pytorch-使用块的网络(VGG)
VGG块
经典卷积神经网络的基本组成部分是下面的这个序列:
- 带填充以保持分辨率的卷积层;
- 非线性激活函数,如ReLU;
- 汇聚层,如最大汇聚层。
而⼀个VGG块与之类似,由⼀系列卷积层组成,后面再加上用于空间下采样的最大汇聚层。原文中作者使用3 × 3卷积核、填充为1(保持高度和宽度)的卷积层,和带有2 × 2汇聚窗口、步幅为2(每个块后的分辨率减半)的最大汇聚层。在下面的代码中,我们定义了⼀个名为vgg_block的函数来实现⼀个VGG块。
该函数有三个参数,分别对应于卷积层的数量num_convs、输入通道的数量in_channels 和输出通道的数量out_channels.
VGG网络
与AlexNet、LeNet⼀样,VGG网络可以分为两部分:第⼀部分主要由卷积层和汇聚层组成,第⼆部分由全连接层组成。
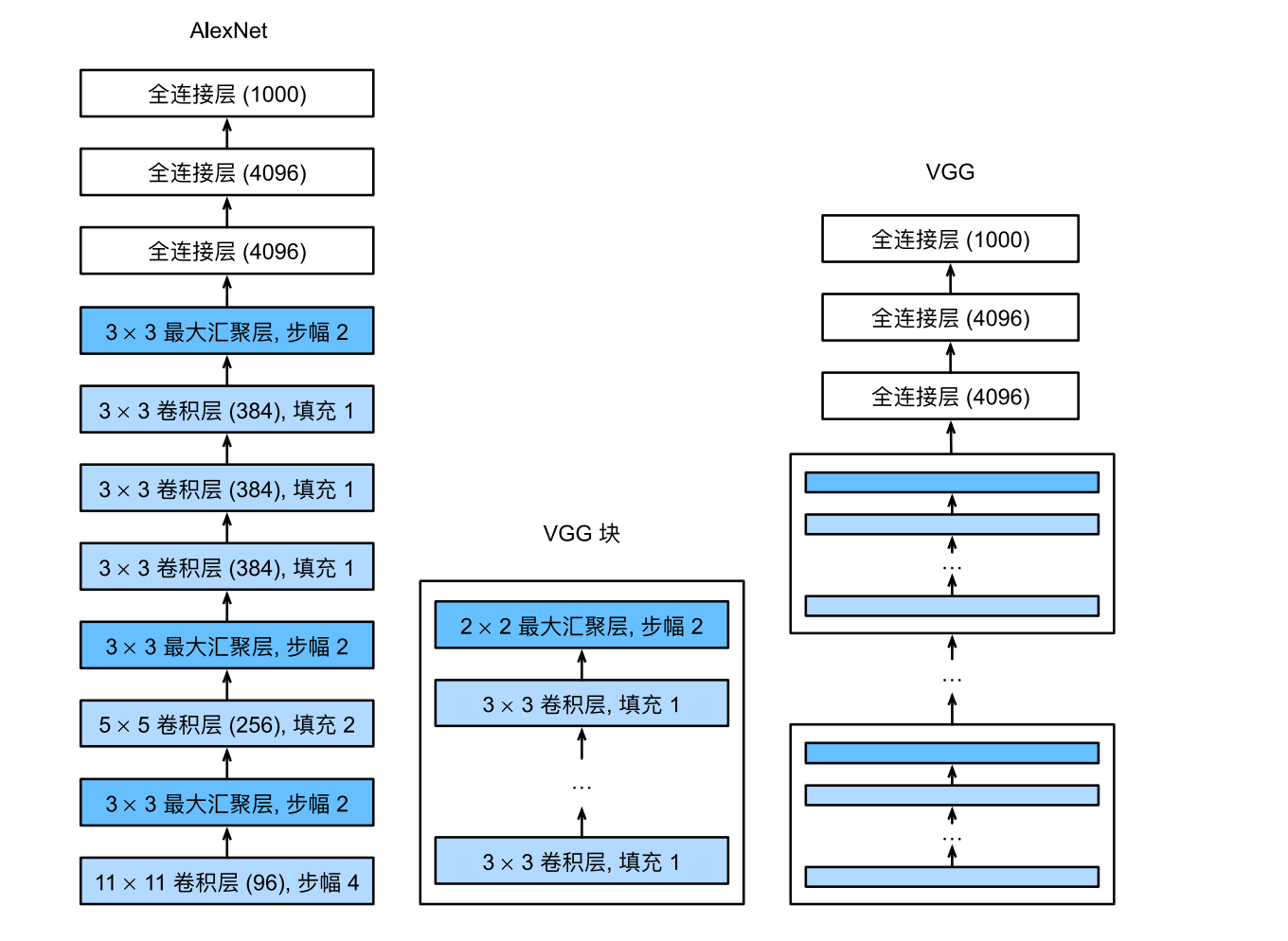
原始VGG网络有5个卷积块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层。第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。由于该网络使用8个卷积层和3个全连接层,因此它通常被称为VGG-11。
conv_arch = ((1, 64), (1, 128), (2, 256), (2, 512), (2, 512))
def vgg(conv_arch):
conv_blks = []
in_channels = 1
# 卷积层部分
for (num_convs, out_channels) in conv_arch:
conv_blks.append(vgg_block(num_convs, in_channels, out_channels))
