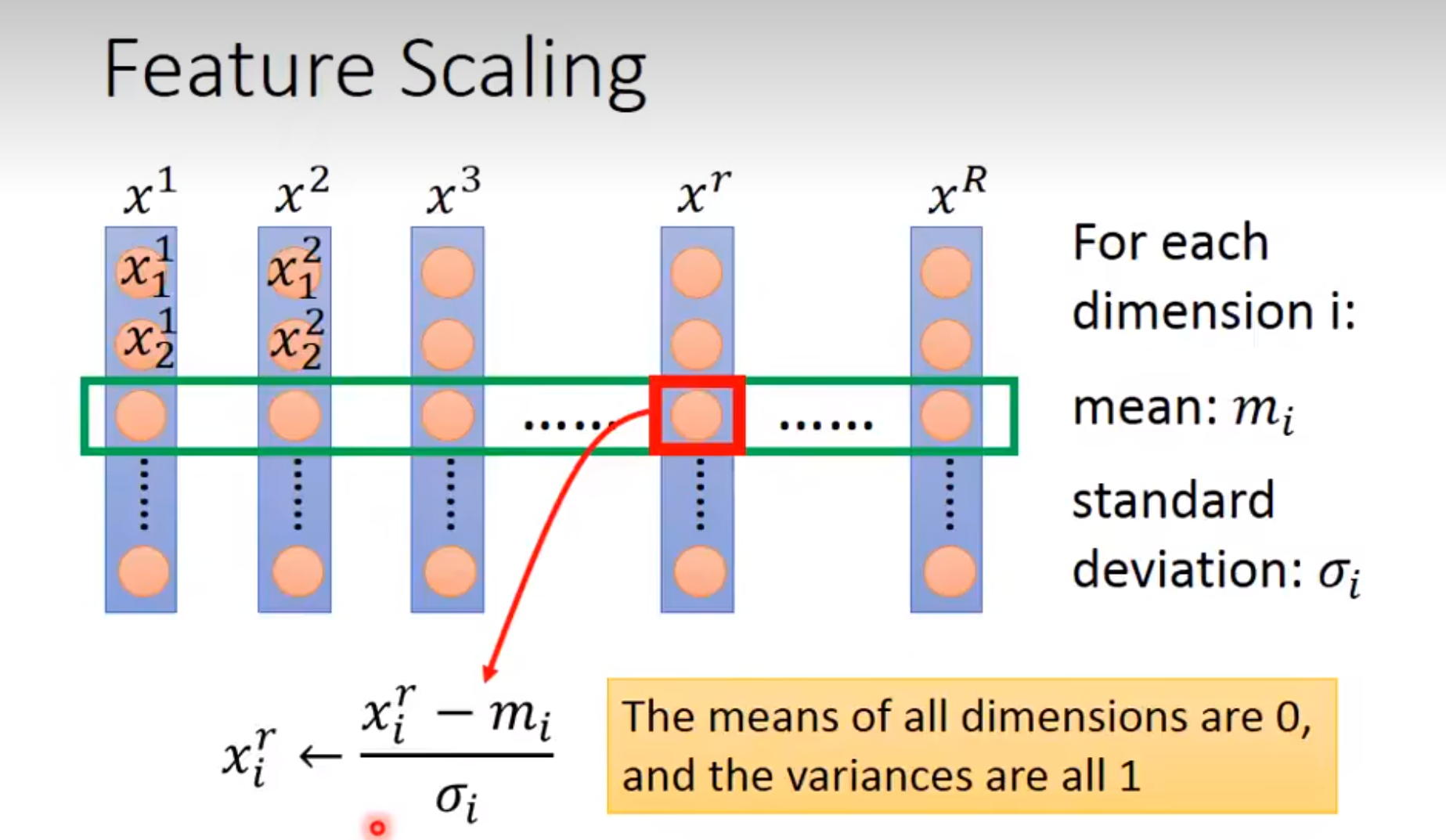
Feature Scaling(特征归一化)
Feature scaling,常见的提法有"特征归一化"、"标准化",是数据预处理中的重要技术。他的重要性:
(1)特征间的单位(尺度)可能不同,比如身高和体重,比如摄氏度和华氏度,比如房屋面积和房间数,一个特征的变化范围可能是[1,2,3,4....],另一个特征的变化范围可能是[100,200,300....]。
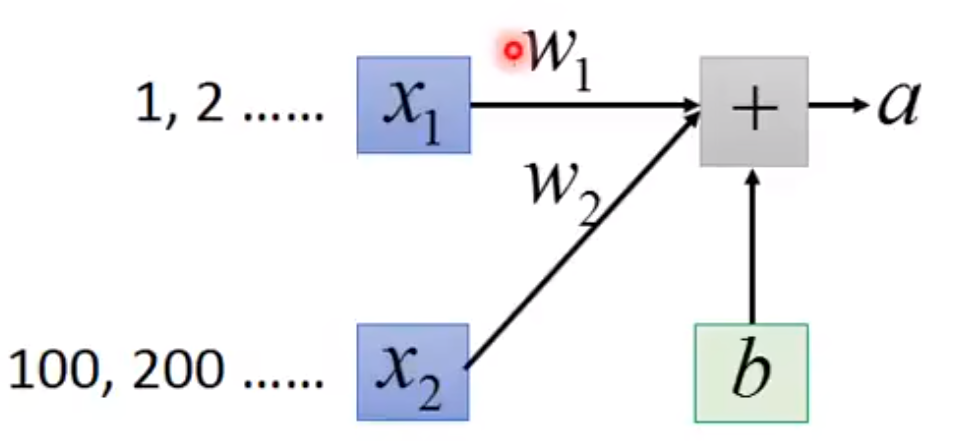
在进行计算的时候,这使得\(W_1\)的影响比较大,\(W_2\)的影响比较小。这使得尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
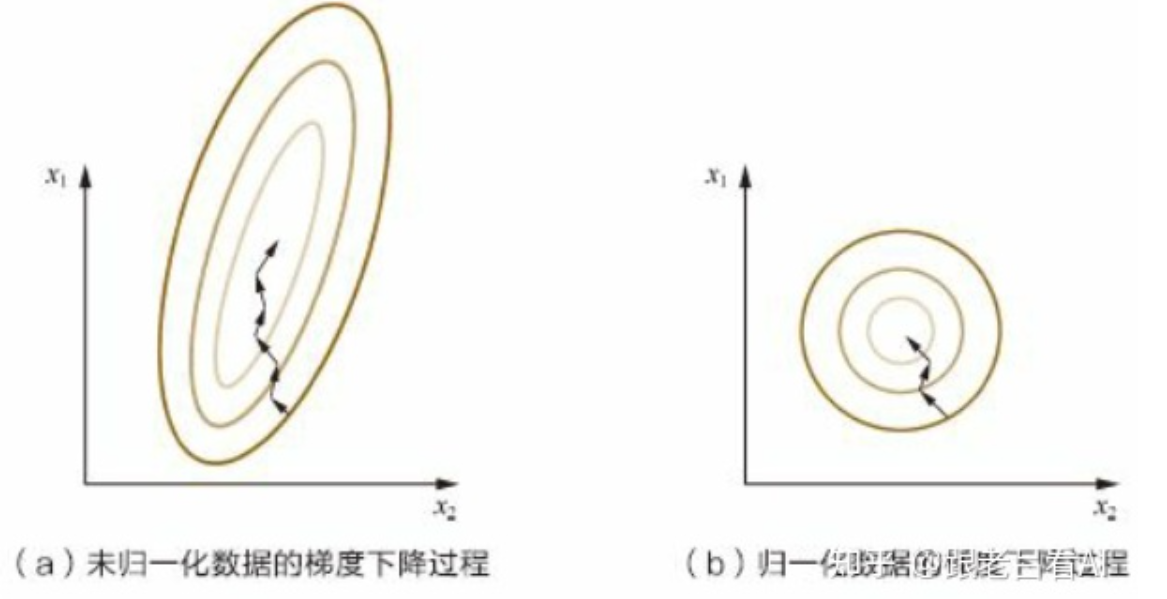
(2)原始特征下,因尺度差异,其损失函数的等高线图可能是椭圆形,梯度方向垂直于等高线,下降会走zigzag路线,而不是指向local minimum。通过对特征进行zero-mean and unit-variance变换后,其损失函数的等高线图更接近圆形,梯度下降的方向震荡更小,收敛更快
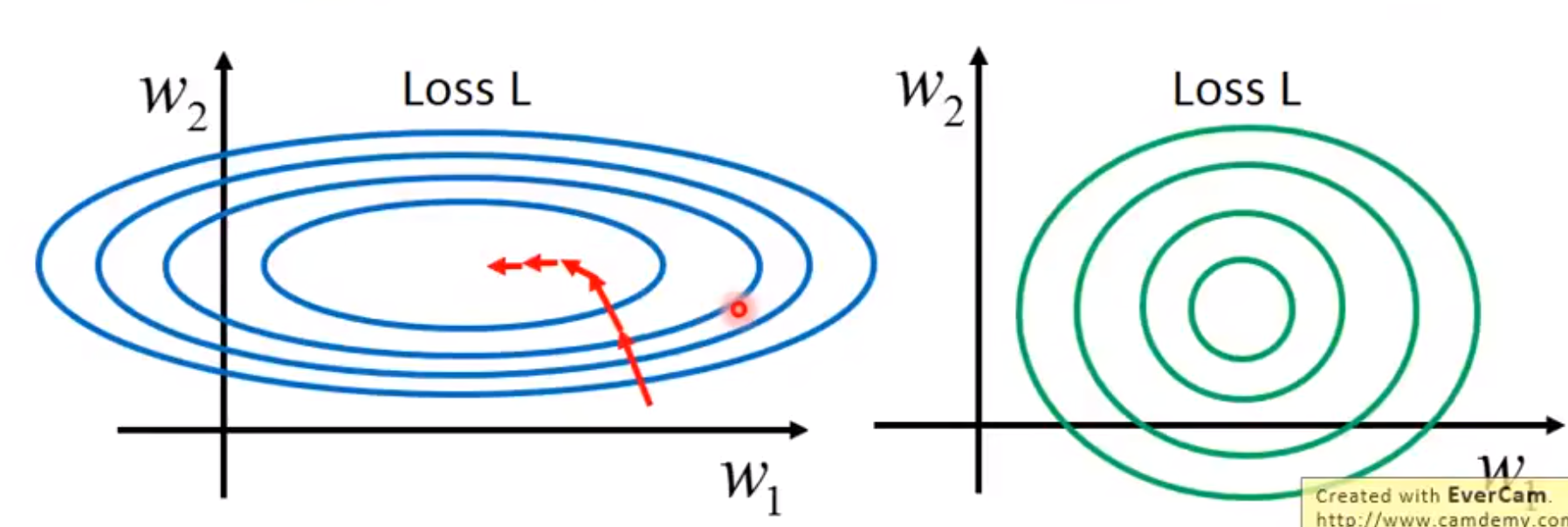
数据归一化后,寻优解的寻优过程明显会变得平缓,更容易正确收敛到最优解。
(1)归一化后,加快了梯度下降求最优解的速度
(2)归一化有可能提高精度。因为有些分类器需要计算样本间距离
所以我们在做训练的时候经常先对数据进行Feature Scaling。归一化公式:
Batch Normalization
我们在图像预处理过程中通常会对图像进行标准化处理,这样能够加速网络的收敛,如下图所示,对于Conv1来说输入的就是满足某一分布的特征矩阵,但对于Conv2而言输入的feature map就不一定满足某一分布规律了,而我们Batch Normalization的目的就是使我们的每一个Batch中的feature map满足均值为0,方差为1的分布规律。
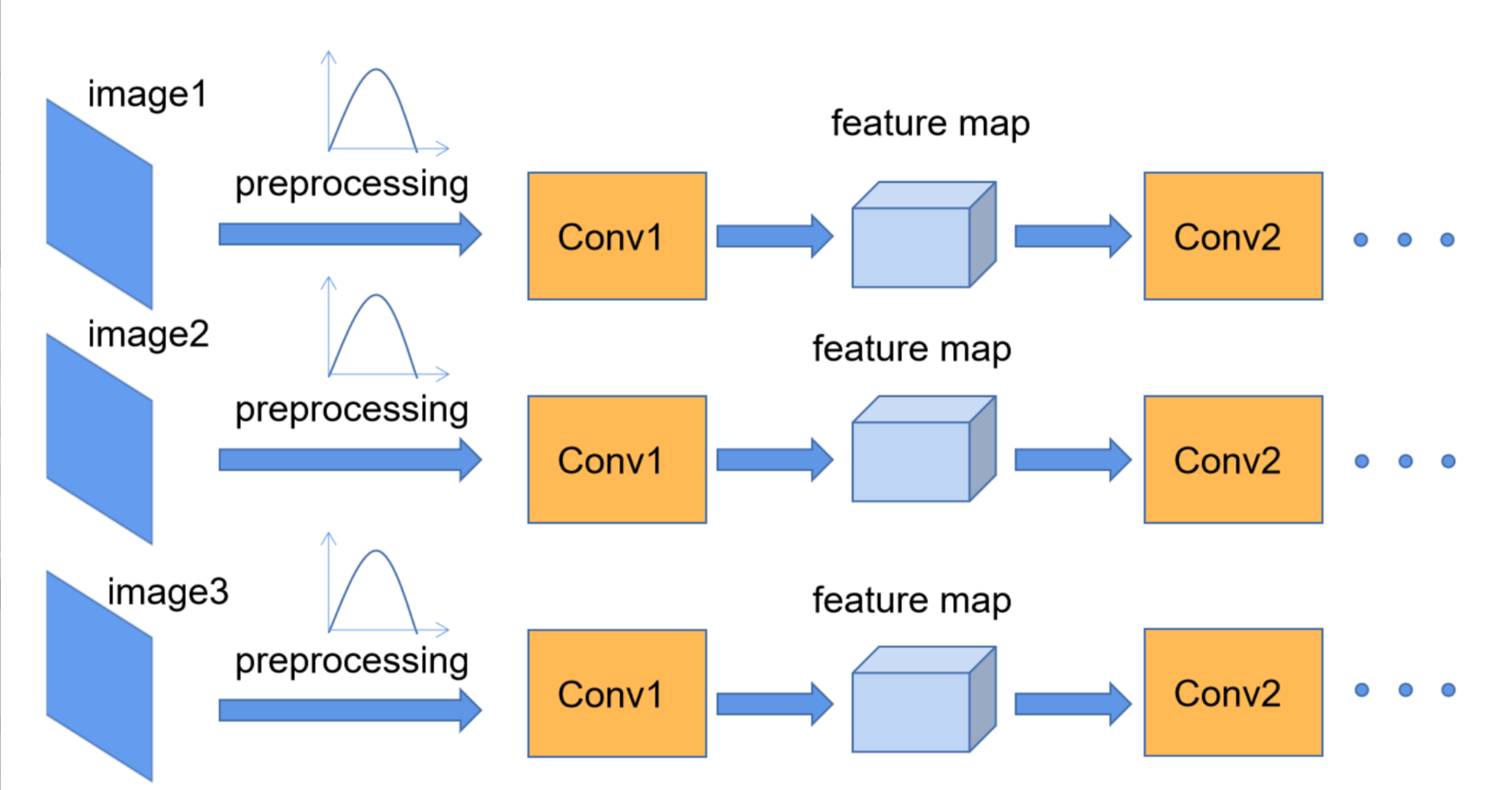
这个Conv2的输入是Conv1的输出,我们一开始的数据归一化是将Conv1进行归一化的,并没有对Conv1的输出Conv2进行归一化。
就像这样一样:
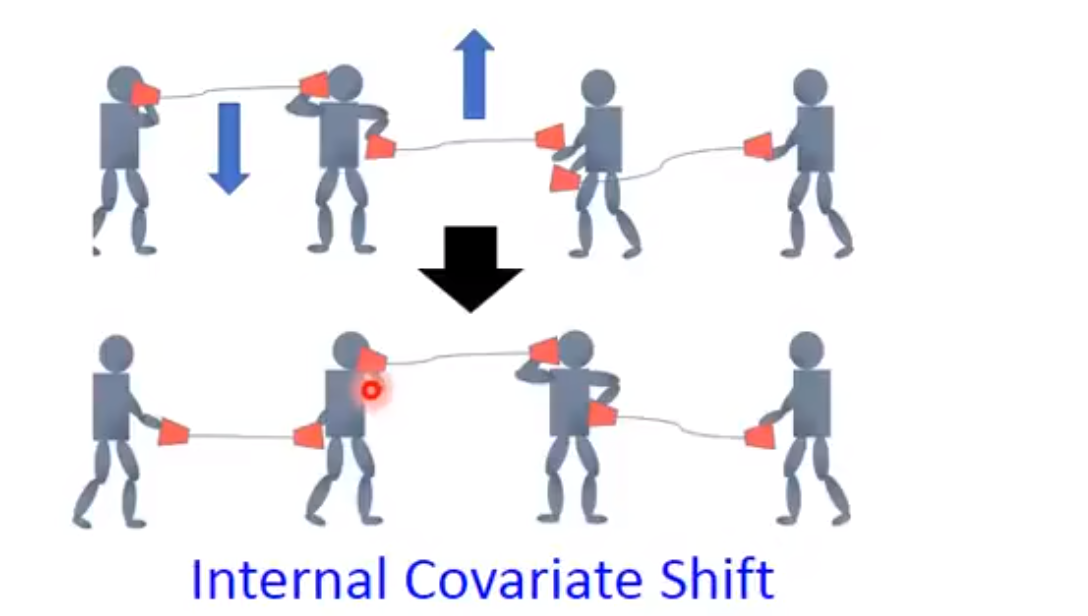
虽然我们可以利用学习率进行调整调整,但是调整的时候很容易调整过头。然后如果更小的学习率会使得training的更慢。然后我们需要新的技术就是Batch Normalization也可以防止梯度爆炸和梯度消失,特别是对于激活函数是sigmoid和tanh。
因为。
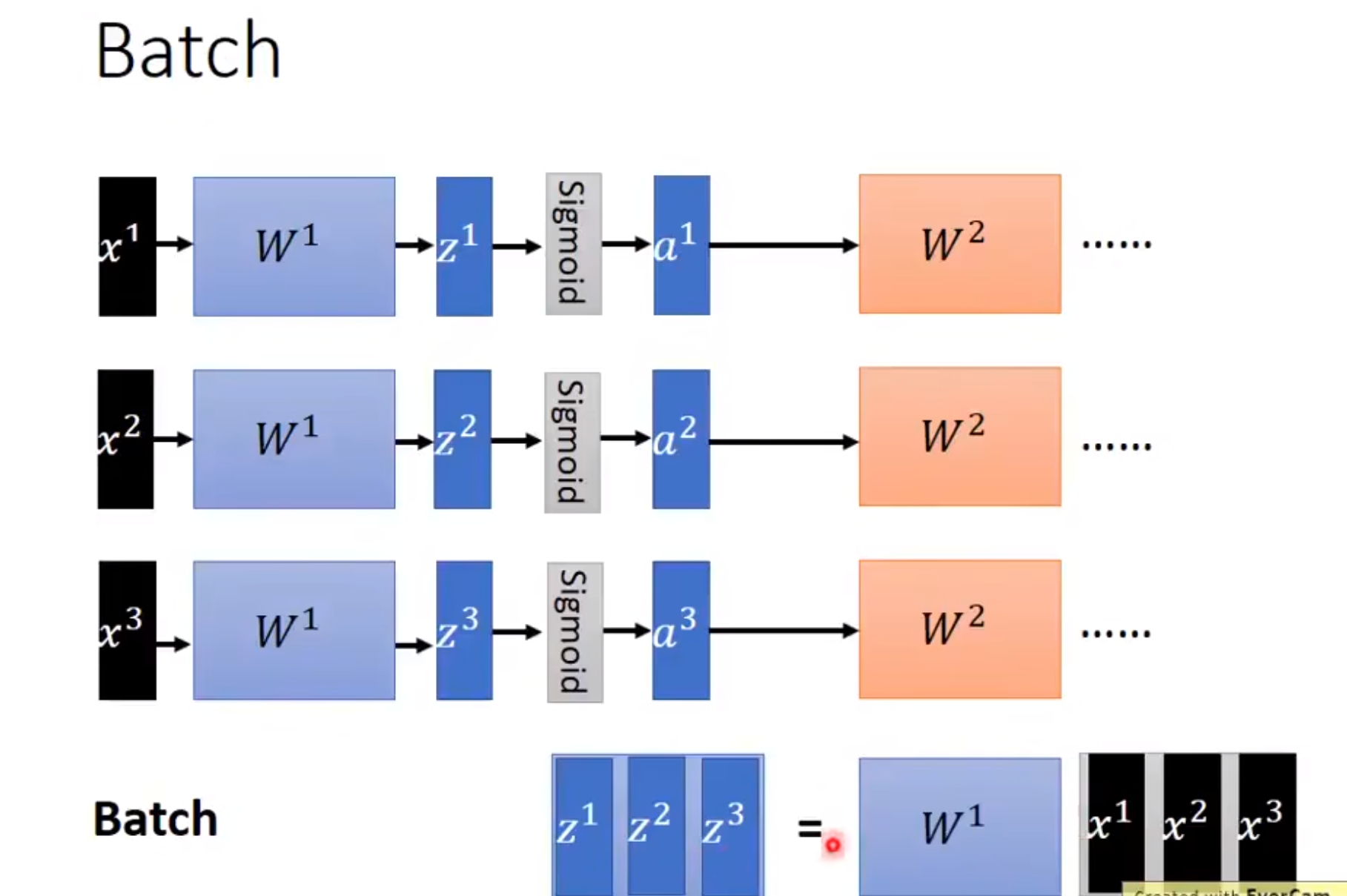
Batch
Batch,中文意为"批"。假设我们的训练集有100个训练样本,将这些样本分为5批,那么每批就有20个训练样本,此时Batch Size=20,如果让神经网络以上述的规则进行分批训练,那么每迭代一次(更新一次网络参数)就会训练一批(20个)样本(也即完成了一个iteration),迭代5次后,就对全部训练样本完成了一次遍历,也即完成了一个epoch。分批是为了提高GPU的并行。
Batch Normalization
然后其实Batch Normalization就是对每一个Batch、每一层的输出进行归一化,使得它的每一层的输入都是变成均值为0方差为1。使得它更好收敛。
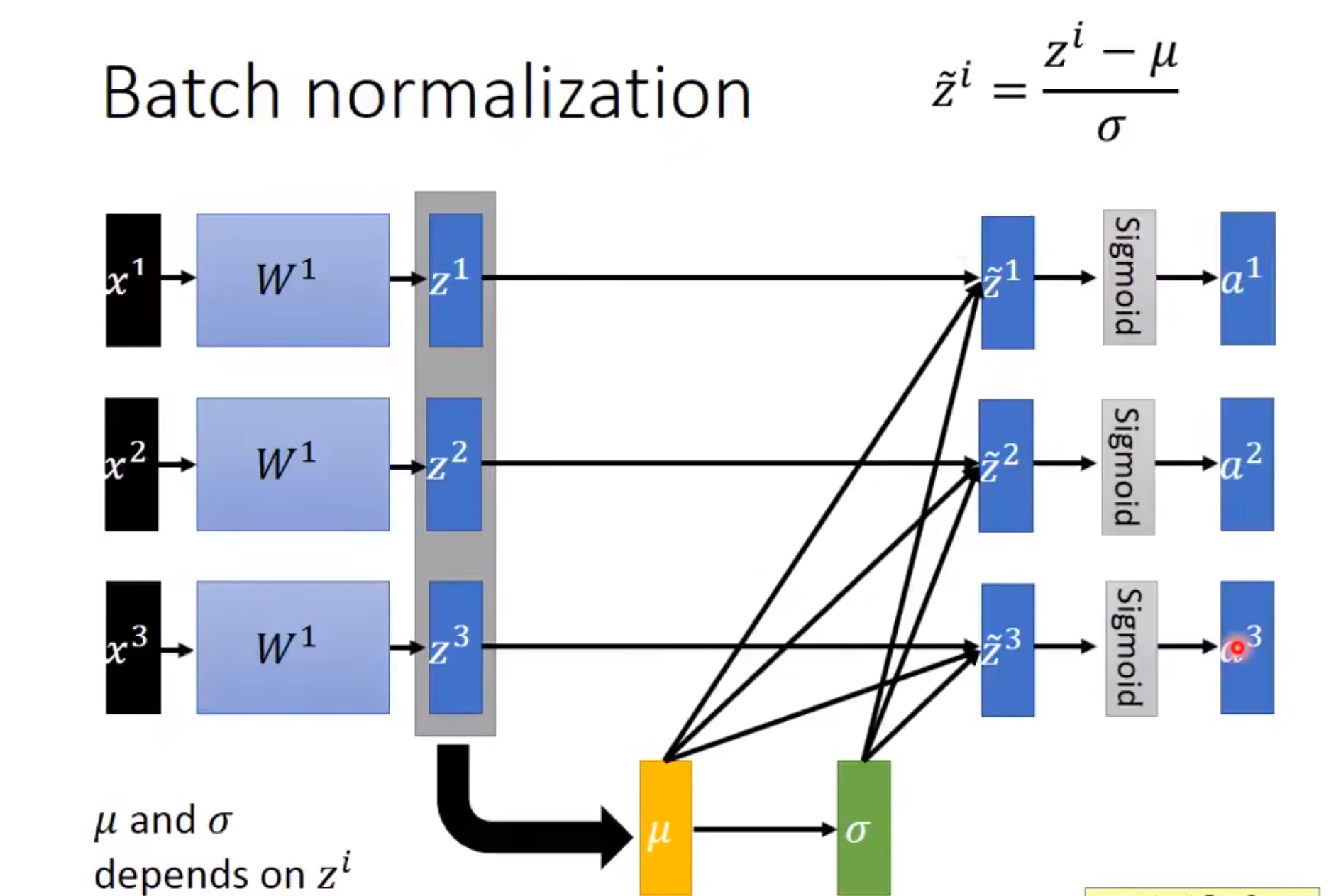
然后这个\(\mu\)和\(\sigma\)是每个小批量中样本均值和样本方差,应用BN后,生成的小批量的平均值为0和单位方差为1。
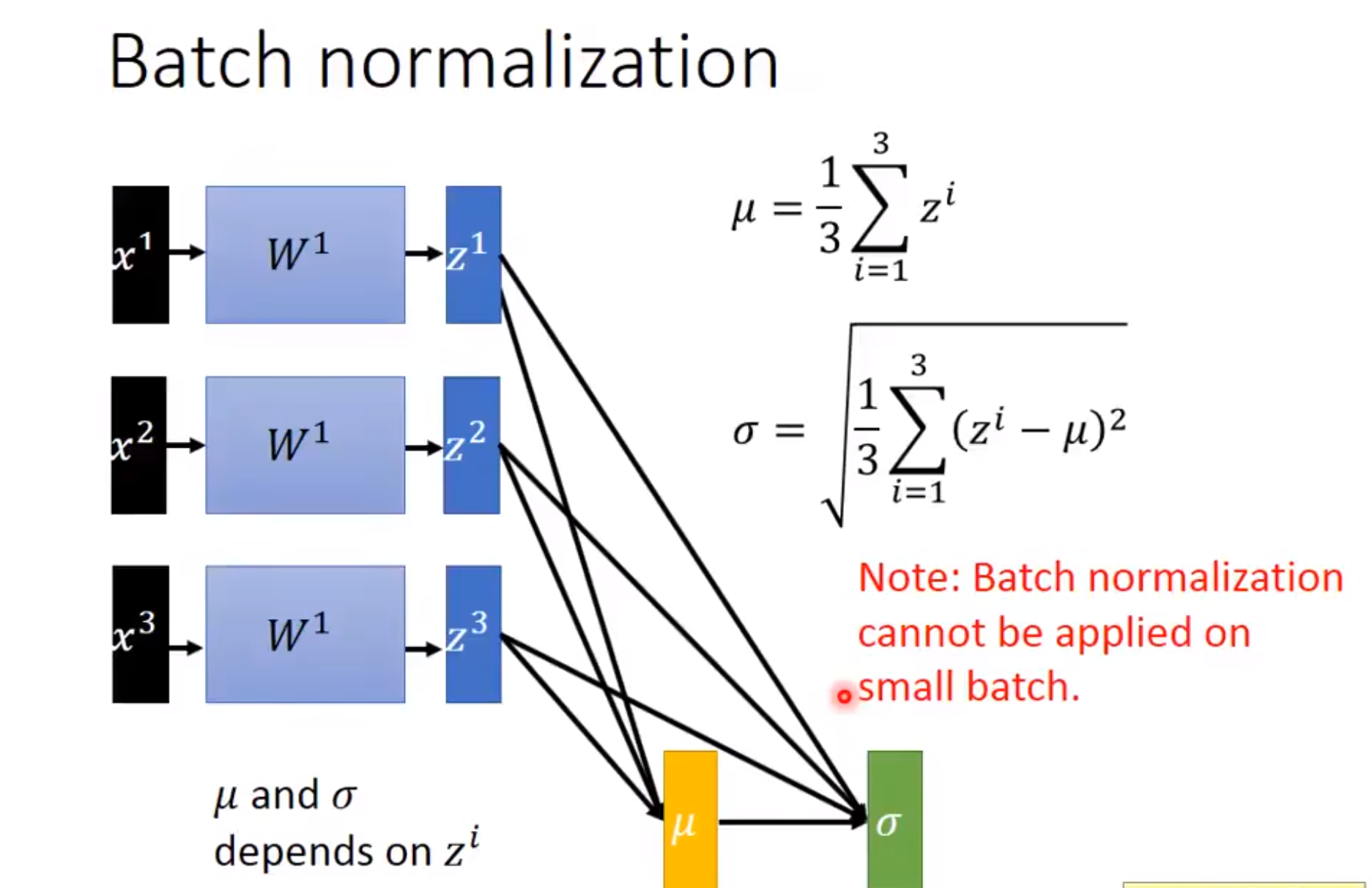