in_channels = out_channels
# 全连接层部分
return nn.Sequential(*conv_blks, nn.Flatten(),
nn.Linear(out_channels * 7 * 7, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 4096), nn.ReLU(),
nn.Dropout(0.5), nn.Linear(4096, 10))
net = vgg(conv_arch)
接下来,我们将构建⼀个高度和宽度为224的单通道数据样本,以观察每个层输出的形状。
X = torch.randn(size=(1, 1, 224, 224))
for blk in net:
X = blk(X)
print(blk.__class__.__name__, 'output shape:\t', X.shape)
Sequential output shape: torch.Size([1, 64, 112, 112])
Sequential output shape: torch.Size([1, 128, 56, 56])
Sequential output shape: torch.Size([1, 256, 28, 28])
Sequential output shape: torch.Size([1, 512, 14, 14])
Sequential output shape: torch.Size([1, 512, 7, 7])
Flatten output shape: torch.Size([1, 25088])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 4096])
ReLU output shape: torch.Size([1, 4096])
Dropout output shape: torch.Size([1, 4096])
Linear output shape: torch.Size([1, 10])
训练模型
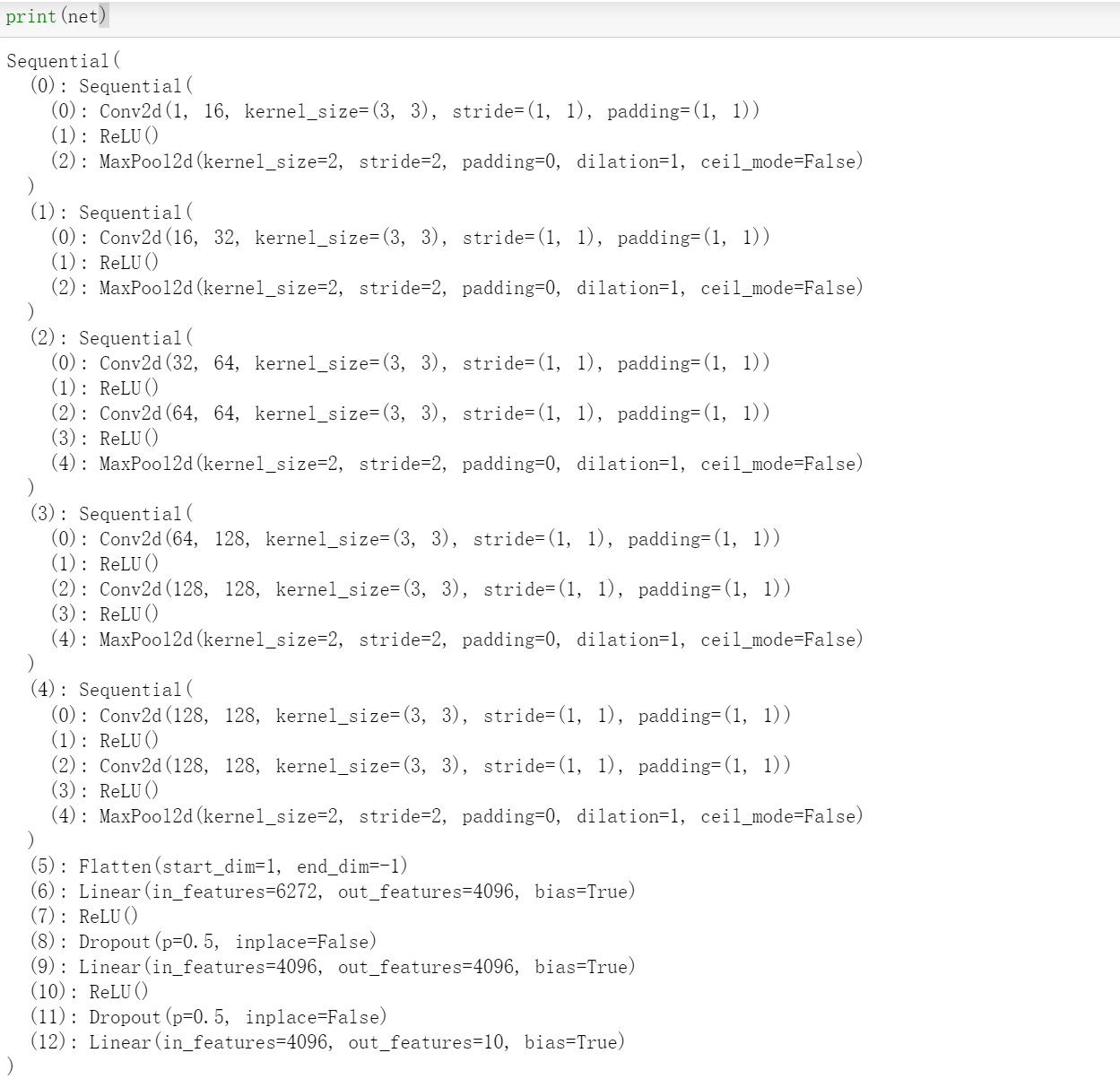
由于VGG-11比AlexNet计算量更大,因此我们构建了⼀个通道数较少的网络,足够用于训练Fashion-MNIST数据集。
ratio = 4
small_conv_arch = [(pair[0], pair[1] // ratio) for pair in conv_arch]
print(small_conv_arch)
net = vgg(small_conv_arch)
# [(1, 16), (1, 32), (2, 64), (2, 128), (2, 128)]
lr, num_epochs, batch_size = 0.05, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size, resize=224)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, d2l.try_gpu())
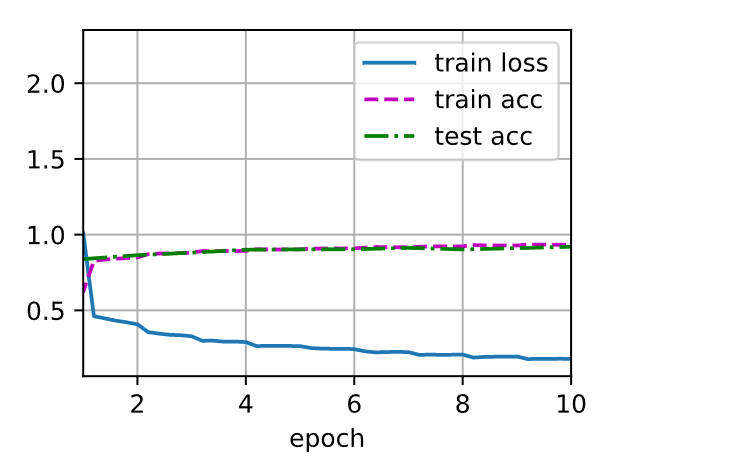
loss 0.179, train acc 0.933, test acc 0.920
931.8 examples/sec on cuda:0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号