那么当我们进行反向传播的时候也是要经过这个\(\mu\)和\(\sigma\)的:
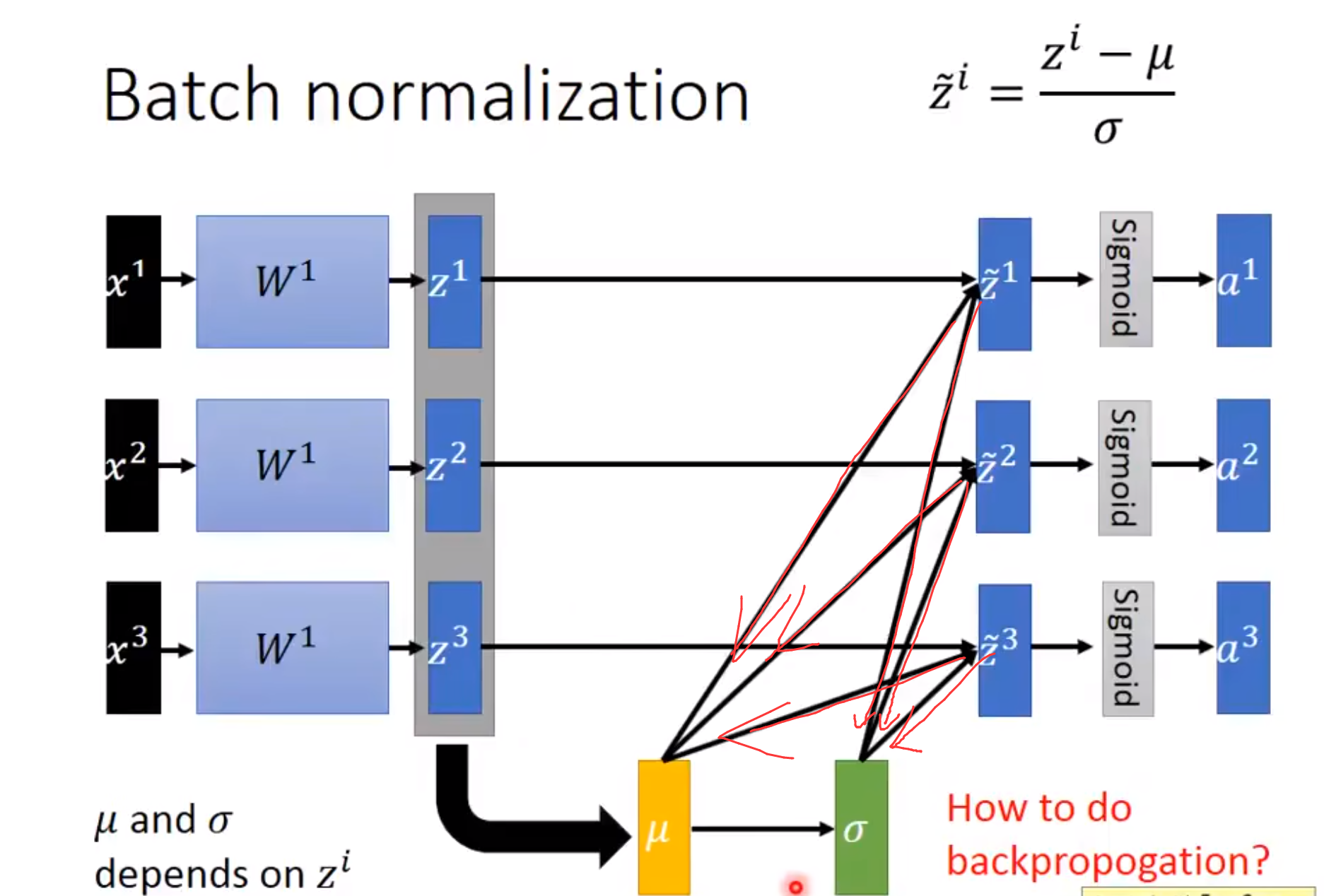
然后归一化了之后为了防止破坏一些特征的表达,我们加入\(\gamma\)和\(\beta\)。至于为啥要加入\(\gamma\)和\(\beta\)。有人说将数据尽可能还原为最初的输入分布,提高模型的容纳能力,也有人说是"减均值除方差让每一层的均值方差都变成了0/1,加入\(\gamma\)和\(\beta\)为了增加非线性性"。
加入\(\gamma\)和\(\beta\)之后:
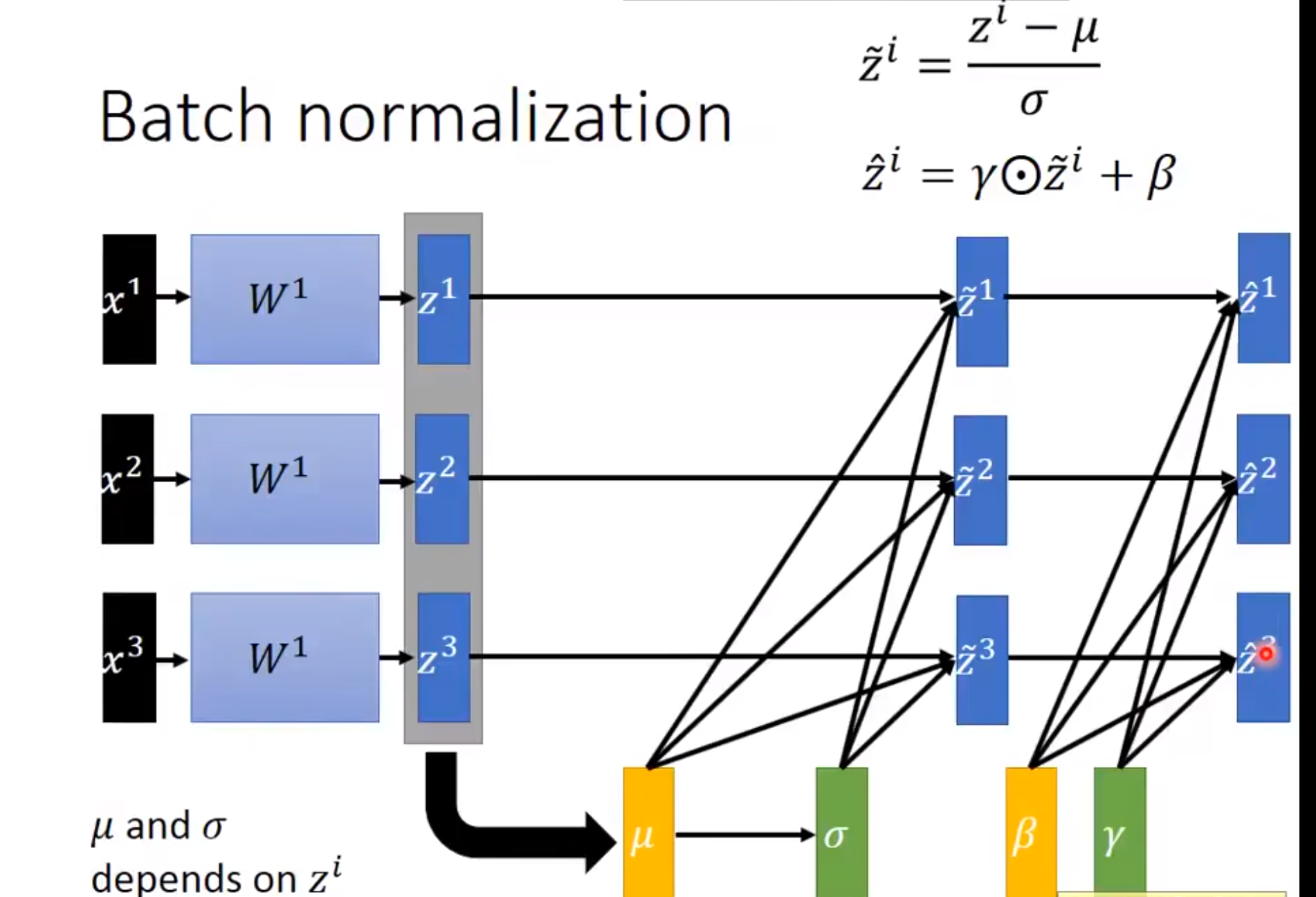
这里需要注意的是\(\gamma\)和\(\beta\)是需要与其他模型参数⼀起学习的参数。
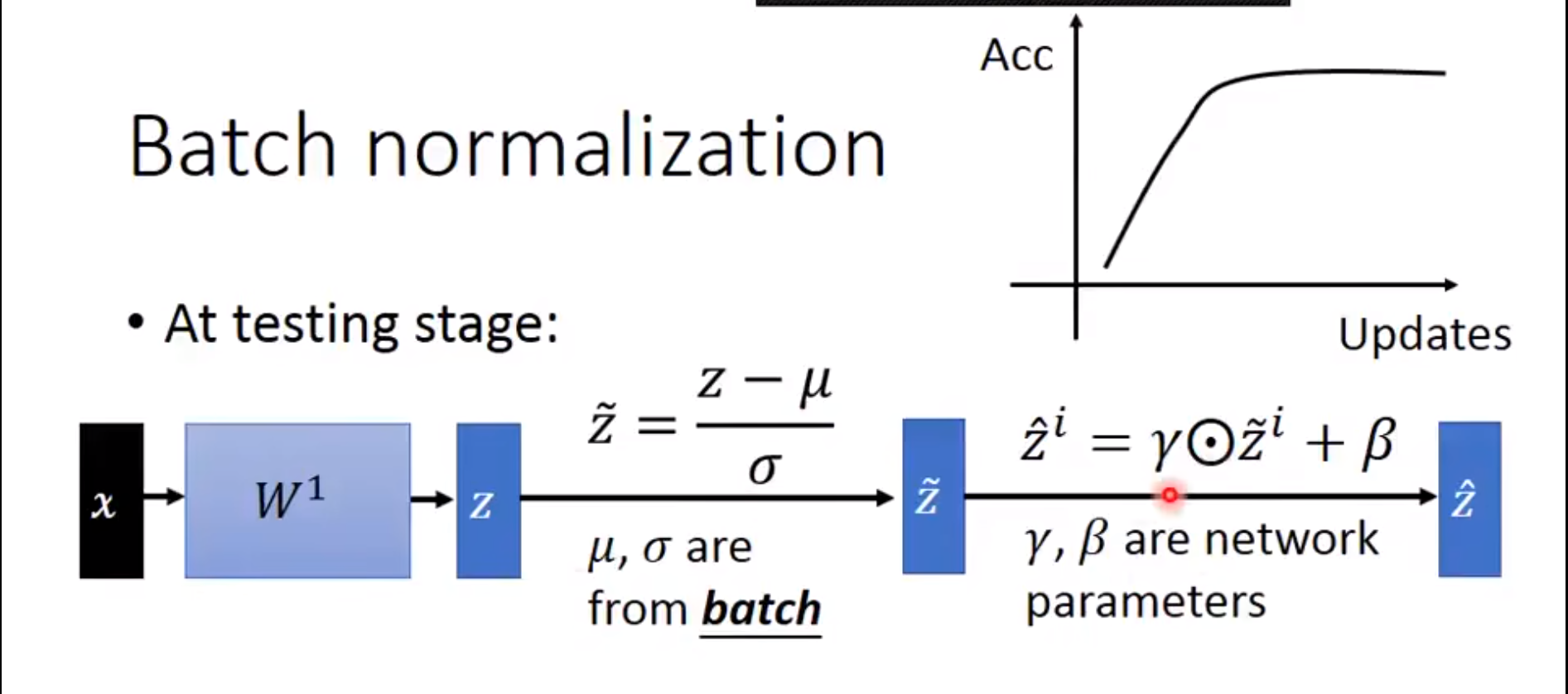
另外,批量规范化层在”训练模式“(通过小批量统计数据规范化)和“预测模式”(通过数据集统计规范化)中的功能不同。在训练过程中,我们无法得知使用整个数据集来估计平均值和方差,所以只能根据每个小批次的平均值和方差不断训练模型。而在预测模式下,可以根据整个数据集精确计算批量规范化所需的平均值和方差。
然后Batch Normalization也可以防止梯度爆炸和梯度消失,特别是对于激活函数是sigmoid和tanh。
例如:我们发现这个sigmoid函数在小于-4或者大于4的时候他的导数趋近于0。然后我们送进去的input的值在[-100,100]之间,这样很容易引起梯度弥散的现象。所以我们一般情况下使用ReLU函数,但是我们有时候又不得不使用sigmoid函数。这个时候我们在送到下一层的时候我们应该先经过Normalization操作。使得这个input变成N(0,z2)就是他的的input变成以0为均值,然后以z为方差的一个输入。就是使得这个input均匀的散布到0附近,然后再一个很小的范围变动。
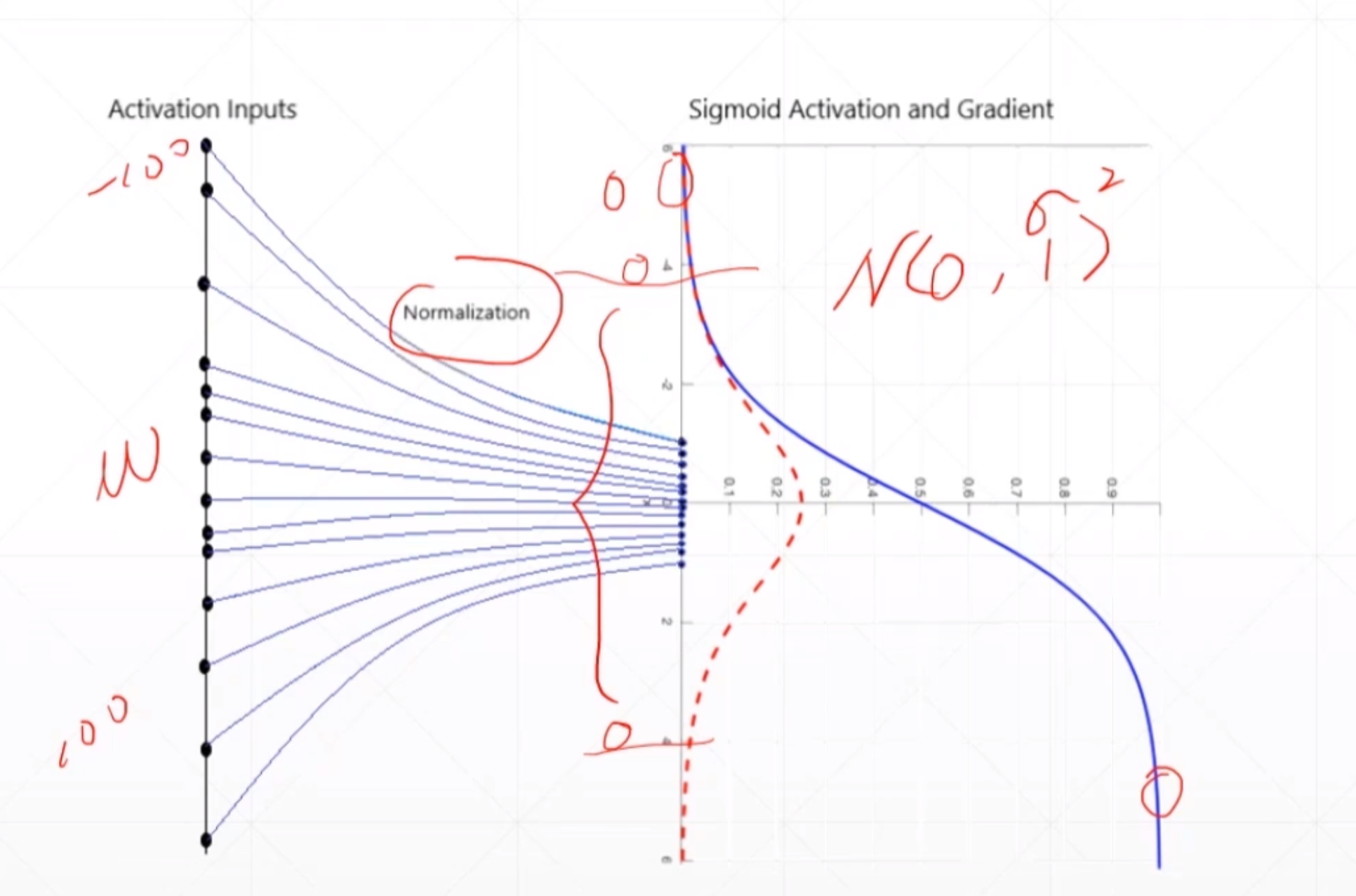
然后这个BN层主要是作用在激活函数之前。
作用:
-
BN层可以减少training 的时间,所以对于有利于跟深的网络,因为更深的网络taining的时间更长。
-
加入了BN层之后我们可以使用更大的学习率。
-
防止梯度爆炸或者梯度消失,特别是对于sigmoid,tanh激活函数
-
加入了BN层之后,网络对于数据初始化就不会那么敏感了,数据初始化就影响就更小了。
总结:
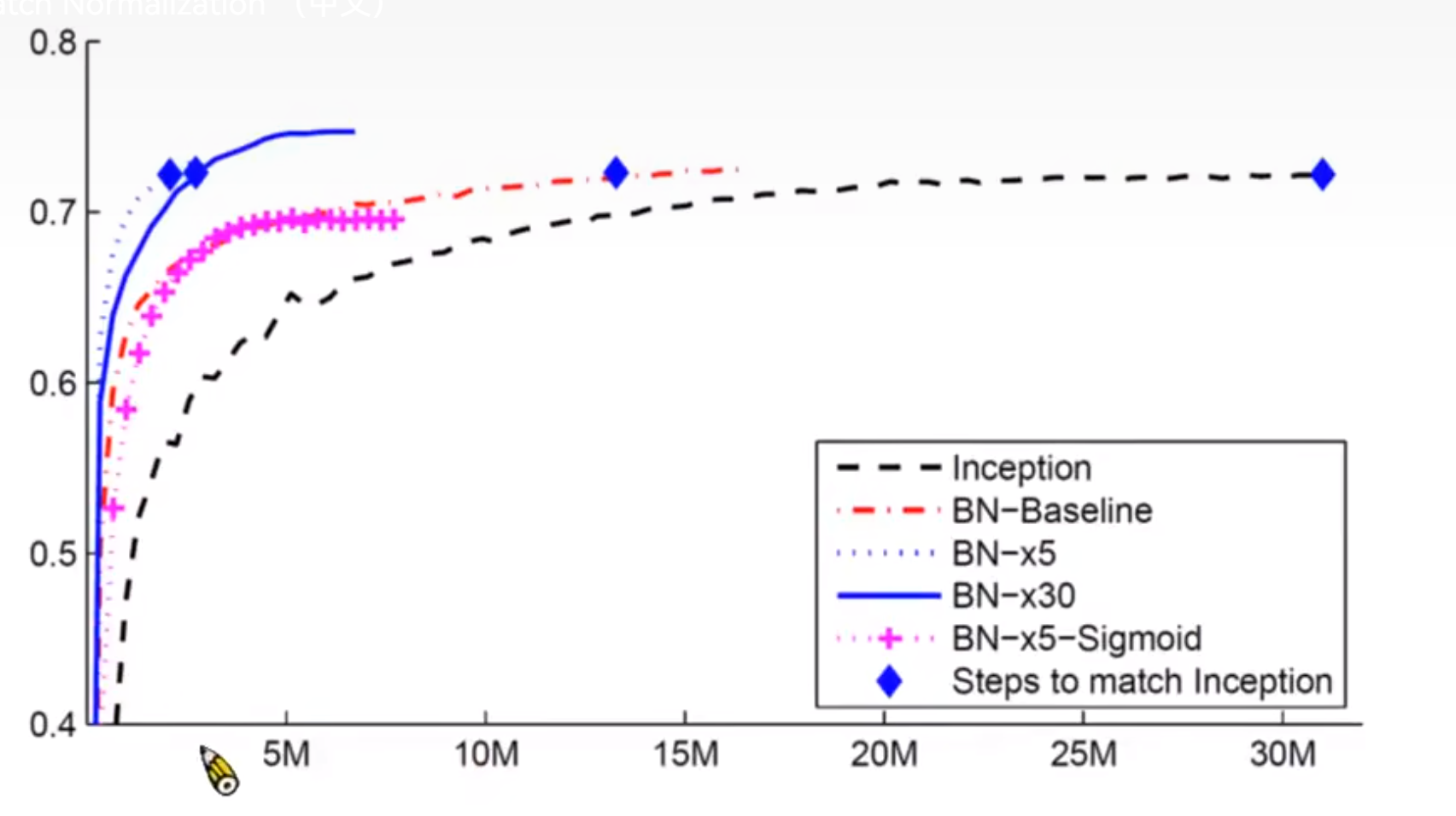
·批量归一化固定小批量中的均值和方差,然后学习出适合的偏移和缩放
·可以加速收敛速度,但一般不改变模型精度
我们可以发现它使得收敛更快:
实现
从零实现
下面,我们从头开始实现一个具有张量的批量规范化层。
import torch
from torch import nn
from d2l import torch as d2l
def batch_norm(X, gamma, beta, moving_mean, moving_var, eps, momentum):
# 通过is_grad_enabled来判断当前模式是训练模式还是预测模式
if not torch.is_grad_enabled():
# 如果是在预测模式下,直接使⽤传⼊的移动平均所得的均值和⽅差
X_hat = (X - moving_mean) / torch.sqrt(moving_var + eps)
else:
assert len(X.shape) in (2, 4)
if len(X.shape) == 2:
# 使⽤全连接层的情况,计算特征维上的均值和⽅差
mean = X.mean(dim=0)
var = ((X - mean)**2).mean(dim=0)
else:
# 使⽤二维卷积层的情况,计算通道维上(axis=1)的均值和⽅差。
# 这⾥我们需要保持X的形状以便后⾯可以做⼴播运算
mean = X.mean(dim=(0, 2, 3), keepdim=True)
var = ((X - mean)**2).mean(dim=(0, 2, 3), keepdim=True)
# 训练模式下,⽤当前的均值和⽅差做标准化
X_hat = (X - mean) / torch.sqrt(var + eps)
# 更新移动平均的均值和⽅差
moving_mean = momentum * moving_mean + (1.0 - momentum) * mean
moving_var = momentum * moving_var + (1.0 - momentum) * var
Y = gamma * X_hat + beta # 缩放和移位
return Y, moving_mean.data, moving_var.data
我们现在可以创建⼀个正确的BatchNorm层。这个层将保持适当的参数:拉伸gamma和偏移beta,这两个参数将在训练过程中更新。此外,我们的层将保存均值和⽅差的移动平均值,以便在模型预测期间随后使用。撇开算法细节,注意我们实现层的基础设计模式。通常情况下,我们用一个单独的函数定义其数学原理,比如说batch_norm。然后,我们将此功能集成到一个自定义层中,其代码主要处理数据移动到训练设备(如GPU)、分配和初始化任何必需的变量、跟踪移动平均线(此处为均值和方差)等问题。为了方便起见,我们并不担心在这里自动推断输入形状,因此我们需要指定整个特征的数量。不用担心,深度学习框架中的批量规范化API将为我们解决上述问题,我们稍后将展示这⼀点。
class BatchNorm(nn.Module):
# num_features:完全连接层的输出数量或卷积层的输出通道数。
# num_dims:2表⽰完全连接层,4表⽰卷积层
def __init__(self, num_features, num_dims):
super().__init__()
if num_dims == 2:
shape = (1, num_features)
else:
shape = (1, num_features, 1, 1)
# 参与求梯度和迭代的拉伸和偏移参数,分别初始化成1和0
self.gamma = nn.Parameter(torch.ones(shape))
self.beta = nn.Parameter(torch.zeros(shape))
# ⾮模型参数的变量初始化为0和1
self.moving_mean = torch.zeros(shape)
self.moving_var = torch.ones(shape)
def forward(self, X):
# 如果X不在内存上,将moving_mean和moving_var
# 复制到X所在显存上
if self.moving_mean.device != X.device:
self.moving_mean = self.moving_mean.to(X.device)
self.moving_var = self.moving_var.to(X.device)
# 保存更新过的moving_mean和moving_var
Y, self.moving_mean, self.moving_var = batch_norm(
X, self.gamma, self.beta, self.moving_mean, self.moving_var,
eps=1e-5, momentum=0.9)
return Y
使用批量规范化层的 LeNet
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), BatchNorm(6, num_dims=4),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16,
kernel_size=5), BatchNorm(16, num_dims=4),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.Linear(16 * 4 * 4, 120),
BatchNorm(120, num_dims=2), nn.Sigmoid(),
nn.Linear(120, 84), BatchNorm(84, num_dims=2),
nn.Sigmoid(), nn.Linear(84, 10))
和以前⼀样,我们将在Fashion-MNIST数据集上训练网络。这个代码与我们第⼀次训练LeNet时几乎完全相同,主要区别在于学习率大得多。
lr, num_epochs, batch_size = 1.0, 10, 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.250, train acc 0.908, test acc 0.875
17457.2 examples/sec on cuda:0
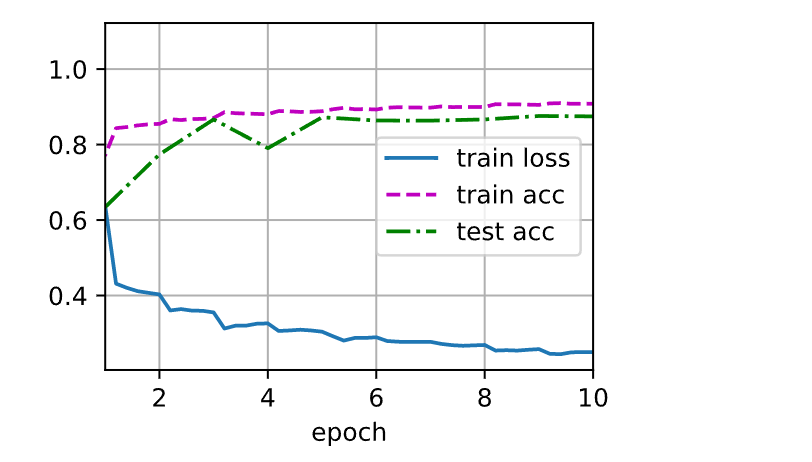
让我们来看看从第⼀个批量规范化层中学到的拉伸参数gamma和偏移参数beta。
net[1].gamma.reshape((-1,)), net[1].beta.reshape((-1,))
(tensor([2.4991, 2.4905, 2.0317, 1.2024, 1.5244, 1.0475], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>),
tensor([ 0.6538, -0.2818, -1.9867, 0.6670, -1.3946, -0.0351], device='cuda:0',
grad_fn=<ReshapeAliasBackward0>))

简明实现
除了使用我们刚刚定义的BatchNorm,我们也可以直接使用深度学习框架中定义的BatchNorm。该代码看起来几乎与我们上面的代码相同。
nn.BatchNorm2d(k)和nn.BatchNorm1d(k)
nn.BatchNorm2d(k)是卷积层输出的通道数
nn.batchNorm1d(k)是全连接层的输出层
net = nn.Sequential(nn.Conv2d(1, 6, kernel_size=5), nn.BatchNorm2d(6),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Conv2d(6, 16, kernel_size=5), nn.BatchNorm2d(16),
nn.Sigmoid(), nn.MaxPool2d(kernel_size=2, stride=2),
nn.Flatten(), nn.Linear(256, 120), nn.BatchNorm1d(120),
nn.Sigmoid(), nn.Linear(120, 84), nn.BatchNorm1d(84),
nn.Sigmoid(), nn.Linear(84, 10))
lr, num_epochs = 0.1,10
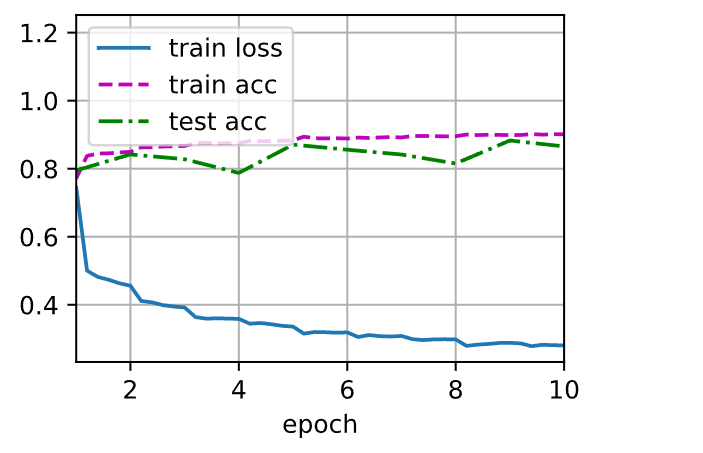
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
loss 0.281, train acc 0.901, test acc 0.866
38330.0 examples/sec on cuda:0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号